
Cursus
Développer des LLM
16 h
Mistral released Pixtral 12B, a 12 billion parameter open-source large language model (LLM). This is Mistral’s first multimodal model, which means it can process both text and images.
Here’s why Pixtral is a valuable addition to the LLM landscape:
In this tutorial, I’ll provide numerous examples and step-by-step guidance on using Pixtral through the web chat interface, Le Chat, and programmatically via the API. But first, let’s cover the essential theoretical aspects of Pixtral.
Mistral AI has launched Pixtral 12B, a model designed to process both images and text together. With 12 billion parameters, it can handle tasks that involve a mix of visuals and language, such as interpreting charts, documents, or graphs.
It’s useful for environments that require a deep understanding of both formats.
A key feature of Pixtral 12B is its capacity to handle multiple images within a single input, processing them at their native resolution. The model has a 128,000-token context window, which allows for the analysis of long and complex documents, images, or multiple data sources simultaneously. This makes it helpful in areas like financial reporting or document scanning for businesses.
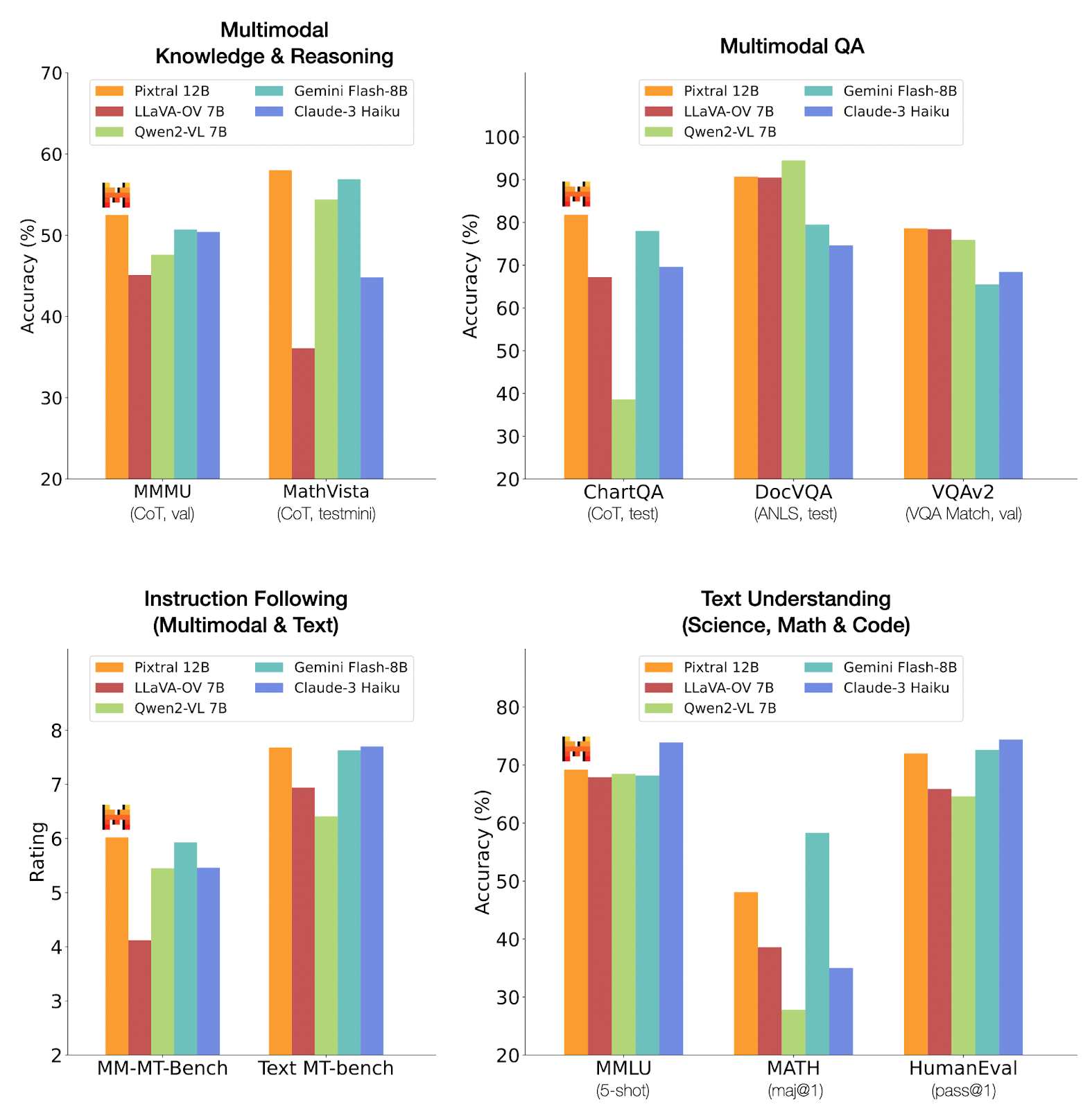
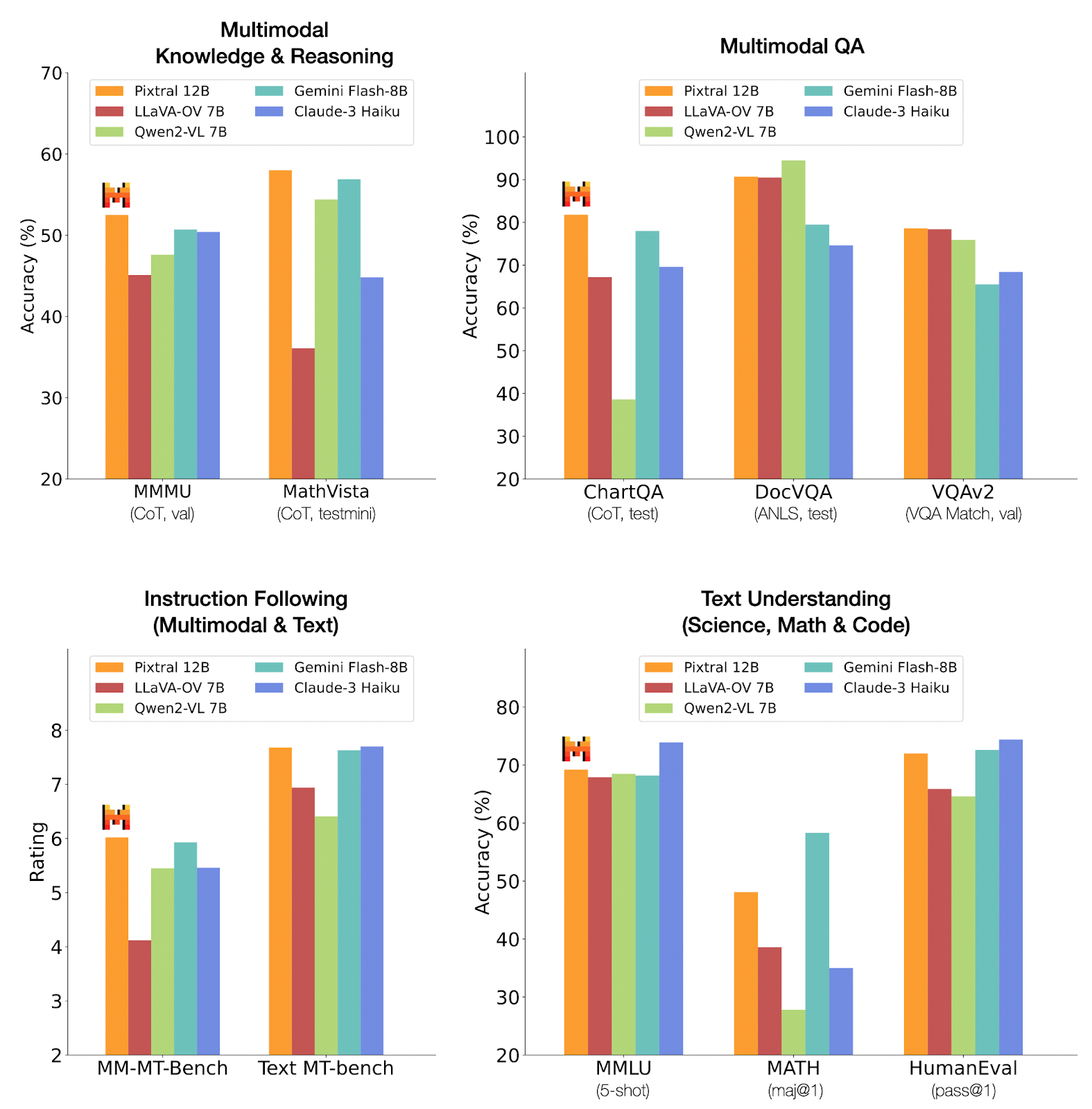
Pixtral performs well in tasks related to Multimodal Knowledge & Reasoning, especially in the MathVista test, where it leads the pack. In multimodal QA tasks, it also holds a strong position, particularly in ChartQA.
Source: Mistral AI
However, in instruction following and text-based tasks, other models like Claude-3 Haiku and Gemini Flash-8B show competitive or superior performance. This suggests that Pixtral 12B excels in multimodal and visual reasoning but may not dominate in purely text-based tasks.
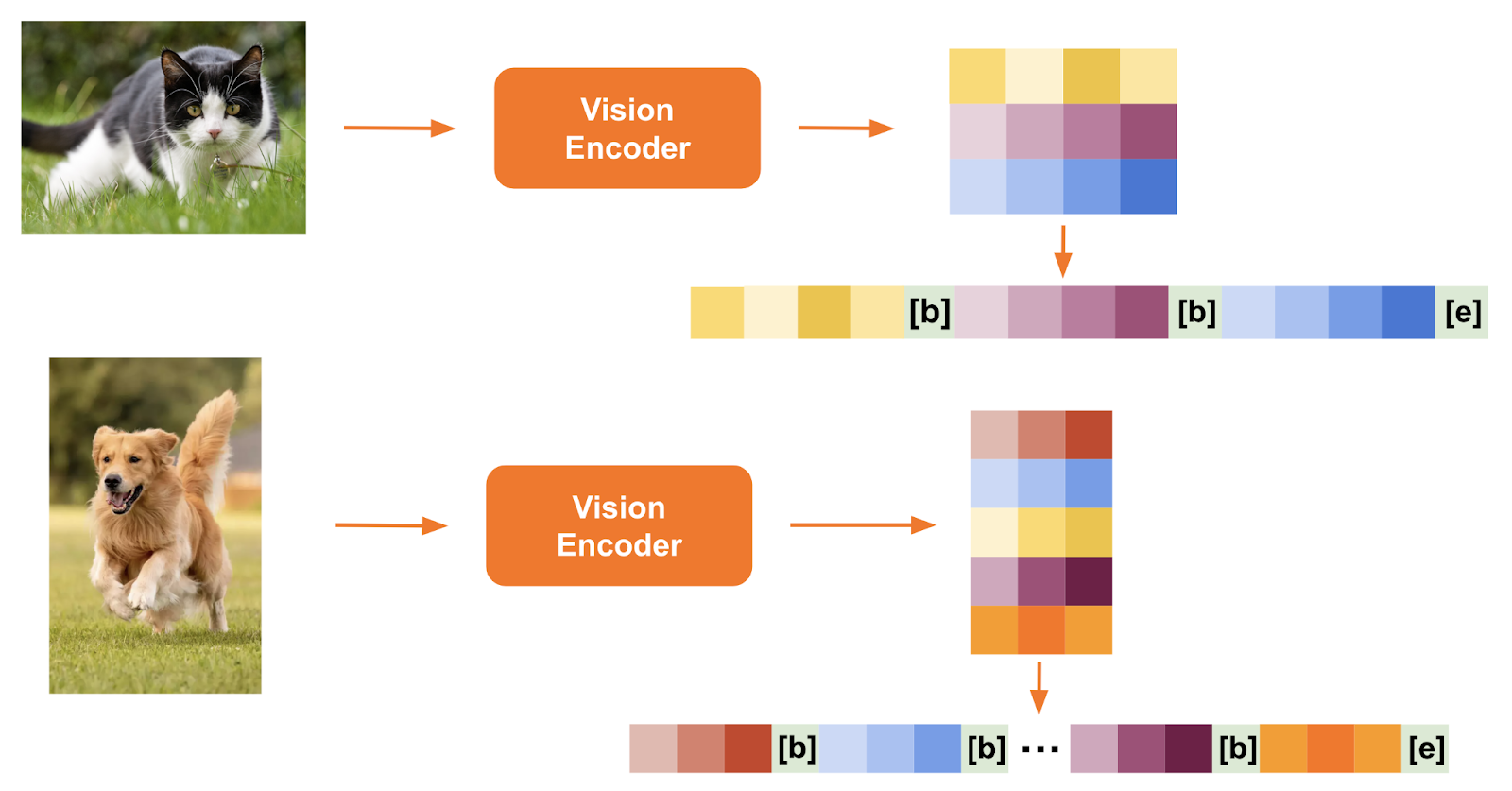
The architecture of Pixtral 12B is designed to process both text and images simultaneously. It features two main components: a Vision Encoder and a Multimodal Transformer Decoder.
The Vision Encoder, which has 400 million parameters, is specifically trained to accommodate images of varying sizes and resolutions.
Source: Mistral AI
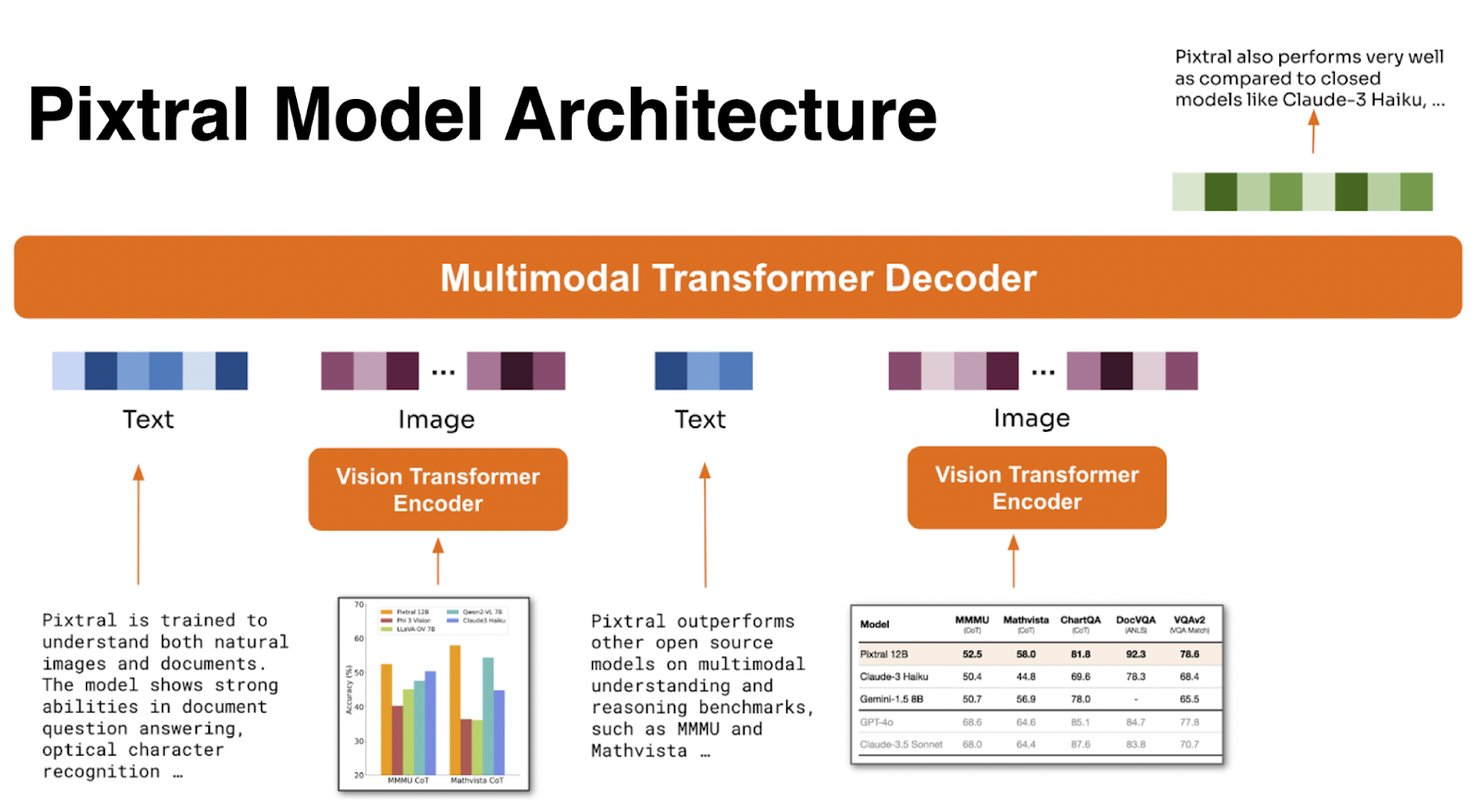
The second component, the Multimodal Transformer Decoder, is a more extensive model with 12 billion parameters. It's based on the existing Mistral Nemo architecture and is designed to predict the next text token in sequences that interleave text and image data.
This decoder can process very lengthy contexts (up to 128k tokens), enabling it to handle numerous image tokens and extensive textual information in large documents.
Source: Mistral AI
This combined architecture allows Pixtral to deal with a wide range of image sizes and formats, translating high-resolution images into coherent tokens without losing context.
The easiest way to access Pixtral for free is through Le Chat, their chat interface. This interface resembles other LLM chat interfaces—like that of ChatGPT, for example.
To use Pixtral, navigate to the model selector located at the bottom, next to the prompt input, and choose the Pixtral model from the list of available models.
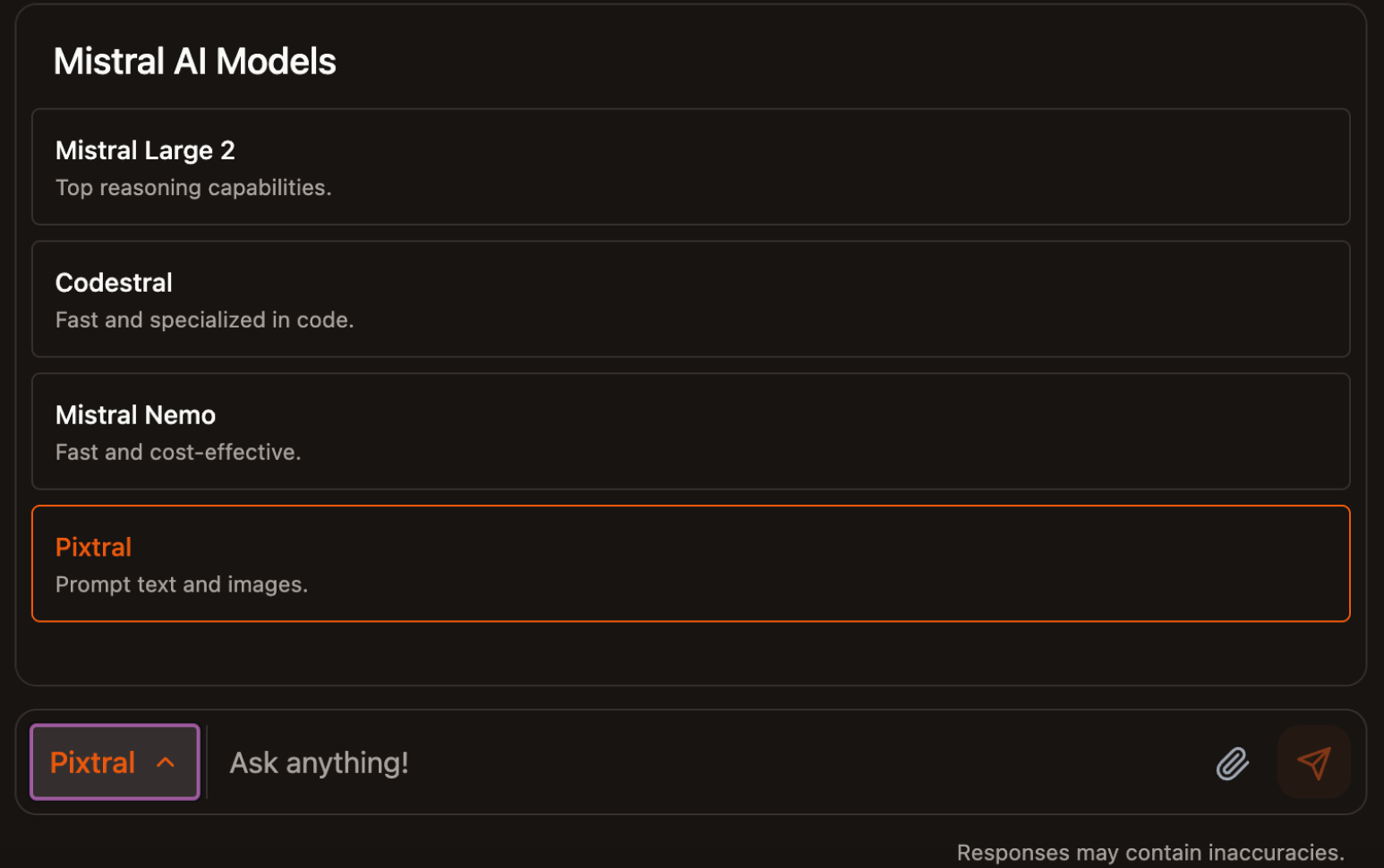
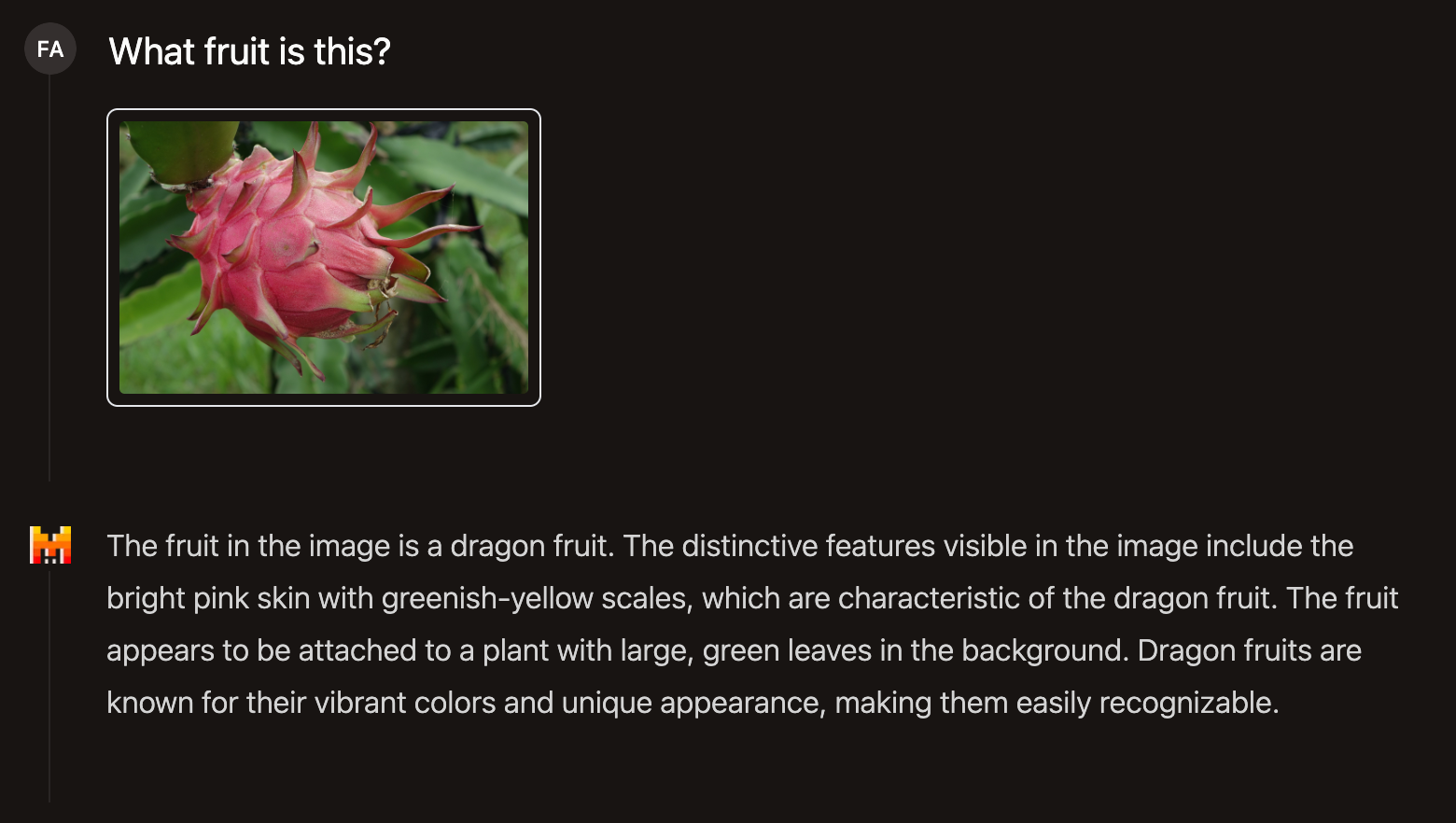
Pixtral is a multimodal model that supports both text and images. By using the clip icon located at the bottom, we can upload one or more images and combine them with a text prompt. For example, this functionality can assist us in identifying a fruit depicted in an image.
Let's explore another example where we request Pixtral to transform an image containing a pie chart into a markdown table:

Although using Pixtral through its web interface is nice and easy, it's not suitable for incorporating it into our projects. In this section, we will discuss how to interact with Pixtral via their API using Python, through La Plateforme.
To begin, we need to create an account. This can be done with just one click by using a Google account, or alternatively, by setting up a traditional account with a username and a password.
Upon creating the account, we are prompted to set up a workspace. You can select any name for your workspace and opt for the "I'm a solo creator" option.
After creating the account, proceed to the billing plans page. Here, we have the option to either create an experimental billing plan, which allows us to try the API for free, or set up a paid plan. It's important to note that the free experimental plan requires us to link a valid phone number to our account.

Our profile should now be ready to create an API key. This key is necessary for making requests to the Mistral API and for programmatically interacting with Pixtral using Python.
To generate the API key, navigate to the API key page. At the top of the page, we have a button to create a new API key:

When creating a key, we are prompted to name it and set an expiration date. However, both fields are optional, allowing us to leave them blank if desired.
Generally, it is advisable to set an expiration date for keys. Often, keys are created to experiment with an API but then are forgotten, leaving them active indefinitely. Setting an expiration date ensures that if a key is accidentally leaked, it cannot be used forever, thus minimizing potential risks.
Once the key is created, it will be displayed. This display is the only opportunity to view the key, so it's essential to copy it. If the key is lost, the solution is to delete it from the list and create a new one.
I recommend creating a .env file in the same directory as the Python script to store the key using the following format (replacing <key_value> with the actual key):
# contents of the .env fileAPI_KEY=<key_value>Skipping this step and hardcoding the API key in our script is not recommended. Doing so prevents us from sharing our code without also sharing the key. Learn more about this approach in this tutorial on Python environment variables.
To begin, we install the necessary dependencies, which include:
mistralai, the client library provided by Mistral for API interaction.python-dotenv, a module used for loading environment variables from a .env file.pip install python-dotenv mistralaiOnce the dependencies are installed, we can proceed to script creation. Create a file called mistral_example.py in the same directory as the .env file. The initial step involves importing the modules and loading the API key into a variable.
# Create a mistral_example.py file in the same folder as the .env fileimport osfrom mistralai import Mistralfrom dotenv import load_dotenvload_dotenv()api_key = os.getenv("API_KEY")Following that, we can proceed to initialize the client.
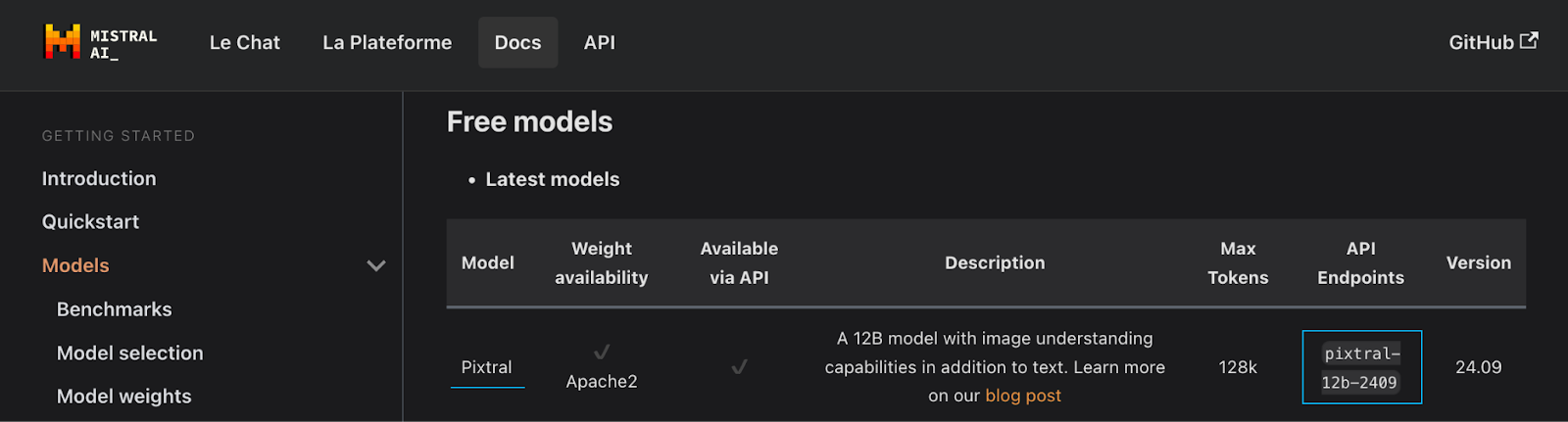
The Mistral documentation page provides a list of all available models. We are particularly interested in the latest Pixtral model, which has the API endpoint pixtral-12b-2409.
# Add this code in mistral_example.py after initializing the API keymodel = "pixtral-12b-2409"client = Mistral(api_key=api_key)We’re now ready to make a request to the Mistral API and interact with Pixtral programmatically. Here’s an example of how to submit a text prompt:
# Add this code in mistral_example.py after initializing the clientchat_response = client.chat.complete( model=model, messages = [ { "role": "user", "content": [ { "type": "text", "text": "What is 1 + 1?" } ] }, ])print(chat_response.choices[0].message.content)We can run this script on the terminal and see the Pixtral’s response to our prompt:
$ python mistral_example.py The sum of 1 + 1 is 2. So,1 + 1 = 2In the example provided, the text prompt is submitted through the content field, where type is set to "text".
{ "type": "text", "text": "What is 1 + 1?"}The content field is an array that allows us to send multiple pieces of data. As a multi-modal model, Pixtral also accepts image data. To use an image from a URL in the prompt, we can include it in the content field by specifying "image_url" as the type:
{ "type": "image_url", "Image_url": "<image_url>” }Replace <image_url> with the actual URL of the image. For example, we can use Pixtral to analyze the performance charts below:
Source: Mistral AI
chat_response = client.chat.complete( model=model, messages = [ { "role": "user", "content": [ { "type": "text", "text": "According to the chart, how does Pixtral 12B performs compared to other models?" }, { "type": "image_url", "image_url": "https://mistral.ai/images/news/pixtral-12b/pixtral-benchmarks.png" } ] }, ])print(chat_response.choices[0].message.content)When this request is submitted, Pixtral receives both the text prompt and the image containing the charts for analysis and then provides a response detailing the analysis. We won't display the response here due to its considerable length.
In the previous example, we showed how to display an image from a URL. Alternatively, we can use an image stored on our hard drive by loading it as a base-64 encoded image. To load and encode an image in base-64, we use the built-in base64 package:
def encode_image_base64(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode("utf-8")When using base-64 encoded images, we still use the image_url type to provide the encoded image but we need to prepend it with data:image/jpeg;base64,:
{ "type": "image_url", "image_url": f"data:image/jpeg;base64,{base_64_image}"}base_64_image is the result of calling the encode_image_base64() function to load the image. Let’s use this to ask Pixtral to build a to-do list website with two pages based on the following two sketches I made:
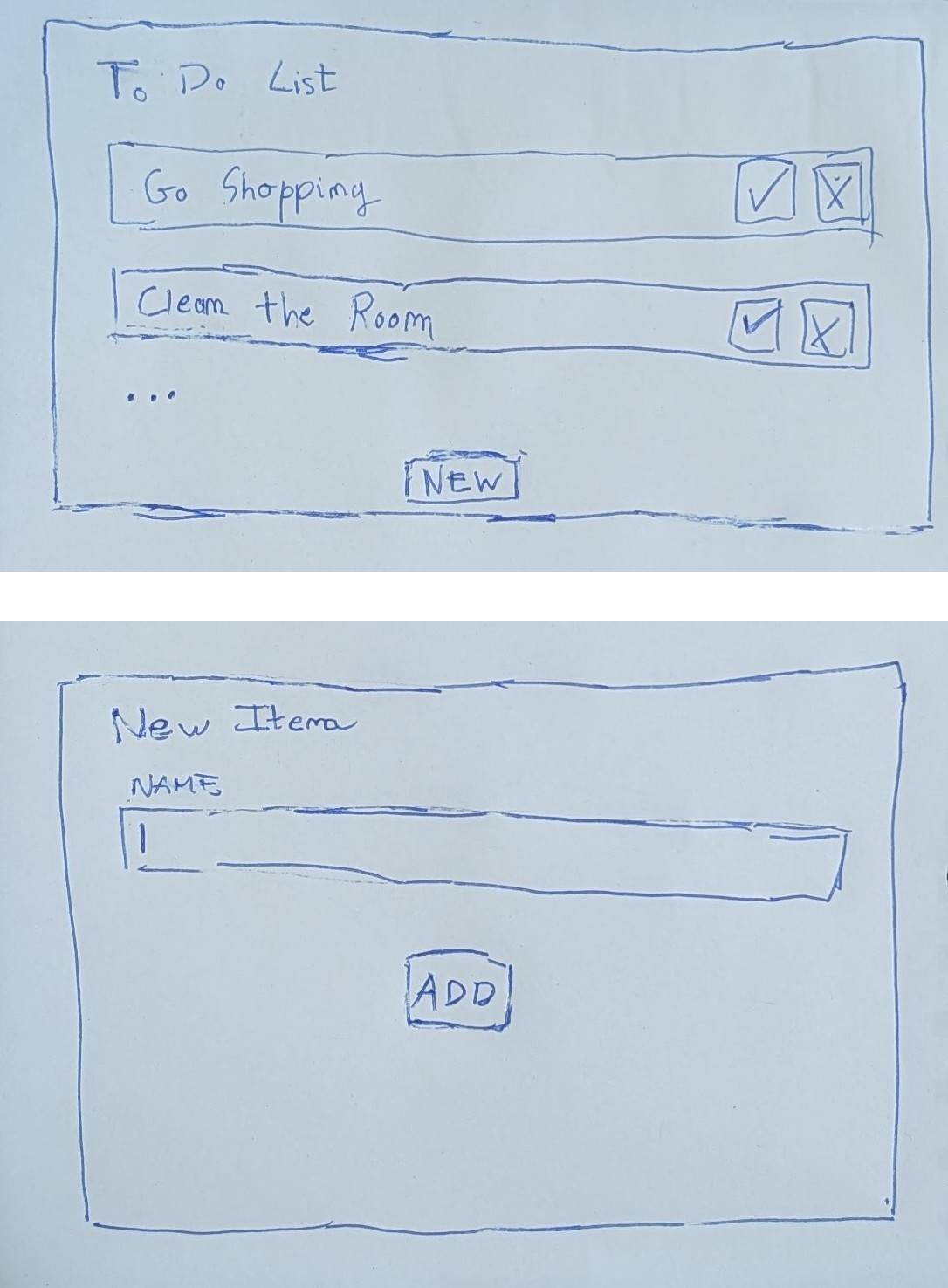
We provide the two images separately as well as a prompt asking to create an HTML website based on the images:
list_image = encode_image_base64("./todo-list.jpeg")new_item_image = encode_image_base64("./new-item-form.jpeg")chat_response = client.chat.complete( model=model, messages = [ { "role": "user", "content": [ { "type": "text", "text": "Create a HTML website with two pages like in the images" }, { "type": "image_url", "image_url": f"data:image/jpeg;base64,{list_image}" }, { "type": "image_url", "image_url": f"data:image/jpeg;base64,{new_item_image}" }, ] }, ])print(chat_response.choices[0].message.content)Pixtral will output two code blocks with the content of the two pages. We saved the code into two files named index.html and add.html and opened them in the browser. This was the result:
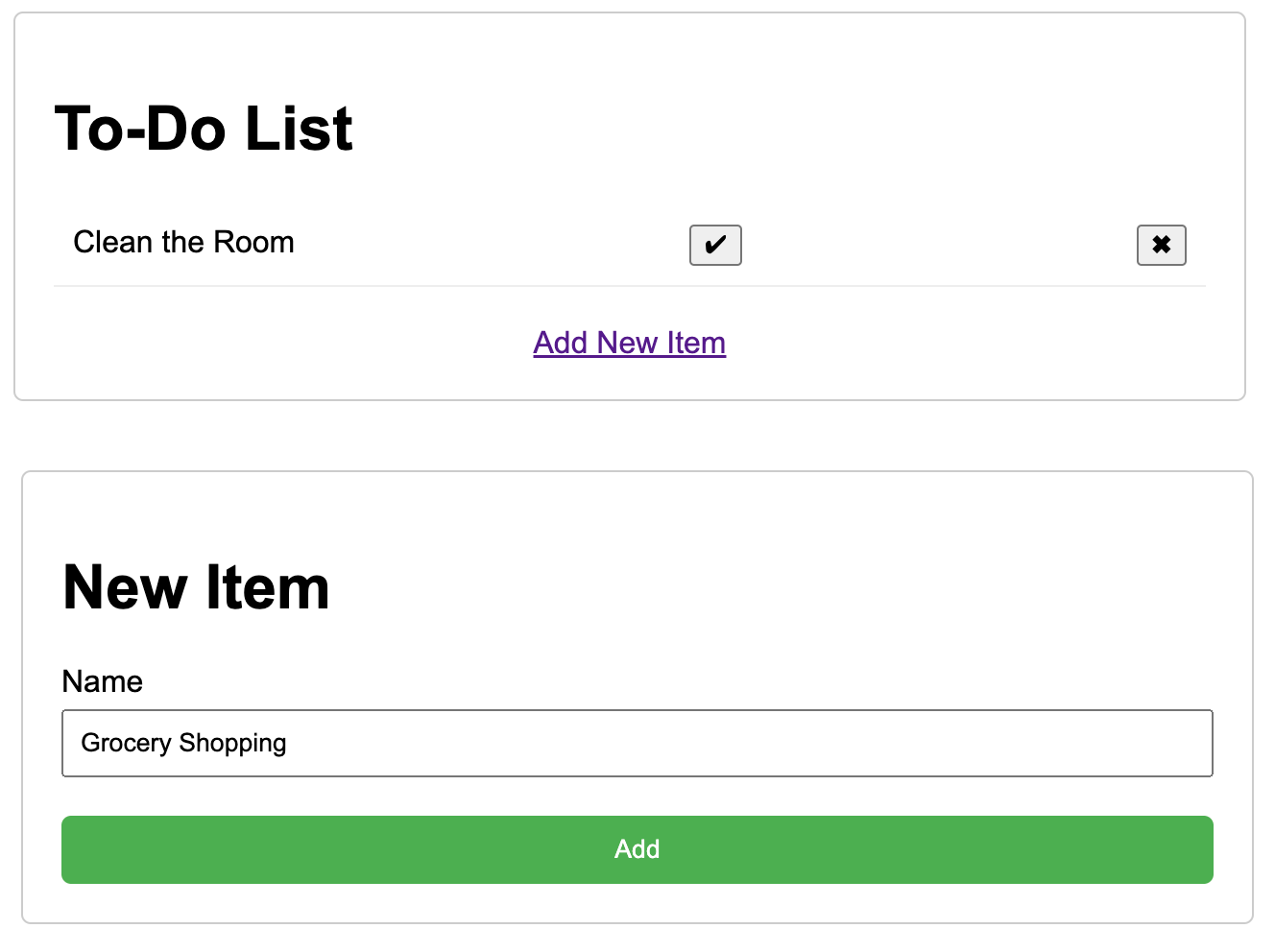
Although it's not a fully functional application yet, it's operational and an excellent starting point for further development.
Pixtral 12B is Mistral’s first multimodal model. It can handle images of all sizes without pre-processing, features a 128K context window for complex prompts, and performs well in both text-only and multimodal tasks.
Available for free in non-monetized projects and open-source under the Apache 2.0 license, Pixtral is valuable for researchers and hobbyists alike.
In this tutorial, I’ve provided practical insights into using Pixtral, highlighting its capabilities through examples and step-by-step guidance.
Learn AI with these courses!
Cursus
Cours
Cours
Tutoriel
Josep Ferrer
Tutoriel
Bex Tuychiev
Tutoriel
Ryan Ong
Tutoriel
Abid Ali Awan
Tutoriel
Bhavishya Pandit
Tutoriel
Dr Ana Rojo-Echeburúa


