Programa
Caixa de ferramentas de programação Python
13 h
A função ` map() ` do Python é uma ferramenta integrada super útil que permite usar padrões de programação funcional para transformar dados. Se você quer processar grandes conjuntos de dados, limpar dados de texto ou fazer cálculos em massa, a função map() pode ser muito útil para aumentar a produtividade.
Neste tutorial, vou mostrar a sintaxe, as aplicações práticas e as técnicas avançadas da função ` map() ` do Python. Também vamos dar uma olhada na avaliação preguiçosa para eficiência de memória e comparar o ` map() ` com alternativas como compreensão de lista, além de discutir as melhores práticas para um desempenho ideal.
Entender os iteradores é só o primeiro passo pra escrever um código eficiente. Para realmente dominar a manipulação de dados, você precisa de uma caixa de ferramentas de programação Python que inclua tudo, desde tratamento de erros até iteráveis avançados.
Antes de ver como usar a função ` map() `, vamos dar uma olhada em como ela funciona. Entender sua sintaxe e comportamento pode nos ajudar a aplicá-la de forma mais eficaz.
A função ` map() ` é um utilitário embutido do Python que aplica uma função específica a cada item em um iterável (como uma lista, tupla ou string) e retorna um iterador com os resultados transformados. Como resultado, isso ajuda a manter a imutabilidade e a reutilização do código, o que é importante em pipelines de processamento de dados e recursos de pré-processamento para modelos de machine learning.
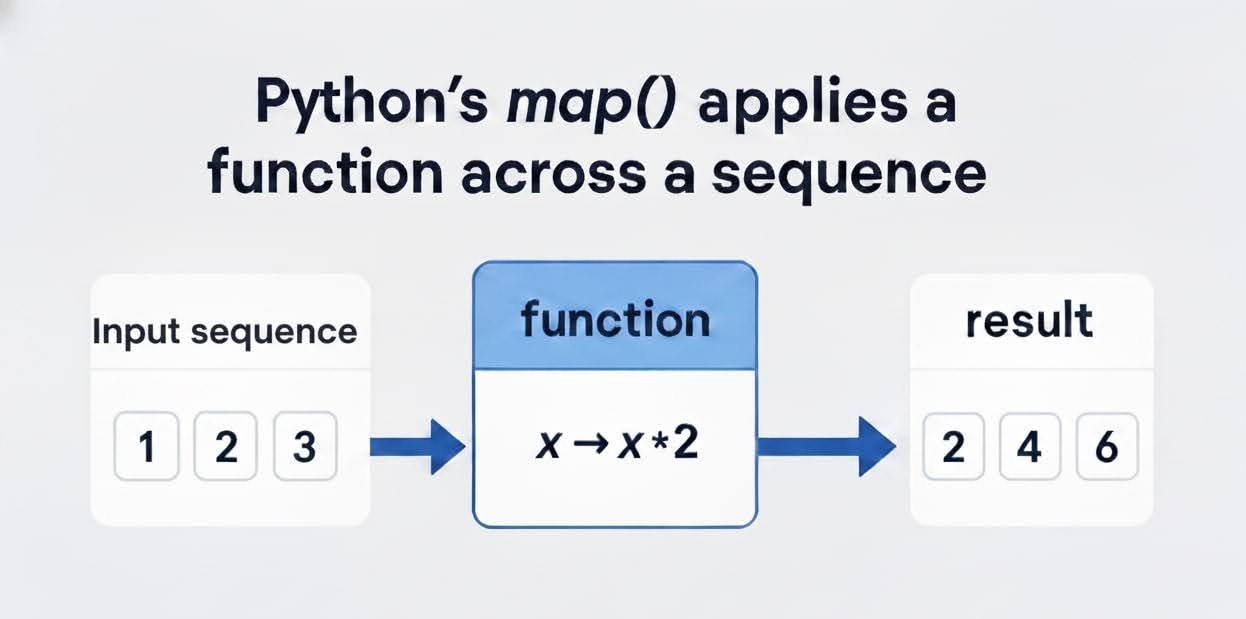
A sintaxe é simples, como mostrado abaixo:
map(function, iterable, ...) A função ` function`, que pode ser uma função integrada como ` len() ` ou uma função personalizada, é aplicada a todos os itens no ` iterable`. Também podemos adicionar vários iteráveis para permitir o mapeamento paralelo. Vamos falar sobre isso mais tarde.
