
Curso
Entrenamiento eficiente de modelos de IA con PyTorch
4 h
1.5K
Es posible que ya estés familiarizado con la segmentación de imágenes y vídeos, pero la segmentación de audio es una idea mucho menos explorada. Se refiere a la capacidad de separar y aislar sonidos dentro de una secuencia de audio, como extraer una voz hablada de la música de fondo o aislar la voz de una sola persona en una reunión de grupo. Hasta hace poco, estas tareas requerían herramientas especializadas y específicas, así como un considerable esfuerzo manual.
En este tutorial, exploraremos SAM Audio, la extensión de audio del modelo Segment Anything Model. Configuraremos un entorno local, instalaremos las dependencias necesarias, cargaremos el modelo y ejecutaremos la inferencia en una GPU RTX 3090.
A lo largo del camino, visualizaremos cómo SAM Audio puede segmentar con precisión partes específicas de una señal de audio de una manera mucho más intuitiva y clínicamente precisa que los enfoques tradicionales de procesamiento de audio.
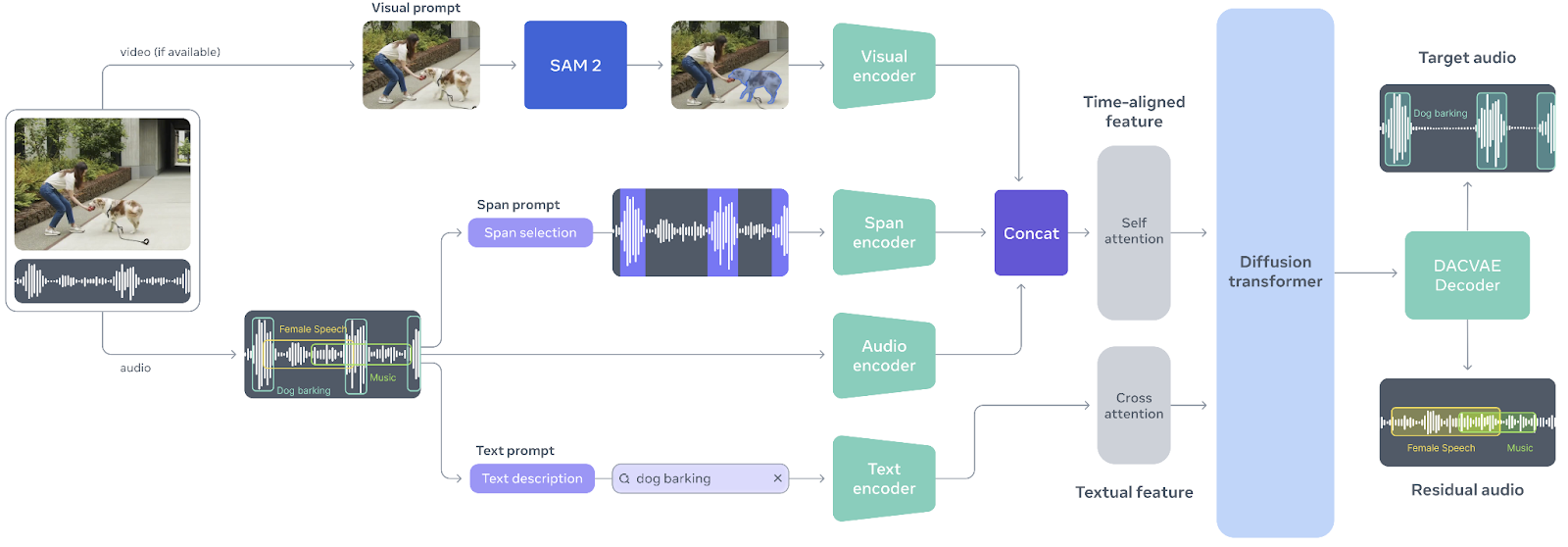
SAM Audio es un modelo multimodal unificado, el primero de su clase, diseñado para que la separación de audio sea tan intuitiva como la interacción con el sonido mismo. Inspirado en el éxito del modelo Segment Anything en visión, SAM Audio permite a los usuarios aislar cualquier sonido de mezclas de audio complejas utilizando indicaciones naturales, ya sea a través de texto, señales visuales en vídeo o marcando intervalos de tiempo. Este enfoque unificado sustituye las herramientas de audio fragmentadas y de un solo uso por un único sistema que funciona de forma fiable con voz, música y sonidos generales, incluso en situaciones reales y en entornos naturales.
Fuente: facebookresearch/sam-audio
El núcleo de SAM Audio es Perception Encoder Audiovisual (PE-AV), un potente motor que alinea lo que se ve con lo que se oye mediante la codificación conjunta de señales de audio y vídeo a lo largo del tiempo.
Basado en el codificador de percepción de código abierto de Meta, PE-AV proporciona representaciones ricas y temporalmente precisas que permiten un rendimiento de vanguardia en la separación de audio multimodal.
Juntos, SAM Audio y PE-AV abren nuevas posibilidades para los medios creativos, la accesibilidad y la comprensión del audio, haciendo que la segmentación de audio de calidad profesional sea más rápida, más accesible y más fácil de controlar que nunca.
Ahora te explicaré cómo empezar a utilizar SAM Audio de forma local.
SAM Audio es un modelo cerrado, lo que significa que debes solicitar acceso antes de poder descargarlo y utilizarlo localmente. Empieza por visitar la página del modelo Hugging Face en facebook/sam-audio-large y completa el formulario de solicitud de acceso. La aprobación suele tardar unos 10 minutos, pero en algunos casos se puede denegar el acceso en función de tu ubicación u otras políticas aplicadas por Meta.
Fuente: facebook/sam-audio-large · Hugging Face
Una vez que se te haya concedido el acceso, inicia un Jupyter Notebook local e instala la biblioteca SAM Audio directamente desde el repositorio oficial:
!pip install -q git+https://github.com/facebookresearch/sam-audio.gitUn problema habitual al trabajar con SAM Audio es que el kernel de Jupyter se bloquee o se reinicie de forma inesperada. Esto suele deberse a una versión incompatible de torchcodec. Para solucionar este problema, desinstala la versión existente e instala explícitamente la recomendada:
!pip uninstall -y torchcodec
!pip install --no-cache-dir "torchcodec==0.7.0" -f https://download.pytorch.org/whl/torchcodec/Para acelerar las descargas de modelos y dependencias, utilizaremos hf_transfer:
!pip install hf_transferPor último, inicia sesión en Hugging Face Hub utilizando un token de acceso. Asegúrate de haber generado un token API desde tu cuenta de Hugging Face y de haberlo almacenado como variable de entorno (HF_TOKEN):
import os
from huggingface_hub import login
login(token=os.environ["HF_TOKEN"])En este paso, descargarás y cargarás el modelo base SAM Audio. Aunque SAM Audio también ofrece una variante más amplia, el modelo básico proporciona prácticamente la misma calidad de separación, pero consume mucha menos memoria de la GPU.
Esto lo hace mucho más adecuado para la experimentación local, especialmente en GPU de consumo como la RTX 3090.
Para evitar errores de memoria insuficiente (OOM), es importante cargar el modelo en FP16 (media precisión) en lugar de FP32.
La RTX 3090 tiene una excelente compatibilidad con FP16, y al cambiar a media precisión se reduce casi a la mitad el uso de VRAM sin que ello afecte de forma notable a la calidad de la inferencia.
import torch
import torchaudio
from pathlib import Path
from sam_audio import SAMAudio, SAMAudioProcessor
MODEL_ID = "facebook/sam-audio-base" # base model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SAMAudio.from_pretrained(MODEL_ID).eval()
# Use fp16 on GPU to cut VRAM roughly in half (3090 supports fp16 well)
model = model.to(device=device, dtype=torch.float16).eval()
processor = SAMAudioProcessor.from_pretrained(MODEL_ID)
print("Device:", device)
print("Sampling rate:", processor.audio_sampling_rate)La primera vez que ejecutes esto, la descarga puede tardar un poco. SAM Audio utiliza múltiples componentes y puntos de control que, en conjunto, forman el canal completo de segmentación de audio, incluidos el codificador de percepción y los módulos de separación generativa. Este es el comportamiento esperado y solo ocurre una vez, ya que los archivos se almacenan en caché localmente para futuras ejecuciones.
