
Cours
Introduction à Spark SQL en Python
4 h
20.3K
L'équilibrage de charge est un concept qui apparaît dans plus d'endroits que vous ne le pensez.
Prenons l'exemple d'un samedi matin dans un supermarché bondé où une seule caisse est ouverte. Quinze personnes font la queue, tout le monde est agacé, et le caissier semble regretter toutes les décisions qui l'ont conduit à cette situation. La tension commence vraiment à monter lorsque trois membres du personnel apparaissent soudainement, ouvrent quelques files supplémentaires et commencent à diriger les personnes vers les files d'attente les plus courtes. Tout s'accélère, la pression diminue et les files d'attente recommencent à avancer normalement. C'est, en substance, ce qu'est l'équilibrage de charge.
Dans cet article, je vais vous expliquer ce qu'est l'équilibrage de charge, pourquoi il est important, comment il fonctionne en arrière-plan et comment il empêche le monde numérique de s'effondrer lorsque le trafic est intense. Aucune connaissance particulière n'est requise pour suivre cet article, donc ne vous inquiétez pas si vous n'êtes pas un expert en réseaux ou en architecture cloud. Ce guide vous fournira des informations claires, pratiques et, nous l'espérons, quelque peu divertissantes.
Dans le domaine technologique, l'équilibrage de charge désigne la manière dont nous répartissons le trafic entrant ou les tâches entre plusieurs serveurs ou ressources. Au lieu de laisser une seule machine être submergée par la charge de travail, un équilibreur de charge répartit la charge afin que le système reste rapide, stable et évolutif. Il est omniprésent dans les infrastructures modernes : les plateformes cloud l'utilisent pour gérer des millions d'utilisateurs, les pipelines d'IA s'appuient sur lui pour répartir les charges de données entre les nœuds et les sites de commerce électronique comptent sur lui pour faire face au Black Friday.
Imaginons un instant que votre application ne dispose pas d'équilibreur de charge. Un serveur reçoit toutes les requêtes, tout le trafic, toute la pression. Peut-être que cela dure un certain temps, jusqu'à ce que (inévitablement) cela cesse. Le système ralentit, les utilisateurs sont frustrés, voire le système peut se bloquer complètement. Pendant ce temps, les autres serveurs restent inactifs, ne faisant rien.
Sans équilibrage de charge, vous êtes essentiellement contraint de :
Maintenant, ajoutez un équilibreur de charge, et la situation apparaît très différente. Il est positionné devant vos serveurs backend, surveillant le fonctionnement de chacun d'entre eux et distribuant les requêtes entrantes vers celui qui est le plus performant ou le moins sollicité. Certains surveillent même en temps réel des éléments tels que le temps de réponse ou les ressources du serveur.
Voici ce que vous recevrez :
Si vous réfléchissez encore à l'exemple du supermarché, imaginez que cette file d'attente de 15 personnes soit intelligemment répartie entre cinq caisses. Personne ne panique, personne ne crie, et vous pouvez vous rendre plus rapidement au rayon des pizzas surgelées. Tel est l'objectif.
Nous avons donc discuté de l'utilité de l'équilibrage de charge de l'. Examinons maintenant et son fonctionnement interne.
À un niveau élevé, un équilibreur de charge se trouve entre les clients (les personnes ou les systèmes qui font des demandes) et vos serveurs backend (ceux qui effectuent le travail). Sa fonction consiste à recevoir chaque requête entrante et à déterminer où l'acheminer.
Voici le déroulement de base :
En théorie, cela semble assez simple, mais il se passe beaucoup de choses en coulisses, et quelques concepts clés permettent d'assurer le bon fonctionnement de l'ensemble :
Remarque : le « load balancing » ( équilibrage de charge) est le concept (répartition du trafic), tandis qu'un « load balancer » (équilibreur de charge) est l', ou le service qui permet de le mettre en œuvre. Ces deux termes sont souvent utilisés de manière interchangeable, mais il est utile de connaître la distinction entre les deux.
Bien que les équilibreurs de charge choisissent parfois un serveur au hasard, il existe des stratégies concrètes, appelées algorithmes d'équilibrage de charge, qui déterminent la manière dont le trafic entrant est réparti entre les ressources backend.
Certaines sont assez simples et prévisibles, tandis que d'autres s'ajustent en temps réel en fonction des performances du serveur, du nombre de connexions ou de la vitesse de réponse. Nous pouvons les classer en deux grandes catégories.
