Introduction
Les pipelines, le déploiement et les MLOps sont des concepts très importants pour les data scientists aujourd'hui. Construire un modèle dans Notebook n'est pas suffisant. Le déploiement de pipelines et la gestion des processus de bout en bout à l'aide des meilleures pratiques MLOps constituent un objectif de plus en plus important pour de nombreuses entreprises. Ce tutoriel aborde plusieurs concepts importants tels que Pipeline, CI/DI, API, Container, Docker, Kubernetes. Vous apprendrez également à connaître les frameworks et les bibliothèques MLOps en Python. Enfin, le tutoriel montre la mise en œuvre de bout en bout de la conteneurisation d'une application web ML basée sur Flask et son déploiement sur le cloud Microsoft Azure.
Concepts clés
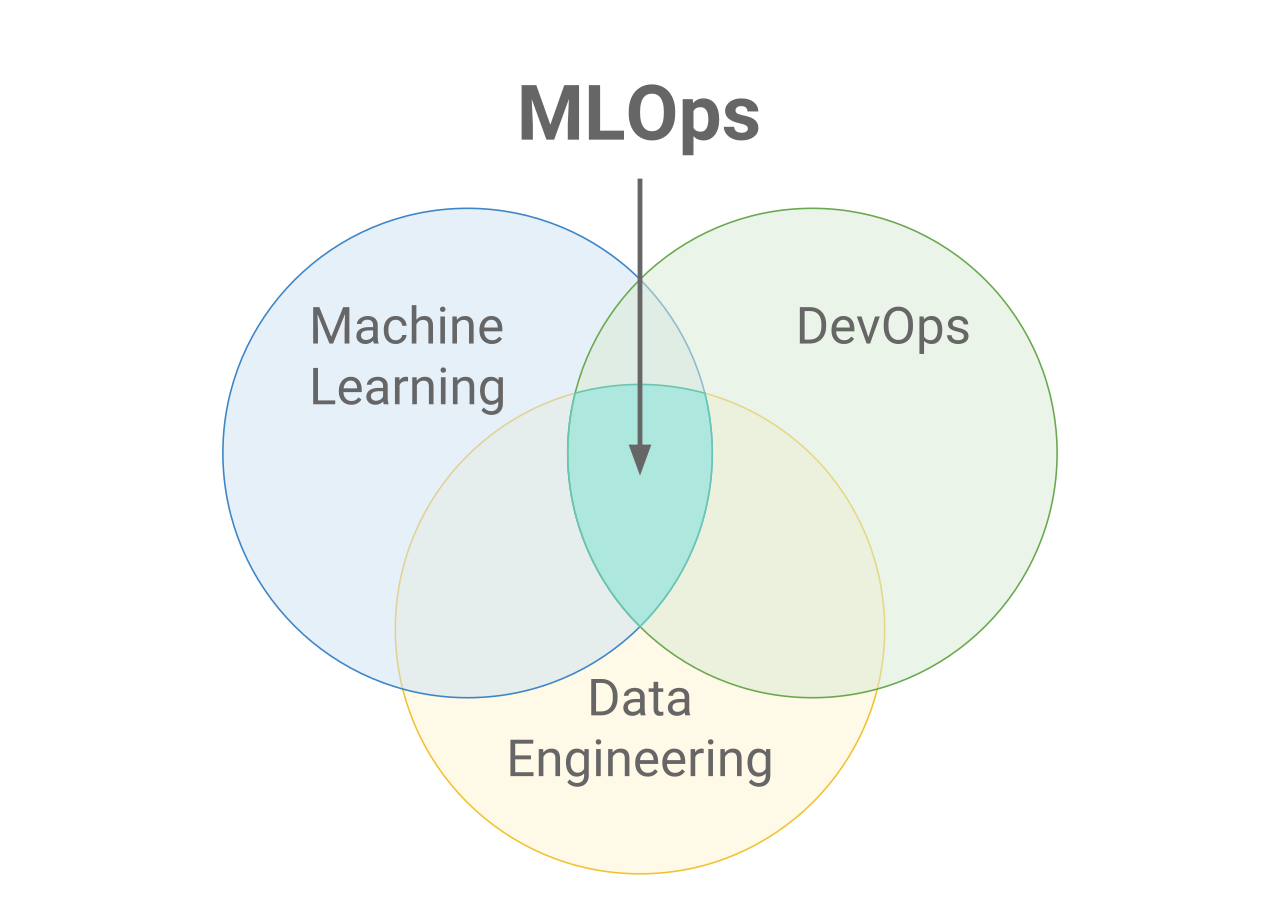
MLOps
MLOps signifie Machine Learning Operations (opérations d'apprentissage automatique). MLOps se concentre sur la rationalisation du processus de déploiement des modèles d'apprentissage automatique en production, puis sur leur maintenance et leur surveillance. MLOps est une fonction collaborative, souvent composée de data scientists, d'ingénieurs ML et d'ingénieurs DevOps. Le mot MLOps est un composé de deux domaines différents, à savoir l'apprentissage automatique et DevOps de l'ingénierie logicielle.
Les MLOps peuvent tout englober, du pipeline de données à la production de modèles d'apprentissage automatique. Dans certains endroits, vous verrez que la mise en œuvre de MLOps ne concerne que le déploiement du modèle d'apprentissage automatique, mais vous trouverez également des entreprises qui mettent en œuvre MLOps dans de nombreux domaines différents du développement du cycle de vie de l'apprentissage automatique, y compris l'analyse exploratoire des données (EDA), le prétraitement des données, l'entraînement au modèle, etc.
Si MLOps a débuté comme un ensemble de bonnes pratiques, il évolue lentement vers une approche indépendante de la gestion du cycle de vie des ML. MLOps s'applique à l'ensemble du cycle de vie - de l'intégration à la génération de modèles (cycle de vie du développement logiciel et intégration continue/prestation continue), à l'orchestration et au déploiement, en passant par l'état de santé, les diagnostics, la gouvernance et les mesures commerciales.
Pourquoi les MLOps ?
Les entreprises souhaitent atteindre de nombreux objectifs grâce aux MLOps. Voici quelques-unes des plus courantes :
- Automatisation
- Évolutivité
- Reproductibilité
- Contrôle
- Gouvernance
MLOps vs DevOps
DevOps est une approche itérative de la mise en production d'applications logicielles. MLOps emprunte les mêmes principes pour amener les modèles d'apprentissage automatique à la production. Qu'il s'agisse de Devops ou de MLOps, l'objectif final est d'améliorer la qualité et le contrôle des applications logicielles/modèles ML.
CI/CD : intégration continue, livraison continue et déploiement continu.
CI/CD est une pratique dérivée de DevOps et fait référence à un processus continu de reconnaissance des problèmes, de réévaluation et de mise à jour automatique des modèles d'apprentissage automatique. Les principaux concepts attribués à CI/CD sont l'intégration continue, la livraison continue et le déploiement continu. Il automatise le pipeline d'apprentissage automatique (construction, test et déploiement) et réduit considérablement la nécessité pour les scientifiques des données d'intervenir manuellement dans le processus, le rendant efficace, rapide et moins sujet à l'erreur humaine.
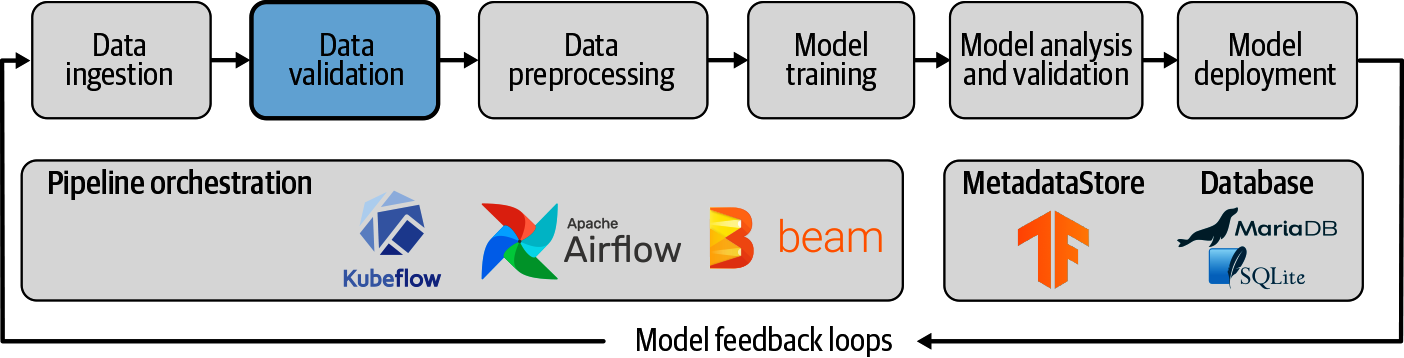
Pipeline
Un pipeline d'apprentissage automatique est un moyen de contrôler et d'automatiser le flux de travail nécessaire à la production d'un modèle d'apprentissage automatique. Les pipelines d'apprentissage automatique se composent de plusieurs étapes séquentielles qui vont de l'extraction et du prétraitement des données à l'entraînement et au déploiement des modèles.
Les pipelines d'apprentissage automatique sont itératifs, car chaque étape est répétée pour améliorer en permanence la précision du modèle et atteindre l'objectif final.
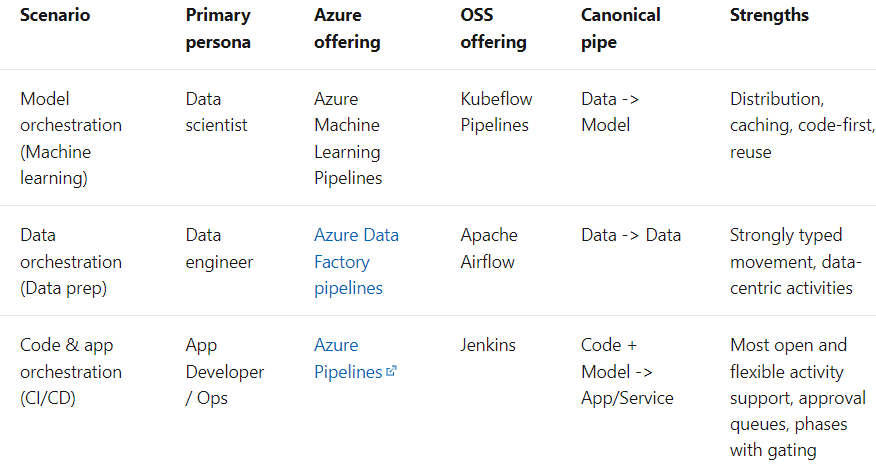
Le terme " pipeline" est généralement utilisé pour décrire la séquence indépendante d'étapes qui sont organisées ensemble pour réaliser une tâche. Cette tâche peut relever de l'apprentissage automatique ou non. Les pipelines d'apprentissage automatique sont très courants, mais ce n'est pas le seul type de pipeline qui existe. Les pipelines d'orchestration de données en sont un autre exemple. Selon la documentation de Microsoft, il existe trois scénarios :
Déploiement
Le déploiement de modèles d'apprentissage automatique (ou pipelines) est le processus de mise à disposition de modèles en production où les applications web, les logiciels d'entreprise (ERP) et les API peuvent consommer le modèle entraîné en fournissant de nouveaux points de données, et obtenir les prédictions.
En résumé, le déploiement de l'apprentissage automatique est la méthode par laquelle vous intégrez un modèle d'apprentissage automatique dans un environnement de production existant afin de prendre des décisions commerciales pratiques basées sur des données. Il s'agit de la dernière étape du cycle de vie de l'apprentissage automatique.
Normalement, le terme "déploiement de modèles d'apprentissage automatique" est utilisé pour décrire le déploiement de l'ensemble du pipeline d'apprentissage automatique, dans lequel le modèle lui-même n'est qu'un composant du pipeline.
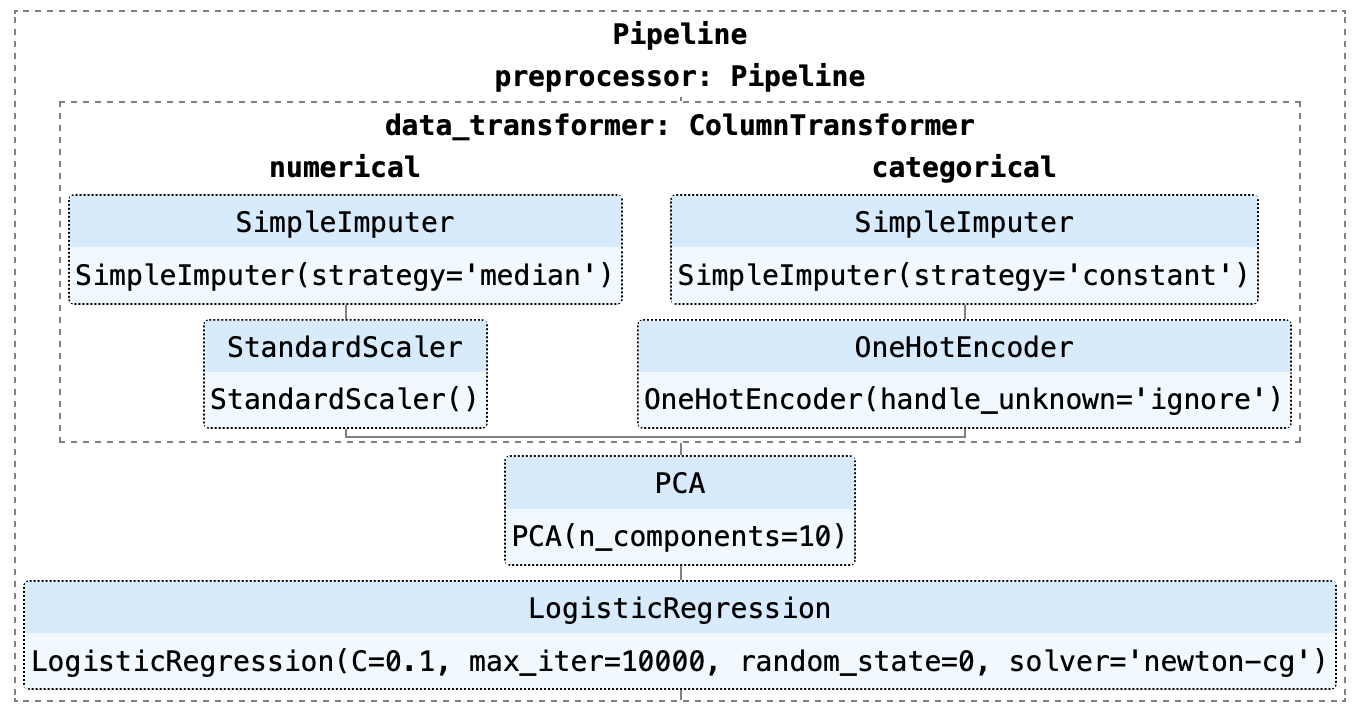
Comme vous pouvez le voir dans l'exemple ci-dessus, ce pipeline consiste en un modèle de régression logistique. Plusieurs étapes du pipeline doivent être exécutées avant que la formation ne puisse commencer, telles que l'imputation des valeurs manquantes, le codage One-Hot, la mise à l'échelle et l'analyse en composantes principales (ACP).
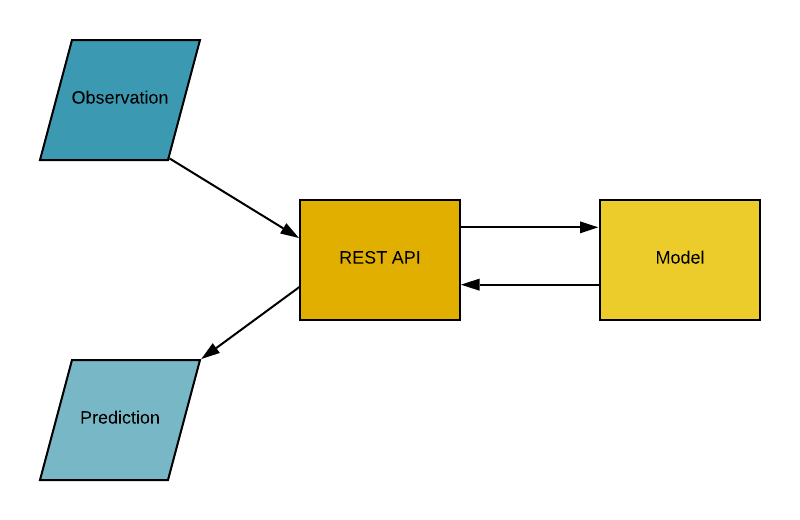
Interface de programmation d'applications (API)
L'interface de programmation d'applications (API) est un intermédiaire logiciel qui permet à deux applications de communiquer entre elles. En d'autres termes, une API est un contrat entre deux applications qui stipule que si le logiciel de l'utilisateur fournit des données dans un format prédéfini, l'API fournira le résultat à l'utilisateur. En d'autres termes, l'API est un point final où vous hébergez les modèles d'apprentissage automatique formés (pipelines) pour les utiliser. En pratique, cela ressemble à ceci :
Conteneur
Avez-vous déjà rencontré le problème suivant : votre code Python (ou tout autre code) fonctionne correctement sur votre ordinateur, mais lorsque votre ami essaie d'exécuter exactement le même code, il ne fonctionne pas ? Si votre ami répète exactement les mêmes étapes, il devrait obtenir les mêmes résultats, n'est-ce pas ? La réponse est simple : l'environnement Python de votre ami est différent du vôtre.
Que comprend un environnement ?
Python (ou tout autre langage que vous avez utilisé) et toutes les bibliothèques et dépendances utilisées pour construire cette application.
Si nous pouvons d'une manière ou d'une autre créer un environnement que nous pouvons transférer sur d'autres machines (par exemple, l'ordinateur de votre ami ou un fournisseur de services cloud comme Microsoft Azure, AWS ou GCP), nous pouvons reproduire les résultats n'importe où. Un conteneur est un type de logiciel qui regroupe une application et toutes ses dépendances afin que l'application puisse fonctionner de manière fiable d'un environnement informatique à l'autre.
La façon la plus intuitive de comprendre les conteneurs dans la science des données est de penser aux conteneurs d'un navire ou d'un bateau. L'objectif est d'isoler le contenu d'un conteneur des autres afin qu'ils ne se mélangent pas. C'est exactement ce à quoi servent les conteneurs dans le domaine de la science des données.
Maintenant que nous comprenons la métaphore des conteneurs, examinons d'autres options pour créer un environnement isolé pour notre application. Une solution simple consiste à disposer d'une machine distincte pour chacune de vos applications.
L'utilisation d'une machine séparée est simple, mais elle ne l'emporte pas sur les avantages de l'utilisation de conteneurs, car maintenir plusieurs machines pour chaque application est coûteux, cauchemardesque à entretenir et difficile à faire évoluer. En bref, ce n'est pas pratique dans de nombreux scénarios de la vie réelle.
Une autre solution pour créer un environnement isolé consiste à utiliser des machines virtuelles. Les conteneurs sont encore une fois préférables car ils nécessitent moins de ressources, sont très portables et sont plus rapides à mettre en service.
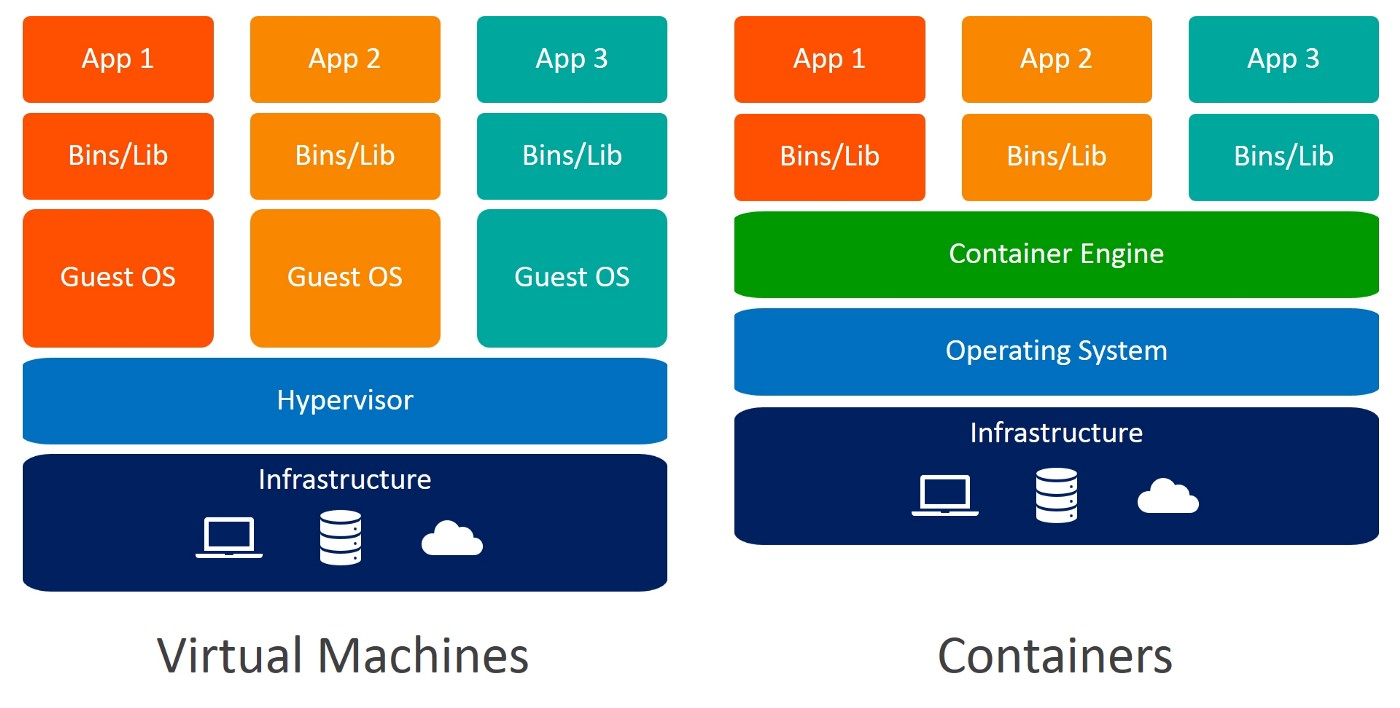
Pouvez-vous identifier les différences entre les machines virtuelles et les conteneurs ? Lorsque vous utilisez des conteneurs, vous n'avez pas besoin de systèmes d'exploitation invités. Imaginez 10 applications fonctionnant sur une machine virtuelle. Cela nécessiterait 10 systèmes d'exploitation invités, alors qu'aucun n'est nécessaire lorsque vous utilisez des conteneurs.
Docker
Docker est une entreprise qui fournit un logiciel (également appelé Docker) permettant aux utilisateurs de construire, d'exécuter et de gérer des conteneurs. Si les conteneurs de Docker sont les plus courants, d'autres solutions moins connues, telles que LXD et LXC, proposent également des solutions de conteneurs.
Docker est un outil conçu pour faciliter la création, le déploiement et l'exécution d'applications à l'aide de conteneurs. Les conteneurs sont utilisés pour emballer une application avec tous ses composants nécessaires, tels que les bibliothèques et autres dépendances, et l'expédier en un seul paquet.
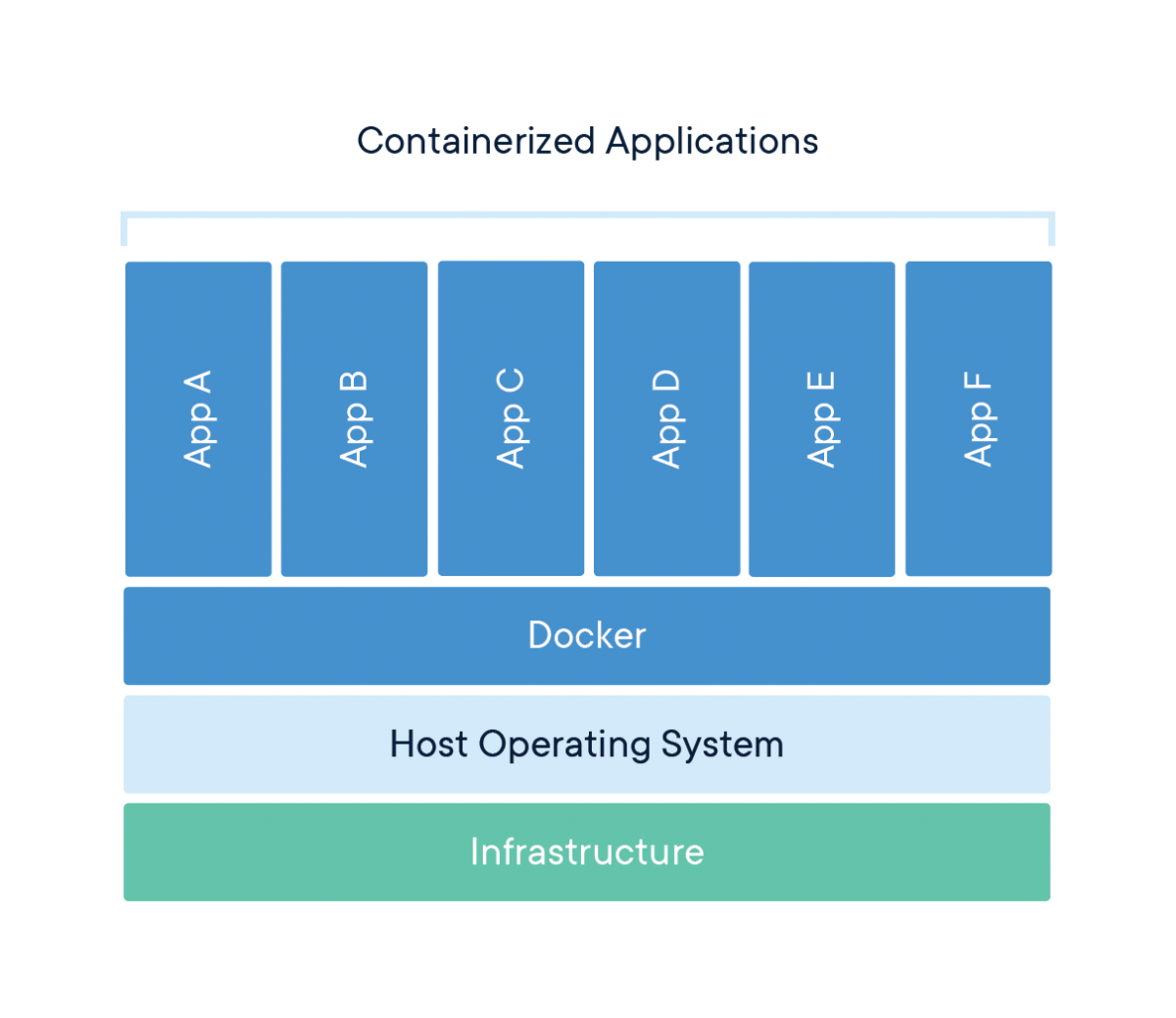
Briser l'engouement
En fin de compte, Docker n'est qu'un fichier contenant quelques lignes d'instructions qui sont enregistrées dans votre dossier de projet sous le nom de "Dockerfile".
Une autre façon d'envisager les fichiers Docker est de les comparer à des recettes que vous avez inventées dans votre propre cuisine. Lorsque vous partagez ces recettes avec quelqu'un d'autre et qu'il suit exactement les mêmes instructions, il est capable de produire le même plat. De même, vous pouvez partager vos fichiers Docker avec d'autres personnes, qui peuvent alors créer des images et exécuter des conteneurs basés sur ce fichier Docker particulier.
Kubernetes
Développé par Google en 2014, Kubernetes est un puissant système open-source de gestion des applications conteneurisées. En termes simples, Kubernetes est un système permettant d'exécuter et de coordonner des applications conteneurisées sur un cluster de machines. Il s'agit d'une plateforme conçue pour gérer entièrement le cycle de vie des applications conteneurisées.
Caractéristiques
- Équilibrage de la charge : Répartit automatiquement la charge entre les conteneurs.
- Échelle : Augmentez ou réduisez automatiquement votre capacité en ajoutant ou en supprimant des conteneurs lorsque la demande change, par exemple aux heures de pointe, les week-ends et les jours fériés.
- Stockage : Permet de conserver un stockage cohérent pour plusieurs instances d'une application.
Pourquoi avez-vous besoin de Kubernetes si vous avez Docker ?
Imaginez un scénario dans lequel vous devez exécuter plusieurs conteneurs Docker, sur plusieurs machines, pour prendre en charge une application ML de niveau entreprise avec des charges de travail variées, jour et nuit. Aussi simple que cela puisse paraître, c'est un travail considérable à effectuer manuellement.
Vous devez démarrer les bons conteneurs au bon moment, déterminer comment ils peuvent communiquer entre eux, gérer les considérations relatives au stockage et faire face aux défaillances des conteneurs ou du matériel. C'est le problème que résout Kubernetes, en permettant à un grand nombre de conteneurs de travailler ensemble en harmonie et en réduisant la charge opérationnelle.
Google Kubernetes Engine est une mise en œuvre du logiciel libre Kubernetes de Google sur Google Cloud Platform. D'autres alternatives populaires à GKE sont Amazon ECS et Microsoft Azure Kubernetes Service.
Récapitulation rapide des termes :
- Un conteneur est un type de logiciel qui regroupe une application et toutes ses dépendances afin que l'application fonctionne de manière fiable d'un environnement informatique à l'autre.
- Docker est un logiciel utilisé pour construire et gérer des conteneurs.
- Kubernetes est un système open-source permettant de gérer des applications conteneurisées dans un environnement en cluster.
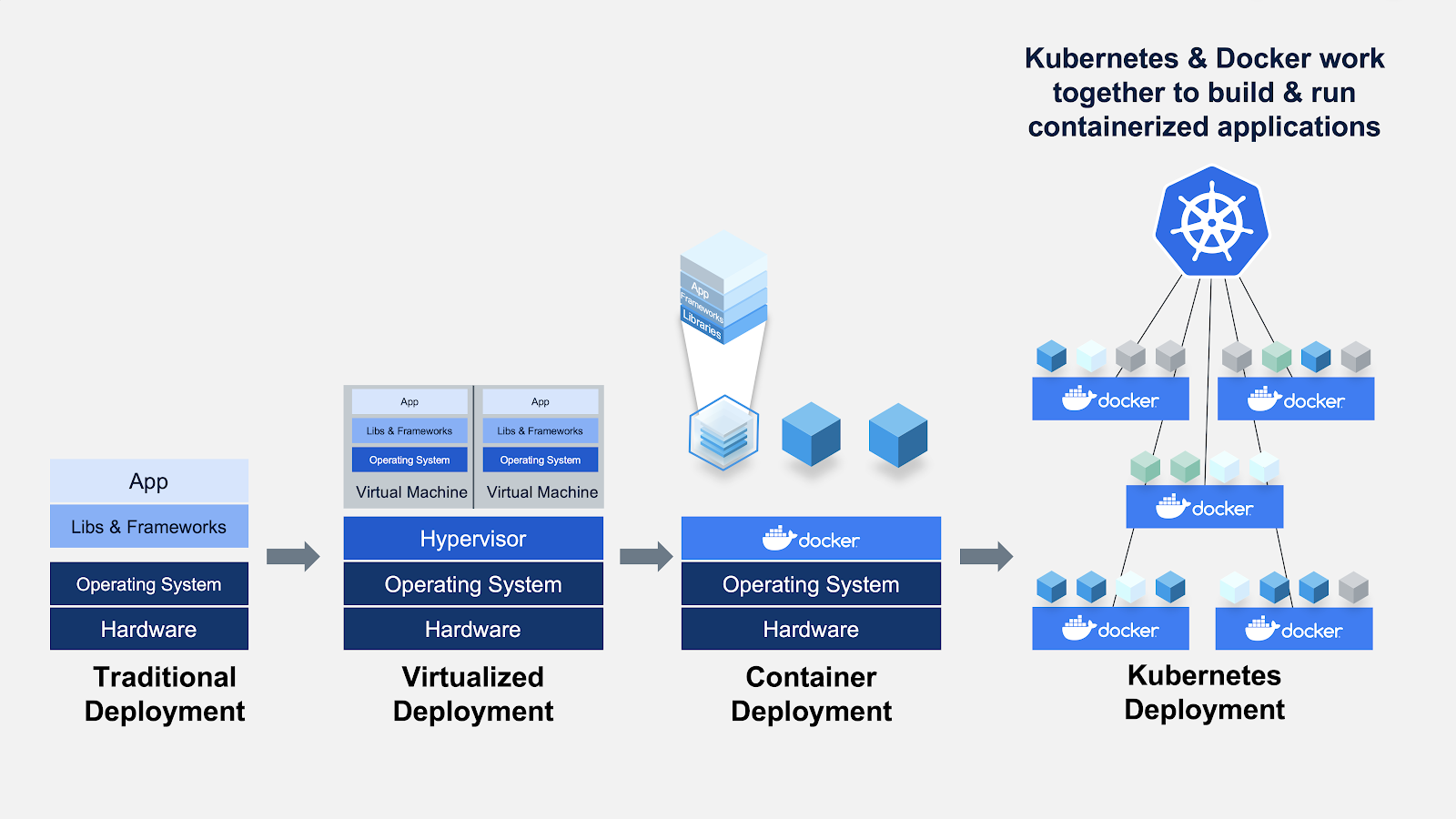
Cadres et bibliothèques MLOps en Python
MLflow
MLflow est une plateforme open-source qui permet de gérer le cycle de vie de la ML, y compris l'expérimentation, la reproductibilité, le déploiement et un registre central de modèles. MLflow propose actuellement le suivi de MLflow, les projets MLflow, les modèles MLflow et le registre des modèles.
Metaflow
Metaflow est une bibliothèque Python conviviale qui aide les scientifiques et les ingénieurs à construire et à gérer des projets réels de science des données. Metaflow a été développé à l'origine chez Netflix pour stimuler la productivité des scientifiques des données qui travaillent sur une grande variété de projets, des statistiques classiques à l'apprentissage profond de pointe. Metaflow fournit une API unifiée à la pile d'infrastructure nécessaire à l'exécution des projets de science des données, du prototype à la production.
Kubeflow
Kubeflow est une plateforme d'apprentissage automatique open-source, conçue pour permettre aux pipelines d'apprentissage automatique d'orchestrer des flux de travail compliqués s'exécutant sur Kubernetes. Kubeflow était basé sur la méthode interne de Google pour déployer les modèles TensorFlow, appelée TensorFlow Extended.
Kedro
Kedro est un framework Python open-source pour créer du code de science des données reproductible, maintenable et modulaire. Il emprunte des concepts aux meilleures pratiques de l'ingénierie logicielle et les applique au code de l'apprentissage automatique ; les concepts appliqués comprennent la modularité, la séparation des préoccupations et le versionnage.
FastAPI
FastAPI est un framework Web pour le développement d'API RESTful en Python. FastAPI est basé sur Pydantic et les indices de type pour valider, sérialiser et désérialiser les données, et générer automatiquement des documents OpenAPI.
ZenML
ZenML est un cadre MLOps extensible et open-source qui permet de créer des pipelines d'apprentissage automatique prêts à la production. Construit pour les scientifiques des données, il a une syntaxe simple et flexible, est agnostique au cloud et aux outils, et a des interfaces/abstractions qui sont adaptées aux flux de travail de ML.
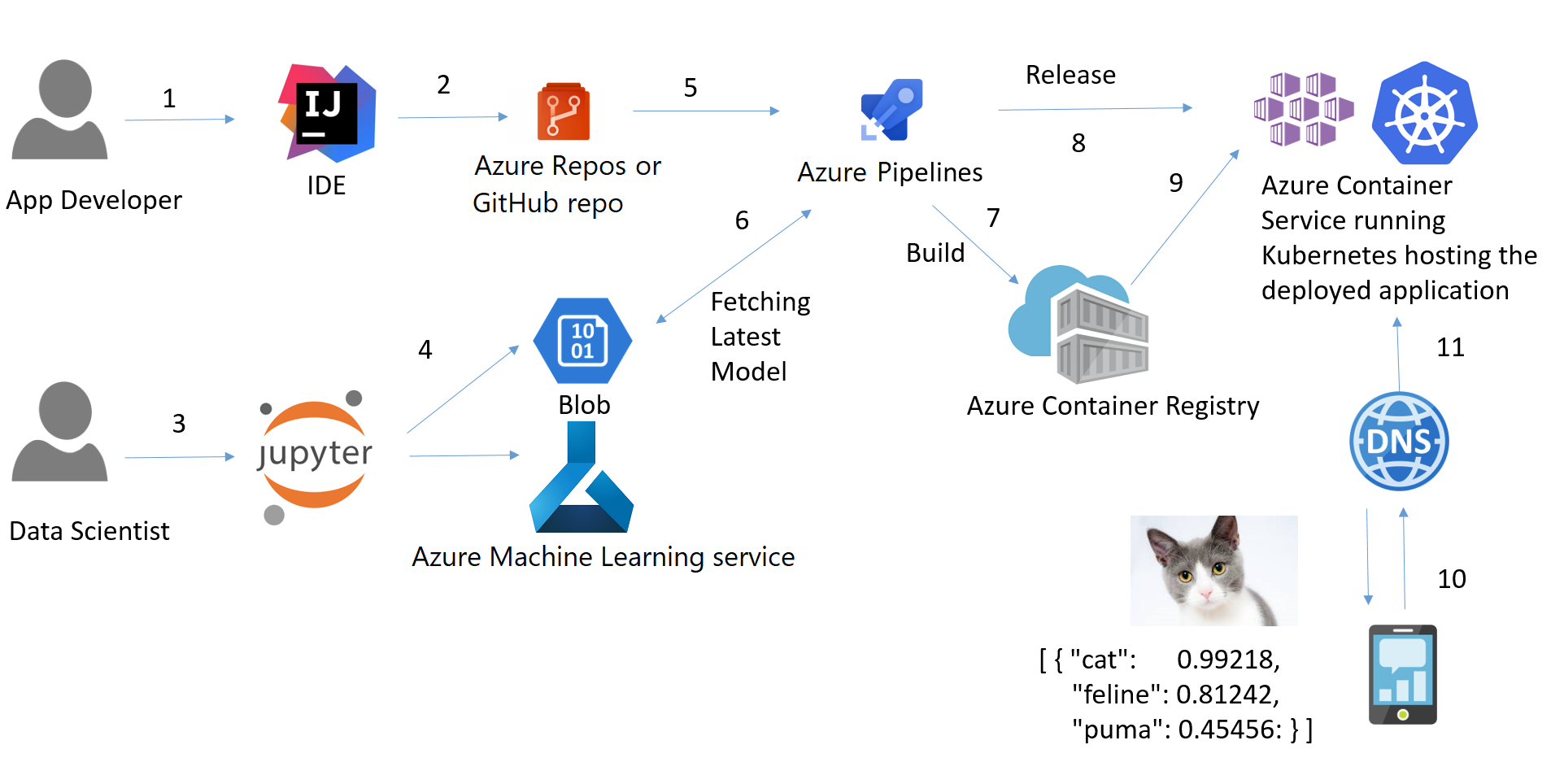
Exemple : Développement de bout en bout du pipeline, déploiement et MLOps
Configuration du problème
Une compagnie d'assurance souhaite améliorer ses prévisions de trésorerie en prévoyant mieux les frais à la charge des patients, à l'aide de données démographiques et de données de base sur les risques de santé des patients au moment de l'hospitalisation.
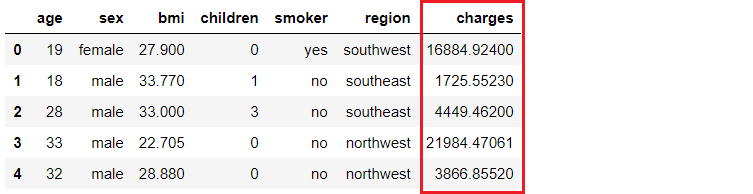
Notre objectif est de créer et de déployer une application web dans laquelle les informations démographiques et sanitaires d'un patient sont saisies dans un formulaire web, qui produit ensuite un montant de frais prédit. Pour ce faire, nous procéderons de la manière suivante :
- Former et développer un pipeline d'apprentissage automatique pour le déploiement (modèle de régression linéaire simple).
- Créez une application web en utilisant le framework Flask. Il utilisera le pipeline de ML formé pour générer des prédictions sur de nouveaux points de données en temps réel (le code frontal n'est pas l'objet de ce tutoriel).
- Créez une image Docker et un conteneur.
- Publiez le conteneur dans le Registre des conteneurs Azure (ACR).
- Déployez l'application web dans le conteneur en la publiant sur ACR. Une fois déployé, il sera mis à la disposition du public et accessible via une adresse URL.
Pipeline d'apprentissage automatique
Je vais utiliser PyCaret en Python pour la formation et le développement d'un pipeline d'apprentissage automatique qui sera utilisé dans le cadre de notre application web. Vous pouvez utiliser le cadre de votre choix car les étapes suivantes n'en dépendent pas.
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# init environment
from pycaret.regression import *
r1 = setup(insurance, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
# train a model
lr = create_model('lr')
# save pipeline/model
save_model(lr, model_name = 'c:/username/pycaret-deployment-azure/deployment_28042020')
Lorsque vous enregistrez un modèle dans PyCaret, l'ensemble du pipeline de transformation est créé, sur la base de la configuration définie dans la fonction de configuration. Toutes les interdépendances sont orchestrées automatiquement. Voir le pipeline et le modèle stockés dans la variable 'deployment_28042020' :

Application web frontale
Ce tutoriel n'est pas axé sur la création d'une application Flask. Elle n'est évoquée ici que par souci d'exhaustivité. Maintenant que notre pipeline d'apprentissage automatique est prêt, nous avons besoin d'une application web qui peut lire notre pipeline formé, pour prédire de nouveaux points de données. Cette demande comporte deux parties :
- Front-end (conçu à l'aide de HTML)
- Back-end (développé avec Flask)
Voici à quoi ressemble l'interface :
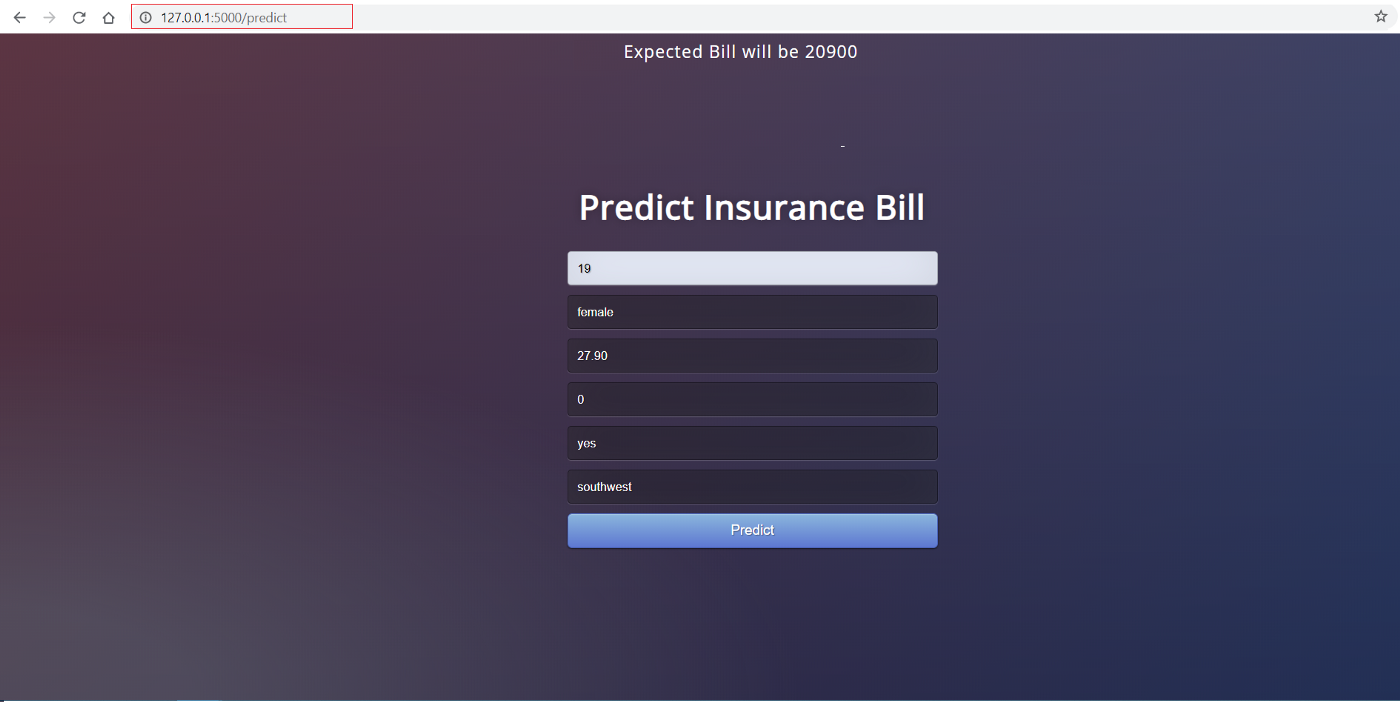
La partie frontale de cette application est constituée d'un simple code HTML et de quelques feuilles de style CSS. Si vous souhaitez vérifier le code, veuillez consulter ce repo. Maintenant que nous avons une application web entièrement fonctionnelle, nous pouvons commencer le processus de conteneurisation de l'application à l'aide de Docker.
Le back-end de l'application
Le back-end de l'application est un fichier Python nommé app.py. Il est construit en utilisant le framework Flask.
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('deployment_28042020')
cols = ['age', 'sex', 'bmi', 'children', 'smoker', 'region']
@app.route('/')
def home():
return render_template("home.html")
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('home.html',pred='Expected Bill will be {}'.format(prediction))
@app.route('/predict_api',methods=['POST'])
def predict_api():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
if __name__ == '__main__':
app.run(debug=True)
Conteneur Docker
Si vous utilisez Windows, vous devrez installer Docker pour Windows. Si vous utilisez Ubuntu, Docker est livré par défaut et aucune installation n'est nécessaire.
La première étape de la conteneurisation de votre application consiste à écrire un fichier Docker dans le même dossier/répertoire que celui où réside votre application. Un Dockerfile est simplement un fichier contenant un ensemble d'instructions. Le fichier Docker pour ce projet ressemble à ceci :
FROM python:3.7
RUN pip install virtualenv
ENV VIRTUAL_ENV=/venv
RUN virtualenv venv -p python3
ENV PATH="VIRTUAL_ENV/bin:$PATH"
WORKDIR /app
ADD . /app
# install dependencies
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# run application
CMD ["python", "app.py"]
Dockerfile est sensible à la casse et doit se trouver dans le dossier du projet avec les autres fichiers du projet. Un fichier Docker n'a pas d'extension et peut être créé à l'aide de n'importe quel éditeur. Nous avons utilisé Visual Studio Code pour le créer.
Déploiement dans le cloud
Après avoir configuré correctement Dockerfile, nous allons écrire quelques commandes pour créer une image Docker à partir de ce fichier, mais d'abord, nous avons besoin d'un service pour héberger cette image. Dans cet exemple, nous utiliserons Microsoft Azure pour héberger notre application.
Registre de conteneurs Azure
Si vous n'avez pas de compte Microsoft Azure ou si vous ne l'avez jamais utilisé, vous pouvez vous inscrire gratuitement. Lorsque vous vous inscrivez pour la première fois, vous bénéficiez d'un crédit gratuit pendant les 30 premiers jours. Vous pouvez utiliser ce crédit pour créer et déployer une application web sur Azure. Une fois que vous vous êtes inscrit, suivez les étapes suivantes :
- Connectez-vous sur https://portal.azure.com
- Cliquez sur Créer une ressource
- Recherchez le registre des conteneurs et cliquez sur Créer.
- Sélectionnez Subscription, Resource group et Registry name (dans notre cas : pycaret.azurecr.io est notre nom de registre).
Une fois le registre créé, la première étape consiste à créer une image Docker à l'aide de la ligne de commande. Accédez au dossier du projet et exécutez le code suivant :
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .
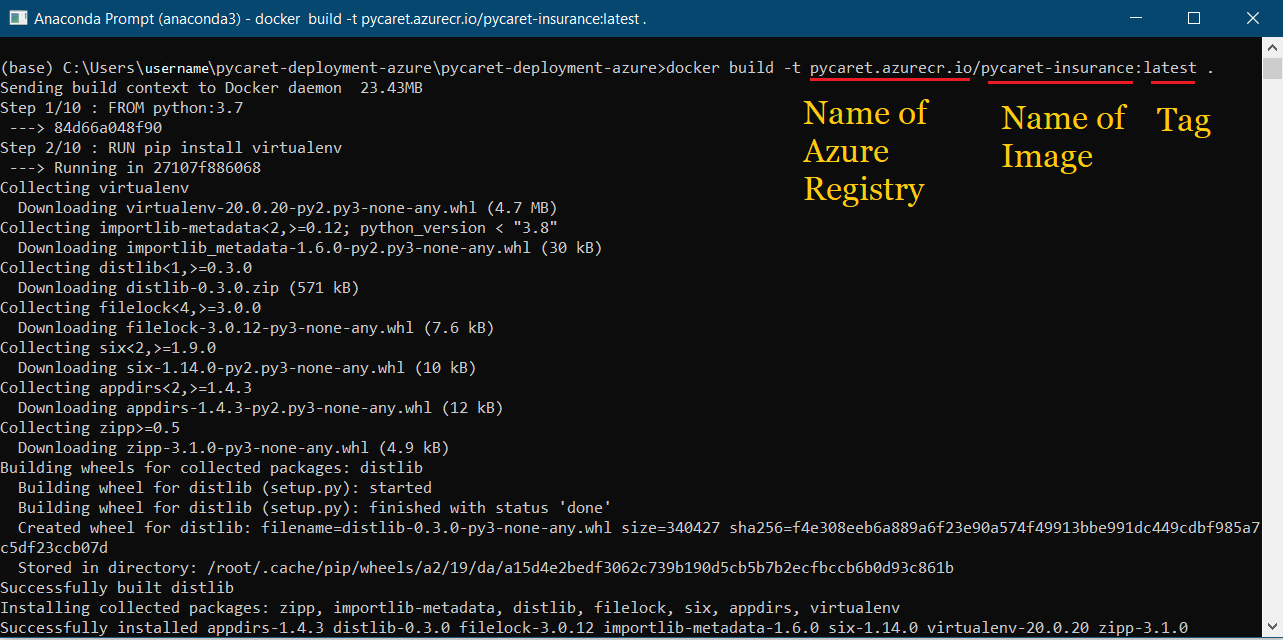
- pycaret.azurecr.io est le nom du registre que vous obtenez lorsque vous créez une ressource sur le portail Azure.
- pycaret-insurance est le nom de l'image et latest est la balise, qui peut être n'importe quoi.
Exécutez un conteneur à partir d'une image Docker
Maintenant que l'image est créée, nous allons exécuter un conteneur localement et tester l'application avant de l'envoyer au Azure Container Registry. Pour exécuter le conteneur localement, exécutez le code suivant :
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
Vous pouvez voir l'application en action en allant sur localhost:5000 dans votre navigateur internet. Une application web devrait s'ouvrir.
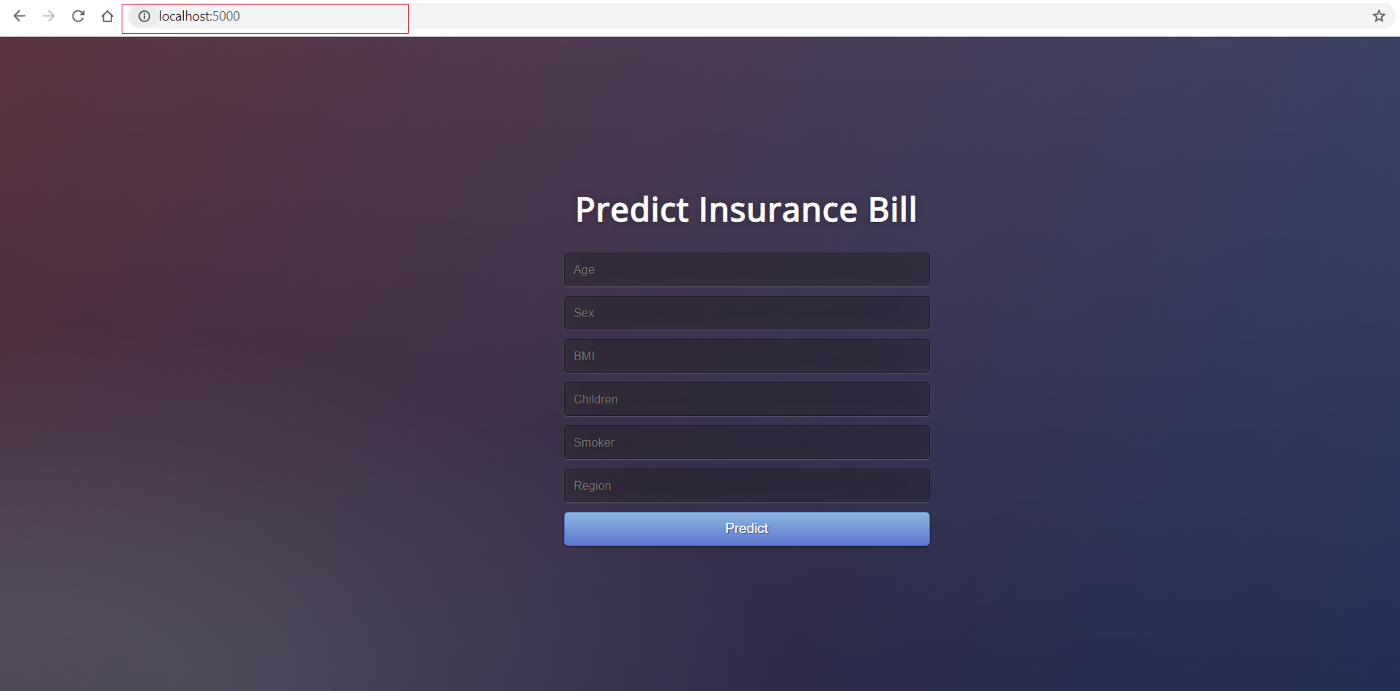
Si vous pouvez voir cela, cela signifie que l'application est maintenant opérationnelle sur votre machine locale et qu'il ne s'agit plus que de la pousser sur le cloud. Pour le déploiement sur Azure, lisez la suite :
Authentifier les informations d'identification Azure
Une dernière étape avant de pouvoir télécharger le conteneur sur ACR consiste à authentifier les informations d'identification azur sur votre machine locale. Pour ce faire, exécutez le code suivant dans la ligne de commande :
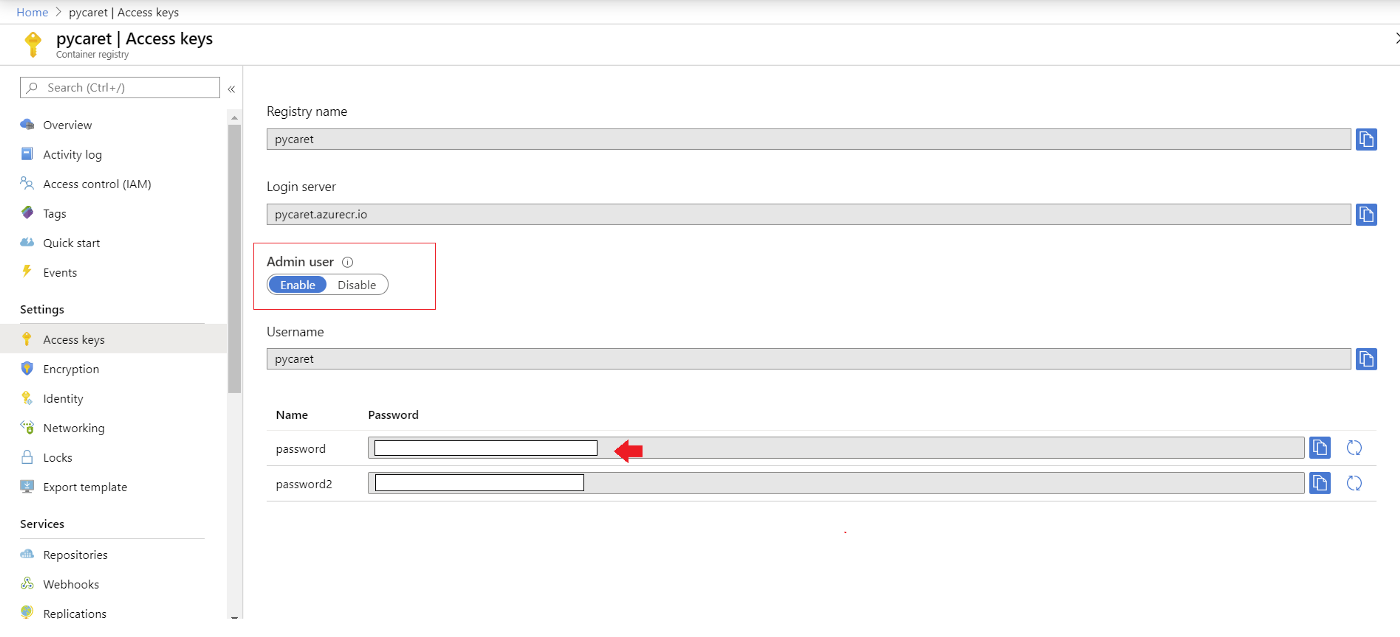
docker login pycaret.azurecr.io
Un nom d'utilisateur et un mot de passe vous seront demandés. Le nom d'utilisateur est le nom de votre registre (dans cet exemple, le nom d'utilisateur est "pycaret"). Vous trouverez votre mot de passe sous les clés d'accès de la ressource Azure Container Registry que vous avez créée.
Pousser le conteneur dans le registre des conteneurs Azure
Maintenant que vous vous êtes authentifié auprès d'ACR, vous pouvez pousser le conteneur que vous avez créé vers ACR en exécutant le code suivant :
docker push pycaret.azurecr.io/pycaret-insurance:latest
En fonction de la taille du conteneur, la commande push peut prendre un certain temps pour transférer le conteneur vers le cloud.
Application Web
Pour créer une application web sur Azure, procédez comme suit :
- Connectez-vous au portail Azure
- Cliquez sur créer une ressource
- Recherchez l'application web et cliquez sur créer
- Liez votre image ACR à votre application
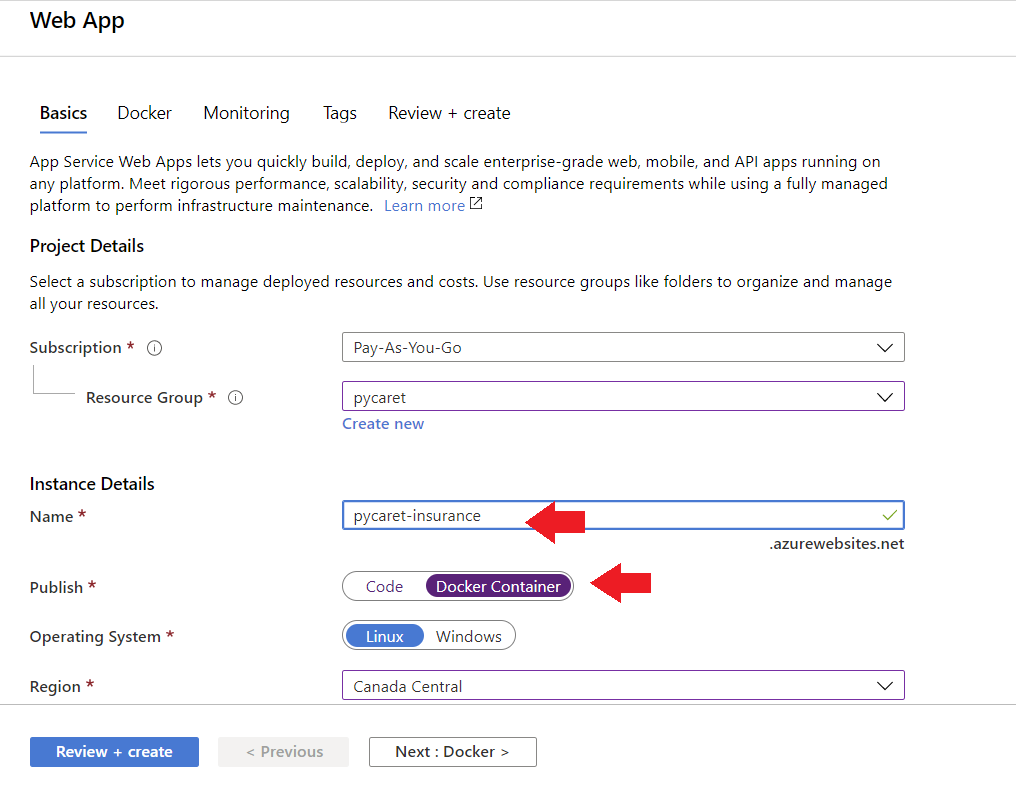
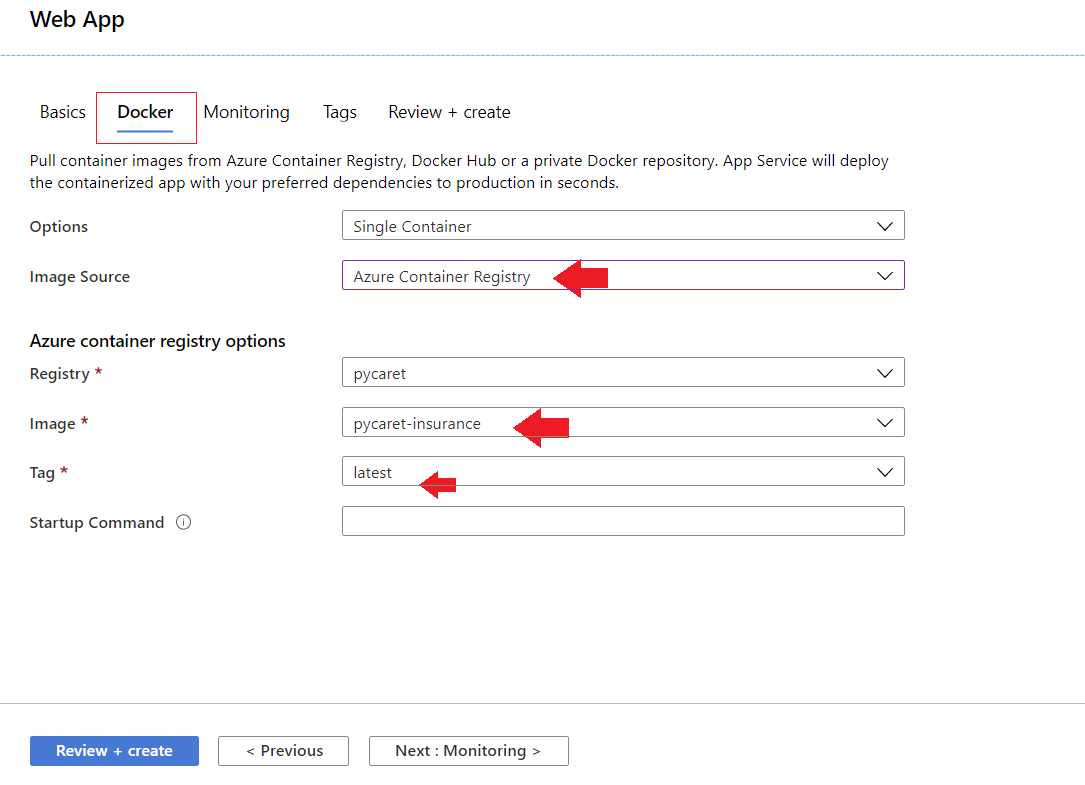
L'application est maintenant opérationnelle sur Azure Web Services.

Conclusion
Les MLOps permettent de s'assurer que les modèles déployés sont bien entretenus, qu'ils fonctionnent comme prévu et qu'ils n'ont pas d'effets négatifs sur l'entreprise. Ce rôle est crucial pour protéger l'entreprise contre les risques liés à des modèles qui dérivent au fil du temps, ou qui sont déployés mais non maintenus ou non surveillés.
Les MLOps sont en tête du classement des emplois émergents de LinkedIn, avec une croissance enregistrée de 9,8 fois en cinq ans.
Vous pouvez consulter le nouveau cursus de compétences MLOps Fundamentals à DataCamp, qui couvre le cycle de vie complet d'une application d'apprentissage automatique, allant de la collecte des besoins de l'entreprise aux étapes de conception, de développement, de déploiement, d'exploitation et de maintenance. Datacamp propose également un cours étonnant sur la compréhension de l'ingénierie des données. Inscrivez-vous dès aujourd'hui pour découvrir comment les ingénieurs de données jettent les bases de la science des données, sans avoir à coder.