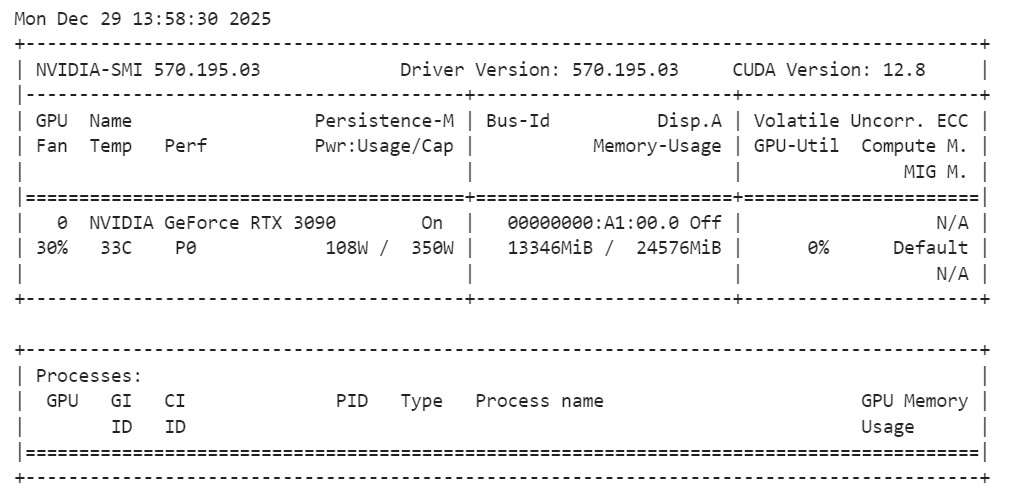
Una vez cargado el modelo, es recomendable comprobar el uso de la memoria de la GPU para asegurarte de que todo funciona dentro de los límites:
!nvidia-smiDebes tener en cuenta que el modelo básico de SAM Audio utiliza aproximadamente 14 GB de VRAM, lo que cabe perfectamente en una RTX 3090. Esto deja suficiente margen para la inferencia y la experimentación sin provocar problemas de memoria, lo que hace que la configuración sea estable y fiable para las tareas de segmentación de audio local.
Para probar SAM Audio, necesitamos una muestra de audio realista que contenga múltiples fuentes de sonido superpuestas. Para este tutorial, utilizaremos un ejemplo de AudioCaps, un conjunto de datos de referencia muy utilizado para la comprensión y la subtitulación de audio.
AudioCaps contiene clips de audio cortos y variados recopilados de entornos del mundo real, lo que lo hace ideal para evaluar modelos de separación de audio.
Cargamos el conjunto de datos directamente desde Hugging Face utilizando la biblioteca datasets. El audio de muestra se almacena en formato Parquet e incluye tanto datos de forma de onda como metadatos, como la frecuencia de muestreo.
from datasets import load_dataset
from IPython.display import Audio
# Get an example audio from AudioCaps
dset = load_dataset(
"parquet",
data_files="hf://datasets/OpenSound/AudioCaps/data/test-00000-of-00041.parquet",
)
samples = dset["train"][8]["audio"].get_all_samples()
Audio(samples.data, rate=samples.sample_rate)Este código descarga un único fragmento del conjunto de pruebas AudioCaps y extrae un clip de audio para su demostración. El widget « Audio » (Escuchar mezcla de audio) te permite escuchar la mezcla sin procesar directamente en el cuaderno, lo que resulta útil para comprender la complejidad del audio original antes de la segmentación. Así es como suena:
Escuchar es la forma más rápida de entender una mezcla de audio, pero visualizar la forma de onda te ayuda a ver dónde ocurre cada cosa.
Un gráfico de forma de onda facilita la detección de momentos con mucha energía (como una bocina, un aplauso o un grito), regiones más silenciosas (pausas o ruido de fondo) y picos repentinos que a menudo se corresponden con eventos sonoros breves.
