
Kurs
Einführung in Spark SQL mit Python
4 Std.
20.3K
Lastverteilung ist ein Konzept, das man an mehr Orten findet, als man denkt.
Stell dir einen Samstagmorgen in einem vollgepackten Supermarkt vor, wo nur eine Kasse offen ist. Fünfzehn Leute stehen Schlange, alle sind genervt, und der arme Kassierer sieht aus, als würde er jede Entscheidung in seinem Leben, die zu diesem Moment geführt hat, überdenken. Die Spannung steigt richtig, als plötzlich drei Mitarbeiter auftauchen, ein paar weitere Kassen öffnen und die Leute zu den kürzesten Warteschlangen leiten. Alles wird schneller, der Druck lässt nach und die Schlangen fangen an, sich normal zu bewegen. Das ist im Grunde genommen Lastenausgleich.
In diesem Artikel erkläre ich dir, was Lastenausgleich ist, warum er wichtig ist, wie er im Hintergrund funktioniert und wie er verhindert, dass die digitale Welt zusammenbricht, wenn viel los ist. Du brauchst keine besonderen Kenntnisse, um diesem Artikel folgen zu können. Also mach dir keine Sorgen, wenn du dich nicht so gut mit Netzwerken oder Cloud-Architekturen auskennst! Dieser Leitfaden ist übersichtlich, praktisch und (hoffentlich) ein bisschen unterhaltsam.
In der Technik ist Lastenausgleich, wie wir eingehenden Datenverkehr oder Aufgaben auf mehrere Server oder Ressourcen verteilen. Anstatt eine Maschine mit der ganzen Last zu überfordern, verteilt ein Load Balancer die Arbeit, damit alles schnell, stabil und skalierbar bleibt. Es ist überall in der modernen Infrastruktur zu finden: Cloud-Plattformen nutzen es, um Millionen von Nutzern zu verwalten, KI-Pipelines verlassen sich darauf, um Datenlasten auf Knoten zu verteilen, und E-Commerce-Websites setzen darauf, um den Black Friday zu überstehen.
Stell dir mal kurz vor, deine App hätte keinen Load Balancer. Ein Server kriegt alle Anfragen, den ganzen Datenverkehr und den ganzen Druck ab. Vielleicht hält es eine Weile an, bis es (unvermeidlich) nicht mehr so ist. Es wird langsamer, die Leute werden genervt, vielleicht stürzt es sogar komplett ab. In der Zwischenzeit drehen die anderen Server Däumchen und machen einfach nichts.
Ohne Lastenausgleich bist du im Grunde genommen auf Folgendes angewiesen:
Jetzt schmeiß mal einen Load Balancer dazu, und schon sieht alles ganz anders aus. Es sitzt vor deinen Backend-Servern, behält im Auge, wie jeder einzelne läuft, und verteilt eingehende Anfragen an den Server, der am besten läuft oder am wenigsten ausgelastet ist. Manche checken sogar Sachen wie Reaktionszeit oder Serverressourcen in Echtzeit.
Das kriegst du:
Wenn du immer noch an das Beispiel aus dem Supermarkt denkst, stell dir vor, dass die Schlange mit 15 Leuten clever auf fünf Kassen verteilt wird. Niemand flippt aus, niemand schreit rum, und du kommst schneller zum Regal mit den Tiefkühlpizzen. Das ist das Ziel.
Also, wir haben darüber geredet, warum Lastenausgleich bei „ “ nützlich ist. Schauen wir uns jetzt mal an,wie „ “ eigentlich funktioniert.
Auf hoher Ebene sitzt ein Load Balancer zwischen den Clients (Personen oder Systeme, die Anfragen stellen) und deinen Backend-Servern (die die Arbeit erledigen). Seine Aufgabe ist es, jede eingehende Anfrage zu empfangen und zu entscheiden, wohin sie weitergeleitet werden soll.
Hier ist der grundlegende Ablauf:
Theoretisch ziemlich einfach, aber hinter den Kulissen passiert eine Menge, und es gibt ein paar wichtige Konzepte, die dafür sorgen, dass alles funktioniert:
Kleine Anmerkung am Rande: „Lastenausgleich“ ist das Konzept (Verteilung des Datenverkehrs), und ein „Lastenausgleichs “ ist das Tool oder der Dienst, der das möglich macht. Man hört oft, dass beide Begriffe gleich verwendet werden, aber es ist gut, den Unterschied zu kennen.
Auch wenn Load Balancer manchmal einfach einen Server nach dem Zufallsprinzip auswählen, gibt es doch Strategien, die als Load-Balancing-Algorithmen bezeichnet werden und die bestimmen, wie der eingehende Datenverkehr auf die Backend-Ressourcen verteilt wird.
Einige davon sind ziemlich einfach und vorhersehbar, während andere sich in Echtzeit je nach Serverleistung, Anzahl der Verbindungen oder Antwortgeschwindigkeit anpassen. Teilen wir sie mal in zwei große Kategorien ein.
Die passen sich nicht an das Geschehen im System an, sondern folgen einfach einer festgelegten Regel. Das macht sie berechenbar und einfach umzusetzen, aber unter realem Druck nicht immer ideal.
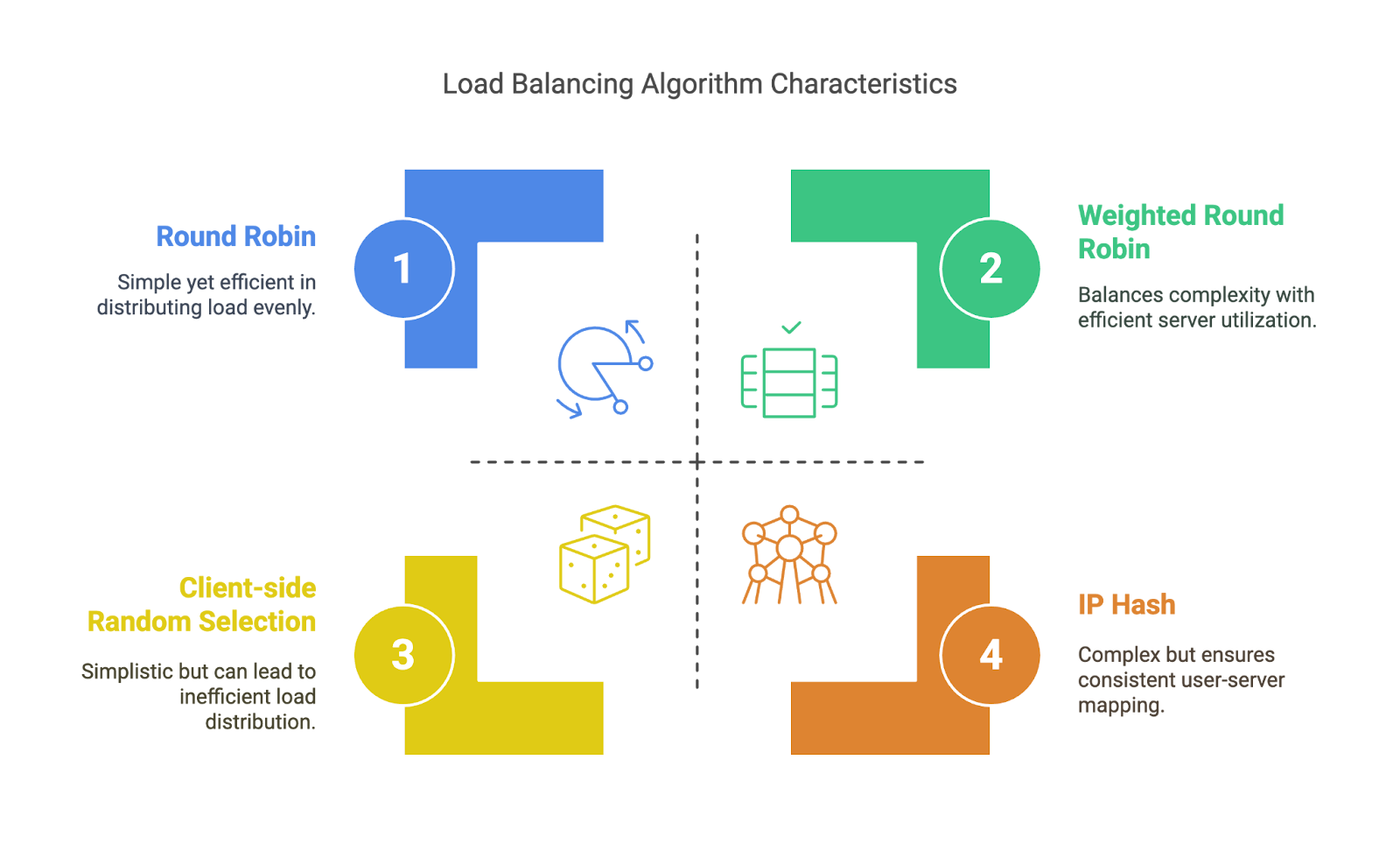
Statische Algorithmen. Bild vom Autor
Diese Algorithmen passen sich an, je nachdem, was im System gerade passiert. Sie sind schlauer, brauchen aber mehr Überwachung und Systemkenntnisse.
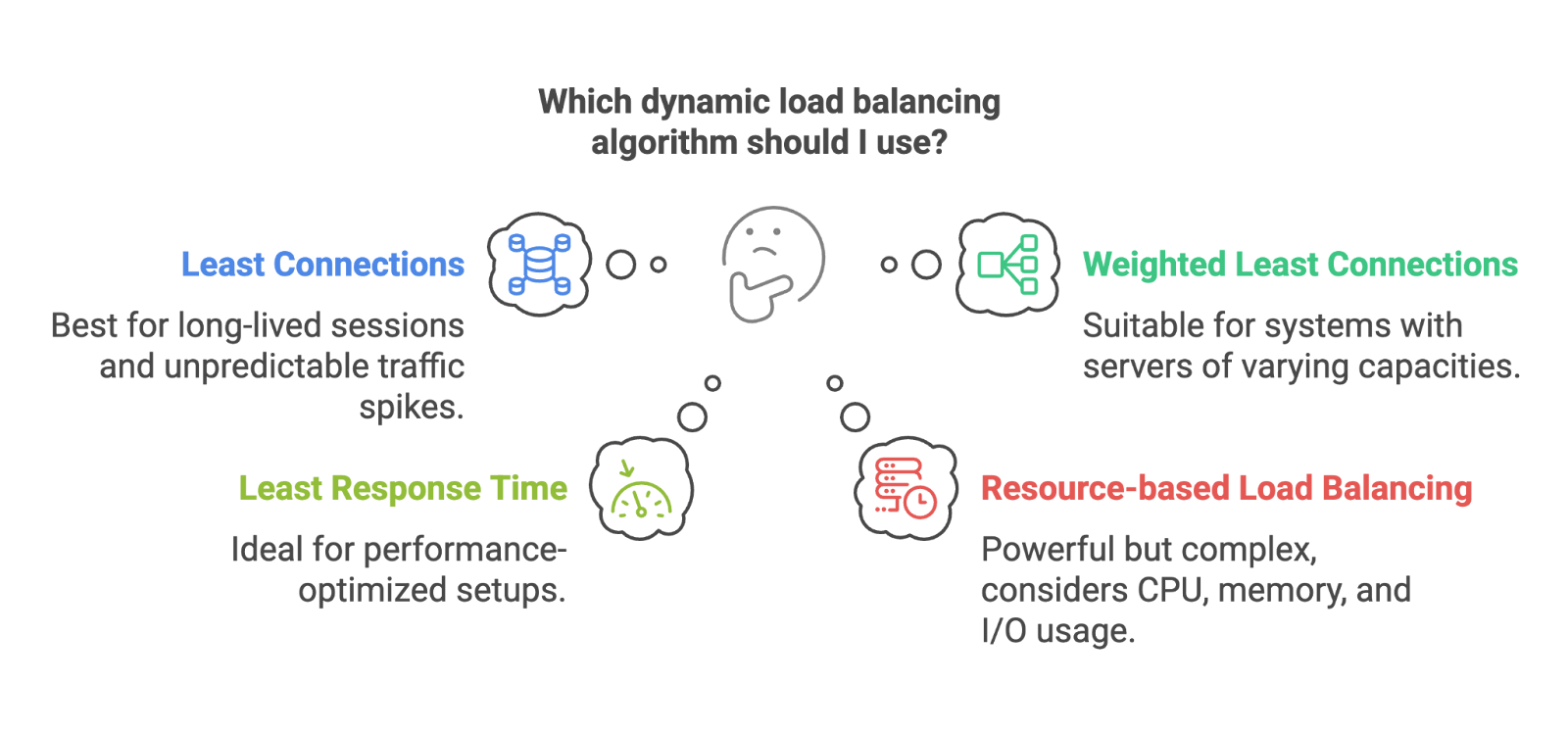
Dynamische Algorithmen. Bild vom Autor
Statische Algorithmen sind super, wenn dein Datenverkehr vorhersehbar ist und deine Server gleichmäßig verteilt sind. Dynamische Algorithmen sind super, wenn es mal etwas chaotischer zugeht.
Okay, jetzt reden wir mal über die verschiedenen Arten von Load Balancern: Hardware, Software, Cloud-native und mehr.
Nicht alle Load Balancer sind gleich. Einige laufen auf Hardware, andere als Software, manche sind mit Cloud-Diensten verbunden und wieder andere sind auf ganz bestimmte Anwendungsfälle spezialisiert. Welches du nimmst, hängt von deiner Architektur, deiner Größe und manchmal einfach von deinem Budget ab.
Das sind physische Geräte, die in deinem Rechenzentrum stehen und speziell dafür gemacht sind, den Datenverkehr auszugleichen. Sie sind leistungsstark und schnell, aber teuer und schwieriger nach Bedarf zu skalieren. Denk an große Unternehmen und lokale Installationen.
Die laufen als Anwendungen auf normalen Servern. T-ools wie HAProxy, nginx (gehört zu F5) oder Envoy sind in dieser Kategorie. Sie sind günstiger, flexibler und lassen sich leichter indie meisten Umgebungen einbinden.
Wenn du AWS, Azure oder GCP nutzt, verwendest du wahrscheinlich schon einen Cloud-nativen Load Balancer wie AWS ELB, Azure Load Balancer oder GCP Load Balancing. Sie werden für dich verwaltet, passen sich automatisch an und lassen sich super mit anderen Diensten verbinden.
Wenn du wissen willst, wie AWS das macht (und noch ein paar andere Infrastruktur-Sachen), schau dirunserenKurs „AWS Cloud Technology and Services Concepts“ an.
Du hast vielleicht schon mal von elastischen Lastenausgleichern gehört. Die sind so gemacht, dass sie sich je nach deinem Arbeitspensum vergrößern oder verkleinern lassen. Sie sind oft Teil von Cloud-nativen Systemen, aber „elastisch“ heißt einfach, dass sie sich dynamisch an den Datenverkehr anpassen können, was super für unregelmäßige oder unvorhersehbare Lasten ist.
Das OSI-Modell ist ein Konzept, das zeigt, wie Daten durch ein Netzwerk fließen. Es hat sieben Schichten, vom physischen Kabel bis hin zur App in deinem Browser. Für die Lastverteilung sind die wichtigsten Schichten die Schichten 4 und 7.
Die treffen Routing-Entscheidungen anhand von IP-Adressen, Ports und TCP/UDP-Datenverkehr. Sie sind schnell und effizient, wissen aber nichts über den Inhalt der gesendeten Daten.
Diese schauen sich den eigentlichen Inhalt der Anfrage an, wie HTTP-Header, Cookies oder URLs. Dadurch können sie fortgeschrittenere Sachen machen, wie Routing basierend auf dem URL-Pfad, A/B-Tests oder Spracheinstellungen. Wenn du zum Beispiel möchtest, dass Anfragen an /api/ an einen Cluster und Anfragen an /login an einen anderen Cluster weitergeleitet werden, brauchst du Layer 7.
Wird benutzt, um den Datenverkehr auf geografisch verteilte Rechenzentren zu verteilen. Nützlich für Setups in mehreren Regionen, mit geringer Latenz oder für die Notfallwiederherstellung.
Funktioniert komplett in privaten Netzwerken und wird benutzt, um den Datenverkehr zwischen Diensten in einer Cloud oder einem Cluster auszugleichen.
Spezialisiert auf Telekommunikationssysteme, die das Diameter-Protokoll nutzen, das man oft in Mobilfunknetzen für Routing, Authentifizierung und Abrechnungsanfragen findet.
Die sind extra für den Umgang mit HTTP- und HTTPS-Datenverkehr gemacht. Sie haben oft SSL-Terminierung, URL-basiertes Routing und einen eingebauten DDoS-Schutz.
Jeder Typ von Load Balancer löst ein anderes Problem. Einige konzentrieren sich auf die Skalierbarkeit, andere auf die Latenz, die Sicherheit oder die Benutzerfreundlichkeit. Zu wissen, welches man wählen soll, kann einen großen Unterschied machen, wie reibungslos (oder mühsam) der Betrieb deiner Infrastruktur ist.
Bis jetzt haben wir darüber geredet, was Load Balancer machen und welche Typen es gibt, aber wie sind sie eigentlich aufgebaut? Die Architektur eines Lastenausgleichssystems beeinflusst alles, von der Skalierbarkeit bis hin zur Fehlerbehandlung.
Das ist die klassische Konfiguration: Ein „Leader“-Knoten trifft die Entscheidungen und verteilt die Arbeit an mehrere „Worker“-Knoten. Es ist einfach und leicht zu verstehen, aber der Anführer kann zum Engpass oder zur Schwachstelle werden, wenn er nicht richtig unterstützt wird.
Statt nur einem zentralen Gehirn weiß jeder Load Balancer, wo seine Kollegen sind, undteilt die Arbeit auf. Das macht die Fehlertoleranz und Skalierbarkeit besser, aber die Koordination wird dadurch etwas komplizierter. Das sieht man oft in großen Systemen mit Anycast-Routing oder DNS-basierter Verteilung.
In Container-Umgebungen, vor allem mit Kubernetes, wird Load Balancing noch spannender. Services, Ingress-Controller und Sidecars arbeiten zusammen, um den Datenverkehr innerhalb von Clustern clever zu leiten. Wenn du gerade erst in diese Welt einsteigst, ist unser Kurs „Einführung in Kubernetes“ eine gute Möglichkeit, die Grundlagen praktisch zu erlernen.
In dieser Situation können Leute, die gerade nichts zu tun haben, Aufgaben von denen „klauen“, die viel zu tun haben. Es wird oft in rechenintensiven Umgebungen wie Aufgabenwarteschlangen oder Datenverarbeitungs-Pipelines benutzt, aber nicht so oft für Web-Traffic. Das ist ein praktisches Muster, um unvorhersehbare Arbeitslasten auszugleichen.
Manche Systeme haben mehrere Load Balancer, zum Beispiel einen auf globaler Ebene (z. B. über Regionen hinweg), einen anderen auf Rechenzentrumsebene und einen dritten innerhalb eines bestimmten Service-Clusters. Das hilft dabei, die Komplexität zu bewältigen, und sorgt dafür, dass jede Ebene auf einen bestimmten Bereich fokussiert bleibt.
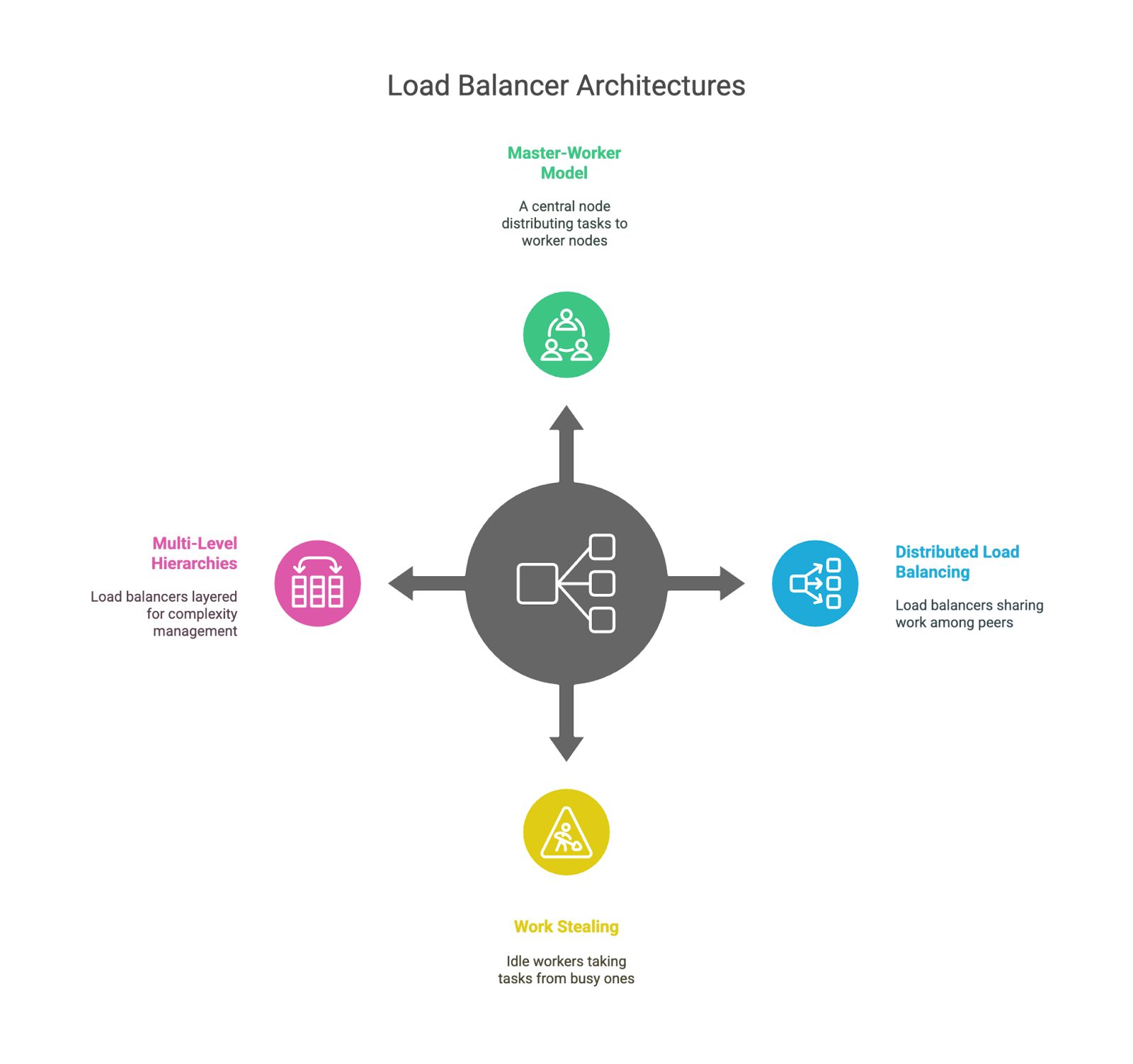
Lastverteilungsarchitekturen.
Jede dieser Architekturen hat ihre Vor- und Nachteile. Zentrale Modelle sind einfach zu verstehen, können aber zu Engpässen führen. Verteilte Modelle lassen sich besser skalieren, machen die Sache aber komplizierter. Schichtbasierte Topologien bieten Modularität, können aber zu Verzögerungen führen, wenn sie nicht sorgfältig geplant werden. Wie immer gibt's keine allgemeingültige Antwort. Das hängt von der Größe deines Systems, den Datenverkehrsmustern und deiner Risikotoleranz ab.
Lastverteilung ist echt stark, aber es ist keine Zauberei. Es kann Systeme zwar zuverlässiger, skalierbarer und effizienter machen, führt aber auch zu neuer Komplexität und möglichen Fehlerquellen. Reden wir mal über ein paar der Kompromisse, die Ingenieure eingehen müssen, sowohl technisch als auch betrieblich.
Ironischerweise kann genau das Tool, das den Datenverkehr verteilen soll, zu einem Single Point of Failure werden, wenn es nicht richtig aufgebaut ist, vor allem in zentralisierten oder leaderbasierten Modellen. Deshalb nutzen viele Systeme mehrere Load Balancer, Failover-Mechanismen oder sogar DNS-Level-Balancing, um das Risiko zu verteilen.
Egal wie schnell er ist, ein Load Balancer fügt immer noch einen Hop zwischen dem Client und dem Backend hinzu. Das kann zu Verzögerungen führen, vor allem bei mehrschichtigen Architekturen oder beim Routing auf Anwendungsebene (Layer 7).
HTTPS-Datenverkehr auf der Ebene des Lastenausgleichs verarbeiten (auch bekannt als SSL-Terminierung) kann die CPU-Last von Backend-Servern verringern, aber das heißt auch, dass der Load Balancer mehr zu tun hat und für sensible Sicherheitseinstellungen und Zertifikate verantwortlich ist.
Sticky Sessions sind praktisch, um Nutzer am selben Backend zu halten (wie beim Einloggen), aber sie machen das Skalieren komplizierter und erschweren den Betrieb komplett zustandsloser Dienste. Ingenieure müssen sich oft zwischen Benutzerfreundlichkeit und architektonischer Eleganz entscheiden.
Je cleverer deine Routing-Logik ist, desto mehr Platz gibt's für Fehler, falsche Weiterleitungen oder kleine Performance-Probleme, die schwer zu finden sind. Du wirst dich schlau fühlen, wenn du es einrichtest, und viel weniger schlau, wenn du um 2 Uhr morgens geweckt wirst, um Probleme mit dem Health Check zu beheben.
Jede Anwendung verhält sich unter Last anders. Die Entscheidung zwischen statischen und dynamischen Algorithmen und das Einstellen von Sachen wie Verbindungsschwellenwerten oder Intervallen für Zustandsprüfungen kann viel Ausprobieren, Fehler und Erfahrung erfordern.
Wenn was schiefgeht, sucht der Load Balancer an einem anderen Ort. Falsch konfigurierte Routen, verlorene Anfragen, Caching-Ebenen oder widersprüchliche Ergebnisse von Zustandsprüfungen können alles durcheinanderbringen.
Wenn dein Load Balancer SSL verarbeitet, musst du sicherstellen, dass er richtig konfiguriert, gepatcht und überwacht wird. Jeder Fehler kann Schwachstellen schaffen oder die sichere Kommunikation beeinträchtigen.
Das hängt irgendwie mit dem zusammen, was wir über die zusätzliche Komplexität gesagt haben. Du brauchst starke Protokollierung, Metriken und Nachverfolgung, um zu verstehen, wie Anfragen durch das System fließen. Ohne gute Beobachtbarkeit kann ein fehlerhafter Load Balancer schwer zu erkennen und noch schwerer zu beheben sein.
Nur um das klarzustellen: Keiner dieser Punkte ist ein Grund , Load Balancingnicht zu nutzen. Das ist einfach die Realität beim Aufbau robuster Systeme: Jede zusätzliche Ebene kann helfen, bringt aber auch neue Herausforderungen mit sich, die es zu bewältigen gilt.
Wie alles in der Technik entwickelt sich auch die Lastverteilung weiter. Da Systeme immer komplexer, verteilter und dynamischer werden, stoßen traditionelle Ansätze an ihre Grenzen, und neue Strategien werden ausprobiert.
Das ist angesichts des globalen Technologietrends ziemlich offensichtlich. Moderne Plattformen fangen an, maschinelles Lernen zu integrieren, um Verkehrsmuster vorherzusagen und intelligentere Routing-Entscheidungen zu treffen. Anstatt nur auf die aktuelle Auslastung zu reagieren, können diese Systeme Spitzen (wie eine Produkteinführung oder aktuelle Nachrichten) vorhersagen und den Datenverkehr im Voraus anpassen. Es ist noch früh, aber das Potenzial für selbstoptimierende Infrastruktur ist echt.
Wenn du dich mit diesem Thema beschäftigen möchtest,ist unser Tutorialzu maschinellem Lernen, Pipelines, Bereitstellung und MLOps ein guter Einstieg.
Herkömmliche Load Balancer wissen nicht wirklich, was deine App macht; sie schauen nur auf den Datenverkehr. Die anwendungsorientierte Lastverteilung geht noch weiter. Es kann Entscheidungen treffen, je nachdem, wer der Nutzer ist, was für ein Gerät er benutzt oder wie wichtig die Anfrage für das Unternehmen ist. Zum Beispiel könnte es angemeldete Nutzer bei einem Anstieg priorisieren oder sensiblen Datenverkehr zu Clustern mit höherer Sicherheit umleiten.
Da Unternehmen ihre Arbeitslasten auf mehrere Cloud-Anbieter verteilen (oder On-Premise-Lösungen mit Cloud-Lösungen kombinieren), passen sich Load Balancer an. Sie müssen standortbewusster sein, Cloud-übergreifendes Failover unterstützen und das Routing zwischen ganz unterschiedlichen Umgebungen verwalten. Rechne damit, dass es in diesen Setups mehr globale Traffic-Direktoren und DNS-Level-Orchestrierung geben wird.
Mit dem Aufkommen von Edge-Computing rückt die Lastverteilung näher an den Nutzer heran. Anstatt alles über eine zentrale Cloud zu leiten, werden Anfragen von Edge-Knoten bedient, was die Latenz deutlich reduziert. Die Lastverteilung am Rand muss leicht, clever und superlokal sein.
Einige Versuchsplattformen probieren gerade aus, wie man mit Agenten die Lastverteilung regeln kann. Dabei helfen einzelne Dienste dabei zu entscheiden, wie der Datenverkehr fließen soll, basierend auf dem, was sie vor Ort sehen. Es ist dezentraler und kann schnell auf kleine Veränderungen reagieren, bringt aber auch Herausforderungen bei der Koordination mit sich.
Ich denke, es ist ziemlich klar, dass all diese Trends auf eins hindeuten: dynamischeres, intelligenteres und kontextbewussteres Load Balancing. Die Zeiten des einfachen Round-Robin-Routings sind noch nicht vorbei (warum etwas wegwerfen, das funktioniert?), aber langsam kommen Systeme dazu, die lernen, sich anpassen und Echtzeitentscheidungen treffen, die auf viel mehr als nur der Serverauslastung basieren.
In diesem Artikel haben wir uns angesehen, was Lastenausgleich ist, warum er wichtig ist und wie er im Hintergrund funktioniert. Wir haben über Algorithmen, Architekturen und reale Anwendungen gesprochen und hoffentlich dazu beigetragen, dass das Ganze jetzt ein bisschen weniger geheimnisvoll wirkt. Ich hoffe, dieser Artikel hat dir ein klareres Bild davon gegeben, wie alles zusammenhängt!
Wenn du mehr wissen willst, melde dich als nächsten Schritt für unsere speziellen Kurse an. Ich empfehle, unseren Einführungskurs zu Kubernetes und unseren Kurs zu AWS Cloud-Technologie und -Dienstkonzepten.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Allan Ouko
Tutorial
Stephen Gruppetta

