Lernpfad
Python Programming Toolbox
13 Std.
Die Python-Funktion „ map() ” ist ein echt starkes integriertes Tool, das funktionale Programmiermuster für die Datenumwandlung ermöglicht. Wenn du große Datensätze bearbeiten, Textdaten bereinigen oder Massenberechnungen durchführen willst, kann die Funktion „ map() “ echt hilfreich sein, um deine Produktivität zu steigern.
In diesem Tutorial zeige ich dir die Syntax, praktische Anwendungen und fortgeschrittenen Techniken der Python-Funktion „ map() “. Wir schauen uns auch die verzögerte Auswertung für die Speichereffizienz an, vergleichen „ map() “ mit Alternativen wie „list comprehension“ und reden über die besten Vorgehensweisen für optimale Leistung.
Iteratoren zu verstehen ist nur der erste Schritt, um effizienten Code zu schreiben. Um die Datenbearbeitung wirklich zu meistern, brauchst du eine komplette Python-Programmier-Toolbox, die alles von der Fehlerbehandlung bis hin zu fortgeschrittenen Iterablen abdeckt.
Bevor wir uns mit der Verwendung der Funktion „ map() “ beschäftigen, schauen wir uns mal an, wie diese Funktion funktioniert. Wenn wir die Syntax und das Verhalten verstehen, können wir es besser nutzen.
Die Funktion „ map() “ ist ein integriertes Python-Dienstprogramm, das eine bestimmte Funktion auf jedes Element in einer iterierbaren Struktur (wie einer Liste, einem Tupel oder einer Zeichenfolge) anwendet und einen Iterator mit den transformierten Ergebnissen zurückgibt. Dadurch fördert es die Unveränderlichkeit und Wiederverwendbarkeit von Code, was bei Datenverarbeitungs-Pipelines und Vorverarbeitungsfunktionen für Machine-Learning-Modelle wichtig ist.
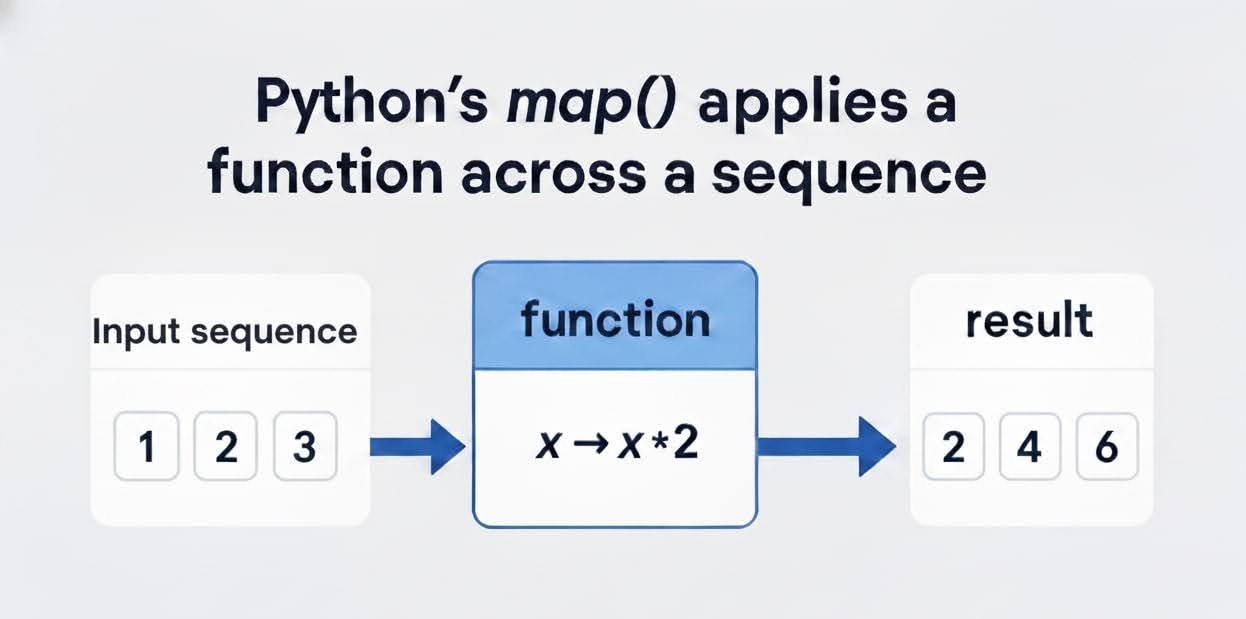
Die Syntax ist einfach, wie unten gezeigt:
map(function, iterable, ...) Die Funktion „ function “, die entweder eine integrierte Funktion wie „ len() “ oder eine benutzerdefinierte Funktion sein kann, wird auf jedes Element in „ iterable “ angewendet. Wir können auch mehrere Iterables hinzufügen, um paralleles Mapping zu ermöglichen. Darauf kommen wir später zurück.
Im Gegensatz zur eifrigen Auswertung (bei der alles im Voraus berechnet wird) nutzt „ map() “ die verzögerte Auswertung. Es gibt ein Map-Objekt zurück, einen Iterator, der Werte auf Anfrage liefert. Dadurch wird die Berechnung erst dann durchgeführt, wenn du die Daten durchläufst, was bei großen Datensätzen Speicherplatz spart.
Schau dir mal dieses einfache Beispiel für das Quadrieren von Zahlen an, um dir einen schnellen Überblick zu verschaffen:
numbers = [1, 2, 3, 4]
squared = map(lambda x: x**2, numbers)
print(list(squared))[1, 4, 9, 16]Die Funktion „ map() “ braucht mindestens zwei Parameter: eine aufrufbare Funktion und ein iterierbares Objekt. Optionale zusätzliche Iterables ermöglichen die Übertragung der Funktion auf gezippte Sequenzen, die sich perfekt für vektorisierte Operationen eignen, ähnlich wie bei NumPy's „ apply_along_axis() “.
In Python 3 gibt „ map() “ ein Map-Objekt zurück, das eine Unterklasse von Iterator ist, statt einer Liste. Diese Änderung macht den Speicher effizienter, weil nicht schon vorher Platz für das ganze Ergebnis reserviert wird. Um Ergebnisse zu bekommen, musst du sie explizit umwandeln:
An eine Liste: list(map(function, iterable))
Zu einem Set: set(map(function, iterable))
Direkt wiederholen: for item in map(function, iterable): ..
Hier ist ein Code-Schnipsel, der die Konvertierung zeigt:
words = ['python', 'data', 'science']
# Converts map object to list
lengths = list(map(len, words))
print(lengths)[6, 4, 7]Für einen schnellen Überblick über die verschiedenen Python-Operationen, die in diesem Tutorial verwendet werden, schau dir am besten diesen Python-Spickzettel an.
In Python 2 hat „ map() “ sofort eine Liste zurückgegeben, was bei großen Eingaben den Speicher überlasten konnte – ein häufiger Fehler in alten Datenskripten. Das Lazy - map -Objekt von Python 3 hat das geändert und passt sich jetzt den Iterator-Protokollen an, um die Skalierbarkeit in Big-Data-Umgebungen wie PySpark zu verbessern.
Was bedeutet das? Reibungslosere Verarbeitung riesiger Datensätze ohne Speicherausfälle (OOM-Fehler), auch wenn dafür eine explizite Konvertierung für die Indizierung nötig ist. Zum Beispiel funktioniert my_map[0] nicht, also müssen wir stattdessen next(iter(my_map)) nehmen.
Wenn du mit listenbasierter Logik vertraut bist, schau dir mal die Python für MATLAB-Anwender an, um den Umstieg von vektorisierten Operationen auf Python-Iteratoren zu vereinfachen.
Nachdem wir uns die Grundlagen angesehen haben, lass uns jetzt die Funktion „ map() ” umsetzen. Wir schauen uns die gängigsten Methoden an, um „ map() “ anzuwenden, von einfachen integrierten Funktionen bis hin zu komplexeren Transformationen mit mehreren Iterationen.
Am einfachsten kannst du „ map() “ mit einer eingebauten Funktion nutzen. Angenommen, du hast eine Liste von Zeichenfolgen und möchtest die Länge jeder einzelnen Zeichenfolge ermitteln. So benutzt du die Funktion „ map() “:
Identifiziere dein Iterable: words = ['apple', 'banana', 'cherry']
Finde raus, was deine Aufgabe ist: Die eingebaute Funktion „ len() “.
map() anwenden: map(len, words)
In eine Liste umwandeln: list(map(len, words)
Schauen wir uns mal den Code unten an:
words = ['apple', 'banana', 'cherry']
# Apply the len() function to each item in the list
lengths_map = map(len, words)
# Convert the map object to a list to see the results
lengths_list = list(lengths_map)
print(lengths_list)[5, 6, 6]Wie wir sehen können, ist das viel knapper als das Schreiben eines for Schleife zu schreiben, etwas an eine neue Liste anzuhängen und den Status dieser Liste zu verwalten.
Oft ist der Vorgang, den du machen willst, einfach und geht schnell. Anstatt eine komplette Funktion mit ` def` zu definieren, kannst du eine Lambda-Funktion verwenden, die eine kleine, anonyme Einzeiler-Funktion ist.
Das kommt in der Datenverarbeitung echt oft vor. Wenn du zum Beispiel eine Liste von Zahlen quadrieren willst, ist eine Lambda-Funktion genau das Richtige. Schauen wir uns das anhand eines Beispiels an:
numbers = [1, 2, 3, 4, 5]
# Use a lambda function to square each number
squared_map = map(lambda x: x * x, numbers)
squared_list = list(squared_map)
print(squared_list)[1, 4, 9, 16, 25]In den folgenden Fällen solltest du Lambda-Funktionen mit „ map() “ verwenden:
Die Umwandlung ist einfach (im Idealfall ein einziger Ausdruck).
Die Funktion wird an keiner anderen Stelle in deinem Code wiederverwendet.
Wenn du mehr über Lambda-Funktionen wissen willst, schau dir diese ausführliche interaktive Python-Lambda-Tutorial Tutorial.
Für kompliziertere oder wiederholte Umwandlungen kannst du eine benutzerdefinierte Funktion verwenden, die mit dem Schlüsselwort „ def “ definiert wird. Es macht deinen Code übersichtlicher, modularer und einfacher zu testen.
Angenommen, du hast eine Liste mit Temperaturen in Celsius und musst diese in Fahrenheit umrechnen. Das können wir so machen:
def celsius_to_fahrenheit(c):
# The formula is (Celsius * 9/5) + 32
return (c * 9/5) + 32
celsius_temps = [0, 10, 25, 30.5, 100]
# Pass the user-defined function to map()
fahrenheit_map = map(celsius_to_fahrenheit, celsius_temps)
fahrenheit_list = list(fahrenheit_map)
print(fahrenheit_list)[32.0, 50.0, 77.0, 86.9, 212.0]Wenn du eine Funktion mit einem aussagekräftigen Namen wie „ celsius_to_fahrenheit() ” benutzt, wird die Absicht des Codes klar dokumentiert, was eine bewährte Methode für jede spezielle Geschäftslogik ist.
Eine coole Funktion von „ map() “ ist, dass es mehrere Iterables gleichzeitig verarbeiten kann. Dafür muss deine Funktion genauso viele Argumente akzeptieren wie du Iterables bereitstellst.
Angenommen, du hast zwei Listen mit Zahlen und möchtest sie elementweise addieren:
list_a = [1, 2, 3, 4]
list_b = [10, 20, 30, 40]
# The lambda function now takes two arguments, x and y
sums_map = map(lambda x, y: x + y, list_a, list_b)
sums_list = list(sums_map)
print(sums_list)[11, 22, 33, 44]Was passiert, wenn die Iterables unterschiedliche Größen haben? Die Funktion „ map() “ hört auf zu arbeiten, sobald die kürzeste Iterable leer ist, also hat die Ausgabe die Länge der kürzesten Iterable. Schauen wir uns das mal anhand eines Beispiels an:
list_a = [1, 2, 3] # Length 3
list_b = [10, 20, 30, 40] # Length 4
# map() will stop after the 3rd element
short_map = map(lambda x, y: x + y, list_a, list_b)
print(list(short_map))[11, 22, 33]Dieses Verhalten ist vorhersehbar und nützlich, weil es Ausnahmen vom Typ „ IndexError “ verhindert. Wenn du alle Elemente bearbeiten und einen Standardwert für die kürzere Liste eingeben musst, kannst du „ itertools.zip_longest() “ verwenden.
Als Nächstes schauen wir uns ein paar alltägliche Anwendungsfälle für die Funktion „ map() “ an.
Die Funktion „ map() “ ist echt vielseitig und super praktisch für viele gängige Aufgaben bei der Datenverarbeitung und -bereinigung. Schauen wir mal, wo du es am nützlichsten findest.
Das ist der typischste Anwendungsfall. Wenn du eine Liste mit Zahlen hast und eine einheitliche mathematische Operation auf jedes einzelne Element anwenden musst, ist „ map() “ eine saubere und effiziente Lösung.
Wir haben schon im letzten Abschnitt ein super Beispiel dafür gesehen, nämlich die Umrechnung von Celsius in Fahrenheit. Ein weiteres häufiges Szenario ist die Anwendung einer Finanzformel, wie zum Beispiel die Berechnung der Umsatzsteuer oder die Umrechnung von Währungen.
Stell dir vor, du hast eine Liste mit Produktpreisen in USD und musst sie in EUR umrechnen. Das können wir wie folgt machen:
def usd_to_eur(price_usd):
# Assuming a static exchange rate for this example
EXCHANGE_RATE = 0.92
return round(price_usd * EXCHANGE_RATE, 2)
prices_usd = [99.99, 150.00, 45.50, 78.25]
prices_eur_map = map(usd_to_eur, prices_usd)
print(list(prices_eur_map))[91.99, 138.0, 41.86, 71.99]Dieses Muster ist viel übersichtlicher als eine „ for “-Schleife, vor allem wenn die Konvertierungslogik kompliziert ist und am besten in einer eigenen Funktion bleibt.
Datenbereinigung bedeutet oft, dass man mit vielen Textdaten. Du hast vielleicht Tausende von Texteinträgen, die vor der Analyse normalisiert werden müssen. Die Funktion „ map() “ ist super, um String-Methoden auf eine ganze Liste anzuwenden.
Lass uns zum Beispiel eine Liste mit Namen bereinigen, indem wir unerwünschte Leerzeichen entfernen und die Groß-/Kleinschreibung vereinheitlichen:
raw_names = [' Alice Smith ', ' bob johnson', 'Charlie Brown ', ' david lee']
# Use map() with the built-in .strip() method
cleaned_names_map = map(str.strip, raw_names)
# Now chain another map() to convert to title case
# Note: we apply the second map to the *results* of the first map
final_names_map = map(str.title, cleaned_names_map)
print(list(final_names_map))['Alice Smith', 'Bob Johnson', 'Charlie Brown', 'David Lee']Diese Möglichkeit, „ map() “-Operationen zu verketten (weil jede einen Iterator zurückgibt), ist wichtig für die effiziente Verarbeitung von Datenpipelines.
Oft willst du nicht jedes Element von „ “ umwandeln . Du willst nur Sachen umwandeln, die eine bestimmte Bedingung erfüllen. Das ist ein gängiges Muster in der Datenanalyse und lässt sich ganz einfach lösen, indem man „ map() “ mit der Python-Funktion „ filter() Funktion.
Die Funktion „ filter(function, iterable) ” funktioniert ähnlich wie „ map() ”, aber sie nur Elemente zurück, für die die Funktion „ True “ zurückgibt.
Nehmen wir mal an, wir haben eine Liste mit Sensorwerten und wollen nur die positiven Werte quadrieren, während wir die negativen (die vielleicht Fehler sind) einfach weglassen. Das können wir so machen:
Filter: Zuerst nimmst du „ filter() “, um nur die positiven Zahlen zu kriegen.
Karte: Dann nimm „ map() “, um die Quadratfunktion auf die gefilterten Ergebnisse anzuwenden.
readings = [10, -5, 3, -1, 20, 0]
# 1. Filter out the negative numbers
positive_readings = filter(lambda x: x > 0, readings)
# 2. Map the squaring function to the filtered iterator
squared_positives = map(lambda x: x * x, positive_readings)
print(list(squared_positives))[100, 9, 400]Weil sowohl map() als auch filter() nachlässig sind, ist dieser zweistufige Prozess super speichereffizient. Es werden keine Zwischenlisten erstellt. Dieses Muster „ filter-then-map “ ist eine coole Alternative zu einem komplizierteren Python-Listenkomprimierung.
Nachdem wir uns die grundlegenden Konzepte und gängigen Anwendungsfälle angesehen haben, schauen wir uns jetzt ein paar konkrete Beispiele an, die zeigen, wie die Funktion „ map() “ eine saubere und effiziente Syntax für verschiedene Datenumwandlungsaufgaben bietet.
Das ist eine typische Aufgabe in der Zeichenfolgenverarbeitung. Wenn du eine Liste von Zeichenfolgen hast, kannst du die Funktion „ map() “ zusammen mit der eingebauten Methode „ str.upper() “ nutzen, um jedes Element in Großbuchstaben umzuwandeln, wie unten gezeigt:
words = ['data science', 'python', 'map function']
# Apply the str.upper method to each item
upper_words = map(str.upper, words)
print(list(upper_words))['DATA SCIENCE', 'PYTHON', 'MAP FUNCTION']Manchmal musst du aus jedem Element eine bestimmte Info rausholen. Hier können wir die Funktion „ lambda “ nutzen, um das erste Zeichen (bei Index 0) aus jeder Zeichenfolge in einer Liste zu holen.
names = ['Alice', 'Bob', 'Charlie']
# Use a lambda function to get the character at index 0
first_chars = map(lambda s: s[0], names)
print(list(first_chars))['A', 'B', 'C']Wie wir im Abschnitt über die Verarbeitung von Zeichenfolgen gesehen haben, ist das Bereinigen von Leerzeichen ein wichtiger Schritt bei der Vorbereitung von Textdaten. „ map() “ mit „ str.strip() “ ist die Python-typischste Methode dafür.
raw_data = [' value1 ', ' value2 ', ' value3']
# Apply the str.strip method
cleaned_data = map(str.strip, raw_data)
print(list(cleaned_data))['value1', 'value2', 'value3']Weitere Möglichkeiten zum Verwalten von Zeichenfolgen- und Listendaten findest du in diesem interaktiven Tutorial zu Python-Listenfunktionen und -methoden bietet viele Beispiele.
In einer Web- oder datengesteuerten Anwendung kriegst du Daten oft als Liste von Wörterbüchern (wie eine JSON-Nutzlast). Die Funktion „ map() “ kann verwendet werden, um die Daten für eine Datenbankaktualisierung vorzubereiten, z. B. in Django oder bei der Arbeit mit MongoDB.
Stell dir vor, wir haben 'ne Liste von Wörterbüchern, die Produktaktualisierungen zeigen, und wir müssen jedem 'nem Zeitstempel „ processed ” hinzufügen, bevor wir sie an die Datenbank schicken:
import datetime
def add_timestamp(record):
# Don't modify the original! Return a new copy.
new_record = record.copy()
new_record['processed_at'] = datetime.datetime.now()
return new_record
product_updates = [
{'id': 101, 'price': 50.00},
{'id': 102, 'price': 120.50},
{'id': 103, 'price': 75.25}
]
processed_data = map(add_timestamp, product_updates)
print(list(processed_data))[{'id': 101, 'price': 50.0, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123456)},
{'id': 102, 'price': 120.5, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123457)},
{'id': 103, 'price': 75.25, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123458)}]Dieses Muster ist super für Batch-Updates und zeigt echt, wie wichtig es ist, sich mit Wörterbüchern.
Für Webentwickler kann „ map() “ eine einfache Template-Engine sein. Du kannst eine Liste von Datenelementen in eine Liste von HTML-Zeichenfolgen umwandeln, die dann gerendert werden können. Hier ist ein Beispiel, wie man eine Python-Liste in eine ungeordnete HTML-Liste umwandelt:
def create_list_item(text):
return f"<li>{text}</li>"
menu_items = ['Home', 'About', 'Contact']
# Map the function to the list
html_items = map(create_list_item, menu_items)
# Join the results into a single string
html_list = "\n".join(html_items)
print(f"<ul>\n{html_list}\n</ul>")<ul>
<li>Home</li>
<li>About</li>
<li>Contact</li>
</ul>map() t super für einfache Eins-zu-Eins-Transformationen, aber seine wahre Stärke zeigt sich in komplizierteren Situationen. Schauen wir uns ein paarfortgeschrittene Mustervon „ ” an,bei denen „ map() ” ein wichtiger Teil einer ausgeklügelten Datenverarbeitungsstrategie ist.
Wir haben kurz angesprochen, wie man „ map() ” mit mehreren iterierbaren Objekten benutzt, und das ist ein Muster, das für viele fortgeschrittene Daten- und wissenschaftliche Berechnungen echt wichtig ist. Wenn du mehrere iterierbare Objekte angibst, funktioniert „ map() “ wie ein Reißverschluss, der das i-te Element aus jedem iterierbaren Objekt an deine Funktion weitergibt. Das heißt, die Anzahl der Argumente muss mit der Anzahl der iterierbaren Objekte übereinstimmen.
Um zum Beispiel den Gesamtwert verschiedener Produkte in einem Inventar zu berechnen, könntest du drei separate Listen haben. Schauen wir mal, wie „ map() “ hier benutzt wird:
product_ids = ['A-101', 'B-202', 'C-303']
quantities = [50, 75, 30]
prices = [10.99, 5.49, 20.00]
# A function that takes three arguments
def calculate_line_total(pid, qty, price):
# Returns a tuple of (id, total_value)
return (pid, round(qty * price, 2))
# map() feeds one element from each list into the function
line_totals = map(calculate_line_total, product_ids, quantities, prices)
print(list(line_totals))[('A-101', 549.5), ('B-202', 411.75), ('C-303', 600.0)]Wie schon gesagt, hört „ map() “ beim kürzesten iterierbaren Element auf. Das ist absichtlich so gemacht, um Ausnahmen vom Typ „ IndexError “ zu vermeiden. Wenn du alle Elemente aus der längsten Liste verarbeiten musst (z. B. um Standardwerte einzutragen), denk dran, stattdessen „ itertools.zip_longest() “ zu benutzen. Du kannst das zusammen mit vielen anderen nützlichen Funktionen in diesem Kurs über schreibst du effizienten Python-Code.
Was passiert, wenn deine Daten schon in eine Liste von Tupeln gepackt sind? Das passiert echt oft, wenn man mit Datenbankabfrageergebnissen, CSV-Dateien oder Koordinatenpaaren arbeitet.
Angenommen, du hast eine Liste mit Punkten wie unten gezeigt ( (x,y) ) und möchtest das Produkt jedes Paares berechnen.
points = [(1, 5), (3, 9), (4, -2)]Du könntest eine „ lambda ” mit „ map() ” verwenden, aber das ist bei langen verschachtelten Funktionen etwas umständlich:
list(map(lambda p: p[0] * p[1], points))Eine viel sauberere, Python-typischere Lösung ist itertools.starmap(). Es braucht eine Funktion und ein einzelnes iterierbares Element von iterierbaren Elementen (wie unsere Liste von Tupeln). Dann packt es jedes innere Tupel als Argumente für die Funktion aus. Schauen wir uns das mal in Aktion an:
import itertools
points = [(1, 5), (3, 9), (4, -2)]
# A simple function that takes two arguments
def product(x, y):
return x * y
# starmap() unpacks each tuple from 'points' into (x, y)
# and passes them to product()
products = itertools.starmap(product, points)
print(list(products))[5, 27, -8]starmap() ist das richtige Tool, wenn die Argumente deiner Funktion schon in Tupeln gepackt sind. Dieses Muster ist besonders praktisch, wenn du Geodaten bearbeitest, wie zum Beispiel eine Liste von (latitude, longitude) Koordinaten. Wenn du dich näher mit diesen Konzepten beschäftigen willst, empfehle ich dir diesen Kurs zum Thema Arbeiten mit Geodaten in Python.
Die Funktion „ map() ” ist in der funktionalen Programmierung echt nützlich. Wir können es mit anderen coolen Tools wie filter() und functools.reduce() kombinieren, um saubere, super effiziente Datenverarbeitungs-Pipelines zu erstellen.
Wir haben schon die Kombination von filter() und map() gesehen. Schauen wir uns jetzt an, wie man „ reduce() “ benutzt, das eine Iterable zu einem einzigen kumulativen Wert zusammenfasst (oder „reduziert“).
Angenommen, du willst die Summe der Quadrate aller ungeraden Zahlen ( ) in einer bestimmten Liste berechnen . Das können wir so machen:
from functools import reduce
numbers = [1, 2, 3, 4, 5, 6, 7]
# 1. Filter: Get only the odd numbers
odd_numbers = filter(lambda x: x % 2 != 0, numbers)
# -> Iterator(1, 3, 5, 7)
# 2. Map: Square the odd numbers
squared_odds = map(lambda x: x * x, odd_numbers)
# -> Iterator(1, 9, 25, 49)
# 3. Reduce: Sum the results
# (lambda a, b: a + b) is the summing function
# 'a' is the accumulator, 'b' is the next item
total = reduce(lambda acc, val: acc + val, squared_odds)
print(total)84Das ist ein echt starkes Muster. Weil sowohl „ map() ” als auch „ filter() ” verzögerte Iteratoren zurückgeben, ist diese ganze Operation echt speichereffizient. Es werden nie große Zwischenlisten im Speicher erstellt. Die Daten fließen Stück für Stück durch die Pipeline.
Eines der wichtigsten Features von „ map() ” in Python 3 ist, dass es „lazy evaluation” nutzt. Dieses Konzept zu verstehen ist wichtig, um effizienten, skalierbaren Code zu schreiben, vor allem für Leute, die regelmäßig mit großen Datensätzen arbeiten. In diesem Abschnitt schauen wir uns an, wie das funktioniert.
In Python 3 führt „ map() “ deine Funktion nicht sofort aus und gibt keine Liste zurück. Stattdessen gibt es ein „ map “-Objekt zurück, das ein Iterator ist. Dieser Iterator „weiß“, welche Funktion und welche Daten er verwenden soll, aber er macht die Berechnung erst, wenn du explizit nach dem nächsten Element fragst.
Diese „Just-in-time”-Berechnung hat echt coole Vorteile, wie zum Beispiel:
Speichereffizienz: Ein „ map “-Objekt braucht nur wenig Speicherplatz, egal ob es 10 oder 10 Milliarden Elemente verarbeitet. Es wird keine neue Liste im Speicher erstellt, um alle Ergebnisse zu speichern.
Leistung mit großen Datensätzen: Wenn du das Objekt „ map “ durchläufst (z. B. in einer Schleife „ for “), berechnet es jeweils einen Wert und gibt diesen aus. Damit kannst du riesige Dateien oder Datenströme bearbeiten, die zu groß sind, um sie auf einmal in den Arbeitsspeicher zu laden.
Verkettbarkeit: Wie wir im Abschnitt über funktionale Programmierung gesehen haben, können lazy iterators miteinander verkettet werden (z. B. map() nach filter()). Da keine Zwischenlisten erstellt werden, fließen die Daten einzeln durch die Pipeline, was echt effizient ist.
Vergleich das mal mit einer Listenkomprimierung, die eine Eager- --Auswertung nutzt. Schau dir mal dieses Beispiel an:
squared = [x * x for x in range(10000000)]Dieser Code versucht sofort, eine Liste mit 10 Millionen Zahlen zu erstellen, was möglicherweise eine riesige Menge an RAM verbraucht.
Ein Generatorausdruck ist das Lazy-Äquivalent einer Listenkomprimierung. Es sieht ziemlich ähnlich aus, verhält sich aber in Sachen Speicher wie „ map() “.
squared = (x * x for x in range(10000000))Der obige Code erstellt auch einen speichereffizienten Iterator, genau wie „ map() “. Die Entscheidung zwischen „ map() ” und einem Generatorausdruck hängt oft von der Lesbarkeit ab. „ map() ” kann bei der Anwendung einer komplexen, vorhandenen Funktion klarer sein, während ein Generatorausdruck bei einfachen Inline-Ausdrücken oft besser lesbar ist.
Schauen wir mal, wie viel Speicher diese Vorgänge brauchen:
import tracemalloc
# Define the base data for comparison
large_numbers = range(10000000)
print("--- Memory Usage (Object Creation vs. List Materialization) ---")
# --- 1. Memory for List Comprehension (creates full list immediately) ---
tracemalloc.start()
list_comp_obj = [x * x for x in large_numbers]
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for List Comprehension (full list): {peak / (1024 * 1024):.2f} MB")
del list_comp_obj # Free up memory
# --- 2. Memory for Map Object (lazy) ---
tracemalloc.start()
map_obj = map(lambda x: x * x, large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Map Object (iterator itself): {peak / (1024 * 1024):.2f} MB")
del map_obj # Free up memory
# --- 3. Memory for Generator Expression (lazy) ---
tracemalloc.start()
gen_exp_obj = (x * x for x in large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Generator Expression (iterator itself): {peak / (1024 * 1024):.2f} MB")
del gen_exp_obj # Free up memory--- Memory Usage (Object Creation vs. List Materialization) ---
Peak RAM for List Comprehension (full list): 390.16 MB
Peak RAM for Map Object (iterator itself): 0.03 MB
Peak RAM for Generator Expression (iterator itself): 0.03 MBAnmerkung: Der „Peak RAM” für Map-/Generator-Objekte bezieht sich hier auf den Speicher, der dem Iterator-Objekt selbst zugewiesen wird, nicht auf den Speicher der vollständigen Liste, die bei einer Konvertierung entstehen würde, was ihre „lazy nature” zeigt.
Da „ map() “ einen verzögerten Iterator zurückgibt, musst du ihn oft materialisieren oder in eine konkrete Sammlung umwandeln, um die Ergebnisse tatsächlich nutzen zu können.
Du solltest ein „ map “-Objekt konvertieren, wenn du:
Schau dir alle Ergebnisse auf einmal an (z. B. um sie zu „ print() “).
Greif auf Elemente über den Index zu (z. B. results[0]).
Hol dir die Länge der Ergebnisse (z. B. len(results)).
Gib die Ergebnisse an eine Funktion weiter, die eine Liste oder Menge braucht.
Geh die Ergebnisse mehrmals durch. (Ein Objekt vom Typ „ map “ ist, wie alle Iteratoren, erschöpfbar.) Du kannst es nur einmal durchlaufen.
So konvertierst du ein „ map “-Objekt:
def square(x):
return x * x
numbers = [1, 2, 3, 3, 4, 5]
map_obj = map(square, numbers)
# --- Common Conversions ---
# 1. To a list:
list_results = list(map_obj)
print(f"List: {list_results}")
# Important
# The map_obj is now exhausted.
# If you try to do list(map_obj) again, you'll get an empty list.
# You must re-create the map object to reuse it.
map_obj = map(square, numbers) # Re-create it
# 2. To a set (removes duplicates):
set_results = set(map_obj)
print(f"Set: {set_results}")
map_obj = map(square, numbers) # Re-create it
# 3. To a tuple:
tuple_results = tuple(map_obj)
print(f"Tuple: {tuple_results}")List: [1, 4, 9, 9, 16, 25]
Set: {1, 4, 9, 16, 25}
Tuple: (1, 4, 9, 9, 16, 25)Um in ein Wörterbuch zu konvertieren (wenn die Ausgabe Schlüssel-Wert-Paare sind), kannst du „ map() “ mit „ dict() “ verwenden, aber oft ist Pythons Dictionary Comprehensions einfacher zu verstehen.
Das Wichtigste ist, bewusst zu handeln. Lass „ map() “ so lange wie möglich ein fauler Iterator in deiner Pipeline bleiben und wandle ihn erst ganz am Ende in eine Liste um, wenn du tatsächlich konkrete Ergebnisse brauchst.
Python-Kurse
Lernpfad
Lernpfad
Kurs
Tutorial
Mark Pedigo
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Javier Canales Luna

