
Course
Generative AI Concepts
2 hr
105.3K
In November 2022, OpenAI launched ChatGPT. It took just a few days for it to take the world by storm with its unprecedented capabilities. The generative AI revolution had started, and everyone was asking the same question: what’s next?
At the time, ChatGPT and the many other generative AI tools powered by Large Language Models (LLMs) were designed to process text inputs from users and generate text outputs. In other words, they were considered unimodal AI tools.
However, this was just the beginning. We were just scratching the surface of what LLMs can do. Only a year after the launch of ChatGPT, the progress of the industry is simply astonishing, making it very difficult to locate the frontiers of the possible, as we analyzed in our separate article on the long-term impacts of ChatGPT and Generative AI.
Today, if we were to answer the question of what’s next? the best answer is probably multimodal learning. This is one of the most promising trends in the ongoing AI revolution. Multimodal generative AI models are capable of combining various types of inputs and creating an output that may also include multiple types of outputs.
In this guide, we will take you through the concept of multimodal AI. We will take a look at the definition of multimodal AI, its core concepts, underlying technologies, and applications, as well as how to implement them in real-world scenarios. Ready for multimodality? Let’s get started!
While most advanced generative AI tools are still incapable of thinking like humans, they are delivering groundbreaking results that bring us just a bit closer to the threshold of Artificial General Intelligence (AGI). This term refers to a hypothetical AI system that can understand, learn, and apply knowledge across a wide range of tasks, much like a human.
In the debate on how to achieve AGI, a central question we need to address is how humans learn. And this leads us to how the human brain works. To cut a long story short, our brain relies on our five senses to collect all kinds of information from the surrounding environment. Such information is then stored in our memory, processed to learn new insights, and leveraged to make decisions.
The first modern generative AI models, like ChatGPT, were considered unimodal; that is, they were only able to take one type of data as an input and generate the same type of output. In particular, most of these models were designed to process text prompts and generate a text response.
This makes sense, for these models need vast amounts of data to be trained, and text is not only a data type that can be stored and processed easily, but it’s also readily available. It’s not surprising that most of the training data of tools like ChatGPT come from different sources on the Internet. We explain all these technicalities in our What is ChatGPT article, where we ask the questions directly to ChatGPT.
However, reading is only one of the various ways humans can learn new things, and, for many tasks, not the most effective.
Multimodal learning is a subfield of AI that tries to augment the learning capacity of machines by training them with large amounts of text, as well as other data types, also known as sensory data, such as images, videos, or audio recordings. This allows models to learn new patterns and correlations between text descriptions and their associated images, videos or audio.
Multimodal learning is unlocking new possibilities for intelligent systems. The combination of multiple data types during the training process makes multimodal AI models suitable for receiving multiple modalities of input type and generating multiple types of outputs. For example, GPT-4, the foundation model of ChatGPT, can accept both image and text inputs and generate text outputs, and the recently announced Sora text-to-video model from OpenAI.
Multimodal generative AI models add a new layer of complexity to state-of-the-art LLMs. These models are based on a type of neural architecture called a Transformer. Developed by Google researchers, transformers rely on the encoder-decoder architecture and the attention mechanism to enable efficient processing of data.
This is a rather complex process that can be difficult to understand. If you want to get more details on how LLMs and transformers work, we highly encourage you to read our How Transformers Work guide, or, if you want to get your hands dirty and learn how to create LLMs step by step, check out our Large Language Models (LLMs) Concepts Course.
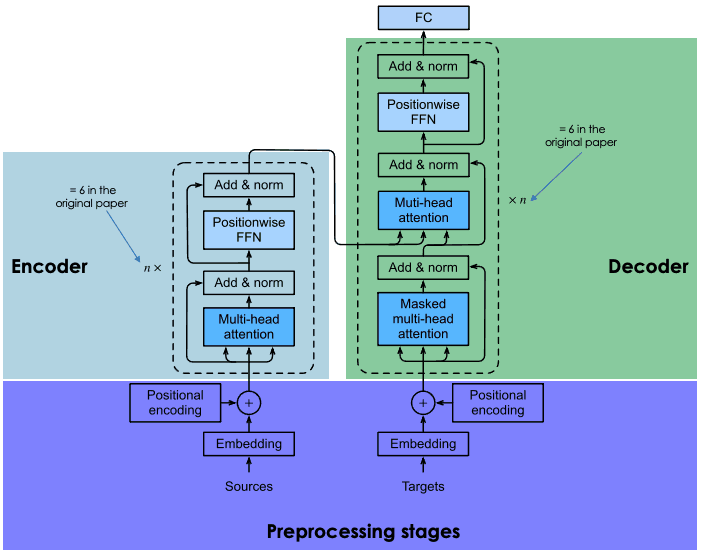
Source: DataCamp
Multimodal AI relies on data fusion techniques to integrate disparate data types and build a more complete and accurate understanding of the underlying data. The ultimate goal is to make better predictions by combining the complementary information that different modalities of data provide.
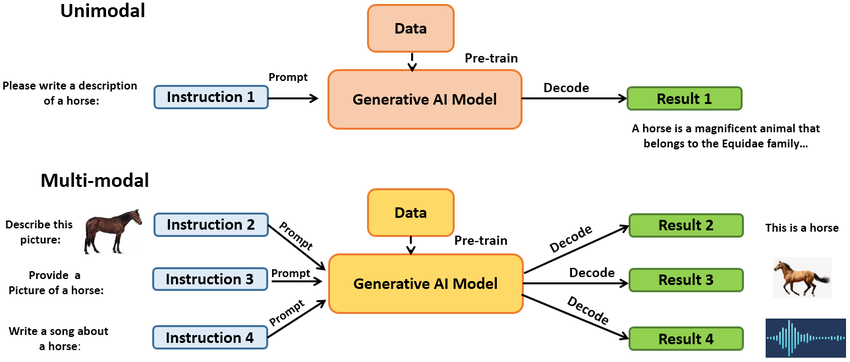
Unimodal vs Multimodal AI. Source: ResearchGate
Several data fusion techniques can be implemented to address multimodal challenges. Depending on the processing stage at which fusion takes place, we can classify data fusion techniques into three categories:
There is no single data fusion technique that is best for all kinds of scenarios. Instead, the chosen technique will depend on the multimodal task at hand. Hence, a trial and error process will likely be required to find the most suitable multimodal AI pipeline.
Multimodal AI is the result of the accumulated knowledge in multiple subfields of AI. In recent years, AI practitioners and scholars have made impressive progress in storing and processing data in multiple formats and modalities.
Below, you can find a list of the domains that are fuelling the multimodal AI boom:
Deep learning is a subfield of AI that employs a type of algorithm called an artificial neural network to address complex tasks. The current generative AI revolution is powered by deep learning models, particularly transformers, which are a type of neural architecture.
The future of multimodal AI will also depend on new progress in this domain. Particularly, research is very much needed to find new ways to augment the capabilities of transformers, as well as new data fusion techniques.
Check out our Deep Learning in Python Track to further your learning in this promising domain.
NLP is a pivotal technology in artificial intelligence, bridging the gap between human communication and computer understanding. It is a multidisciplinary domain that empowers computers to interpret, analyze, and generate human language, enabling seamless interaction between humans and machines.
Since the primary way to communicate with machines is through text, it’s not surprising that NLP is critical to ensuring the high performance of generative AI models, including multimodal ones.
Interested in NLP? Check out our Natural Language Processing in Python Track to gain the core NLP skills needed to convert unstructured data into valuable insights.
Image analysis, also known as computer vision, comprises a set of techniques by which computers can “see” and understand an image. The progress in this sector has allowed the development of multimodal AI models that can process images and videos as both inputs and outputs.
If you are interested in delving further into this fascinating topic, check out our Image Processing with Python Skill Track to incorporate image processing skills into your data science toolbox.
Some of the most advanced generative AI models are capable of processing audio files both as inputs and outputs. The possibilities of audio processing range from interpreting voice messages to simultaneous translation and music creation.
Check out our Spoken Language Processing in Python Course to learn how to load, transform, and transcribe speech from raw audio files in Python.
Multimodal learning allows machines to acquire new “senses," increasing their accuracy and interpretation capabilities. These powers are opening the gate for a myriad of new applications across sectors and industries, including:
Most of the first generation of generative AI models were text-to-text, capable of processing text prompts by users and providing text answers. Multimodal models, like GPT-4 Turbo, Google Gemini, or DALL-E, come with new possibilities that can improve user experience both at the input and output sides. Whether accepting prompts in multiple modalities or generating content in various formats, the possibilities of multimodal AI agents seem unlimited.
Self-driving cars rely heavily on multimodal AI. These cars are equipped with multiple sensors to process information from the surroundings in various formats. Multimodal learning is key for these vehicles to combine these sources in an effective and efficient manner to make intelligence decisions in real time.
The increasing availability of biomedical data from biobanks, electronic health records, clinical imaging, and medical sensors, as well as genomic data, is fuelling the creation of multimodal AI models in the field of medicine. These models are capable of processing these various data sources coming in multiple modalities to help us unravel the mysteries of human health and disease, as well as to make intelligent clinical decisions.
The rapid expansion of ground sensors, drones, satellite data, and other measurement techniques is increasing our capabilities to understand the planet. Multimodal AI is critical to combine this information accurately, and create new applications and tools that can help us in a variety of tasks, such as greenhouse gas emissions monitoring, extreme climate events forecasting, and precision agriculture.
The multimodal AI boom comes with endless possibilities for businesses, governments and individuals. However, as with any nascent technology, implementing them in your daily operations can be challenging.
Firstly, you need to find the use cases that match your specific needs. Moving from concept to deployment is not always easy, especially if you lack the people who properly understand the technicalities behind multimodal AI. However, given the current data literacy skill gap, finding the right people to put your models in production may be hard and costly, for companies are willing to pay high numbers to attract such a limited talent.
Finally, when speaking about generative AI, mentioning affordability is mandatory. These models, especially multimodal ones, require considerable computing resources to work, and that means money. Hence, before adopting any generative AI solution, it’s important to estimate the resources you want to invest.
As with any new technology, there are several potential pitfalls that we must navigate with multimodal AI models:
Multimodal AI is certainly the next frontier of the generative AI revolution. The rapid development of the field of multimodal learning is fuelling the creation of new models and applications for all kinds of purposes. We are just at the beginning of this revolution. As new techniques are developed to combine more and new modalities, the scope of multimodal AI will widen.
However, with great power comes great responsibility. Multimodal AI comes with serious risks and challenges that need to be addressed to ensure a fair and sustainable future.
If you want to get started in generative AI, DataCamp gets you covered. Check our dedicated courses, blogs, and materials:
Start Your AI Journey Today!
Course
Course
Course
blog
Christine Cepelak
14 min
blog
Abid Ali Awan
13 min
blog
Javier Canales Luna
9 min
blog
Abid Ali Awan
9 min
cheat-sheet
Richie Cotton
code-along
Korey Stegared-Pace