Diferente da avaliação ansiosa (que calcula tudo de uma vez), a avaliação preguiçosa usa a avaliação preguiçosa ( map() ). Ele retorna um objeto mapa, um iterador que gera valores quando você precisa. Isso adia o cálculo até você iterar sobre ele, economizando memória para grandes conjuntos de dados.
Para uma visualização rápida, veja este exemplo simples de elevar números ao quadrado:
numbers = [1, 2, 3, 4]
squared = map(lambda x: x**2, numbers)
print(list(squared))[1, 4, 9, 16]A função ` map() ` precisa de pelo menos dois parâmetros: uma função chamável e um iterável. Iteráveis adicionais opcionais permitem transmitir a função por sequências compactadas, que são perfeitas para operações vetorizadas semelhantes ao apply_along_axis() do NumPy.
No Python 3, map() retorna um objeto mapa, uma subclasse iteradora, em vez de uma lista. Essa mudança melhora a eficiência da memória, já que não aloca espaço para todo o resultado antecipadamente. Para materializar os resultados, converta-os explicitamente:
Para uma lista: list(map(function, iterable))
Para um conjunto: set(map(function, iterable))
Repita diretamente: for item in map(function, iterable): ..
Aqui está um trecho de código que mostra a conversão:
words = ['python', 'data', 'science']
# Converts map object to list
lengths = list(map(len, words))
print(lengths)[6, 4, 7]Pra ter uma visão geral rápida das diferentes operações Python usadas ao longo deste tutorial, recomendo que você dê uma olhada nesta folha de referência Python.
No Python 2, map() devolvia uma lista, o que podia sobrecarregar a memória para entradas grandes, uma armadilha comum em scripts de dados antigos. O objeto lazy map do Python 3 mudou isso, alinhando-se aos protocolos iteradores para escalabilidade em ambientes de big data como o PySpark.
As implicações? Manipulação mais suave de conjuntos de dados enormes sem erros de memória insuficiente (OOM), embora exija conversão explícita para indexação. Por exemplo, my_map[0] não vai funcionar, então temos que usar next(iter(my_map)) em vez disso.
Se você está acostumado com a lógica baseada em listas, dê uma olhada no Python para usuários do MATLAB para facilitar sua transição de operações vetorizadas para iteradores Python.
Agora que já vimos o básico, vamos implementar a função map(). Vamos ver as formas mais comuns de aplicar map(), desde funções integradas simples até transformações multi-iteráveis mais complexas.
A maneira mais fácil de usar o map() é com uma função integrada. Digamos que você tem uma lista de strings e quer descobrir o comprimento de cada uma delas. Para usar a função map():
Identifique seu iterável: words = ['apple', 'banana', 'cherry']
Identifique sua função: A função integrada len().
Aplicar mapa(): map(len, words)
Converter para uma lista: list(map(len, words)
Vamos dar uma olhada no código abaixo:
words = ['apple', 'banana', 'cherry']
# Apply the len() function to each item in the list
lengths_map = map(len, words)
# Convert the map object to a list to see the results
lengths_list = list(lengths_map)
print(lengths_list)[5, 6, 6]Como dá pra ver, isso é mais direto do que escrever um para , adicionar a uma nova lista e gerenciar o estado dessa lista.
Muitas vezes, a operação que você quer fazer é simples e rápida. Em vez de definir uma função completa com def, você pode usar uma função lambda, que é uma função pequena, anônima e de uma linha.
Isso é super comum no processamento de dados. Por exemplo, se você quiser elevar ao quadrado uma lista de números, uma função lambda é a escolha perfeita. Vamos ver isso com um exemplo abaixo:
numbers = [1, 2, 3, 4, 5]
# Use a lambda function to square each number
squared_map = map(lambda x: x * x, numbers)
squared_list = list(squared_map)
print(squared_list)[1, 4, 9, 16, 25]Recomenda-se usar funções lambda com o map() nos seguintes casos:
A transformação é simples (idealmente, uma única expressão).
A função não é reutilizada em nenhum outro lugar do seu código.
Pra saber mais sobre funções lambda, dá uma olhada nesse guia interativo detalhado sobre Python lambda. tutorial lambda Python .
Para transformações mais complexas ou repetidas, use uma função personalizada definida com a palavra-chave ` def `. Isso deixa seu código mais fácil de ler, modular e mais simples de testar.
Digamos que você tenha uma lista de temperaturas em Celsius e precise convertê-las para Fahrenheit. Podemos fazer isso da seguinte maneira:
def celsius_to_fahrenheit(c):
# The formula is (Celsius * 9/5) + 32
return (c * 9/5) + 32
celsius_temps = [0, 10, 25, 30.5, 100]
# Pass the user-defined function to map()
fahrenheit_map = map(celsius_to_fahrenheit, celsius_temps)
fahrenheit_list = list(fahrenheit_map)
print(fahrenheit_list)[32.0, 50.0, 77.0, 86.9, 212.0]Usar uma função com um nome descritivo, como ` celsius_to_fahrenheit()`, deixa bem claro o que o código quer fazer, o que é uma boa prática para qualquer lógica de negócio especializada.
Uma característica poderosa do map() é a capacidade de processar vários iteráveis ao mesmo tempo. Pra fazer isso, sua função precisa aceitar o mesmo número de argumentos que o número de iteráveis que você fornece.
Digamos que você tenha duas listas de números e queira somá-las elemento por elemento:
list_a = [1, 2, 3, 4]
list_b = [10, 20, 30, 40]
# The lambda function now takes two arguments, x and y
sums_map = map(lambda x, y: x + y, list_a, list_b)
sums_list = list(sums_map)
print(sums_list)[11, 22, 33, 44]E se os iteráveis tiverem tamanhos diferentes? A função ` map() ` vai parar de processar assim que o iterável mais curto acabar, então a saída vai ter o comprimento do iterável mais curto. Vamos ver isso em ação com um exemplo:
list_a = [1, 2, 3] # Length 3
list_b = [10, 20, 30, 40] # Length 4
# map() will stop after the 3rd element
short_map = map(lambda x, y: x + y, list_a, list_b)
print(list(short_map))[11, 22, 33]Esse comportamento é previsível e útil, evitando exceções do tipo " IndexError ". Se você precisar processar todos os elementos e preencher um valor padrão para a lista mais curta, pode usar itertools.zip_longest().
A seguir, vamos ver alguns casos de uso cotidiano da função ` map() `.
A função map() é versátil e muito útil para muitas tarefas comuns de processamento e limpeza de dados. Vamos dar uma olhada onde você vai achar isso mais útil.
Esse é o caso de uso mais clássico. Quando você tem uma lista de números e precisa aplicar uma operação matemática igual a todos os elementos, o map() é uma solução simples e eficiente.
Já vimos um ótimo exemplo disso com a conversão de Celsius para Fahrenheit na seção anterior. Outro cenário comum é usar uma fórmula financeira, tipo calcular o imposto sobre vendas ou converter moedas.
Imagina que você tem uma lista de preços de produtos em dólares americanos e precisa convertê-los para euros. Podemos fazer isso como mostrado abaixo:
def usd_to_eur(price_usd):
# Assuming a static exchange rate for this example
EXCHANGE_RATE = 0.92
return round(price_usd * EXCHANGE_RATE, 2)
prices_usd = [99.99, 150.00, 45.50, 78.25]
prices_eur_map = map(usd_to_eur, prices_usd)
print(list(prices_eur_map))[91.99, 138.0, 41.86, 71.99]Esse padrão é bem mais fácil de entender do que um loop “ for ”, principalmente quando a lógica de conversão é complexa e é melhor mantê-la dentro de sua própria função.
A limpeza de dados geralmente envolve o processamento de grandes volumes de dados de texto. Você pode ter milhares de entradas de texto que precisam ser normalizadas antes da análise. A função ` map() ` é perfeita para aplicar métodos de string a uma lista inteira.
Por exemplo, vamos limpar uma lista de nomes removendo espaços indesejados e padronizando as letras maiúsculas e minúsculas:
raw_names = [' Alice Smith ', ' bob johnson', 'Charlie Brown ', ' david lee']
# Use map() with the built-in .strip() method
cleaned_names_map = map(str.strip, raw_names)
# Now chain another map() to convert to title case
# Note: we apply the second map to the *results* of the first map
final_names_map = map(str.title, cleaned_names_map)
print(list(final_names_map))['Alice Smith', 'Bob Johnson', 'Charlie Brown', 'David Lee']Essa capacidade de encadear operações de map() (porque cada uma retorna um iterador) é importante para lidar com pipelines de dados eficientes.
Muitas vezes, você não quer transformar todos os itens. Você só quer transformar itens que atendam a uma determinada condição. Esse é um padrão comum na análise de dados e é fácil de resolver combinando o map() com Python filter() ..
A função ` filter(function, iterable) ` funciona de forma parecida com ` map()`, mas apenas retorna itens para os quais a função retorna True.
Digamos que temos uma lista de leituras de sensores e queremos elevar ao quadrado apenas os valores positivos, ignorando os negativos (que podem ser erros). Podemos fazer isso da seguinte forma:
Filtro: Primeiro, use filter() para obter apenas os números positivos.
Mapa: Depois, use map() para aplicar a função de quadratura aos resultados filtrados.
readings = [10, -5, 3, -1, 20, 0]
# 1. Filter out the negative numbers
positive_readings = filter(lambda x: x > 0, readings)
# 2. Map the squaring function to the filtered iterator
squared_positives = map(lambda x: x * x, positive_readings)
print(list(squared_positives))[100, 9, 400]Como tanto map() quanto filter() são preguiçosos, esse processo de duas etapas é super eficiente em termos de memória. Não são criadas listas intermediárias. Esse padrão filter-then-map é uma alternativa poderosa para um compreensão de lista Python.
Agora que já vimos os conceitos básicos e os casos de uso mais comuns, vamos dar uma olhada em alguns exemplos práticos específicos que mostram como a função map() oferece uma sintaxe limpa e eficiente para várias tarefas de transformação de dados.
Essa é uma tarefa clássica de processamento de strings. Com uma lista de strings, você pode usar a função map() com o método embutido str.upper() para converter todos os itens para maiúsculas, como mostrado abaixo:
words = ['data science', 'python', 'map function']
# Apply the str.upper method to each item
upper_words = map(str.upper, words)
print(list(upper_words))['DATA SCIENCE', 'PYTHON', 'MAP FUNCTION']Às vezes, você precisa pegar uma informação específica de cada item. Aqui, podemos usar uma função lambda para pegar o primeiro caractere (no índice 0) de cada string em uma lista.
names = ['Alice', 'Bob', 'Charlie']
# Use a lambda function to get the character at index 0
first_chars = map(lambda s: s[0], names)
print(list(first_chars))['A', 'B', 'C']Como vimos na seção sobre processamento de strings, limpar espaços em branco é uma etapa fundamental na preparação de dados de texto. Usar map() com str.strip() é a maneira mais Pythonic de fazer isso.
raw_data = [' value1 ', ' value2 ', ' value3']
# Apply the str.strip method
cleaned_data = map(str.strip, raw_data)
print(list(cleaned_data))['value1', 'value2', 'value3']Para saber mais maneiras de gerenciar dados de string e lista, dá uma olhada nesse tutorial interativo sobre funções e métodos de listas Python tem vários exemplos.
Em um aplicativo web ou orientado a dados, você geralmente recebe dados como uma lista de dicionários (como uma carga JSON). A função ` map() ` pode ser usada para preparar os dados para uma atualização do banco de dados, como no Django ou ao trabalhar com o MongoDB.
Imaginemos que temos uma lista de dicionários representando atualizações de produtos e precisamos adicionar um carimbo de data/hora ( processed ) a cada um deles antes de enviá-los ao banco de dados:
import datetime
def add_timestamp(record):
# Don't modify the original! Return a new copy.
new_record = record.copy()
new_record['processed_at'] = datetime.datetime.now()
return new_record
product_updates = [
{'id': 101, 'price': 50.00},
{'id': 102, 'price': 120.50},
{'id': 103, 'price': 75.25}
]
processed_data = map(add_timestamp, product_updates)
print(list(processed_data))[{'id': 101, 'price': 50.0, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123456)},
{'id': 102, 'price': 120.5, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123457)},
{'id': 103, 'price': 75.25, 'processed_at': datetime.datetime(2025, 11, 11, 13, 40, 25, 123458)}]Esse padrão é ideal para atualizações em lote e mostra o quanto é importante saber usar os dicionários. dicionários.
Para desenvolvedores web, o map() pode ser um mecanismo de modelos simples. Você pode transformar uma lista de itens de dados em uma lista de strings HTML, prontas para serem renderizadas. Abaixo está um exemplo de como transformar uma lista Python em uma lista HTML não ordenada:
def create_list_item(text):
return f"<li>{text}</li>"
menu_items = ['Home', 'About', 'Contact']
# Map the function to the list
html_items = map(create_list_item, menu_items)
# Join the results into a single string
html_list = "\n".join(html_items)
print(f"<ul>\n{html_list}\n</ul>")<ul>
<li>Home</li>
<li>About</li>
<li>Contact</li>
</ul>Embora o map() seja ótimo para transformações simples e diretas, seu verdadeiro poder aparece em cenários mais complexos. Vamos dar uma olhada em algunspadrõesavançados de ,onde o map() é um componente essencial de uma estratégia sofisticada de processamento de dados.
Já falamos sobre como usar o ` map() ` com vários iteráveis, e esse é um padrão que é essencial para muitos cálculos científicos e de dados avançados. Quando você fornece vários iteráveis, map() funciona como um zíper, passando o i-ésimo elemento de cada iterável para sua função, o que significa que o número de argumentos deve corresponder ao número de iteráveis.
Por exemplo, pra calcular o valor total de diferentes produtos em um inventário, você pode ter três listas separadas. Vamos ver como o map() é usado aqui:
product_ids = ['A-101', 'B-202', 'C-303']
quantities = [50, 75, 30]
prices = [10.99, 5.49, 20.00]
# A function that takes three arguments
def calculate_line_total(pid, qty, price):
# Returns a tuple of (id, total_value)
return (pid, round(qty * price, 2))
# map() feeds one element from each list into the function
line_totals = map(calculate_line_total, product_ids, quantities, prices)
print(list(line_totals))[('A-101', 549.5), ('B-202', 411.75), ('C-303', 600.0)]Como já falamos, o map() para na iteração mais curta. Isso é uma coisa de propósito pra evitar exceções do tipo “ IndexError ”. Se a sua lógica precisa processar todos os itens da lista mais longa (por exemplo, preenchendo valores padrão), lembre-se de usar itertools.zip_longest() em vez disso. Você pode aprender isso junto com várias outras funções úteis neste curso sobre escrever código Python eficiente.
E aí, o que rola quando seus dados já estão “compactados” numa lista de tuplas? Isso é super comum quando a gente tá lidando com resultados de consultas a bancos de dados, arquivos CSV ou pares de coordenadas.
Digamos que você tem uma lista de pontos (x,y) como mostrado abaixo e quer calcular o produto de cada par.
points = [(1, 5), (3, 9), (4, -2)]Você poderia usar um lambda com map(), mas é meio complicado com funções aninhadas longas dentro dele:
list(map(lambda p: p[0] * p[1], points))Uma solução bem mais limpa e mais Python é itertools.starmap(). Ele pega uma função e um único iterável de iteráveis (como a nossa lista de tuplas). Em seguida, ele descompacta cada tupla interna como argumentos para a função. Vamos ver isso na prática:
import itertools
points = [(1, 5), (3, 9), (4, -2)]
# A simple function that takes two arguments
def product(x, y):
return x * y
# starmap() unpacks each tuple from 'points' into (x, y)
# and passes them to product()
products = itertools.starmap(product, points)
print(list(products))[5, 27, -8]starmap() é a ferramenta certa quando os argumentos da sua função já estão pré-empacotados em tuplas. Esse padrão é super útil quando a gente está lidando com dados geoespaciais, tipo uma lista de coordenadas (latitude, longitude). Para saber mais sobre esses conceitos, recomendo fazer este curso sobre trabalho com dados geoespaciais em Python.
A função ` map() ` é super útil na programação funcional. Podemos juntar isso com outras ferramentas úteis, tipo filter() e functools.reduce(), pra criar pipelines de processamento de dados limpos e super eficientes.
Já vimos a combinação de filter() e map(). Agora, vamos ver como usar o ` reduce()`, que junta (ou “reduz”) um iterável em um único valor acumulado.
Digamos que você queira encontrar a soma dos quadrados de todos os númerosímpares em uma determinada lista. Podemos fazer isso da seguinte maneira:
from functools import reduce
numbers = [1, 2, 3, 4, 5, 6, 7]
# 1. Filter: Get only the odd numbers
odd_numbers = filter(lambda x: x % 2 != 0, numbers)
# -> Iterator(1, 3, 5, 7)
# 2. Map: Square the odd numbers
squared_odds = map(lambda x: x * x, odd_numbers)
# -> Iterator(1, 9, 25, 49)
# 3. Reduce: Sum the results
# (lambda a, b: a + b) is the summing function
# 'a' is the accumulator, 'b' is the next item
total = reduce(lambda acc, val: acc + val, squared_odds)
print(total)84Esse é um padrão bem forte. Como map() e filter() retornam iteradores preguiçosos, toda essa operação é super eficiente em termos de memória. Nunca são criadas listas grandes intermediárias na memória. Os dados passam pelo pipeline, um por um.
Uma das características mais importantes do map() no Python 3 é o uso da avaliação preguiçosa. Entender esse conceito é essencial pra escrever um código eficiente e escalável, principalmente pra quem trabalha com dados e lida com grandes conjuntos de dados regularmente. Nesta seção, vamos ver como isso funciona.
No Python 3, ` map() ` não executa imediatamente sua função e retorna uma lista. Em vez disso, ele retorna um objeto map, que é um iterador. Esse iterador “sabe” qual função e quais dados usar, mas só faz o cálculo quando você pede explicitamente pelo próximo item.
Esse cálculo “just-in-time” traz benefícios incríveis, tipo:
Eficiência da memória: Um objeto ` map ` ocupa só uma pequena quantidade constante de memória, não importa se está processando 10 itens ou 10 bilhões. Não cria uma nova lista na memória para guardar todos os resultados.
Desempenho com grandes conjuntos de dados: Quando você faz uma iteração sobre o objeto ` map ` (por exemplo, em um loop ` for `), ele calcula e produz um valor de cada vez. Isso permite que você processe arquivos ou fluxos de dados enormes que seriam grandes demais para caber na memória de uma só vez.
Capacidade de encadeamento: Como vimos na seção sobre programação funcional, iteradores preguiçosos podem ser encadeados (por exemplo, map() após filter()). Como não são criadas listas intermediárias, os dados fluem pelo pipeline um item de cada vez, o que é super eficiente.
Compare isso com uma compreensão de lista, que usa avaliação ansiosa. Olha só esse exemplo:
squared = [x * x for x in range(10000000)]Esse código vai tentar criar uma lista com 10 milhões de números na hora, o que pode acabar usando uma quantidade enorme de RAM.
Uma expressão geradora é o equivalente preguiçoso de uma compreensão de lista. Parece bem parecido, mas funciona como um map() o em termos de memória.
squared = (x * x for x in range(10000000))O código acima também cria um iterador eficiente em termos de memória, assim como um map(). A escolha entre uma expressão de gerador ( map() ) e uma expressão de gerador (generator expression) geralmente se resume à legibilidade. A expressão de gerador ( map() ) pode ser mais clara ao aplicar uma função complexa já existente, enquanto a expressão de gerador (generator expression) costuma ser mais legível para expressões simples e inline.
Vamos comparar o uso de memória para essas operações:
import tracemalloc
# Define the base data for comparison
large_numbers = range(10000000)
print("--- Memory Usage (Object Creation vs. List Materialization) ---")
# --- 1. Memory for List Comprehension (creates full list immediately) ---
tracemalloc.start()
list_comp_obj = [x * x for x in large_numbers]
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for List Comprehension (full list): {peak / (1024 * 1024):.2f} MB")
del list_comp_obj # Free up memory
# --- 2. Memory for Map Object (lazy) ---
tracemalloc.start()
map_obj = map(lambda x: x * x, large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Map Object (iterator itself): {peak / (1024 * 1024):.2f} MB")
del map_obj # Free up memory
# --- 3. Memory for Generator Expression (lazy) ---
tracemalloc.start()
gen_exp_obj = (x * x for x in large_numbers)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
print(f"Peak RAM for Generator Expression (iterator itself): {peak / (1024 * 1024):.2f} MB")
del gen_exp_obj # Free up memory--- Memory Usage (Object Creation vs. List Materialization) ---
Peak RAM for List Comprehension (full list): 390.16 MB
Peak RAM for Map Object (iterator itself): 0.03 MB
Peak RAM for Generator Expression (iterator itself): 0.03 MBObservação: O “Pico de RAM” para objetos Map/Generator aqui se refere à memória alocada para o próprio objeto iterador, não à memória da lista completa que ele produziria se fosse convertido, mostrando sua natureza preguiçosa.
Como map() retorna um iterador preguiçoso, muitas vezes você precisa materializá-lo ou convertê-lo em uma coleção concreta para realmente usar os resultados.
Você deve converter um objeto ` map ` quando precisar:
Veja todos os resultados de uma vez (por exemplo, para fazer uma pesquisa no print() ).
Acesse os elementos pelo índice (por exemplo, results[0]).
Pega o comprimento dos resultados (por exemplo, len(results)).
Passe os resultados para uma função que precisa de uma lista ou conjunto.
Repita os resultados várias vezes. (Um objeto ` map `, como todos os iteradores, é exaurível.) Você só pode fazer um loop uma vez.
Veja como converter um objeto ` map `:
def square(x):
return x * x
numbers = [1, 2, 3, 3, 4, 5]
map_obj = map(square, numbers)
# --- Common Conversions ---
# 1. To a list:
list_results = list(map_obj)
print(f"List: {list_results}")
# Important
# The map_obj is now exhausted.
# If you try to do list(map_obj) again, you'll get an empty list.
# You must re-create the map object to reuse it.
map_obj = map(square, numbers) # Re-create it
# 2. To a set (removes duplicates):
set_results = set(map_obj)
print(f"Set: {set_results}")
map_obj = map(square, numbers) # Re-create it
# 3. To a tuple:
tuple_results = tuple(map_obj)
print(f"Tuple: {tuple_results}")List: [1, 4, 9, 9, 16, 25]
Set: {1, 4, 9, 16, 25}
Tuple: (1, 4, 9, 9, 16, 25)Pra converter pra um dicionário (se a saída for pares chave-valor), você pode usar map() com dict(), mas muitas vezes o Python são mais claras. são mais claras.
O ponto principal é ser intencional. Deixe map() permanecer como um iterador preguiçoso pelo maior tempo possível em seu pipeline e só o converta em uma lista no último momento, quando você realmente precisar de resultados concretos.
Cursos de Python
Programa
Programa
Curso
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal