Cursus
Boîte à outils de programmation Python
13 h
La fonction Python map() est un outil intégré puissant qui permet d'utiliser des modèles de programmation fonctionnelle pour la transformation des données. Si vous souhaitez traiter de grands ensembles de données, nettoyer des données textuelles ou effectuer des calculs en masse, la fonction map() peut s'avérer très utile pour améliorer votre productivité.
Dans ce tutoriel, je vais vous présenter la syntaxe, les applications pratiques et les techniques avancées de la fonction Python « map() ». Nous examinerons également l'évaluation paresseuse pour l'efficacité de la mémoire et comparerons l'map() e à des alternatives telles que la compréhension de liste, et discuterons des meilleures pratiques pour une performance optimale.
Comprendre les itérateurs n'est que la première étape pour écrire un code efficace. Pour maîtriser véritablement la manipulation des données, il est nécessaire de disposer d'une boîte à outils de programmation Python complète. boîte à outils de programmation Python qui inclut tout, de la gestion des erreurs aux itérables avancés.
Avant d'examiner l'utilisation de la fonction ` map() `, examinons son fonctionnement. Comprendre sa syntaxe et son comportement peut nous aider à l'utiliser plus efficacement.
La fonction ` map() ` est un utilitaire Python intégré qui applique une fonction spécifiée à chaque élément d'un itérable (tel qu'une liste, un tuple ou une chaîne) et renvoie un itérateur avec les résultats transformés. Par conséquent, cela favorise l'immuabilité et la réutilisabilité du code, ce qui est essentiel dans les pipelines de traitement des données et les fonctionnalités de prétraitement pour les modèles d'apprentissage automatique.
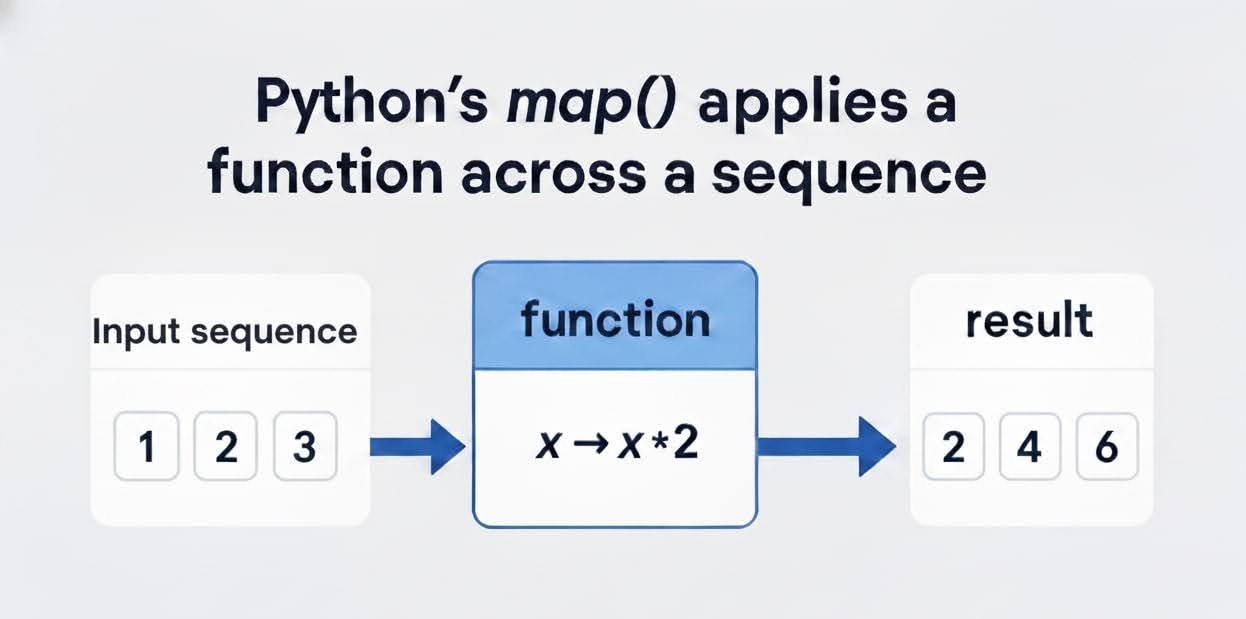
La syntaxe est simple, comme illustré ci-dessous :
map(function, iterable, ...) La fonction d'analyse ( function), qui peut être une fonction intégrée telle que len() ou une fonction personnalisée, est appliquée à chaque élément de l'analyseur de contenu ( iterable). Nous pouvons également ajouter plusieurs itérables pour permettre un mappage parallèle. Nous y reviendrons plus tard.