Esto resulta especialmente útil una vez que empezamos a separar los sonidos, ya que puedes comparar la mezcla original con la salida segmentada y validar rápidamente si SAM Audio realmente extrajo la región correcta.
A continuación se muestra una función auxiliar sencilla que genera un gráfico de la forma de onda durante un tiempo determinado (para que el gráfico siga siendo legible). Admite audio mono y estéreo, y traslada automáticamente los tensores a la CPU para que funcione sin problemas en un ordenador portátil.
import matplotlib.pyplot as plt
import torch
def plot_waveform(wav, sr, title="Waveform", max_seconds=15):
"""
wav: Tensor [C, T] or [T]
sr: sample rate (int)
"""
if isinstance(wav, torch.Tensor):
w = wav.detach().cpu()
else:
w = torch.tensor(wav)
if w.ndim == 1:
w = w.unsqueeze(0)
# limit duration for readability
max_samples = int(sr * max_seconds)
w = w[:, :max_samples]
t = torch.arange(w.shape[1]) / sr
plt.figure(figsize=(14, 3))
for c in range(w.shape[0]):
plt.plot(t, w[c].numpy(), label=f"ch{c}")
plt.title(title)
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
if w.shape[0] > 1:
plt.legend()
plt.tight_layout()
plt.show()
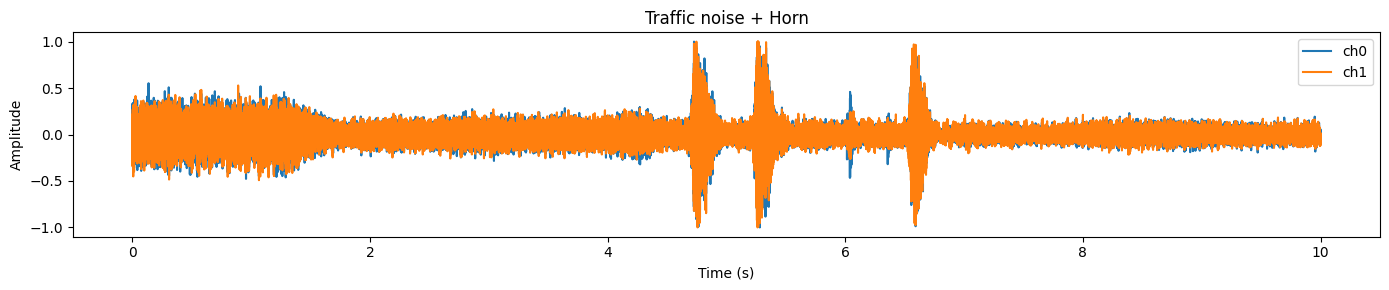
plot_waveform(samples.data, samples.sample_rate, title="Traffic noise + Horn")En este ejemplo, normalmente se observa una forma de onda densa y ocupada que representa el ruido de fondo continuo (tráfico) y picos más pronunciados que a menudo coinciden con eventos cortos y más fuertes (como una bocina).
Antes de ejecutar SAM Audio, debemos asegurarnos de que la forma de onda de entrada coincida con lo que espera el modelo. En la práctica, el audio sin procesar de los conjuntos de datos puede variar en cuanto aforma , tipo de datos, número de canales y frecuencia de muestreo. Si nos saltamos este paso, a menudo se producirán errores (dimensiones incorrectas), se obtendrán resultados deficientes (frecuencia de muestreo incorrecta) o se desperdiciará memoria de la GPU (tipo de datos incorrecto).
Esto es lo que vamos a estandarizar:
C, T] (canales primero).float32 para un procesamiento seguro y, a continuación, haz coincidir el tipo de datos del modelo (FP16 en CUDA).wav = torch.tensor(samples.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0) # [1, T]
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1) # [T, C] -> [C, T]
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True) # [1, T]
# Move to device + match model dtype (FP16 on CUDA)
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Resampled duration: {duration_s:.2f}s @ {target_sr} Hz")Si todo está configurado correctamente, deberías ver un resultado similar al siguiente:
Resampled duration: 10.00s @ 48000 HzEsto confirma que (1) la duración del audio es la esperada y (2) la forma de onda ahora utiliza la frecuencia de muestreo preferida por el modelo.
Ahora viene la parte divertida: vamos a separar un sonido objetivo de la mezcla de audio original. SAM Audio te permite hacerlo mediante indicaciones naturales y, en este ejemplo, extraeremos« » (un claxon sonando) de un clip que contiene ruido de tráfico y sonidos de claxon.
Utilizaremos dos tipos de orientación al mismo tiempo:
description): le dice al modelo lo que queremos («Una bocina sonando»).anchors): indican al modelo enqué momento se produce el objetivo (en segundos).Esto hace que la separación sea mucho más fiable, especialmente cuando la mezcla de audio es compleja o cuando el sonido objetivo es breve.
En el formato de anclajes:
6.3, 7.0] es la ventana de tiempo (inicio, fin) en segundos.description = "A horn honking"
anchors = [[["+", 6.3, 7.0]]] # batch -> one sample -> one anchor
# (Optional) sanity-check anchors
assert 0 <= anchors[0][0][1] < anchors[0][0][2] <= duration_s + 1e-6, "Anchor out of range!"
inputs = processor(
audios=[wav],
descriptions=[description],
anchors=anchors,
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
resid_np = result.residual[0].detach().float().cpu().numpy()
Audio(target_np, rate=processor.audio_sampling_rate)Cuando esto funciona correctamente, el resultado es realmente impresionante: el audio de destino debería sonar como un programa de trompa limpio, con la mayor parte del fondo eliminado. Esta es la idea clave detrás de SAM Audio: no necesitas pistas perfectas ni edición manual, solo tienes que guiar el modelo con indicaciones intuitivas y este aislará el sonido por ti. A continuación se muestra cómo suena:
Escuchar es la mejor prueba, pero la forma de onda permite ver fácilmente lo que ha ocurrido.
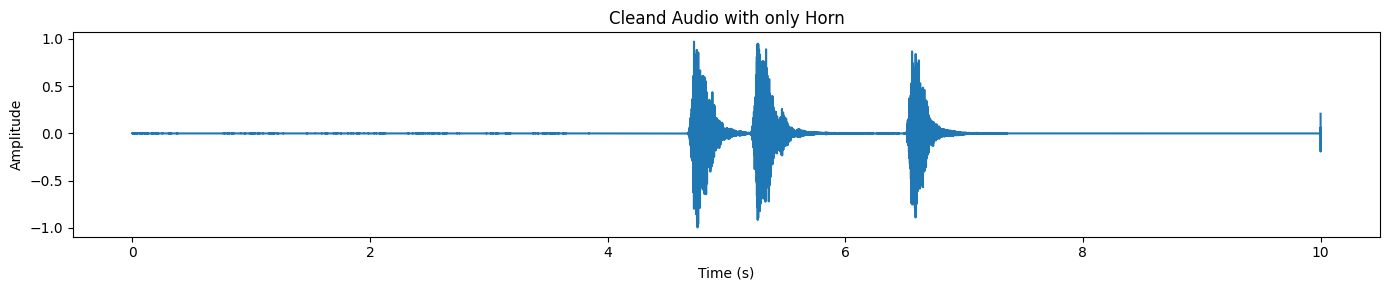
plot_waveform(target_np, processor.audio_sampling_rate, title="Cleand Audio with only Horn")En la salida separada, normalmente se observan picos distintivos donde se produce el sonido del claxon, mientras que el resto de la forma de onda permanece relativamente tranquila.
SAM Audio también devuelve una pista residual, que es básicamente «el resto del audio» después de eliminar el objetivo.
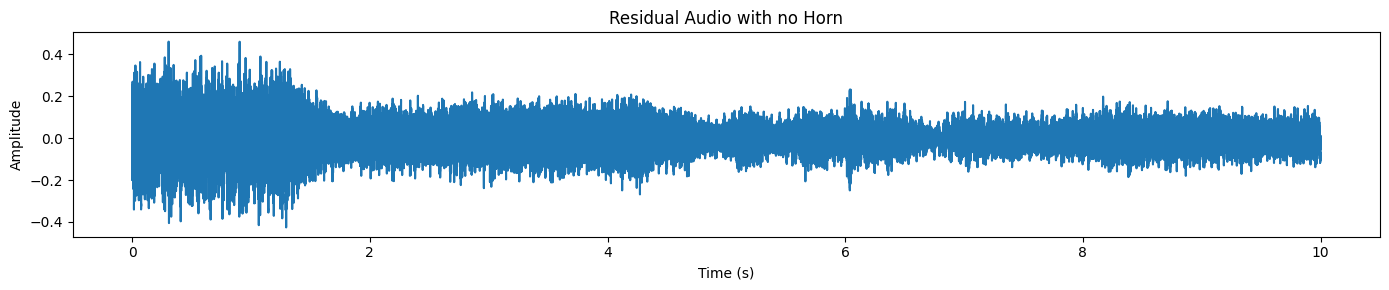
plot_waveform(resid_np, processor.audio_sampling_rate, title="Residual Audio with no Horn")Aquí solo se ve el tráfico y el ruido de fondo, pero no se oye el sonido de la bocina.
Probemos con un ejemplo más difícil y realista. En esta ocasión, elegiremos un fragmento en el que una persona que no habla inglés está hablando por teléfono mientras hay mucho ruido de fondo (ruido de la calle, ambiente, sonidos superpuestos).
Esta es precisamente el tipo de situación en la que la separación de audio resulta realmente útil: el discurso está presente, pero es difícil de entender porque la mezcla es confusa.
Primero, carga una nueva muestra y escucha la mezcla de audio sin procesar:
samples_2 = dset["train"][45]["audio"].get_all_samples()
Audio(samples_2.data, rate=samples_2.sample_rate)Ahora visualiza la forma de onda.
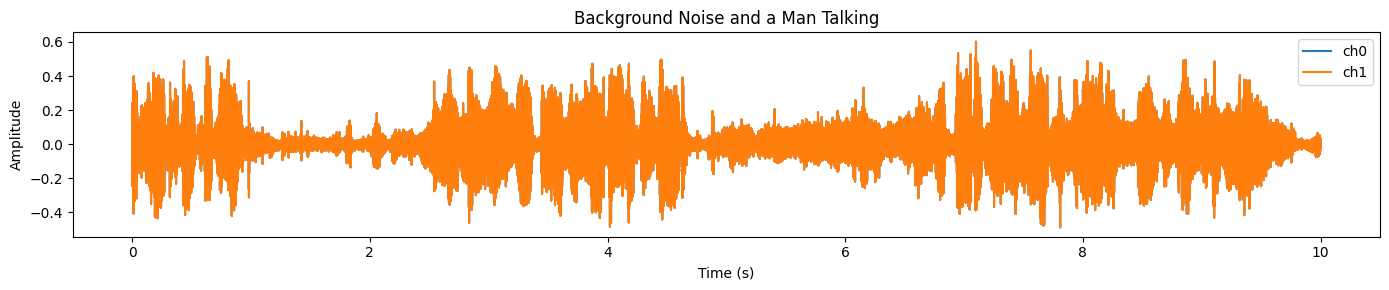
plot_waveform(samples_2.data, samples_2.sample_rate, title="Background Noise and a Man Talking")Verás una señal densa y de alta energía en la mayor parte del clip, lo que suele indicar un fuerte ruido de fondo y una superposición de audio:
Realizaremos los mismos pasos de preprocesamiento que antes: asegurarnos de que [C, T] tenga la forma adecuada, remuestrear a la frecuencia de muestreo objetivo del procesador, convertir a mono y pasar a la GPU en FP16.
# Convert numpy → torch
wav = torch.tensor(samples_2.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0)
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1)
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
# Resample if needed
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True)
# Move to GPU + FP16
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Duration: {duration_s:.2f}s @ {target_sr} Hz")
Deberías ver algo como esto:
Duration: 10.00s @ 48000 HzEn el ejemplo anterior, ayudamos al modelo con un ancla de intervalo de tiempo y una indicación de texto. Aquí, realizaremos indicaciones solo de texto, lo cual es una excelente manera de probar qué tan bien puede generalizar el modelo sin orientación adicional.
description = "A man speaking"
inputs = processor(
audios=[wav],
descriptions=[description],
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
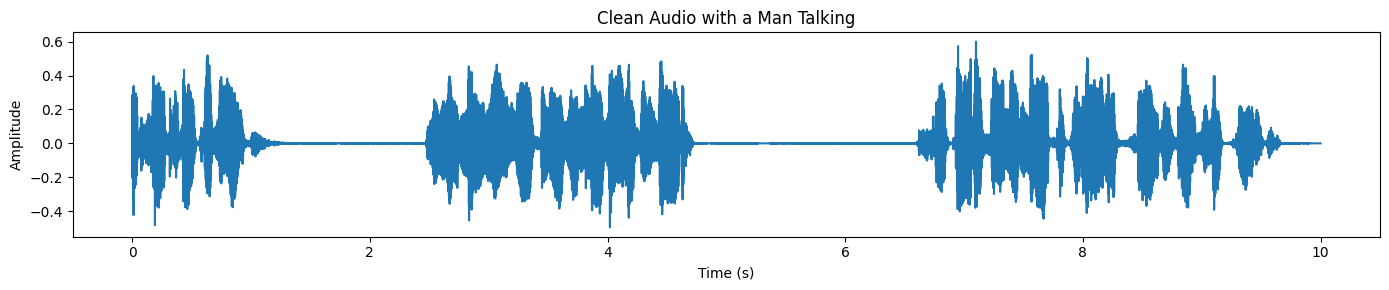
plot_waveform(target_np, processor.audio_sampling_rate, title="Clean Audio with a Man Talking")Por último, gráficamente la forma de onda del habla separada. En comparación con la mezcla original, la forma de onda debería verse más limpia y menos «recargada», especialmente en las regiones donde antes predominaba el ruido de fondo:
Si tienes algún problema al ejecutar el código anterior, consulta el cuaderno de DataLab que se incluye a continuación para obtener una referencia completa y funcional, así como orientación adicional: Uso local de SAM-Audio — DataLab.
SAM Audio está diseñado para comprender y editar audio en el mundo real. En lugar de depender de herramientas específicas para cada tarea, utiliza indicaciones naturales para separar y aislar los sonidos del habla, la música y los entornos cotidianos.
Estas características lo hacen útil en flujos de trabajo creativos, profesionales y de investigación, donde es importante contar con un audio limpio y controlable.
Para ser sincero, no hay mucha información disponible sobre cómo ejecutar SAM Audio localmente. Intenté ejecutarlo en Kaggle con GPU T4, pero falló. También intenté usar UV y configurar un entorno Python virtual, pero tampoco funcionó.
El principal problema con el que me topaba constantemente eran los conflictos de dependencias. La instalación de SAM Audio directamente desde el repositorio GitHub a menudo anula las bibliotecas de audio y PyTorch existentes, lo que provoca que el kernel de Jupyter se bloquee.
Por eso recomiendo encarecidamente empezar con una configuración limpia utilizando Conda o un entorno virtual Python nuevo, instalar primero PyTorch y CUDA y, a continuación, añadir las bibliotecas necesarias. En este tutorial, la configuración se estabilizó una vez que solucioné el fallo reinstalando la versión correcta de torchcodec.
En este tutorial, hemos ejecutado con éxito el modelo base SAM Audio en una RTX 3090 utilizando alrededor de 14 GB de VRAM, lo cual es muy razonable para la inferencia local. La velocidad de inferencia es rápida y la calidad de la separación de audio es realmente impresionante. También puedes ampliar esta configuración a las indicaciones basadas en vídeo, donde SAM Audio funciona junto con SAM 3 para aislar el audio basándose en señales visuales.
Para obtener más información sobre SAM 3, te recomiendo que consultes nuestro tutorial de SAM 3 a continuación.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