Ces derniers ne s'adaptent pas à ce qui se passe dans le système ; ils suivent simplement une règle prédéfinie. Cela les rend prévisibles et faciles à mettre en œuvre, mais pas toujours idéales dans des conditions réelles.
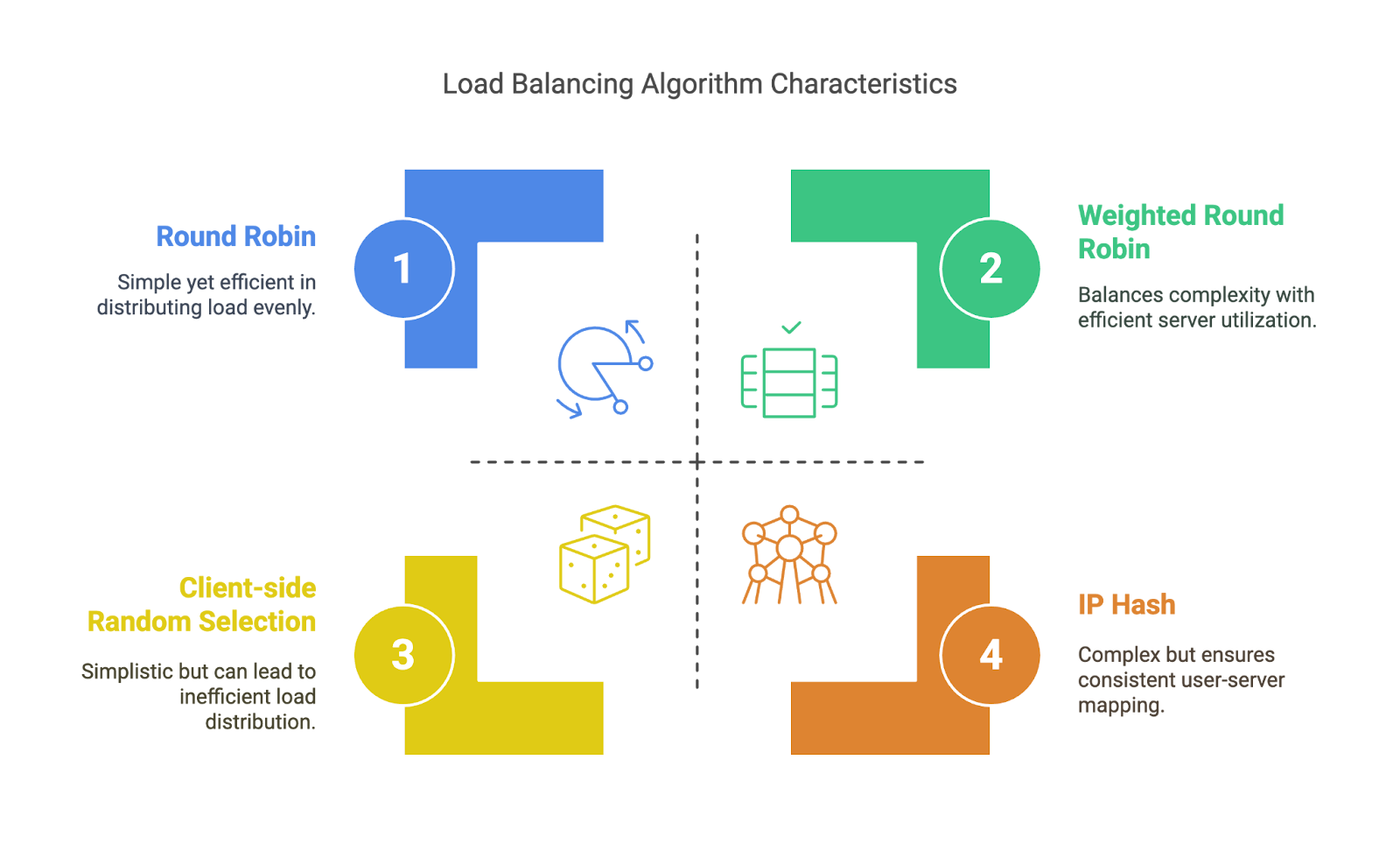
Algorithmes statiques. Image par l'auteur
Ces algorithmes s'adaptent en fonction de ce qui se passe réellement dans le système. Ils sont plus performants, mais nécessitent une surveillance accrue et une meilleure connaissance du système.