Contrairement à l'évaluation enthousiaste (qui calcule tout à l'avance), l'évaluation paresseuse ( map() ) utilise l'évaluation paresseuse. Il renvoie un objet map, un itérateur qui produit des valeurs à la demande. Cela permet de différer le calcul jusqu'à ce que vous l'itériez, ce qui permet d'économiser de la mémoire pour les grands ensembles de données.
Pour une illustration rapide, veuillez considérer cet exemple simple de mise au carré des nombres :
numbers = [1, 2, 3, 4]
squared = map(lambda x: x**2, numbers)
print(list(squared))[1, 4, 9, 16]La fonction ` map() ` nécessite au moins deux paramètres : une fonction appelable et un itérable. Les itérables supplémentaires facultatifs permettent de diffuser la fonction sur des séquences compressées, ce qui est idéal pour les opérations vectorisées similaires à la fonction` apply_along_axis()` de NumPy.
Dans Python 3, la fonction ` map() ` renvoie un objet map, une sous-classe itérative, plutôt qu'une liste. Ce changement améliore l'efficacité de la mémoire, car il n'alloue pas d'espace pour l'ensemble du résultat à l'avance. Pour concrétiser les résultats, veuillez les convertir explicitement :
À une liste : list(map(function, iterable))
À un ensemble : set(map(function, iterable))
Itérez directement : for item in map(function, iterable): ..
Voici un extrait de code illustrant la conversion :
words = ['python', 'data', 'science']
# Converts map object to list
lengths = list(map(len, words))
print(lengths)[6, 4, 7]Pour obtenir un aperçu rapide des différentes opérations Python utilisées tout au long de ce tutoriel, je vous recommande de consulter cette fiche de référence Python.
Dans Python 2, la fonction ` map() ` renvoyait immédiatement une liste, ce qui pouvait entraîner une surcharge de la mémoire pour les entrées volumineuses, un problème courant dans les scripts de données hérités. L'objet d' map e paresseux de Python 3 a modifié cela, s'alignant sur les protocoles d'itérateur pour une évolutivité dans les environnements de mégadonnées tels que PySpark.
Quelles sont les implications ? Gestion plus fluide des ensembles de données volumineux sans erreurs « Out of Memory » (OOM), bien qu'une conversion explicite soit nécessaire pour l'indexation. Par exemple, my_map[0] ne fonctionnera pas, nous devons donc utiliser next(iter(my_map)) à la place.
Si vous êtes habitué à la logique basée sur les listes, veuillez consulter le cours Python pour les utilisateurs de MATLAB pour faciliter votre transition des opérations vectorisées aux itérateurs Python.
Maintenant que nous avons examiné les bases, nous allons implémenter la fonction d' map(). Nous examinerons les méthodes les plus courantes pour appliquer l'map(), des fonctions intégrées simples aux transformations multi-itérables plus complexes.
La manière la plus simple d'utiliser map() est d'utiliser une fonction intégrée. Supposons que vous disposiez d'une liste de chaînes de caractères et que vous souhaitiez déterminer la longueur de chacune d'entre elles. Pour appliquer la fonction d'map():
Identifiez votre itérable : words = ['apple', 'banana', 'cherry']
Veuillez identifier votre fonction : La fonction intégrée d'len().
Veuillez appliquer map() : map(len, words)
Convertir en liste : list(map(len, words)
Veuillez examiner le code ci-dessous :
words = ['apple', 'banana', 'cherry']
# Apply the len() function to each item in the list
lengths_map = map(len, words)
# Convert the map object to a list to see the results
lengths_list = list(lengths_map)
print(lengths_list)[5, 6, 6]Comme nous pouvons le constater, cette approche est plus concise que la rédaction d'un boucle boucle, d'ajouter des éléments à une nouvelle liste et de gérer l'état de cette liste.
Souvent, l'opération que vous souhaitez effectuer est simple et de courte durée. Au lieu de définir une fonction complète avec def, il est possible d'utiliser une fonction lambda, qui est une petite fonction anonyme d'une seule ligne.
Ceci est extrêmement courant dans le traitement des données. Par exemple, si vous souhaitez élever au carré une liste de nombres, une fonction lambda est le choix idéal. Veuillez considérer l'exemple suivant :
numbers = [1, 2, 3, 4, 5]
# Use a lambda function to square each number
squared_map = map(lambda x: x * x, numbers)
squared_list = list(squared_map)
print(squared_list)[1, 4, 9, 16, 25]L'utilisation des fonctions lambda avec map() est recommandée dans les cas suivants :
La transformation est simple (idéalement, une seule expression).
La fonction n'est pas réutilisée ailleurs dans votre code.
Pour en savoir plus sur les fonctions lambda, veuillez consulter ce guide interactif détaillé sur Python lambda. tutoriel Python lambda .
Pour les transformations plus complexes ou répétées, veuillez utiliser une fonction personnalisée définie avec le mot-clé « def ». Cela rend votre code plus lisible, modulaire et plus facile à tester.
Supposons que vous disposiez d'une liste de températures en degrés Celsius et que vous deviez les convertir en degrés Fahrenheit. Nous pouvons procéder de la manière suivante :
def celsius_to_fahrenheit(c):
# The formula is (Celsius * 9/5) + 32
return (c * 9/5) + 32
celsius_temps = [0, 10, 25, 30.5, 100]
# Pass the user-defined function to map()
fahrenheit_map = map(celsius_to_fahrenheit, celsius_temps)
fahrenheit_list = list(fahrenheit_map)
print(fahrenheit_list)[32.0, 50.0, 77.0, 86.9, 212.0]L'utilisation d'une fonction avec un nom descriptif, tel que « celsius_to_fahrenheit() », permet de documenter clairement l'intention du code, ce qui en fait une pratique recommandée pour toute logique métier spécialisée.
Une fonctionnalité puissante d'map(), est sa capacité à traiter simultanément plusieurs itérables. Pour ce faire, votre fonction doit accepter le même nombre d'arguments que le nombre d'itérables que vous fournissez.
Supposons que vous disposiez de deux listes de nombres et que vous souhaitiez les additionner élément par élément :
list_a = [1, 2, 3, 4]
list_b = [10, 20, 30, 40]
# The lambda function now takes two arguments, x and y
sums_map = map(lambda x, y: x + y, list_a, list_b)
sums_list = list(sums_map)
print(sums_list)[11, 22, 33, 44]Maintenant, que se passe-t-il si les itérables ont des tailles différentes ? La fonction ` map() ` cessera le traitement dès que l'itérable le plus court sera épuisé, de sorte que la sortie aura la longueur de l'itérable le plus court. Veuillez observer cela en action à l'aide d'un exemple :
list_a = [1, 2, 3] # Length 3
list_b = [10, 20, 30, 40] # Length 4
# map() will stop after the 3rd element
short_map = map(lambda x, y: x + y, list_a, list_b)
print(list(short_map))[11, 22, 33]Ce comportement est prévisible et utile, car il permet d'éviter les exceptions d'IndexError. Si vous devez traiter tous les éléments et remplir une valeur par défaut pour la liste plus courte, vous pouvez utiliser itertools.zip_longest().
Ensuite, examinons quelques cas d'utilisation courants de la fonction d'map().
La fonction map() est polyvalente et s'avère très utile pour de nombreuses tâches courantes de traitement et de nettoyage des données. Examinons les situations dans lesquelles il vous sera le plus utile.
Il s'agit du cas d'utilisation le plus courant. Lorsque vous disposez d'une liste de nombres et que vous devez appliquer une opération mathématique uniforme à chaque élément, map() constitue une solution claire et efficace.
Nous avons déjà observé un excellent exemple de cela avec la conversion de Celsius en Fahrenheit dans la section précédente. Un autre scénario courant consiste à appliquer une formule financière, comme le calcul de la taxe de vente ou la conversion de devises.
Veuillez imaginer que vous disposez d'une liste de prix de produits en dollars américains et que vous devez les convertir en euros. Nous pouvons procéder comme indiqué ci-dessous :
def usd_to_eur(price_usd):
# Assuming a static exchange rate for this example
EXCHANGE_RATE = 0.92
return round(price_usd * EXCHANGE_RATE, 2)
prices_usd = [99.99, 150.00, 45.50, 78.25]
prices_eur_map = map(usd_to_eur, prices_usd)
print(list(prices_eur_map))[91.99, 138.0, 41.86, 71.99]Ce modèle est beaucoup plus lisible qu'une boucle « for », en particulier lorsque la logique de conversion est complexe et qu'il est préférable de la conserver dans sa propre fonction.
Le nettoyage des données implique souvent le traitement de grands volumes de données textuelles. données textuelles. Vous pourriez avoir des milliers d'entrées de texte qui doivent être normalisées avant d'être analysées. La fonction map() est idéale pour appliquer des méthodes de chaîne à une liste entière.
Par exemple, nettoyons une liste de noms en supprimant les espaces indésirables et en normalisant la casse :
raw_names = [' Alice Smith ', ' bob johnson', 'Charlie Brown ', ' david lee']
# Use map() with the built-in .strip() method
cleaned_names_map = map(str.strip, raw_names)
# Now chain another map() to convert to title case
# Note: we apply the second map to the *results* of the first map
final_names_map = map(str.title, cleaned_names_map)
print(list(final_names_map))['Alice Smith', 'Bob Johnson', 'Charlie Brown', 'David Lee']Cette capacité à enchaîner les opérations d'map() (car chacune renvoie un itérateur) est importante pour gérer efficacement les pipelines de données.
Souvent, il n'est pas souhaitable de transformer chaque élément d'. Vous souhaitez uniquement transformer les éléments qui répondent à une certaine condition. Il s'agit d'un modèle courant dans l'analyse de données, qui peut être facilement résolu en combinant l' map() avec la fonction Python filter() ..
La fonction filter(function, iterable) fonctionne de manière similaire à map(), mais elle renvoie uniquement renvoie que les éléments pour lesquels la fonction renvoie True.
Supposons que nous disposions d'une liste de mesures de capteurs et que nous souhaitions élever au carré uniquement les valeurs positives, en ignorant les valeurs négatives (qui pourraient être des erreurs). Nous pouvons y parvenir en :
Filtre : Tout d'abord, veuillez utiliser filter() pour obtenir uniquement les nombres positifs.
Carte : Ensuite, veuillez utiliser map() pour appliquer la fonction de mise au carré aux résultats filtrés.
readings = [10, -5, 3, -1, 20, 0]
# 1. Filter out the negative numbers
positive_readings = filter(lambda x: x > 0, readings)
# 2. Map the squaring function to the filtered iterator
squared_positives = map(lambda x: x * x, positive_readings)
print(list(squared_positives))[100, 9, 400]Étant donné que les fonctions map() et filter() sont paresseuses, ce processus en deux étapes est extrêmement efficace en termes de mémoire. Aucune liste intermédiaire n'est générée. Ce modèle « filter-then-map » constitue une alternative efficace à un modèle plus complexe. compréhension de liste Python.
Maintenant que nous avons abordé les concepts de base et les cas d'utilisation courants, examinons quelques exemples pratiques spécifiques qui illustrent comment la fonction map() fournit une syntaxe claire et efficace pour diverses tâches de transformation de données.
Il s'agit d'une tâche classique de traitement de chaînes de caractères. À partir d'une liste de chaînes, vous pouvez utiliser la fonction map() avec la méthode intégrée str.upper() pour convertir chaque élément en majuscules, comme illustré ci-dessous :
words = ['data science', 'python', 'map function']
# Apply the str.upper method to each item
upper_words = map(str.upper, words)
print(list(upper_words))['DATA SCIENCE', 'PYTHON', 'MAP FUNCTION']Il est parfois nécessaire d'extraire une information spécifique de chaque élément. Ici, nous pouvons utiliser la fonction ` lambda ` pour extraire le premier caractère (à l'index ` 0`) de chaque chaîne de caractères d'une liste.
names = ['Alice', 'Bob', 'Charlie']
# Use a lambda function to get the character at index 0
first_chars = map(lambda s: s[0], names)
print(list(first_chars))['A', 'B', 'C']Comme nous l'avons vu dans la section consacrée au traitement des chaînes de caractères, le nettoyage des espaces blancs est une étape fondamentale dans la préparation des données textuelles. L'utilisation de la méthode ` map() ` avec ` str.strip() ` est la manière la plus conforme à Python de procéder.
raw_data = [' value1 ', ' value2 ', ' value3']
# Apply the str.strip method
cleaned_data = map(str.strip, raw_data)
print(list(cleaned_data))['value1', 'value2', 'value3']Pour découvrir d'autres méthodes de gestion des données de type chaîne et liste, veuillez consulter ce tutoriel interactif sur les fonctions et méthodes de liste Python. fonctions et méthodes de listes Python fournit de nombreux exemples.
Dans une application Web ou axée sur les données, vous recevez souvent des données sous forme de liste de dictionnaires (comme une charge utile JSON). La fonction ` map() ` peut être utilisée pour préparer les données en vue d'une mise à jour de la base de données, par exemple dans Django ou lors de l'utilisation de MongoDB.
Supposons que nous disposions d'une liste de dictionnaires représentant les mises à jour de produits et que nous devions ajouter un horodatage d' processed ion à chacun d'entre eux avant de les envoyer à la base de données :
import datetime
def add_timestamp(record):
# Don't modify the original! Return a new copy.
new_record = record.copy()
new_record['processed_at'] = datetime.datetime.now()
return new_record
product_updates = [
{'id': 101, 'price': 50.00},
{'id': 102, 'price': 120.50},
{'id': 103, 'price': 75.25}
]
processed_data = map(add_timestamp, product_updates)
print(list(processed_data))[{'id': 101, 'price': 50.0, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123456)},
{'id': 102, 'price': 120.5, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123457)},
{'id': 103, 'price': 75.25, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123458)}]Ce modèle est idéal pour les mises à jour groupées et démontre véritablement l'importance de bien maîtriser les dictionnaires.
Pour les développeurs web, map() peut être un moteur de modèles simple. Vous pouvez convertir une liste d'éléments de données en une liste de chaînes HTML, prêtes à être affichées. Voici un exemple illustrant comment convertir une liste Python en une liste HTML non ordonnée :
def create_list_item(text):
return f"<li>{text}</li>"
menu_items = ['Home', 'About', 'Contact']
# Map the function to the list
html_items = map(create_list_item, menu_items)
# Join the results into a single string
html_list = "\n".join(html_items)
print(f"<ul>\n{html_list}\n</ul>")<ul>
<li>Home</li>
<li>About</li>
<li>Contact</li>
</ul>Bien que map() soit particulièrement adapté aux transformations simples et individuelles, sa véritable puissance se révèle dans des scénarios plus complexes. Examinons quelquesmodèlesavancés d' ,dans lesquels l' map() est un élément clé d'une stratégie sophistiquée de traitement des données.
Nous avons abordé l'utilisation de l' map() ation avec plusieurs itérables, et il s'agit d'un modèle fondamental pour de nombreux calculs scientifiques et de données avancés. Lorsque vous fournissez plusieurs itérables, l'opérateur ` map() ` agit comme une fermeture éclair, transmettant le i-ème élément de chaque itérable à votre fonction, ce qui signifie que le nombre d'arguments doit correspondre au nombre d'itérables.
Par exemple, pour calculer la valeur totale de différents produits dans un inventaire, vous pourriez disposer de trois listes distinctes. Veuillez observer comment map() est utilisé ici :
product_ids = ['A-101', 'B-202', 'C-303']
quantities = [50, 75, 30]
prices = [10.99, 5.49, 20.00]
# A function that takes three arguments
def calculate_line_total(pid, qty, price):
# Returns a tuple of (id, total_value)
return (pid, round(qty * price, 2))
# map() feeds one element from each list into the function
line_totals = map(calculate_line_total, product_ids, quantities, prices)
print(list(line_totals))[('A-101', 549.5), ('B-202', 411.75), ('C-303', 600.0)]Comme indiqué précédemment, l'map() ion s'arrête à la plus courte itération. Il s'agit d'une fonctionnalité intentionnelle visant à prévenir les exceptions d'IndexError. Si votre logique nécessite le traitement de tous les éléments de la liste la plus longue (par exemple, pour remplir les valeurs par défaut), veuillez utiliser plutôt itertools.zip_longest(). Vous pouvez l'apprendre ainsi que de nombreuses autres fonctions utiles dans ce cours sur la rédaction de code Python efficace.
Que se produit-il lorsque vos données sont déjà « compressées » dans une liste de tuples ? Ceci est extrêmement courant lorsque l'on travaille avec des résultats de requêtes de bases de données, des fichiers CSV ou des paires de coordonnées.
Supposons que vous disposiez d'une liste de points d'(x,y), comme indiqué ci-dessous, et que vous souhaitiez calculer le produit de chaque paire.
points = [(1, 5), (3, 9), (4, -2)]Vous pourriez utiliser un « lambda » avec « map() », mais cela peut s'avérer quelque peu complexe avec de longues fonctions imbriquées à l'intérieur :
list(map(lambda p: p[0] * p[1], points))Une solution plus propre et plus conforme à Python est la suivante : itertools.starmap(). Il requiert une fonction et un seul itérable d'itérables (comme notre liste de tuples). Il décompresse ensuite chaque tuple interne en tant qu'arguments pour la fonction. Observons cela en pratique :
import itertools
points = [(1, 5), (3, 9), (4, -2)]
# A simple function that takes two arguments
def product(x, y):
return x * y
# starmap() unpacks each tuple from 'points' into (x, y)
# and passes them to product()
products = itertools.starmap(product, points)
print(list(products))[5, 27, -8]starmap() est l'outil approprié lorsque les arguments de votre fonction sont déjà pré-groupés dans des tuples. Ce modèle est particulièrement utile lors du traitement de données géospatiales, telles qu'une liste de coordonnées (latitude, longitude). Pour approfondir ces concepts, je vous recommande de suivre ce cours sur travailler avec des données géospatiales dans Python.
La fonction d'map() e est très utile en programmation fonctionnelle. Nous pouvons le combiner avec d'autres outils fonctionnels tels que filter() et functools.reduce() afin de créer des pipelines de traitement de données propres et hautement efficaces.
Nous avons déjà observé la combinaison de filter() et map(). Maintenant, examinons comment utiliser reduce(), qui agrège (ou « réduit ») un itérable en une seule valeur cumulative.
Supposons que vous souhaitiez calculer la somme des carrés de tous les nombresimpairs d' s dans une liste donnée. Nous pouvons procéder de la manière suivante :
from functools import reduce
numbers = [1, 2, 3, 4, 5, 6, 7]
# 1. Filter: Get only the odd numbers
odd_numbers = filter(lambda x: x % 2 != 0, numbers)
# -> Iterator(1, 3, 5, 7)
# 2. Map: Square the odd numbers
squared_odds = map(lambda x: x * x, odd_numbers)
# -> Iterator(1, 9, 25, 49)
# 3. Reduce: Sum the results
# (lambda a, b: a + b) is the summing function
# 'a' is the accumulator, 'b' is the next item
total = reduce(lambda acc, val: acc + val, squared_odds)
print(total)84Il s'agit d'un modèle puissant. Étant donné que map() et filter() renvoient tous deux des itérateurs paresseux, l'ensemble de cette opération est extrêmement efficace en termes de mémoire. Aucune liste intermédiaire de grande taille n'est jamais créée en mémoire. Les données circulent à travers le pipeline, élément par élément.
L'une des fonctionnalités les plus importantes de l'map() e dans Python 3 est l'utilisation de l'évaluation paresseuse. Il est essentiel de comprendre ce concept pour écrire un code efficace et évolutif, en particulier pour les professionnels des données qui traitent régulièrement de grands ensembles de données. Dans cette section, nous examinerons comment cela fonctionne.
Dans Python 3, l'instruction « map() » n'exécute pas immédiatement votre fonction et ne renvoie pas de liste. Au lieu de cela, il renvoie un objet map, qui est un itérateur. Cet itérateur « sait » quelle fonction et quelles données utiliser, mais il n'effectue pas réellement le calcul tant que vous ne demandez pas explicitement l'élément suivant.
Ce calcul « juste à temps » présente des avantages considérables, tels que :
Efficacité de la mémoire : Un objet d' map s n'occupe qu'une petite quantité constante de mémoire, qu'il traite 10 éléments ou 10 milliards. Il ne crée pas de nouvelle liste en mémoire pour stocker tous les résultats.
Performances avec des ensembles de données volumineux : Lorsque vous itérez sur l'objet map (par exemple, dans une boucle for ), il calcule et produit une valeur à la fois. Cela vous permet de traiter des fichiers volumineux ou des flux de données qui seraient trop importants pour tenir en mémoire en une seule fois.
Enchaînabilité : Comme nous l'avons vu dans la section consacrée à la programmation fonctionnelle, les itérateurs paresseux peuvent être enchaînés (par exemple, map() après filter()). Étant donné qu'aucune liste intermédiaire n'est créée, les données transitent par le pipeline un élément à la fois, ce qui est extrêmement efficace.
Comparez cela à une compréhension de liste, qui utilise une évaluation anticipée de l' . Veuillez considérer l'exemple suivant :
squared = [x * x for x in range(10000000)]Ce code tentera immédiatement de créer une liste contenant 10 millions de nombres, ce qui pourrait nécessiter une quantité importante de mémoire vive.
Une expression génératrice est l'équivalent paresseux d'une compréhension de liste. Il est très similaire, mais se comporte comme map() en termes de mémoire.
squared = (x * x for x in range(10000000))Le code ci-dessus crée également un itérateur efficace en termes de mémoire, tout comme le ferait map(). Le choix entre une expression de type « map() » et une expression génératrice dépend souvent de la lisibilité. Une expression de type « map() » peut être plus claire lorsqu'il s'agit d'appliquer une fonction complexe existante, tandis qu'une expression génératrice est souvent plus lisible pour les expressions simples et en ligne.
Comparons l'utilisation de la mémoire pour ces opérations :
import tracemalloc
# Define the base data for comparison
large_numbers = range(10000000)
print("--- Memory Usage (Object Creation vs. List Materialization) ---")
# --- 1. Memory for List Comprehension (creates full list immediately) ---
tracemalloc.start()
list_comp_obj = [x * x for x in large_numbers]
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for List Comprehension (full list): {peak / (1024 * 1024):.2f} MB")
del list_comp_obj # Free up memory
# --- 2. Memory for Map Object (lazy) ---
tracemalloc.start()
map_obj = map(lambda x: x * x, large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Map Object (iterator itself): {peak / (1024 * 1024):.2f} MB")
del map_obj # Free up memory
# --- 3. Memory for Generator Expression (lazy) ---
tracemalloc.start()
gen_exp_obj = (x * x for x in large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Generator Expression (iterator itself): {peak / (1024 * 1024):.2f} MB")
del gen_exp_obj # Free up memory--- Memory Usage (Object Creation vs. List Materialization) ---
Peak RAM for List Comprehension (full list): 390.16 MB
Peak RAM for Map Object (iterator itself): 0.03 MB
Peak RAM for Generator Expression (iterator itself): 0.03 MBRemarque : Le « Peak RAM » (RAM maximale) pour les objets Map/Generator fait ici référence à la mémoire allouée à l'objet itérateur lui-même, et non à la mémoire de la liste complète qu'il produirait s'il était converti, ce qui démontre leur nature paresseuse.
Étant donné que map() renvoie un itérateur paresseux, il est souvent nécessaire de le matérialiser ou de le convertir en une collection concrète pour pouvoir utiliser les résultats.
Il est recommandé de convertir un objet map lorsque vous avez besoin de :
Veuillez consulter tous les résultats simultanément (par exemple, pour les enregistrer sur print() ).
Accédez aux éléments par index (par exemple, results[0]).
Obtenir la longueur des résultats (par exemple, len(results)).
Transmettez les résultats à une fonction qui nécessite une liste ou un ensemble.
Répétez l'opération plusieurs fois sur les résultats. (Un objet d'map, comme tous les itérateurs, est épuisable.) Vous ne pouvez effectuer qu'une seule boucle.
Voici comment convertir un objet map:
def square(x):
return x * x
numbers = [1, 2, 3, 3, 4, 5]
map_obj = map(square, numbers)
# --- Common Conversions ---
# 1. To a list:
list_results = list(map_obj)
print(f"List: {list_results}")
# Important
# The map_obj is now exhausted.
# If you try to do list(map_obj) again, you'll get an empty list.
# You must re-create the map object to reuse it.
map_obj = map(square, numbers) # Re-create it
# 2. To a set (removes duplicates):
set_results = set(map_obj)
print(f"Set: {set_results}")
map_obj = map(square, numbers) # Re-create it
# 3. To a tuple:
tuple_results = tuple(map_obj)
print(f"Tuple: {tuple_results}")List: [1, 4, 9, 9, 16, 25]
Set: {1, 4, 9, 16, 25}
Tuple: (1, 4, 9, 9, 16, 25)Pour convertir en dictionnaire (si la sortie est constituée de paires clé-valeur), vous pouvez utiliser map() avec dict(), mais souvent, les compréhensions de dictionnaire de Python compréhensions de dictionnaire sont plus claires.
Le point essentiel à retenir est d'agir de manière délibérée. Veuillez laisser map() rester un itérateur paresseux aussi longtemps que possible dans votre pipeline, et ne le convertir en liste qu'au tout dernier moment, lorsque vous avez réellement besoin de résultats concrets.
Cours Python
Cursus
Cursus
Cours
Tutoriel
Mark Pedigo
Tutoriel
Abid Ali Awan
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali