
Cours
Comprendre ChatGPT
1 h
424.4K
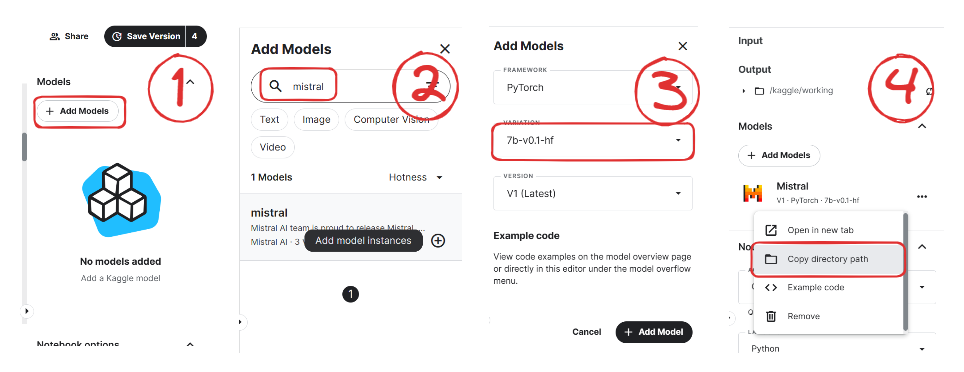
Nous pouvons accéder au Mistral 7B sur HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart et Baseten.
Il existe également une nouvelle et meilleure façon d'accéder au modèle via la nouvelle fonctionnalité de Kaggle appelée Modèles. Cela signifie que vous n'avez pas besoin de télécharger le modèle ou l'ensemble de données ; vous pouvez commencer l'inférence ou la mise au point en quelques minutes.
Dans cette section, nous allons apprendre à charger le modèle Kaggle et à exécuter l'inférence en quelques minutes.
Avant de commencer, nous devons mettre à jour les bibliothèques essentielles pour éviter l'erreur KeyError: 'mistral.
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesEnsuite, nous créerons une quantification 4 bits avec une configuration de type NF4 en utilisant BitsAndBytes pour charger notre modèle avec une précision de 4 bits. Il nous aidera à charger le modèle plus rapidement et à réduire l'empreinte mémoire afin qu'il puisse être exécuté sur Google Colab ou sur des GPU grand public.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Nous allons maintenant apprendre à ajouter le modèle Mistral 7B à notre carnet Kaggle.
Image de Mistral | Kaggle
Nous allons maintenant charger le modèle et le tokenizer à l'aide de la bibliothèque du transformateur.
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Pour nous faciliter la tâche, nous utiliserons la fonction pipeline de la bibliothèque Transformers pour générer la réponse en fonction de l'invite.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Nous fournirons ensuite l'invite à l'objet pipeline et définirons des paramètres supplémentaires pour créer le nombre maximum de jetons et améliorer notre réponse.
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Comme nous pouvons le constater, Mistral 7B a généré des résultats appropriés expliquant le processus de régularisation dans l'apprentissage automatique.
As a data scientist, can you explain the concept of regularization in machine learning?
Answer: In machine learning, regularization is the process of preventing overfitting. Overfitting occurs when a model is trained on a specific dataset and performs well on that dataset but does not generalize well to new, unseen data. Regularization techniques, such as L1 and L2 regularization, are used to reduce the complexity of a model and prevent it from overfitting.Vous pouvez dupliquer et exécuter le code en utilisant le cahier d'inférence Mistral 7B 4-bit sur Kaggle.
Note : Kaggle fournit suffisamment de mémoire GPU pour que vous puissiez charger le modèle sans quantification 4 bits. Vous pouvez suivre le cahier Mistral 7B Simple Inference pour apprendre comment procéder.
Dans cette section, nous suivrons des étapes similaires à celles du guide Fine-Tuning LLaMA 2 : Un guide étape par étape pour personnaliser le grand modèle de langage pour affiner le modèle Mistral 7B sur notre jeu de données favori guanaco-llama2-1k. Vous pouvez également lire le guide pour en savoir plus sur PEFT, la quantification sur 4 bits, QLoRA et SFT.
Nous allons mettre à jour et installer les bibliothèques Python nécessaires.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trlEnsuite, nous chargerons les modules nécessaires pour une mise au point efficace du modèle.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline, logging
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
import os,torch, wandb
from datasets import load_dataset
from trl import SFTTrainerNotez que nous utilisons Kaggle Notebook pour affiner notre modèle. Nous stockerons les clés API en toute sécurité en cliquant sur le bouton "Add-ons" et en sélectionnant l'option "Secret". Pour accéder à l'API dans un bloc-notes, nous copierons et exécuterons l'extrait comme indiqué ci-dessous.
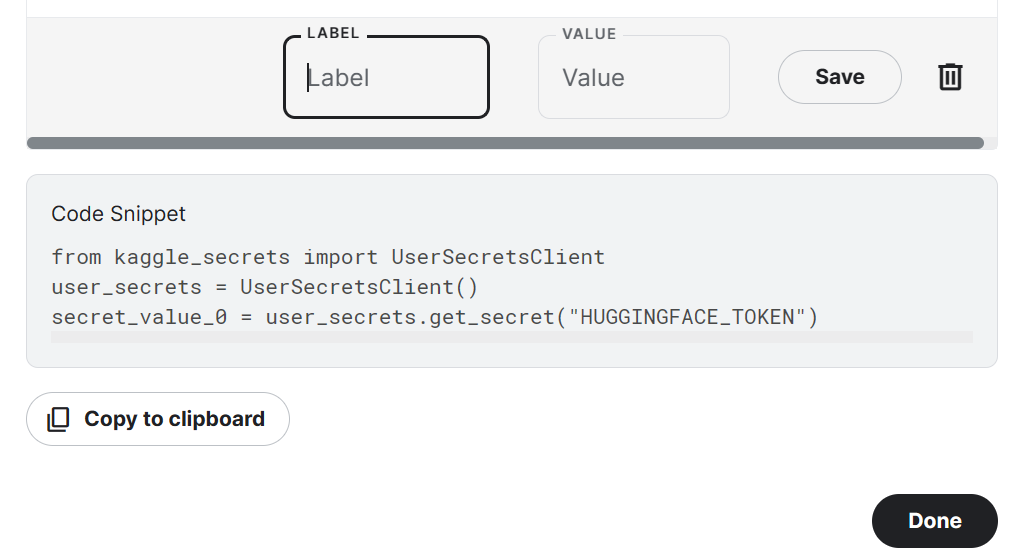
Dans notre cas, nous allons enregistrer les clés API Hugging Face et Weights and Biases et y accéder dans le notebook Kaggle.
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
secret_wandb = user_secrets.get_secret("wandb")Nous utiliserons l'API Hugging Face pour enregistrer et pousser le modèle vers le Hugging Face Hub.
!huggingface-cli login --token $secret_hfPour contrôler la performance du LLM, nous initialiserons les expériences de poids et de biais à l'aide de l'API.
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning mistral 7B',
job_type="training",
anonymous="allow"
)Dans cette section, nous allons définir le modèle de base, le jeu de données et le nom du nouveau modèle. Le nom du nouveau modèle sera utilisé pour enregistrer un modèle affiné.
Note : Si vous utilisez la version gratuite de Colab, vous devez charger la version sharded du modèle (someone13574/Mistral-7B-v0.1-sharded).
Vous pouvez également charger le modèle à partir de Hugging Face Hub en utilisant le nom du modèle de base : mistralai/Mistral-7B-v0.1
base_model = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
dataset_name = "mlabonne/guanaco-llama2-1k"
new_model = "mistral_7b_guanaco"Nous allons maintenant charger l'ensemble de données de Hugging Face Hub et visualiser la 100e ligne.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset["text"][100]
Nous allons maintenant charger un modèle utilisant une précision de 4 bits à partir de Kaggle pour une formation plus rapide. Cette étape est nécessaire si vous souhaitez charger et affiner le modèle sur un GPU grand public.
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False # silence the warnings
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()Ensuite, nous allons charger le tokenizer et le configurer pour résoudre le problème avec fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_tokenDans l'étape suivante, nous inclurons une couche d'adoption dans notre modèle. Cela nous permettra d'affiner le modèle en utilisant un petit nombre de paramètres, ce qui rendra l'ensemble du processus plus rapide et plus efficace sur le plan de la mémoire. Pour mieux comprendre les paramètres, vous pouvez vous référer à la documentation officielle de PEFT.
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj","gate_proj"]
)
model = get_peft_model(model, peft_config)Il est essentiel de définir les bons hyperparamètres. Vous pouvez en savoir plus sur chaque hyperparamètre en lisant le tutoriel Fine-Tuning LLaMA 2.
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="wandb"
)La bibliothèque TRL de HuggingFace offre une API conviviale qui permet de créer et d'entraîner des modèles de réglage fin supervisé (SFT) sur votre ensemble de données avec un codage minimal. Nous fournirons au formateur SFT les composants nécessaires, tels que le modèle, l'ensemble de données, la configuration de Lora, le tokenizer et les paramètres de formation.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= None,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Après avoir tout mis en place, nous allons entraîner notre modèle.
trainer.train()
Notez que vous utilisez la version T4 x2 du GPU, qui peut réduire le temps de formation à 1 heure et 30 minutes.
En fin de compte, nous sauverons un adoptant préformé et nous terminerons le parcours W&B.
trainer.model.save_pretrained(new_model)
wandb.finish()
model.config.use_cache = True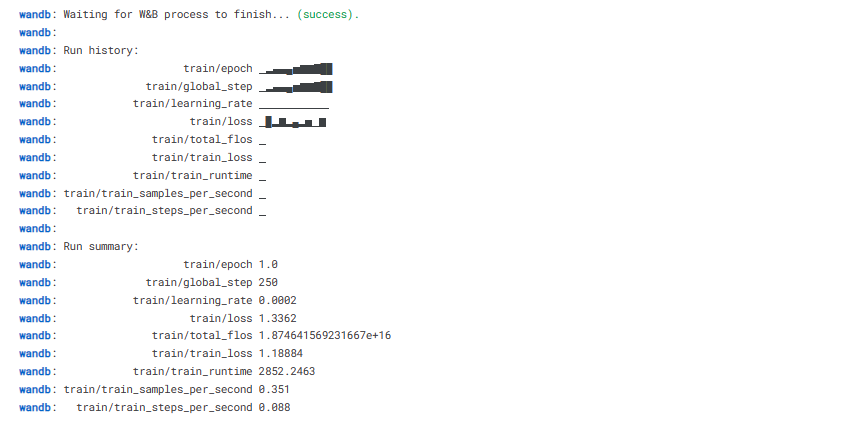
Nous pouvons facilement télécharger notre modèle sur le Hugging Face Hub avec une seule ligne de code, ce qui nous permet d'y accéder depuis n'importe quelle machine.
trainer.model.push_to_hub(new_model, use_temp_dir=False)
Vous pouvez consulter les métriques du système et les performances du modèle en allant sur wandb.ai et en vérifiant l'exécution récente.