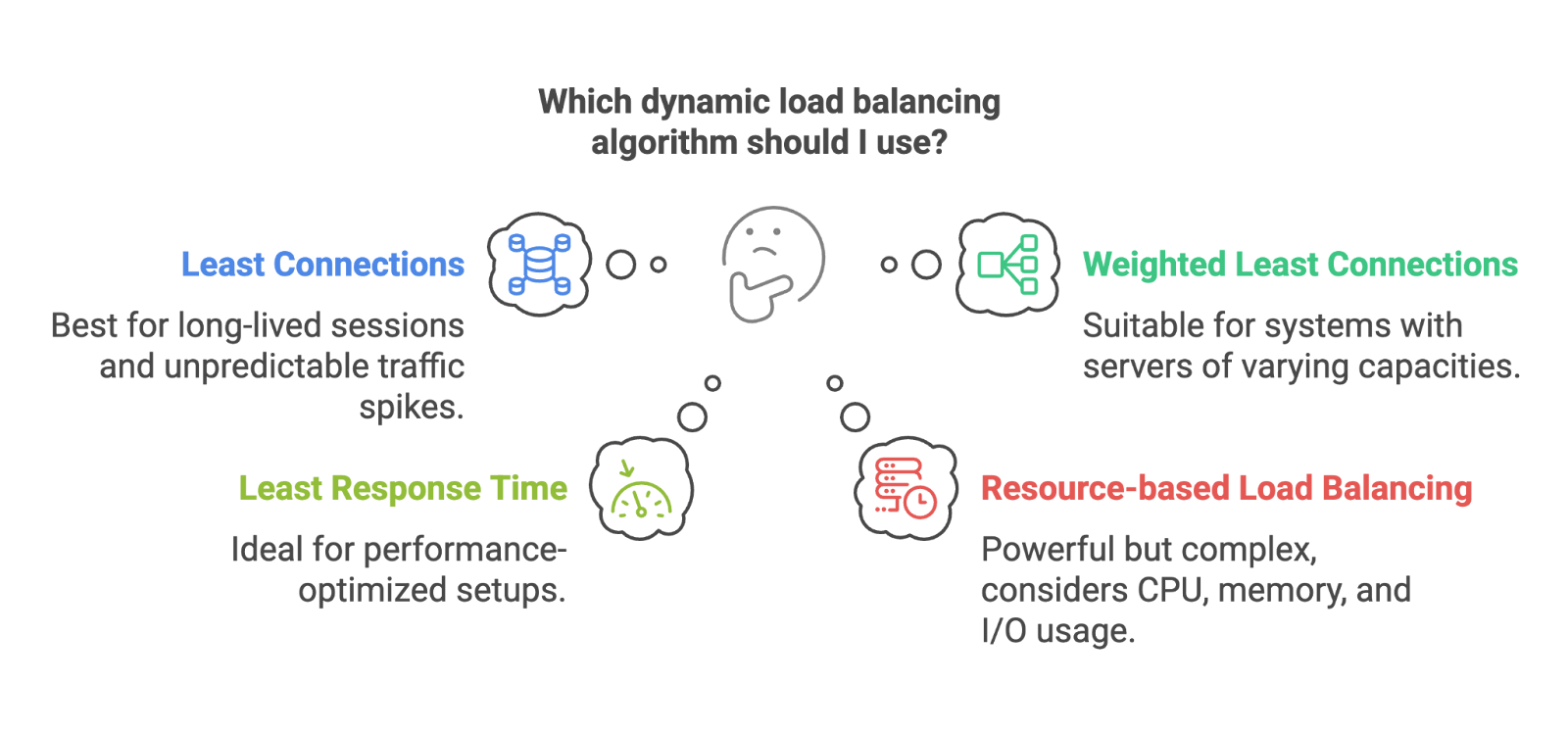
Algorithmes dynamiques. Image par l'auteur
Les algorithmes statiques sont très efficaces lorsque votre trafic est prévisible et que vos serveurs sont équilibrés. Les algorithmes dynamiques sont particulièrement efficaces lorsque la situation est un peu plus complexe.
Très bien, abordons maintenant les différents types de répartiteurs de charge : matériel, logiciel, natif du cloud, etc.
Tous les équilibreurs de charge ne sont pas identiques. Certains sont intégrés au matériel, d'autres fonctionnent comme des logiciels, d'autres encore sont associés à des services cloud, et certains sont spécialisés dans des cas d'utilisation très spécifiques. Le choix dépend de votre architecture, de votre échelle et parfois simplement de votre budget.
Il s'agit d'appareils physiques installés dans votre centre de données, spécialement conçus pour équilibrer le trafic. Ils sont puissants et rapides, mais coûteux et plus difficiles à adapter à la demande. Pensez aux grandes entreprises et aux installations sur site.
Ces programmes fonctionnent comme des applications sur des serveurs à usage général. Les outils d'équilibrage de charge tels que HAProxy, nginx (propriété de F5) ou Envoy relèvent de cette catégorie. Ils sont plus économiques, plus flexibles et plus faciles à intégrer dansla plupart des environnements.
Si vous utilisez AWS, Azure ou GCP, vous utilisez probablement déjà un équilibreur de charge natif du cloud, tel qu'AWS ELB, Azure Load Balancer ou GCP Load Balancing. Ils sont gérés pour vous, s'adaptent automatiquement et s'intègrent parfaitement à d'autres services.
Si vous souhaitez vous familiariser avec la manière dont AWS gère cela (et de nombreux autres éléments d'infrastructure), veuillez consulternotrecours Concepts de technologie et de services cloud AWS.
Vous avez peut-être entendu parler des équilibreurs de charge élastiques. Ils sont conçus pour s'adapter à votre charge de travail. Ils font souvent partie des systèmes cloud natifs, mais le terme « élastique » signifie simplement qu'ils peuvent s'adapter de manière dynamique au trafic, ce qui est idéal pour les charges irrégulières ou imprévisibles.
Le modèle OSI est un cadre conceptuel utilisé pour décrire la manière dont les données circulent à travers un réseau. Il comporte sept couches, depuis le câble physique jusqu'à l'application dans votre navigateur. Pour l'équilibrage de charge, les couches les plus pertinentes sont les couches 4 et 7.
Ces derniers prennent des décisions de routage en fonction des adresses IP, des ports et du trafic TCP/UDP. Ils sont rapides et efficaces, mais ne disposent d'aucune connaissance sur le contenu envoyé.
Ces derniers examinent le contenu réel de la requête, comme les en-têtes HTTP, les cookies ou les URL. Cela leur permet de réaliser des opérations plus avancées telles que le routage basé sur le chemin d'accès URL, les tests A/B ou les préférences linguistiques. Par exemple, si vous souhaitez que les requêtes /api/ soient dirigées vers un cluster et les requêtes /login vers un autre, vous aurez besoin de la couche 7.
Utilisé pour répartir le trafic entre des centres de données géographiquement dispersés. Utile pour les configurations multirégionales, à faible latence ou de reprise après sinistre.
Fonctionne entièrement au sein de réseaux privés, utilisé pour équilibrer le trafic entre les services au sein d'un cloud ou d'un cluster.
Spécialisé dans les systèmes de télécommunications utilisant le protocole Diameter, souvent utilisé dans les réseaux mobiles pour le routage, l'authentification et les demandes de facturation.
Ces derniers sont spécialement optimisés pour gérer le trafic HTTP et HTTPS. Ils intègrent souvent la terminaison SSL, le routage basé sur l'URL et une protection DDoS intégrée.
Chaque type d'équilibreur de charge résout un type de problème différent. Certaines sont axées sur l'échelle, d'autres sur la latence, la sécurité ou la facilité d'utilisation. Savoir lequel choisir peut faire une grande différence dans la fluidité (ou la complexité) du fonctionnement de votre infrastructure.
Jusqu'à présent, nous avons abordé le fonctionnement des équilibreurs de charge et les types que vous pourriez utiliser, mais comment sont-ils conçus en détail ? L'architecture d'un système d'équilibrage de charge influe sur tous les aspects, de sa capacité d'évolutivité à sa gestion des défaillances.
Il s'agit de la configuration classique : un nœud « leader » prend les décisions et distribue le travail à plusieurs nœuds « travailleurs ». C'est simple et facile à comprendre, mais le dirigeant peut devenir un goulot d'étranglement ou un point de défaillance unique s'il n'est pas correctement soutenu.
Au lieu d'un cerveau central, chaque équilibreur de charge est conscient de ses pairs etpartage le travail. Cela améliore la tolérance aux pannes et l'évolutivité, mais rend la coordination légèrement plus complexe. Ceci est fréquemment observé dans les systèmes à grande échelle utilisant le routage anycast ou la distribution basée sur le DNS.
Dans les environnements conteneurisés, en particulier avec Kubernetes, l'équilibrage de charge devient encore plus pertinent. Les services, les contrôleurs d'entrée et les sidecars collaborent pour acheminer intelligemment le trafic au sein des clusters. Si vous débutez dans ce domaine, notre cours Introduction à Kubernetes constitue une excellente approche pratique pour acquérir les bases.
Dans cette configuration, les travailleurs inactifs peuvent « prendre » les tâches de ceux qui sont occupés. Il est couramment utilisé dans les environnements à forte intensité de calcul, tels que les files d'attente de tâches ou les pipelines de traitement de données, mais moins pour le trafic web. Il s'agit d'un modèle utile pour équilibrer des charges de travail imprévisibles.
Certains systèmes superposent leurs équilibreurs de charge, par exemple en en plaçant un au niveau mondial (par exemple, dans toutes les régions), un autre au niveau du centre de données et un troisième au sein d'un cluster de services spécifique. Cela permet de gérer la complexité et de garantir que chaque couche reste concentrée sur un domaine spécifique.
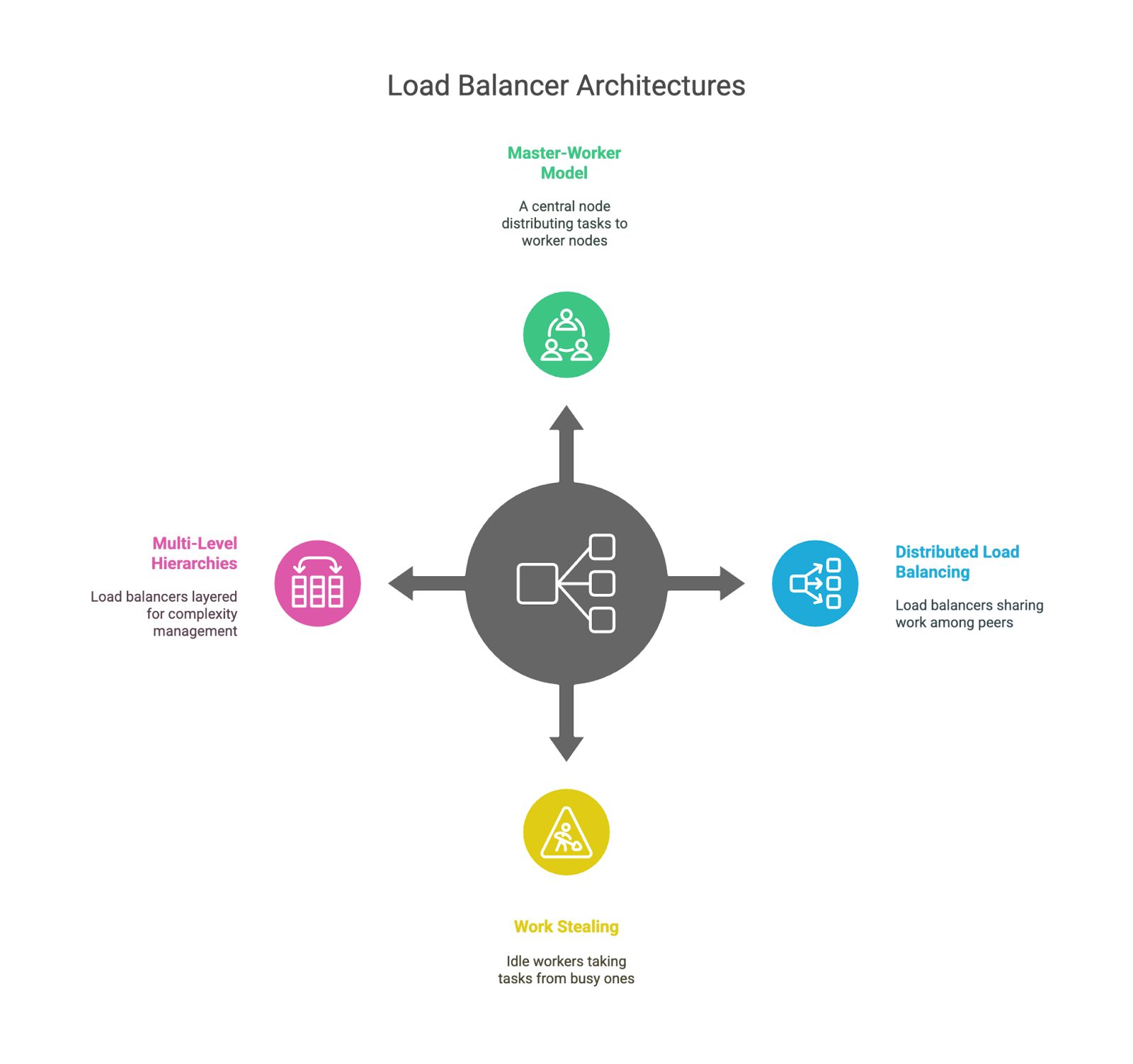
Architectures d'équilibrage de charge.
Chacune de ces architectures présente des avantages et des inconvénients. Les modèles centralisés sont faciles à appréhender, mais risquent de devenir des goulots d'étranglement. Les modèles distribués offrent une meilleure évolutivité, mais ajoutent de la complexité. Les topologies en couches offrent une modularité, mais peuvent introduire de la latence si elles ne sont pas conçues avec soin. Comme d'habitude, il n'existe pas de réponse unique. Cela dépend de la taille de votre système, des modèles de trafic et de la tolérance au risque.
L'équilibrage de charge est un outil puissant, mais ce n'est pas une solution miracle. Bien qu'il puisse rendre les systèmes plus fiables, évolutifs et efficaces, il introduit également de nouveaux niveaux de complexité et de points de défaillance potentiels. Examinons quelques-uns des compromis auxquels les ingénieurs sont confrontés, tant sur le plan technique qu'opérationnel.
Il est intéressant de noter que l'outil conçu pour répartir le trafic peut devenir un point de défaillance unique s'il n'est pas correctement conçu, en particulier dans les modèles centralisés ou basés sur un leader. C'est pourquoi de nombreux systèmes utilisent plusieurs équilibreurs de charge, des mécanismes de basculement ou même un équilibrage au niveau DNS afin de répartir les risques.
Quelle que soit sa rapidité, un équilibreur de charge ajoute toujours un saut entre le client et le backend. Cela peut entraîner une latence, en particulier dans les architectures multicouches ou avec le routage au niveau de la couche application (couche 7).
Gestion du trafic HTTPS au niveau de l'équilibreur de charge (également appelé La terminaison SSL peut alléger la charge de travail du processeur des serveurs backend, mais cela implique également que le répartiteur de charge effectue davantage de tâches et devient responsable des paramètres de sécurité sensibles et des certificats.
Les sessions persistantes sont utiles pour maintenir les utilisateurs connectés au même backend (par exemple lors de la connexion), mais elles compliquent la mise à l'échelle et rendent plus difficile l'exécution de services entièrement sans état. Les ingénieurs doivent fréquemment choisir entre l'expérience utilisateur et l'élégance architecturale.
Plus votre logique de routage est sophistiquée, plus il y a de risques de bugs, d'erreurs de routage ou de problèmes de performance subtils difficiles à détecter. Vous vous sentirez satisfait lorsque vous l'aurez configuré, mais beaucoup moins lorsque vous serez réveillé à 2 heures du matin pour résoudre des problèmes de fiabilité des contrôles de santé.
Chaque application réagit différemment sous la charge. Choisir entre des algorithmes statiques ou dynamiques et régler des paramètres tels que les seuils de connexion ou les intervalles de vérification de l'état de santé peut nécessiter de nombreux essais, erreurs et une certaine expérience.
Lorsqu'un problème survient, le répartiteur de charge ajoute un autre emplacement à examiner. Des routes mal configurées, des requêtes abandonnées, des couches de mise en cache ou des résultats de contrôle de santé incohérents peuvent tous contribuer à compliquer la situation.
Si votre équilibreur de charge gère le protocole SSL, il est nécessaire de vous assurer qu'il est correctement configuré, mis à jour et surveillé. Toute erreur à ce niveau peut créer des vulnérabilités ou compromettre la sécurité des communications.
Ceci est en partie lié au point que nous avons soulevé concernant la complexité accrue. Il est nécessaire de disposer d'un système de journalisation, de métriques et de traçage performant pour comprendre comment les requêtes circulent dans le système. Sans une bonne observabilité, un équilibreur de charge qui fonctionne mal peut être difficile à détecter et encore plus difficile à réparer.
Pour être clair, aucune de ces raisons nejustifie de ne pas envisager l'utilisation de l'équilibrage de charge. Il s'agit simplement de la réalité de la construction de systèmes résilients : chaque couche que vous ajoutez peut être utile, mais elle ajoute également de nouveaux défis à gérer.
Comme tout ce qui touche à la technologie, l'équilibrage de charge est en constante évolution. À mesure que les systèmes deviennent plus complexes, plus distribués et plus dynamiques, les approches traditionnelles sont mises à rude épreuve et de nouvelles stratégies sont testées.
Cela semble assez évident, compte tenu de la tendance technologique mondiale. Les plateformes modernes commencent à intégrer l'apprentissage automatique afin de prévoir les tendances du trafic et de prendre des décisions plus judicieuses en matière d'acheminement. Au lieu de simplement réagir à la charge actuelle, ces systèmes peuvent anticiper les pics (tels qu'un lancement de produit ou une actualité brûlante) et pré-ajuster le flux de trafic. Il est encore trop tôt pour se prononcer, mais le potentiel des infrastructures auto-optimisées est réel.
Si vous souhaitez approfondir ce sujet, notre tutorielsur l'apprentissage automatique, les pipelines, le déploiement et les MLOps constitue un excellent point de départ.
Les équilibreurs de charge traditionnels ne comprennent pas réellement le fonctionnement de votre application ; ils se concentrent uniquement sur le trafic. L'équilibrage de charge sensible aux applications approfondit l'analyse. Il est capable de prendre des décisions en fonction de l'identité de l'utilisateur, du type d'appareil ou de l'importance commerciale de la demande. Par exemple, il pourrait donner la priorité aux utilisateurs connectés pendant un pic de trafic ou acheminer le trafic sensible vers des clusters plus sécurisés.
À mesure que les entreprises répartissent leurs charges de travail entre plusieurs fournisseurs de cloud (ou combinent des solutions sur site et dans le cloud), les équilibreurs de charge s'adaptent. Ils doivent être plus sensibles à l'emplacement, prendre en charge le basculement inter-cloud et gérer le routage entre des environnements très différents. Il est probable que l'on observe une augmentation du nombre de directeurs de trafic mondiaux et d'orchestrations au niveau DNS dans ces configurations.
Avec l'essor de l'informatique en périphérie, l'équilibrage de charge se rapproche de l'utilisateur. Au lieu de tout acheminer via un cloud central, les requêtes sont traitées à partir de nœuds périphériques, ce qui réduit considérablement la latence. L'équilibrage de charge en périphérie doit être léger, intelligent et hyperlocal.
Certaines plateformes expérimentales explorent l'équilibrage de charge basé sur des agents, où les services individuels contribuent à déterminer comment le trafic doit circuler en fonction de ce qu'ils observent localement. Il est plus décentralisé et peut réagir rapidement aux changements à petite échelle, mais il pose également des défis en matière de coordination.
Il me semble évident que toutes ces tendances convergent vers un objectif : un équilibrage de charge plus dynamique, intelligent et contextuel. Les jours du simple routage par tour de rôle sont toujours d'actualité (pourquoi abandonner quelque chose qui fonctionne ?), mais ils commencent à partager la scène avec des systèmes qui apprennent, s'adaptent et prennent des décisions en temps réel en se basant sur bien plus que la charge du serveur.
Tout au long de cet article, nous avons examiné ce qu'est l'équilibrage de charge, pourquoi il est important et comment il fonctionne en arrière-plan. Nous avons abordé les algorithmes, les architectures et les applications concrètes, et nous espérons avoir contribué à rendre ce sujet un peu moins mystérieux. J'espère que cet article vous a permis de mieux comprendre comment tout cela s'articule.
Si vous souhaitez approfondir vos connaissances, nous vous invitons à vous inscrire à nos cours spécialisés. Je recommande vivement notre cours « Introduction à Kubernetes » et notre cours « Concepts de la technologie et des services cloud AWS ».
Apprenez avec DataCamp
Cours
Cours
Cours