
Course
Biomedical Image Analysis in Python
4 hr
23.4K
Learn how to work with LLMs in Python right in your browser

At the core of vision language models is the integration of computer vision and natural language processing.
Computer vision focuses on enabling machines to interpret and analyze visual data, such as images and videos, by recognizing objects, patterns, and other visual elements.
On the other hand, natural language processing is concerned with understanding and generating human language, allowing machines to comprehend, analyze, and produce text.
VLMs bridge the gap between these two fields by creating models that can simultaneously process and understand visual and textual inputs. This is achieved through advanced deep learning architectures, particularly transformer models, which have been instrumental in the success of large language models like GPT-4o, Llama, Gemini, and Gemma.
These transformer-based architectures have been adapted to handle multimodal inputs, enabling VLMs to capture the complex relationships between visual and linguistic data.
The transformer model, initially introduced for NLP tasks, has become the backbone of many advanced AI systems due to its ability to handle long-range dependencies and capture contextual relationships in data.
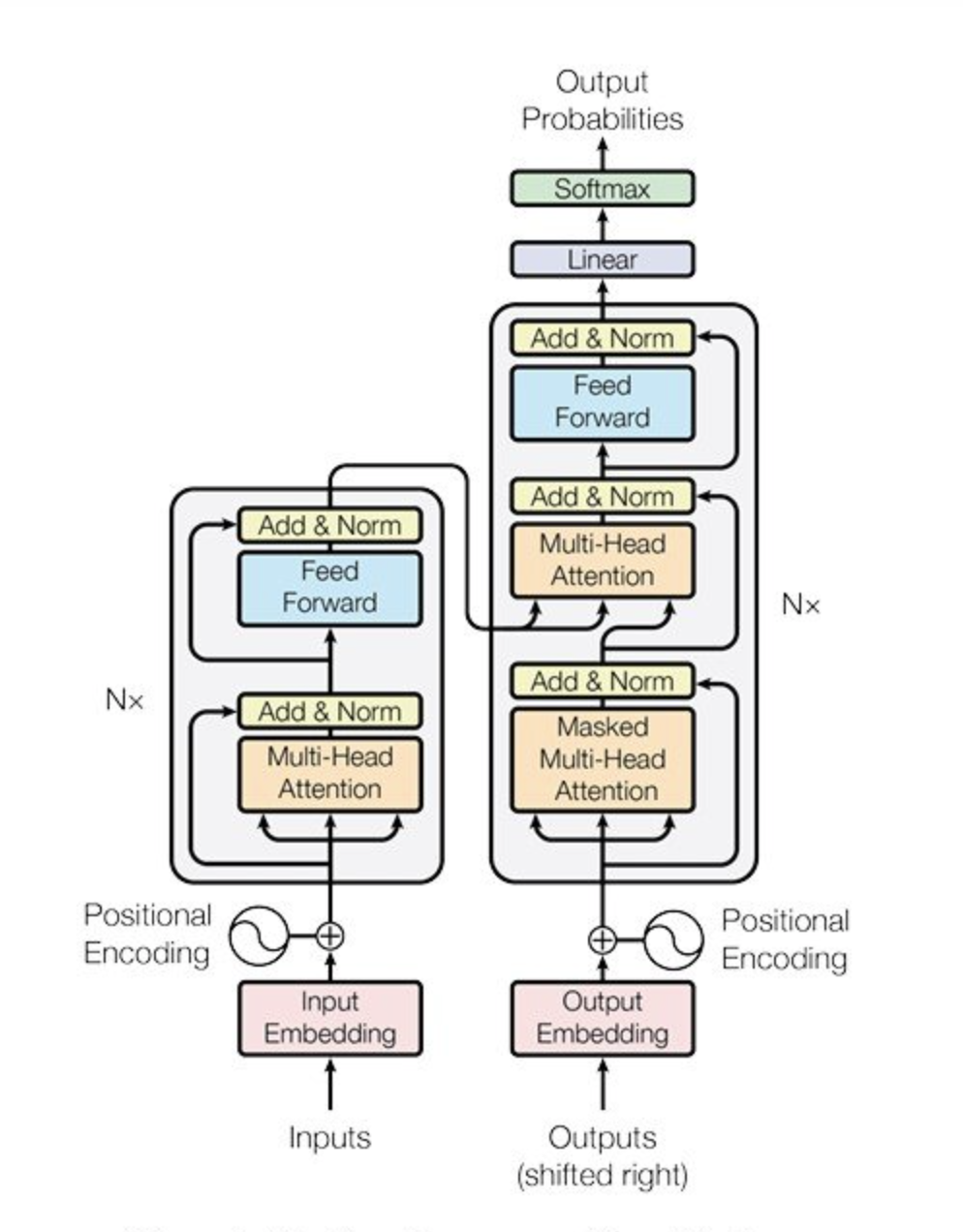
Source: Vaswani et al., 2017
In the context of VLMs, transformers have been adapted to process both images and text, allowing for a seamless integration of these two modalities.
A typical VLM architecture involves two main components: an image encoder and a text decoder:
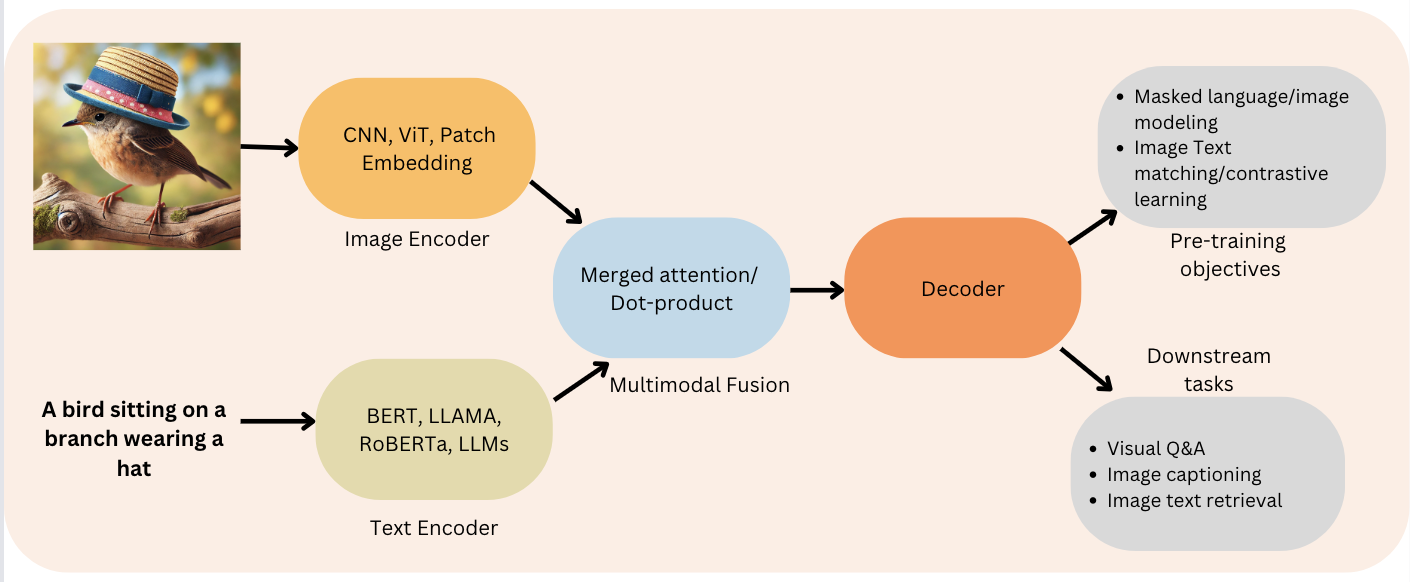
Figure 2: Encoder-Decoder function (Source: Viso.ai)
By combining these two parts, VLMs can do amazing things like describe images in detail, answer questions about what they see, and even generate new images based on text descriptions! The process that VLMs follow takes the following steps:
Most VLMs utilize a Vision Transformer (ViT) as their image encoder, which has been pre-trained on large-scale image datasets to ensure that it can effectively capture the visual features necessary for multimodal tasks.
The text decoder is based on the language model, which has been fine-tuned to handle the intricacies of language generation in the context of visual data. This combination of advanced visual and linguistic processing capabilities makes a highly versatile and powerful VLM.
One of the most significant challenges in developing VLMs is the need for large and diverse datasets that contain both visual and textual information. These datasets are essential for training the models to understand and generate multimodal content.
The process of training a VLM involves feeding the model with pairs of images and their corresponding textual descriptions, allowing the model to learn the intricate relationships between visual elements and linguistic expressions.
To handle this data, VLMs often use embedding layers that transform both visual and textual inputs into a high-dimensional space where they can be compared and combined.
This embedding process enables the model to understand the connections between the two modalities and generate coherent and contextually relevant outputs.
The landscape of vision language models (VLMs) is vast, with numerous open-source models available on the Hugging Face Hub. These models vary in size, capabilities, and licensing, providing users with a range of options tailored to different applications. Below is an overview of some of the most prominent open-source VLMs, highlighting their key features:
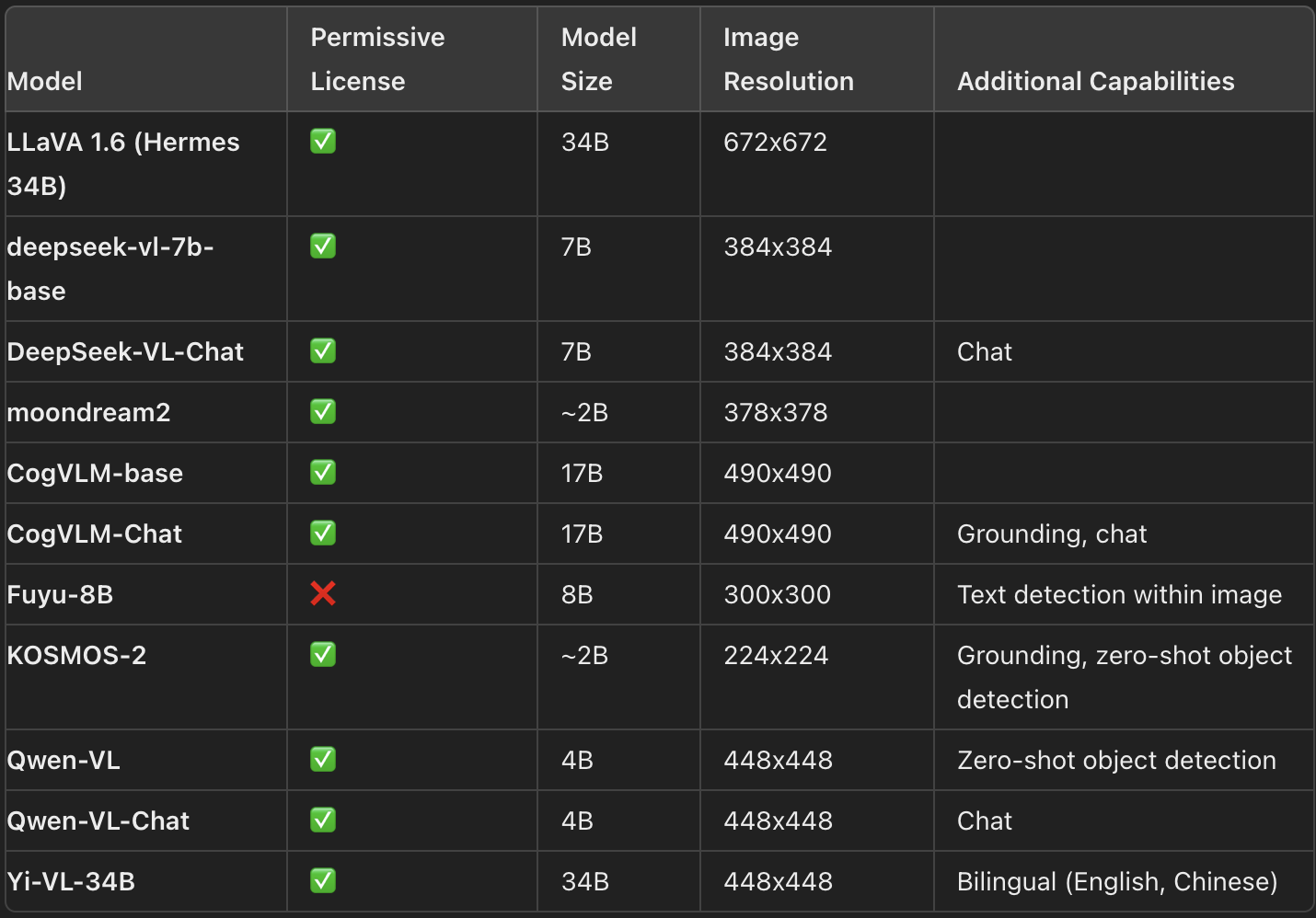
Latest VLMs and their key features (Source: HuggingFace)
Selecting the most appropriate VLM for your specific use case can be challenging, given the range of options available. Several tools and resources can assist in this selection process:
While both Vision Arena and the Open VLM Leaderboard offer valuable insights, they are limited to models that have been submitted and require regular updates to include new models.
Several benchmarks are commonly used to evaluate the performance of VLMs:
Pretraining VLMs involves unifying image and text representations to feed them into a text decoder for generation. The structure typically includes an image encoder, an embedding projector to align image and text representations, and a text decoder. However, different models employ different pretraining strategies.
In many cases, pretraining a VLM is even unnecessary if you can fine-tune existing models for your specific use case. Tools like Transformers and SFTTrainer simplify the process of fine-tuning models for particular tasks, making it accessible even to those with limited resources.
Here is a HuggingFace implementation for using the open-source VLM LlavaNext model free of cost on your Colab or local machine with the Transformers library by HuggingFace.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf"
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)The capabilities of vision language models extend far beyond image captioning. VLMs have opened doors to many applications that use their ability to bridge the gap between visual and textual information. Let's explore some of the most impactful applications of VLMs across various industries.
Visual question answering (VQA) is a task that involves answering questions about the content of an image.
This application requires the model to understand both the visual elements in the image and the linguistic context of the question. For example, given an image of a bustling cityscape, a VLM can answer questions like "What is the color of the tallest building?" or "How many people are visible in the image?"
VQA has numerous practical applications, particularly in industries where visual data plays a critical role. In healthcare, for instance, VQA can be used to analyze medical images and provide answers to questions that assist in diagnosis and treatment planning. In retail, VQA can enhance the shopping experience by allowing customers to interact with product images in a more natural and intuitive manner.
One of the most exciting capabilities of VLMs is text-to-image generation. This task involves generating a visual representation of a scene or object based on a textual description. For example, a VLM can take a prompt like "A serene sunset over a mountain range with a river flowing through the valley" and generate a corresponding image.
Text-to-image generation has immense potential in creative fields such as design and advertising. Designers and advertisers can use this technology to quickly generate visual ideas based on textual prompts. Text-to-image generation can streamline the process of creating visual content that aligns with specific marketing messages.
Image retrieval is the process of finding relevant images based on a textual query. VLMs excel in this task by using their ability to understand both the visual content of images and the linguistic context of the query.
This capability makes search engines more powerful and precise, allowing users to find the exact images they are looking for with greater ease.
Image retrieval has applications in various domains, from e-commerce to medical image analysis. In e-commerce, image retrieval can help customers find products that match their preferences based on visual and textual descriptions. In healthcare, image retrieval can assist medical professionals in finding relevant medical images for research or diagnostic purposes.
While the examples above focus on images, VLMs can also be extended to understand and generate captions for videos. Video understanding involves analyzing the visual content of a video and generating descriptive text that captures the essence of the scenes depicted.
Video understanding has applications in video search, summarization, and content moderation. In video search, VLMs can help users find specific video clips based on textual queries. In summarization tasks, VLMs can generate concise summaries of long videos, making it easier for users to quickly understand the content. In content moderation, VLMs can assist in identifying inappropriate or harmful content in videos, ensuring that platforms maintain a safe and user-friendly environment.
Let’s now consider the challenges associated with VLMs, as well as the ethical aspects.
Training and deploying VLMs requires significant computational resources, particularly for large models like PaliGemma. This can be a barrier for organizations with limited access to high-performance computing infrastructure.
To address this challenge, researchers are exploring ways to make VLMs more efficient, such as by using model compression techniques, optimizing the model architecture, and leveraging hardware accelerators like GPUs and TPUs.
The development of VLMs raises several ethical concerns, particularly around the potential for bias in the model's outputs. VLMs trained on large-scale, real-world image-text data can reflect socio-cultural biases embedded in the training material. These biases can manifest in the model's outputs, leading to harmful or offensive content.
To address these concerns, researchers are implementing various bias mitigation techniques, such as using balanced training datasets, incorporating fairness-aware learning algorithms, and conducting rigorous evaluations of the model's outputs to identify and address potential biases.
Additionally, organizations like Google are implementing content safety filters to ensure that the training data used for models like PaliGemma is clean and free from harmful content.
Another important consideration in the development of VLMs is privacy and data security. VLMs often require access to large amounts of data, including potentially sensitive information. Ensuring that this data is handled securely and in compliance with privacy regulations is critical to maintaining the trust of users and stakeholders.
To address privacy concerns, researchers are exploring techniques such as federated learning, which allows models to be trained on decentralized data without the need to transfer sensitive information to a central server.
Additionally, organizations like Google are implementing data responsibility measures, such as filtering personal information and sensitive data from the training datasets, to protect the privacy of individuals.
Vision language models represent a significant step forward in artificial intelligence, offering the potential to enhance various applications through their ability to process both visual and textual data.
As research in this field progresses, we can anticipate the development of more sophisticated VLMs capable of performing complex tasks and providing valuable insights.
The integration of visual and textual understanding opens up new possibilities for innovation, making VLMs a promising area of research and development.
Learn AI with these courses!
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Abid Ali Awan
8 min
blog
Dimitri Didmanidze
7 min
blog
Abid Ali Awan
10 min
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes