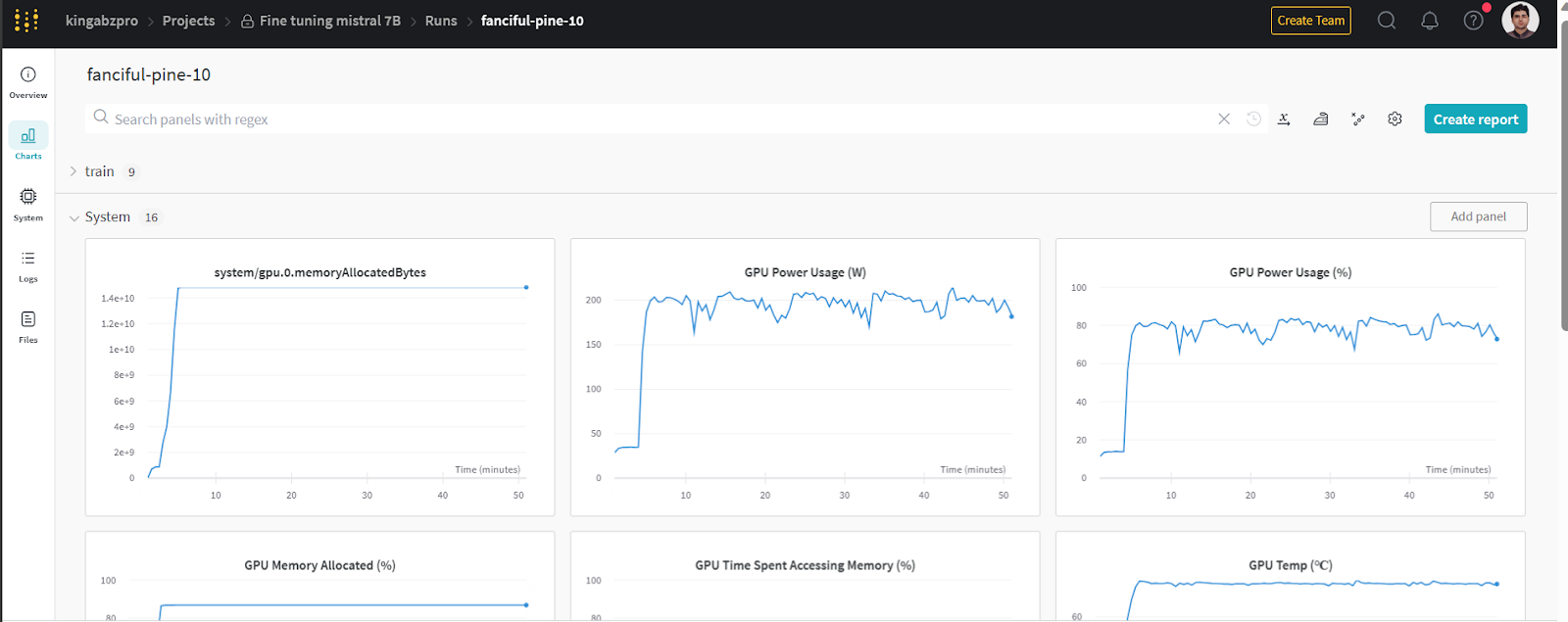
Image de wandb.ai
Pour effectuer l'inférence de modèle, nous devons fournir les objets modèle et tokenizer au pipeline. Ensuite, nous pouvons fournir l'invite dans le style dataset à l'objet pipeline.
logging.set_verbosity(logging.CRITICAL)
prompt = "How do I find true love?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])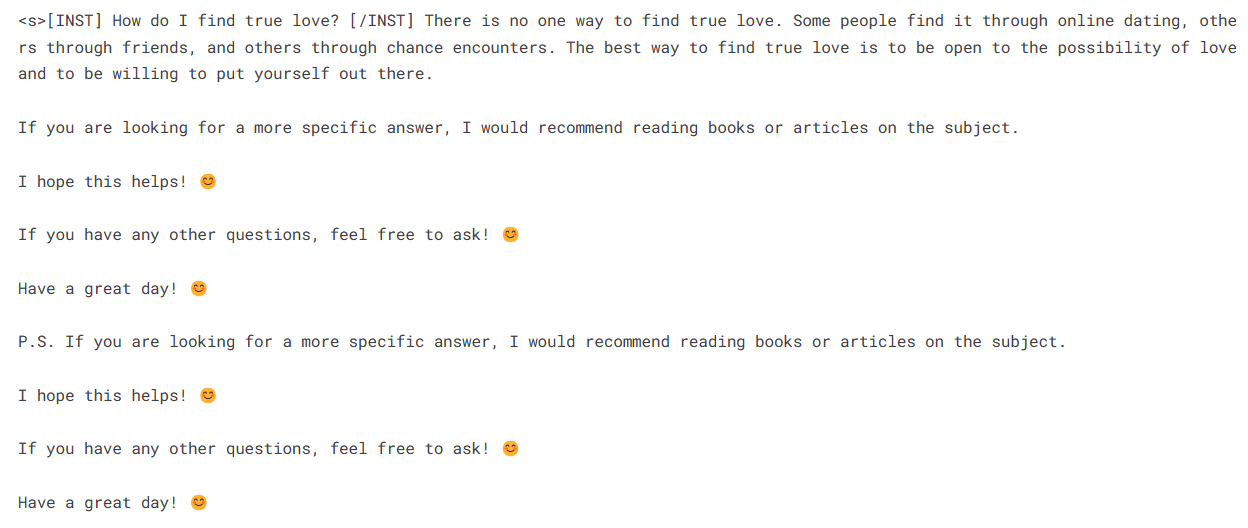
Générons la réponse à une autre question.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Il semble que nous obtenions des réponses parfaites à nos questions simples.

Liens importants pour Mistral 7B :
Image de Mistral 7B 4bit QLoRA Fine-tuning | Kaggle
Liens importants pour Mistral 7B Instruct :
Mistral 7B Instruct Fine-tuned Model
Dans cette section, nous allons charger le modèle de base et attacher l'adaptateur à l'aide de PeftModel, exécuter l'inférence, fusionner les poids du modèle et le pousser vers le Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
from peft import PeftModel
import torchTout d'abord, nous allons recharger le mode de base et l'adaptateur affiné à l'aide de peft. La fonction ci-dessous permet d'attacher l'adaptateur au modèle de base.
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
model = PeftModel.from_pretrained(base_model_reload, new_model)
Chargez le tokenizer du modèle de base et corrigez le problème avec fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Construire un pipeline d'inférence avec le tokenizer et le modèle.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Fournissez l'invite et exécutez le pipeline pour générer la réponse.
prompt = "How become a DataCamp certified data professional"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])
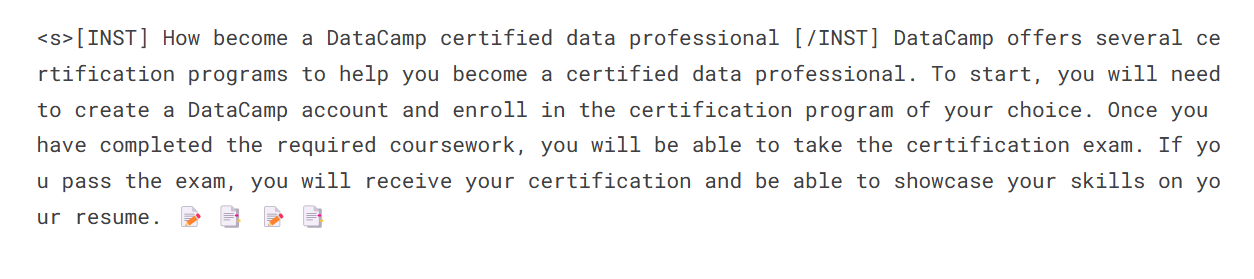
Nous allons maintenant fusionner l'adoptant avec le modèle de base afin que vous puissiez utiliser directement le modèle affiné, comme le modèle original de Mistral 7B, et exécuter l'inférence. Pour ce faire, nous utiliserons la fonction merge_and_unload.
Après avoir fusionné le modèle, nous pousserons à la fois le tokenizer et le modèle vers le Hugging Face Hub. Vous pouvez également suivre le carnet Kaggle si vous êtes bloqué quelque part.
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Image de kingabzpro/mistral_7b_guanaco
Comme vous pouvez le voir, au lieu d'un simple adaptateur, nous avons maintenant un modèle complet d'une taille de 13,98 Go.
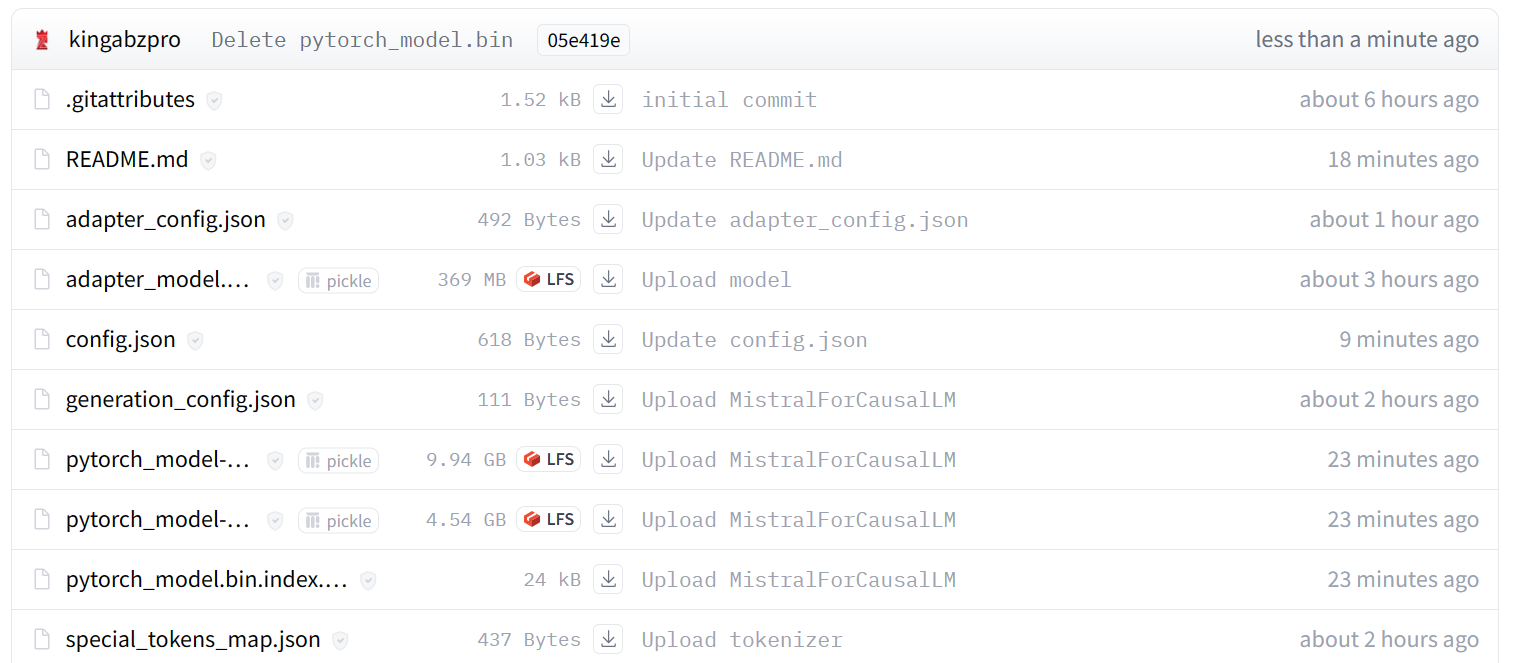
Image de kingabzpro/mistral_7b_guanaco
Pour montrer que nous pouvons charger et exécuter l'inférence sans l'aide du modèle de base, nous allons charger le modèle affiné de Hugging Face Hub et exécuter l'inférence.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model = "kingabzpro/mistral_7b_guanaco",
device_map="auto"
)
prompt = "How do I become a data engineer in 6 months?"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=200,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,)
print(sequences[0]['generated_text'])
Mistral 7B représente une avancée passionnante dans les capacités des grands modèles linguistiques. Grâce à des innovations telles que l'attention aux requêtes groupées et l'attention aux fenêtres coulissantes, il atteint des performances de pointe tout en restant suffisamment efficace pour être déployé.
Dans ce tutoriel, nous avons appris à accéder au modèle Mistral 7B sur Kaggle. En outre, nous avons appris à affiner le modèle sur un petit ensemble de données et à fusionner l'adoptant avec le modèle de base.
Ce guide est une ressource complète pour les passionnés d'apprentissage automatique et les débutants qui souhaitent expérimenter et former un modèle de langage étendu sur des GPU grand public.
Si vous êtes novice en matière de modèles linguistiques de grande taille, nous vous recommandons de suivre le cours Master LLMs Concepts. Pour ceux qui souhaitent entamer une carrière dans l'intelligence artificielle, s'inscrire au cursus de compétences AI Fundamentals est une excellente première étape.
Commencez dès aujourd'hui votre parcours d'apprentissage du LLM !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach