
Course
Introduction to Spark SQL in Python
4 hr
20.4K
Load balancing is a concept that shows up in more places than you’d expect.
Take a Saturday morning in a packed supermarket with only one open checkout. Fifteen people are queued up, everyone’s annoyed, and the poor cashier looks like they’re reconsidering every life decision that led to this moment. The tension is really starting to build up when 3 members of staff suddenly show up, open a few more lanes, and start directing people to the shortest queues. Everything speeds up, the pressure eases, and the lines start moving normally. That, in essence, is load balancing.
In this article, I’ll walk you through what load balancing is, why it matters, how it works under the hood, and how it keeps the digital world from falling apart when things get busy. You don’t need any particular knowledge to follow this article, so don’t worry if you’re not deep into networking or cloud architecture! This guide will keep things clear, practical, and (hopefully) a little fun.
In tech, load balancing is how we distribute incoming traffic or tasks across multiple servers or resources. Instead of letting one machine drown under the weight of it all, a load balancer spreads the work out so things stay fast, stable, and scalable. It’s everywhere in modern infrastructure: cloud platforms use it to handle millions of users, AI pipelines rely on it to spread data loads across nodes and ecommerce sites count on it to survive Black Friday.
Let’s imagine, just for a second, that your app has no load balancer. One server gets all the requests, all the traffic, all the pressure. Maybe it keeps up for a while, until (inevitably) it doesn’t. It slows down, users get frustrated, maybe it crashes altogether. Meanwhile, the other servers are twiddling their digital thumbs, doing nothing.
Without load balancing, you’re essentially stuck with:
Now, throw in a load balancer, and things look very different. It sits in front of your backend servers, keeping an eye on how each one is doing and distributing incoming requests to whichever is healthiest or least busy. Some even monitor things like response time or server resources in real time.
Here’s what you get:
If you’re still thinking about the supermarket example, imagine that queue of 15 people being intelligently split between five checkouts. No one’s panicking, no one’s yelling, and you get to the frozen pizza aisle faster. That’s the goal.
So, we’ve talked about why load balancing is useful. Now let’s look at how it actually works under the hood.
At a high level, a load balancer sits between the clients (people or systems making requests) and your backend servers (the ones doing the work). Its job is to receive each incoming request and decide where to send it.
Here’s the basic flow:
Pretty straightforward in theory, but there’s a lot happening behind the scenes, and there are a few key concepts that ensure it all works:
Quick side note: “load balancing” is the concept (distributing traffic), and a “load balancer” is the tool or service that makes it happen. You’ll often hear both terms used interchangeably, but it helps to know the distinction.
Although sometimes load balancers just pick a server at random, there are actual strategies, called load balancing algorithms, that determine how incoming traffic is distributed across backend resources.
Some of these are pretty simple and predictable, while others adjust in real time based on server performance, connection count, or response speed. Let’s break them down into two broad categories.
These don’t adapt to what’s going on in the system; they just follow a predefined rule. That makes them predictable and easy to implement, but not always ideal under real-world pressure.
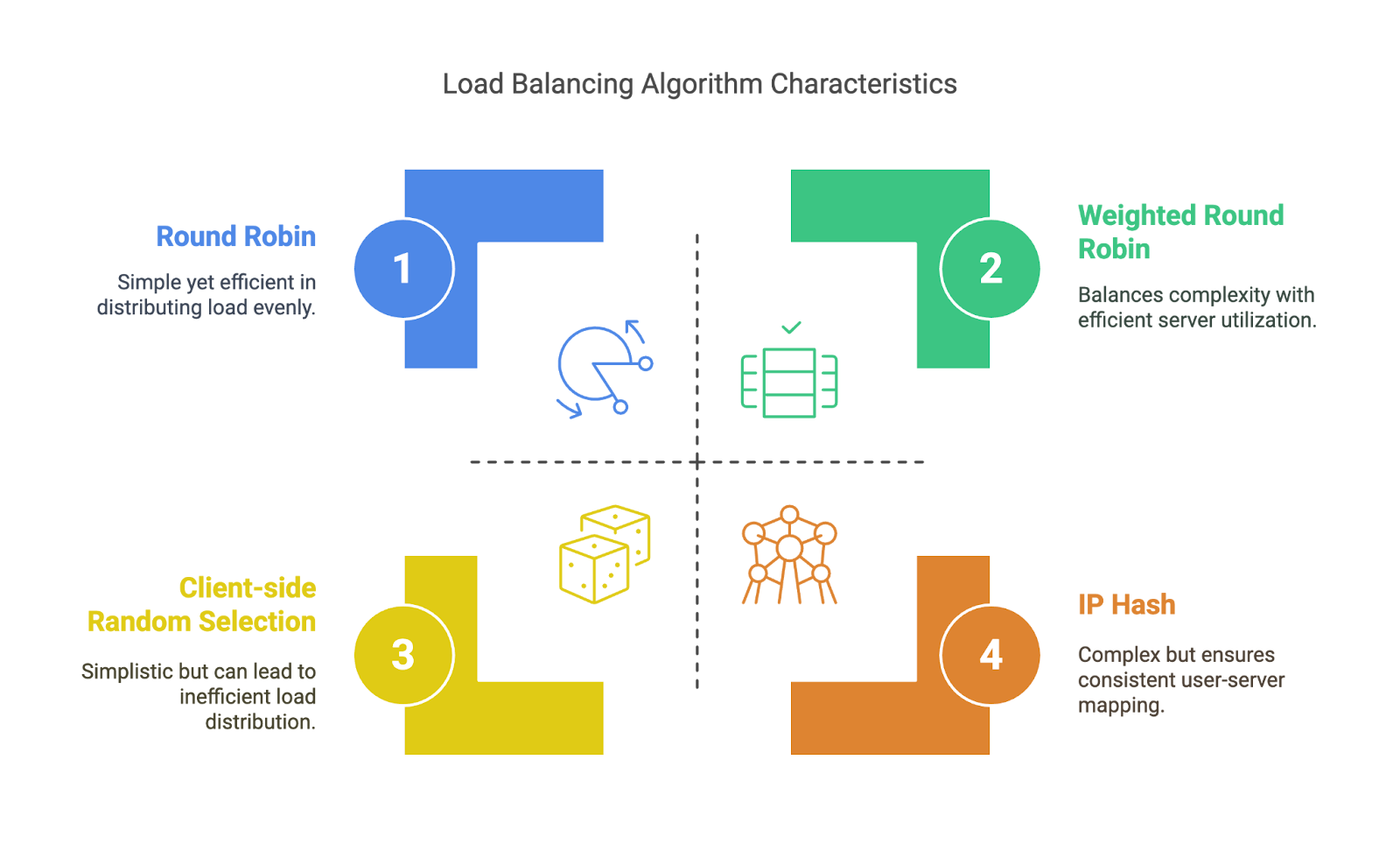
Static algorithms. Image by Author
These algorithms adapt based on what’s actually happening in the system. They’re smarter, but require more monitoring and system awareness.
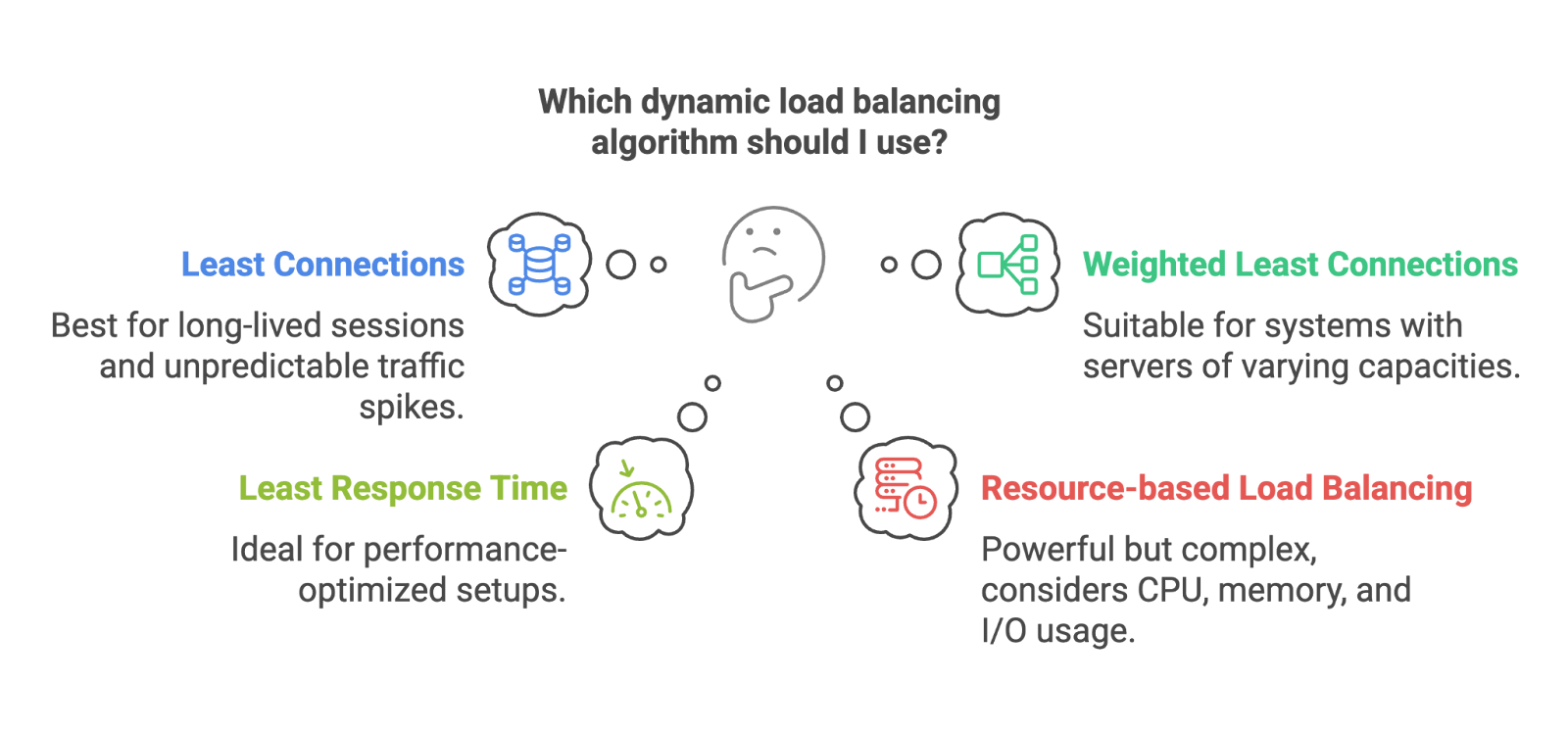
Dynamic algorithms. Image by Author
Static algorithms are great when your traffic is predictable and your servers are evenly matched. Dynamic algorithms shine when things are a little more chaotic.
Alright, now let’s talk about the different types of load balancers themselves: hardware, software, cloud-native, and more.
Not all load balancers are created equal. Some live in hardware, some run as software, some are bundled with cloud services, and some specialize in very specific use cases. Which one you use depends on your architecture, your scale, and sometimes just your budget.
These are physical appliances that sit in your data center, purpose-built to balance traffic. They’re powerful and fast, but expensive and harder to scale on demand. Think big enterprises and on-prem setups.
These run as applications on general-purpose servers. Tools like HAProxy, nginx (owned by F5), or Envoy fall into this category. They’re cheaper, more flexible, and easier to integrate into most environments.
If you’re using AWS, Azure, or GCP, you’re probably already using a cloud-native load balancer, like AWS ELB, Azure Load Balancer, or GCP Load Balancing. They’re managed for you, scale automatically, and integrate nicely with other services.
If you’re looking to get familiar with how AWS handles this (and a bunch of other infrastructure pieces), check out our AWS Cloud Technology and Services Concepts course.
You might have heard of elastic load balancers. These are designed to scale up and down with your workload. They’re often part of cloud-native systems, but the term “elastic” just means they can dynamically adapt to traffic, ideal for spiky or unpredictable loads.
The OSI model is a conceptual framework used to describe how data moves through a network. It has seven layers, from the physical wire all the way up to the app in your browser. For load balancing, the most relevant layers are layer 4 and 7.
These make routing decisions based on IP addresses, ports, and TCP/UDP traffic. They’re fast and efficient, but don’t know anything about the content being sent.
These look at the actual content of the request, like HTTP headers, cookies, or URLs. That lets them do more advanced things like routing based on URL path, A/B testing, or language preferences. For instance, if you want /api/ requests to go to one cluster and /login to go to another, you’ll need Layer 7.
Used to distribute traffic across geographically distributed data centers. Useful for multi-region, low-latency, or disaster recovery setups.
Operate entirely within private networks, used to balance traffic between services inside a cloud or cluster.
Specialized for telecom systems using the Diameter protocol, often found in mobile networks for routing, authentication, and billing requests.
These are optimized for handling HTTP and HTTPS traffic specifically. They often include SSL termination, URL-based routing, and built-in DDoS protection.
Each type of load balancer solves a different kind of problem. Some are focused on scale, others on latency, security, or ease of use. Knowing which one to pick can make a big difference in how smooth (or painful) your infrastructure is to run.
So far, we’ve talked about what load balancers do and the types you might use, but what about how they’re built under the hood? The architecture of a load-balancing system affects everything from how well it scales to how gracefully it handles failure.
This is the classic setup: one “leader” node makes the decisions and distributes work to multiple “worker” nodes. It’s simple and easy to reason about, but the leader can become a bottleneck or single point of failure if not backed up properly.
Instead of one central brain, each load balancer is aware of its peers and shares the work. This improves fault tolerance and scalability, but makes coordination a bit trickier. You’ll often see this in large-scale systems with anycast routing or DNS-based distribution.
In containerized environments, especially with Kubernetes, load balancing gets even more interesting. Services, ingress controllers, and sidecars all work together to route traffic smartly inside clusters. If you're just getting started with that world, our Introduction to Kubernetes course is a solid hands-on way to learn the basics.
In this setup, idle workers can “steal” tasks from busy ones. It’s commonly used in compute-heavy environments like task queues or data processing pipelines, but not so much for web traffic. It is a useful pattern for balancing unpredictable workloads.
Some systems layer their load balancers, like having one at the global level (e.g., across regions), another at the data center level, and a third within a specific service cluster. This helps manage complexity and keeps each layer focused on a specific scope.
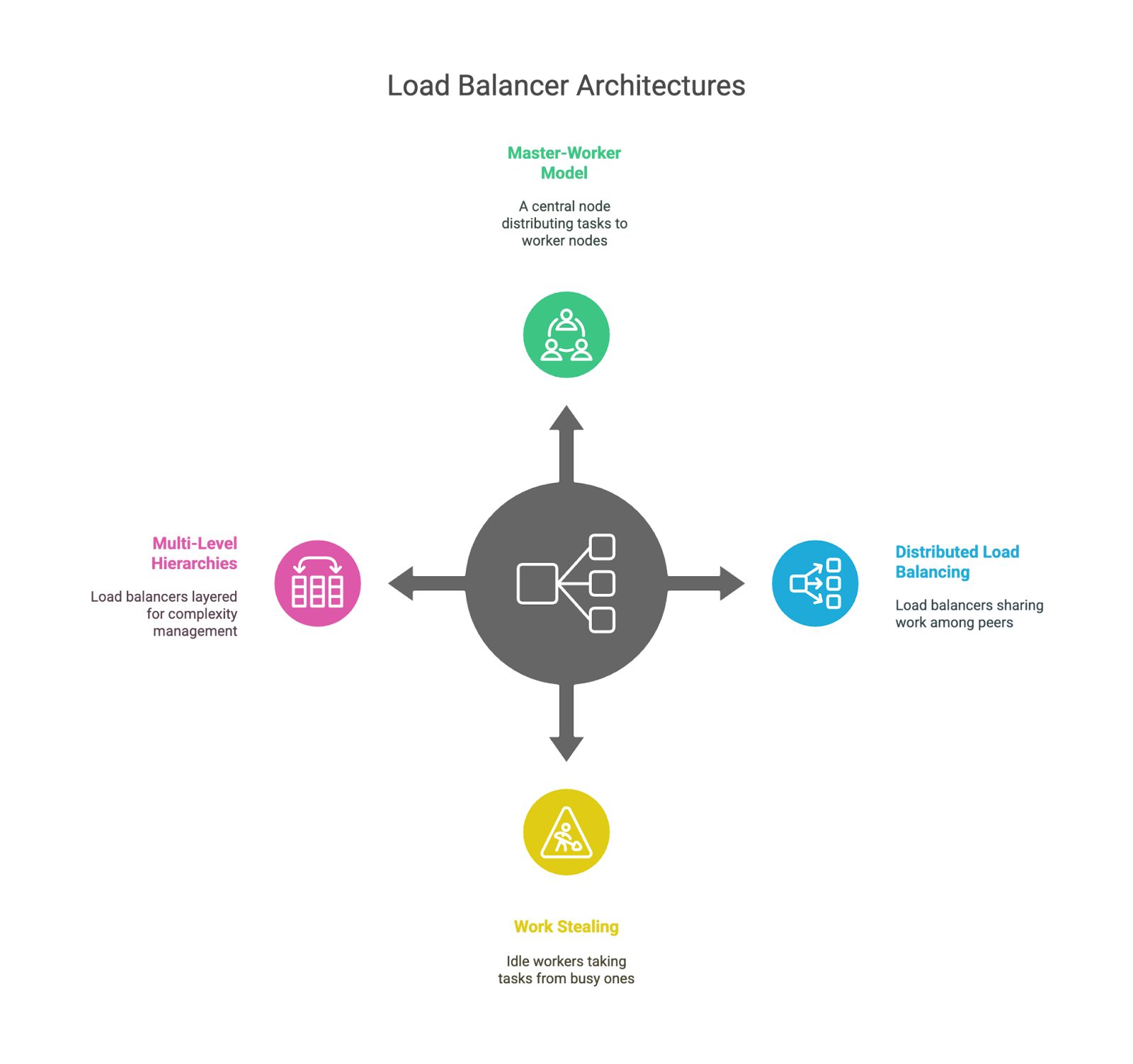
Load balancing architectures.
Each of these architectures has trade-offs. Centralized models are easy to understand but risk becoming chokepoints, distributed models scale better but add complexity, and layered topologies offer modularity but can introduce latency if not designed carefully. As usual, there’s no one-size-fits-all answer. It depends on your system’s size, traffic patterns, and tolerance for risk.
Load balancing is powerful, but it’s not magic. While it can make systems more reliable, scalable, and efficient, it also introduces new layers of complexity and potential failure points. Let’s talk about some of the trade-offs engineers run into, both technically and operationally.
Ironically, the very tool designed to distribute traffic can become a single point of failure if it’s not properly architected, especially in centralized or leader-based models. That’s why many systems use multiple load balancers, failover mechanisms, or even DNS-level balancing to distribute the risk.
No matter how fast it is, a load balancer still adds a hop between the client and the backend. That can introduce latency, especially in multi-layered architectures or with application-layer (Layer 7) routing.
Handling HTTPS traffic at the load balancer level (a.k.a. SSL termination) can offload CPU work from backend servers, but it also means the load balancer is doing more, and becomes responsible for sensitive security settings and certificates.
Sticky sessions are useful for keeping users tied to the same backend (like during login), but they complicate scaling and make it harder to run fully stateless services. Engineers often have to choose between user experience and architectural elegance.
The more intelligent your routing logic, the more room there is for bugs, misrouting, or subtle performance issues that are hard to trace. You’ll feel smart when you set it up, and a lot less when you’re being woken up at 2 a.m. to debug health check flakiness.
Each application behaves differently under load. Choosing between static or dynamic algorithms and tuning things like connection thresholds or health check intervals can take a lot of trial, error, and experience.
When something goes wrong, the load balancer adds another place to look. Misconfigured routes, dropped requests, caching layers, or inconsistent health check results can all muddy the waters.
If your load balancer is handling SSL, you need to make sure it’s correctly configured, patched, and monitored. Any misstep there can create vulnerabilities or break secure communication.
This is somewhat related to the point we made about added complexity. You need strong logging, metrics, and tracing to understand how requests flow through the system. Without good observability, a misbehaving load balancer can be hard to spot, and even harder to fix.
Just to be clear, none of these are reasons not to use load balancing. They’re just the reality of building resilient systems: every layer you add can help, but it also adds new challenges to manage.
Like everything in tech, load balancing is evolving. As systems become more complex, more distributed, and more dynamic, traditional approaches are being stretched, and new strategies are being trialed.
This is a pretty obvious one, given the global tech trend. Modern platforms are starting to integrate machine learning to predict traffic patterns and make smarter routing decisions. Instead of just reacting to current load, these systems can anticipate spikes (like a product launch or breaking news) and pre-adjust traffic flow. It’s still early days, but the potential for self-optimizing infrastructure is real.
If you want to explore that side of things, our tutorial on Machine Learning, Pipelines, Deployment and MLOps is a great starting point.
Traditional load balancers don’t really know what your app does; they just look at traffic. Application-aware load balancing digs deeper. It can make decisions based on user identity, device type, or the business importance of the request. For example, it might prioritize logged-in users during a spike or route sensitive traffic to higher-security clusters.
As companies spread workloads across multiple cloud providers (or mix on-prem with cloud), load balancers are adapting. They need to be more location-aware, support cross-cloud failover, and manage routing between very different environments. Expect to see more global traffic directors and DNS-level orchestration in these setups.
With the rise of edge computing, load balancing is shifting closer to the user. Instead of routing everything through a central cloud, requests are served from edge nodes, bringing latency way down. Load balancing at the edge has to be lightweight, smart, and hyper-local.
Some experimental platforms are exploring agent-based load balancing, where individual services help decide how traffic should flow based on what they’re seeing locally. It’s more distributed and can respond quickly to small-scale shifts, but it also introduces coordination challenges.
I think it is pretty clear that all these trends point toward one thing: more dynamic, intelligent, and context-aware load balancing. The days of simple round-robin routing are still alive and well (why throw away something that works?), but they’re starting to share the stage with systems that learn, adapt, and make real-time decisions based on far more than server load.
Throughout this article, we’ve looked at what load balancing is, why it matters, and how it works under the hood. We’ve talked about algorithms, architectures, and real-world applications, and hopefully, made it all feel a bit less mysterious in the process. I hope this article gave you a clearer picture of how it all fits together!
As a next step, if you are interested in learning more, enroll in our dedicated courses. I recommend our Introduction to Kubernetes course and our AWS Cloud Technology and Services Concepts course.
Learn with DataCamp
Course
Course
Course
blog
Marie Fayard
8 min
blog
Alex Casalboni
12 min
blog
Dario Radečić
15 min
blog
Tim Lu
9 min
Tutorial
Benito Martin
Tutorial
Kofi Glover