
Cursus
Principes fondamentaux de l'apprentissage automatique en Python
16 h
La formation de modèles d'IA est de plus en plus considérée comme l'une des applications potentielles de l'IA dans le domaine de la science des données. Plus précisément, l'apprentissage automatique peut être réalisé à l'aide de Snowflake Cortex AI.
Dans ce guide, nous verrons ce qu'est l'IA de Snowflake Cortex et ce qu'elle peut faire. En outre, nous vous fournirons un tutoriel simple sur la façon de démarrer avec l'apprentissage automatique et l'IA en utilisant Python et un peu de SQL. Si vous ne connaissez pas encore Snowflake, consultez notre cours d'introduction à Snowflake. Introduction à Snowflake pour vous mettre à niveau.
Snowflake Cortex AI est une puissante fonctionnalité intégrée au Snowflake AI Data Cloud, conçue pour faciliter les opérations d'apprentissage machine (ML) directement dans l'environnement Snowflake.
Il permet une intégration transparente des modèles ML Python avec les données Snowflake, ce qui permet aux entreprises de tirer des informations, des prédictions et des analyses avancées à partir de grands ensembles de données tout en tirant parti de l'infrastructure en nuage.
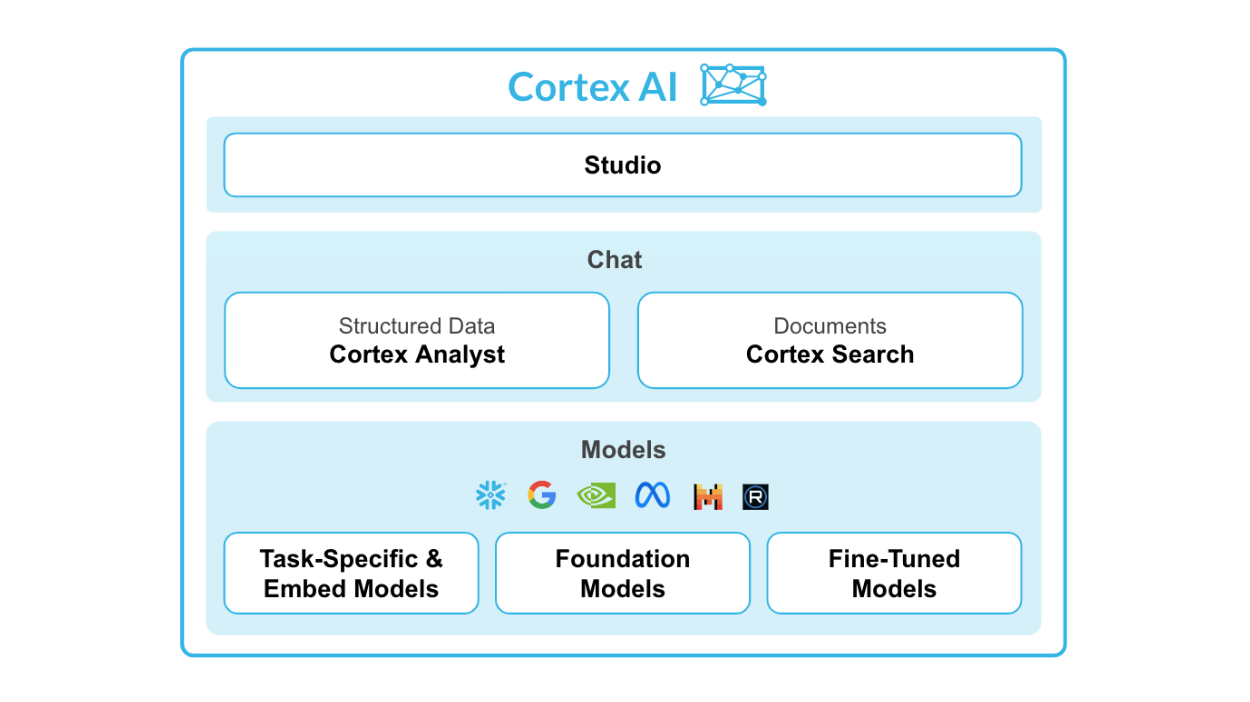
Source : Snowflake Cortex AI
Caractéristiques principales de Snowflake Cortex AI :
Le cortex du flocon de neige se compose de deux parties principales : les fonctions LML et les fonctions ML.
Pour les fonctions LLM, vous avez :
Nous examinerons chaque fonction plus en détail ci-dessous.
Pour les fonctions ML, vous avez :
Vous voulez savoir où apprendre Snowflake et ses fonctions ? Tutoriel du flocon de neige Tutoriel du flocon de neige et Guide de certification Snowflake vous aideront.
Examinons maintenant les avantages de l'utilisation conjointe de ces outils.
Les principaux avantages de l'utilisation de Snowflake Cortex AI sont les suivants :
Tout d'abord, Snowflake Cortex AI est parfait pour les entreprises qui cherchent à améliorer leurs capacités en matière de science des données sans investissement important en ressources. Grâce à son environnement sans code, même les utilisateurs non techniques peuvent facilement développer et déployer des modèles de ML.
Ceci est particulièrement utile pour les petites entreprises ou les startups qui n'ont pas forcément le budget pour embaucher une équipe de data scientists ou investir dans des LLM coûteux.
Deuxièmement, en intégrant Python dans l'environnement informatique de Snowflake, les utilisateurs peuvent tirer parti de la vaste bibliothèque d'algorithmes et d'outils d'apprentissage automatique Python disponibles. Cela signifie qu'ils peuvent créer des modèles plus avancés et plus précis sans avoir à apprendre de nouveaux langages de programmation.
Enfin, les entreprises qui ont déjà adopté l'environnement Snowflake profiteront pleinement des avantages de Cortex AI, qui s'intègre de manière transparente à leur entrepôt de données existant, éliminant ainsi la nécessité d'une infrastructure supplémentaire ou d'une migration des données.
Avec Snowflake Cortex AI, les entreprises peuvent facilement et efficacement mettre en œuvre l'apprentissage automatique dans leurs processus d'affaires.
Dans ce tutoriel, nous verrons comment mettre en place un pipeline d'apprentissage automatique à l'aide de Python et de Snowflake Cortex AI.
Avant de commencer à travailler sur la ML avec Snowflake Cortex AI, assurez-vous que vous remplissez les conditions suivantes :
Tout d'abord, vous aurez besoin d'une instance Snowflake où vos données sont stockées et traitées. Vous pouvez vous inscrire sur le site web du flocon de neige.
Dans le formulaire d'inscription, remplissez tous les détails de votre compte et veillez à faire les sélections suivantes sur la deuxième page. Sélectionnez l'édition Standard pour ce tutoriel et Amazon Web Services pour des raisons de simplicité et de reproductibilité. Pour le serveur, choisissez US West (Oregon) pour la meilleure sélection de fonctions LLM disponibles.

Une fois que vous avez sélectionné ces options, cliquez sur Démarrer pour recevoir l'e-mail d'activation. Rendez-vous sur votre messagerie pour activer votre compte et votre compte Snowflake est prêt à fonctionner.
Ensuite, vous devrez également remplir d'autres conditions pour le logiciel.
Voici une liste simple de choses à avoir :
Avant de commencer toute analyse, installez tous les paquets nécessaires pour que votre environnement de codage soit prêt.
Pour installer les paquets nécessaires, vous pouvez utiliser pip:
pip install snowflakepip install python-dotenvAprès avoir installé les bibliothèques, vous devez configurer votre dossier de travail et vos fichiers pour commencer.
J'ai créé un dossier intitulé Cortex AI Tutorial et inclus un nouveau fichier .env contenant les informations suivantes :
SNOWFLAKE_ACCOUNT = "<YOUR_ACCOUNT>" # eg. XXXX-XXXX
SNOWFLAKE_USER = "<YOUR_USER>"
SNOWFLAKE_USER_PASSWORD = "<YOUR_PASSWORD>"Après avoir saisi vos informations de compte, enregistrez le fichier et créez un fichier Python ou Jupyter Notebook dans le même dossier.
Maintenant que vous êtes prêt, connectons votre environnement Python à Snowflake.
Pour commencer, ouvrez votre fichier Python et importez toutes les bibliothèques nécessaires. Voici le code pour ce faire :
import os
from dotenv import load_dotenv
from snowflake.snowpark import Session
from snowflake.cortex import Summarize, Complete, ExtractAnswer, Sentiment, Translate, EmbedText768Ensuite, vous devez charger les variables que vous avez enregistrées dans le fichier.env que vous avez sauvegardé plus tôt. Cela permettra à Snowflake de disposer de vos identifiants de compte pour se connecter et utiliser ses fonctions.
# Loads environment variables from .env
load_dotenv()
connection_params = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_USER_PASSWORD"],
}
Une fois que vous vous êtes connecté à l'aide des variables, vous devez établir une session Snowflake. Il s'agit de l'objet qui traitera toutes vos demandes.
# Creates a Snowflake session
snowflake_session = Session.builder.configs(connection_params).create()Les fonctions LLM de Cortex AI permettent aux utilisateurs d'exploiter le potentiel des LLM sans avoir à développer leurs propres modèles d'IA.
Ces fonctions permettent à l'utilisateur moyen d'analyses de disposer d'une analyse alimentée par l'IA dans le cadre de certaines tâches de base.
Voici les fonctions du cortex du flocon de neige :
La fonction de synthèse est utilisée pour générer un résumé des données sur la base des données fournies.
Il utilise les LLM pour identifier les informations clés et les présenter dans un format condensé.
Par exemple, si vous disposez d'un long document texte et que vous souhaitez avoir un aperçu rapide de son contenu, vous pouvez utiliser la fonction de résumé pour obtenir un bref résumé qui reprend les points importants. Cela permet de gagner du temps et d'analyser plus rapidement de grandes quantités de données.
La langue d'entrée est actuellement limitée à l'anglais au moment de la rédaction de cet article.
Voir le code ci-dessous à titre de référence :
# Defines the Summarize LLM Function
def summarize(user_text):
summary = Summarize(text=user_text, session=snowflake_session)
return summaryLa fonction de traduction est utilisée pour convertir un texte d'une langue à une autre.
Il utilise des algorithmes d'apprentissage automatique et des modèles statistiques pour traduire le texte avec précision.
Cela peut être utile lorsque vous travaillez avec des données ou des documents dans différentes langues, car cela facilite la communication et la compréhension.
Par exemple, si vous avez un rapport rédigé en espagnol et que vous devez le présenter à un public anglophone, vous pouvez utiliser la fonction de traduction pour convertir rapidement le texte. Cela élimine la nécessité d'une traduction manuelle et permet de gagner du temps.
Voir le code ci-dessous à titre de référence :
# Defines the Translate LLM Function
def translate(user_text):
translation = Translate(
text=user_text, from_language="en", to_language="ko", session=snowflake_session
)
return translationLa fonction complète est une fonction à part entière qui peut être utilisée pour effectuer des tâches spécifiques. Pour ce faire, le modèle d'IA est guidé par des phrases indicatives qui lui fournissent les informations nécessaires à l'exécution d'une tâche.
Voir le code ci-dessous à titre de référence :
# Defines the Complete LLM Function
def complete(user_text):
completion = Complete(
model="snowflake-arctic",
prompt=f"Provide 3 relevant keywords from the following text: {user_text}",
session=snowflake_session,
)
return completionLa fonction d'extraction de réponse donne une réponse basée sur la question fournie au modèle. Les données doivent être rédigées en anglais, sous la forme d'une chaîne de caractères ou d'un format JSON.
Voir le code ci-dessous à titre de référence :
# Defines the Extract Answer LLM Function
def extract_answer(user_text):
answer = ExtractAnswer(
from_text=user_text,
question="What are some reasons why young adult South Koreans love coffee?",
session=snowflake_session,
)
return answerLa fonction de sentiment fournit un nombre quantitatif basé sur le sentiment du texte fourni. Il délivre une valeur comprise entre -1 et 1. Les valeurs avec -1 sont les plus négatives, 1 les plus positives, et les valeurs autour de 0 sont neutres.
Voir le code ci-dessous à titre de référence :
# Defines the Sentiment LLM Function
def sentiment(user_text):
sentiment = Sentiment(text=user_text, session=snowflake_session)
return sentimentLes fonctions de texte incorporé comprennent la fonction EMBED_TEXT_768 et la fonction EMBED_TEXT_1024. Ils créent des vecteurs d'intégration de 768 et 1024 dimensions respectivement.
Consultez le code ci-dessous pour connaître les fonctions de EMBED_TEXT_768:
# Defines the Embed Text LLM Function
def embed_text(user_text):
embed_text = EmbedText768(text=user_text, model='snowflake-arctic-embed-m', session=snowflake_session)
return embed_textRassemblons-les dans une fonction principale et exécutons-la à l'aide d'un exemple de texte afin d'en visualiser les résultats.
J'ai utilisé un texte simple et court pour l'introduire dans le modèle, comme indiqué ci-dessous :

Pour faciliter le copier-coller, voici le texte :
user_text = """
Young adults in South Korea are embracing coffee as a blend of energy, comfort, and culture.
Coffee isn't just about staying awake during demanding studies or work; it’s a cherished part of daily routines.
With South Korea's bustling café culture, coffee shops have become popular spaces for socializing, studying,
or just taking a break from the fast-paced city life.
The diversity of flavors and trendy cafés also offers a unique,
stylish experience that fits right into the evolving lifestyle of young adults,
who seek both connection and personal moments in the midst of it all.
"""Maintenant, exécutons le code. Cela ne devrait prendre que quelques secondes.
Voici les résultats :
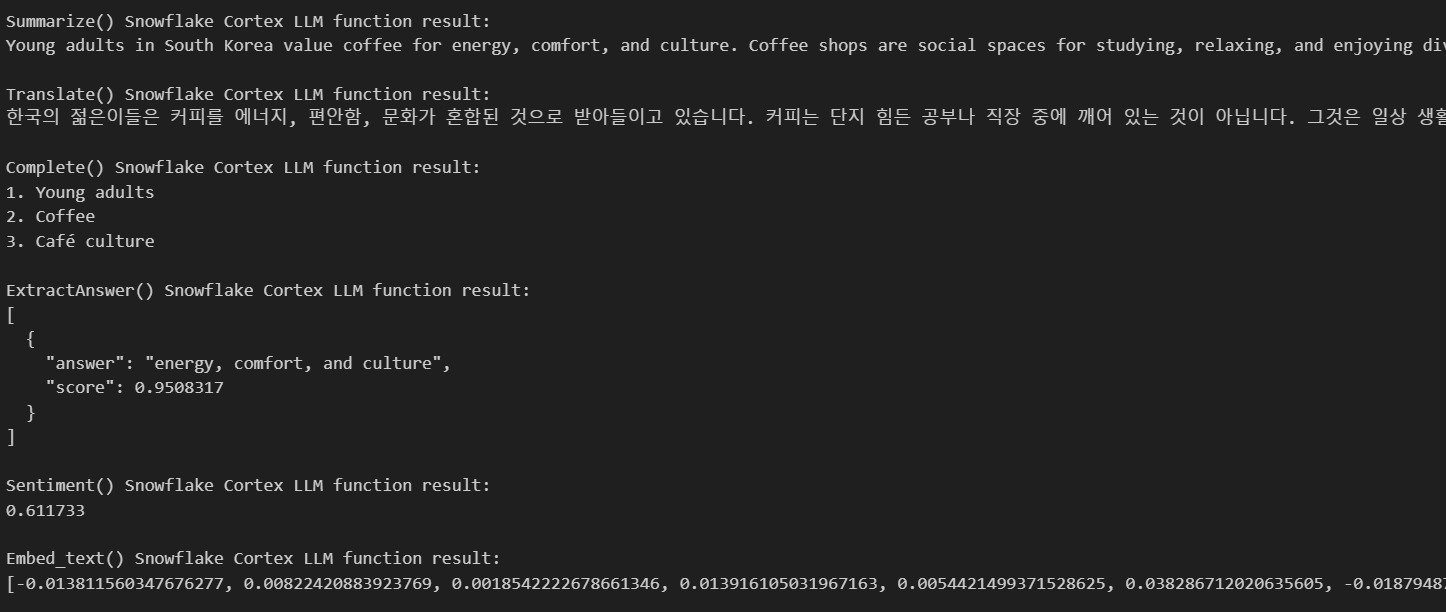
Comme vous pouvez le constater, l'IA nous a fourni tous les résultats dont nous avions besoin sur la base du texte que nous avons fourni. Il nous a donné un résumé, a traduit mon texte en coréen, m'a donné trois mots-clés basés sur mon texte et a fourni des réponses à mes questions.
Cortex AI dispose également de fonctions de ML qui peuvent être exécutées uniquement à l'aide de SQL. Voici les différentes fonctions qu'il offre.
La détection des anomalies est essentielle pour identifier les modèles inhabituels qui ne correspondent pas au comportement attendu de vos données. Snowflake simplifie la détection des anomalies en fournissant des fonctions intégrées d'apprentissage automatique basées sur une machine à gradient (GBM) qui vous permet d'identifier rapidement les valeurs aberrantes dans vos ensembles de données.
La détection des anomalies est particulièrement utile pour des tâches telles que :
La classe ANOMALY_DETECTION (SNOWFLAKE.ML) du flocon de neige peut être utilisée pour la détection des anomalies. Cette commande crée un objet modèle de détection d'anomalies. Cette étape permet d'adapter votre modèle aux données d'apprentissage.
Voici comment vous pouvez l'utiliser :
CREATE [ OR REPLACE ] SNOWFLAKE.ML.ANOMALY_DETECTION <model_name>(
INPUT_DATA => <reference_to_training_data>,
[ SERIES_COLNAME => '<series_column_name>', ]
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
LABEL_COLNAME => '<label_column_name>',
[ CONFIG_OBJECT => <config_object> ]
)
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT = '<string_literal>' ]Une fois l'objet créé, vous pouvez utiliser la méthode <model_name>!DETECT_ANOMALIES pour effectuer la détection des anomalies,
<model_name>!DETECT_ANOMALIES(
INPUT_DATA => <reference_to_data_to_analyze>,
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
[ CONFIG_OBJECT => <configuration_object>, ]
[ SERIES_COLNAME => '<series_column_name>' ]
)Il s'agit de l'étape de prédiction proprement dite au cours de laquelle les valeurs aberrantes seront détectées à l'aide de la méthode.
Voici un exemple de détection d'anomalies à partir d'un ensemble de données.
Tout d'abord, vous pouvez créer une base de données en allant sur Données dans l'onglet de gauche, puis sur Ajouter des données, suivi de Charger des données dans une table.

Dans la fenêtre qui s'affiche, cliquez sur + Base de données et donnez un nom à votre base de données. Cliquez sur Créer, puis dans la fenêtre principale, cliquez sur Annuler.
Cela créera une base de données vide avec laquelle vous pourrez travailler.
Les exemples ci-dessous ont été adaptés à partir de la Documentation sur le flocon de neige.
Pour commencer la détection des anomalies, ouvrez une nouvelle feuille de calcul SQL, sélectionnez votre nouvelle base de données comme source de données et collez le code suivant pour créer une table :
CREATE OR REPLACE TABLE historical_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN,
temperature NUMBER, humidity FLOAT, holiday VARCHAR) ;
// Creating the dataset
INSERT INTO historical_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'),
(1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'),
(2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);Votre code doit être placé dans une feuille de calcul SQL qui ressemble à ceci :
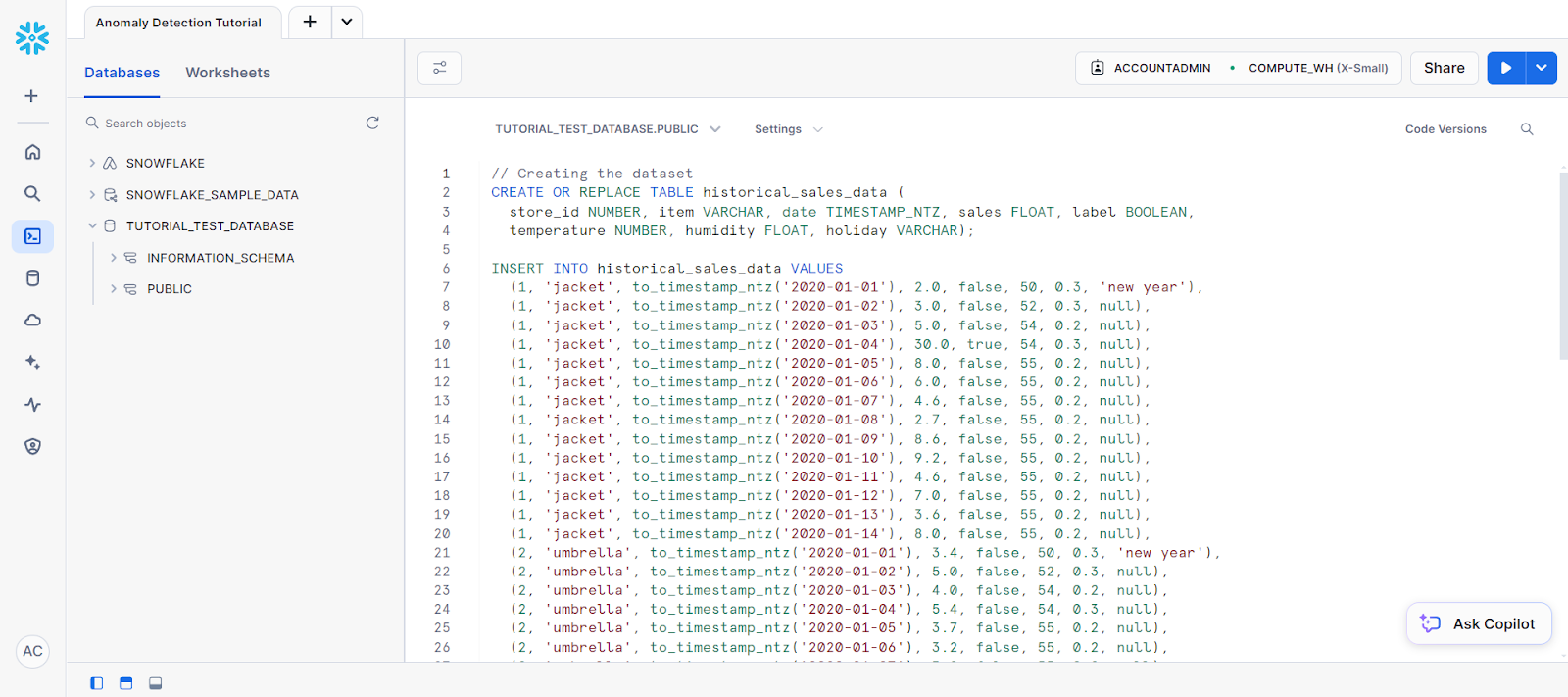
Elle est suivie des instructions suivantes pour créer une table nommée new_sales_data.
// Creating a new table and adding training data
CREATE OR REPLACE TABLE new_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT,
temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO new_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);Créez maintenant le modèle de détection des anomalies :
// Creating anomaly detection model object
CREATE OR REPLACE VIEW view_with_training_data
AS SELECT date, sales FROM historical_sales_data
WHERE store_id=1 AND item='jacket';
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model(
INPUT_DATA => TABLE(view_with_training_data),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '');Vous devriez obtenir un résultat indiquant qu'un modèle a été créé, comme indiqué ci-dessous.

Ensuite, utilisons le modèle d'objet pour faire de la détection.
// Perform anomaly detection
CREATE OR REPLACE VIEW view_with_data_to_analyze
AS SELECT date, sales FROM new_sales_data
WHERE store_id=1 and item='jacket';
CALL basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
);Voici le résultat de la détection :
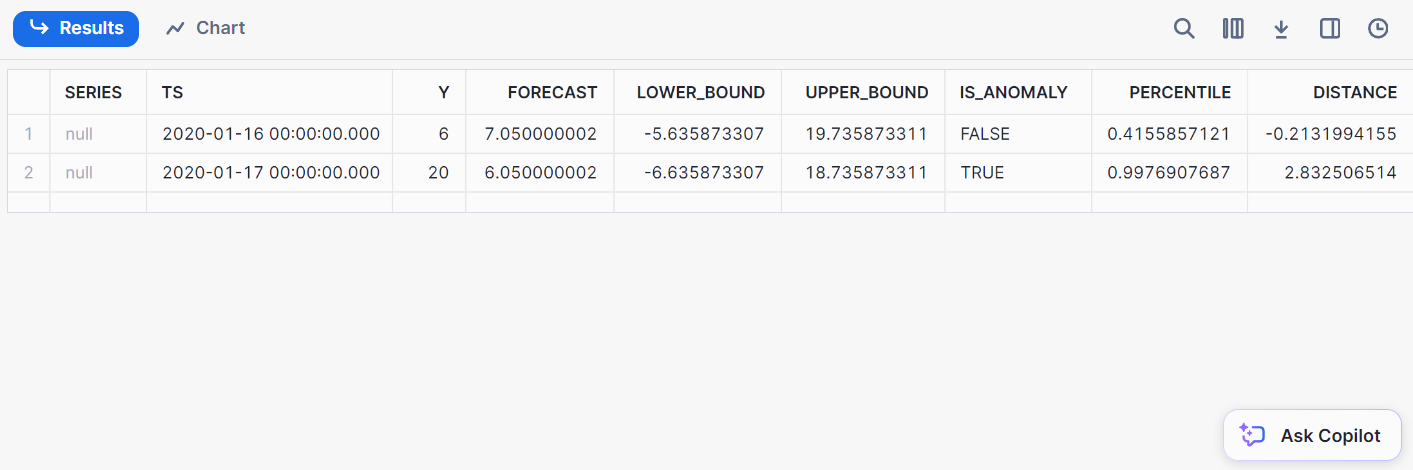
Classification consiste à classer les données dans des catégories prédéfinies. Avec Snowflake, vous pouvez classer les données directement à partir de Snowflake, ce qui élimine la nécessité d'exporter les données vers des environnements ML externes.
Pour commencer, créez un échantillon de données à l'aide du code suivant :
// Creating binary class dataset
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating,
FALSE AS label,
'not_interested' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating,
FALSE AS label,
'add_to_wishlist' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating,
TRUE AS label,
'purchase' AS class
FROM TABLE(GENERATOR(rowCount => 100))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
);Pour les besoins des données de formation, créons une nouvelle vue.
// Creating view for training data
CREATE OR REPLACE view binary_classification_view AS
SELECT user_interest_score, user_rating, label
FROM training_purchase_data;
SELECT * FROM binary_classification_view ORDER BY RANDOM(42) LIMIT 5;Cette vue devrait produire les résultats suivants :
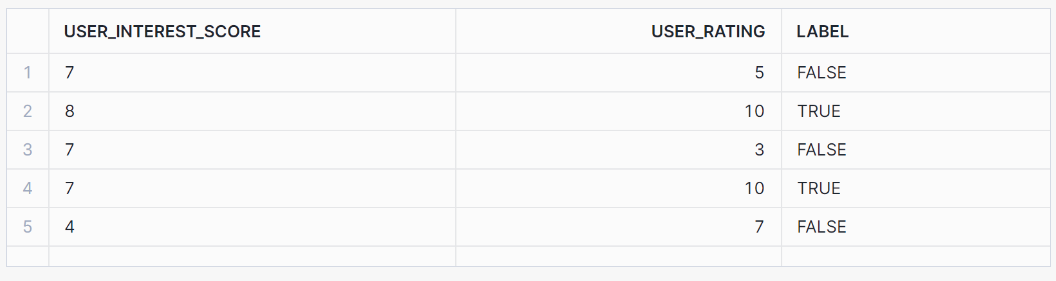
Ensuite, entraînons le modèle sur la base de nos données d'entraînement :
// Training a binary classification model
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label'
);Pour effectuer la classification, utilisez la méthode PREDICT:
// Performing prediction using PREDICT method
SELECT model_binary!PREDICT(INPUT_DATA => {*})
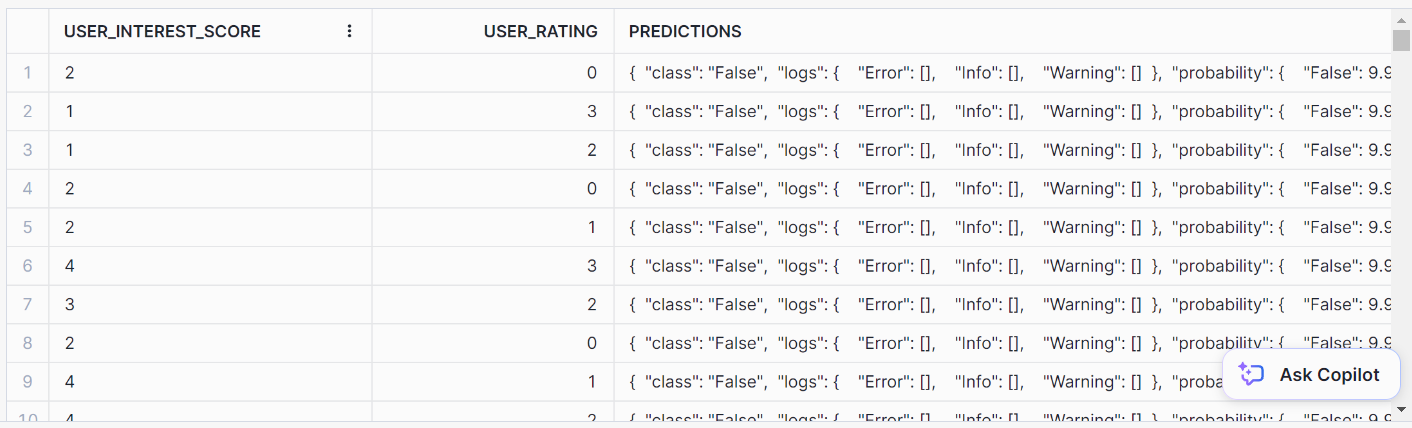
AS prediction FROM prediction_purchase_data;Voici à quoi ressemble la prédiction :
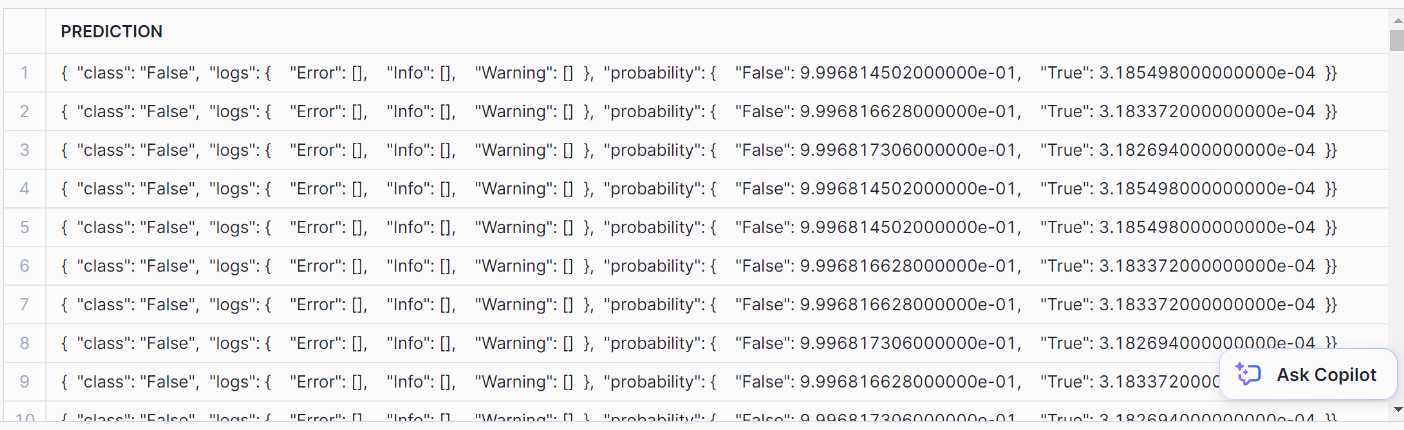
Pour le mettre en forme, utilisez cette instruction SQL :
// Formatting SQL predictions
SELECT *, model_binary!PREDICT(INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data;Vous devriez obtenir ce format de sortie soigné pour les prédictions :
Top Insights est un outil de surveillance qui permet d'observer les fluctuations de vos indicateurs au fil du temps grâce à une analyse des séries chronologiques. En utilisant un modèle d'arbre de décision, Top Insights peut identifier les facteurs les plus significatifs qui contribuent à l'augmentation ou à la diminution d'un indicateur particulier.
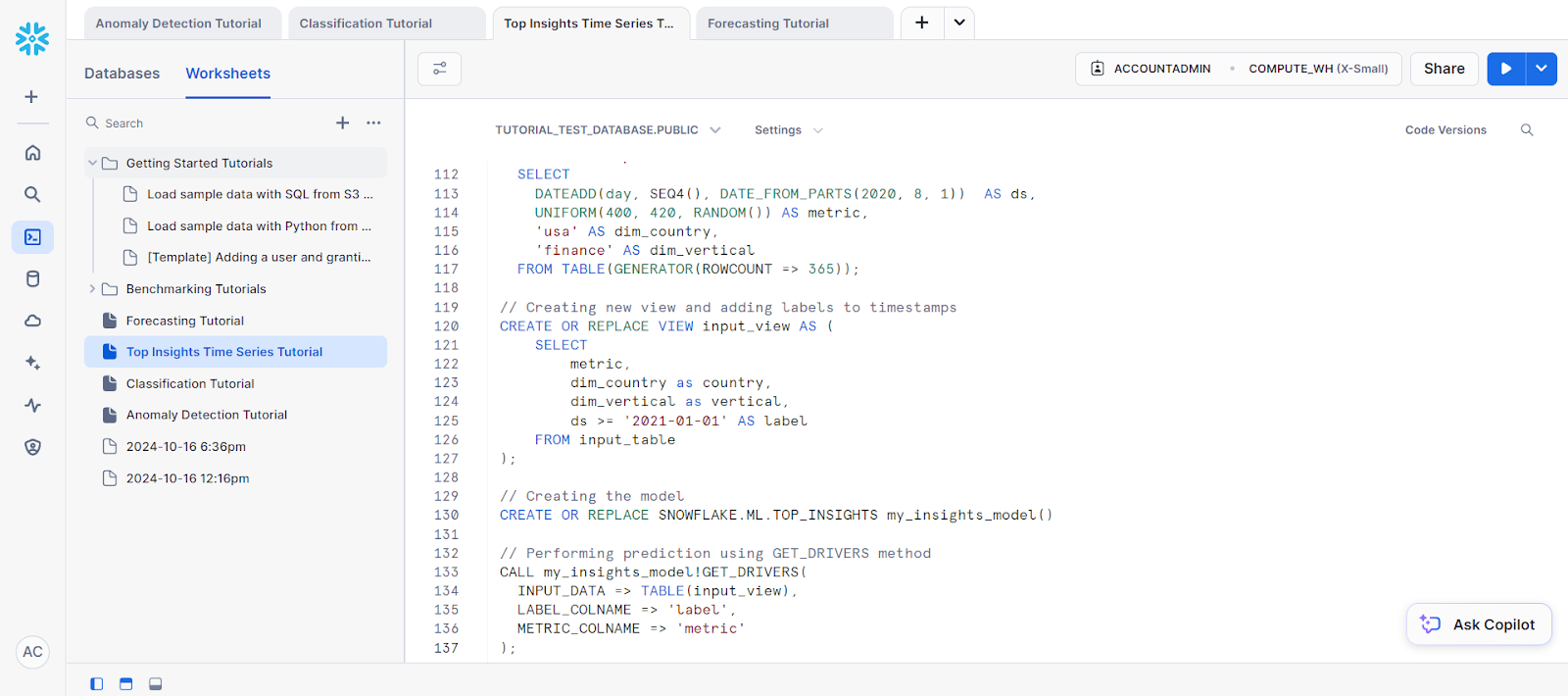
Voyons un exemple d'analyse de séries temporelles à l'aide de cette fonction.
Tout d'abord, créons un jeu de données :
// Creating dataset
CREATE OR REPLACE TABLE input_table(
ds DATE, metric NUMBER, dim_country VARCHAR, dim_vertical VARCHAR);
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, seq4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
-- Data for the test group
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(300, 320, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertica
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(400, 420, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
// Creating new view and adding labels to timestamps
CREATE OR REPLACE VIEW input_view AS (
SELECT
metric,
dim_country as country,
dim_vertical as vertical,
ds >= '2021-01-01' AS label
FROM input_table
);Ensuite, nous devons créer l'objet modèle pour la prédiction. Elle est nécessaire pour accéder à la méthode GET_DRIVERS.
// Creating the model
CREATE OR REPLACE SNOWFLAKE.ML.TOP_INSIGHTS my_insights_model()Enfin, pour la prédiction, appelez la méthode GET_DRIVERS.
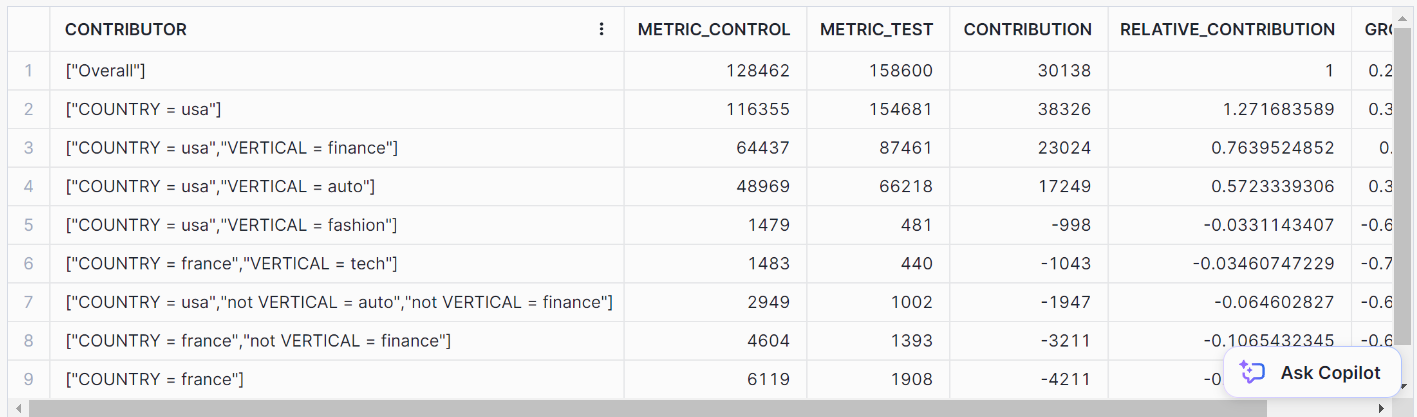
// Performing prediction using GET_DRIVERS method
CALL my_insights_model!GET_DRIVERS(
INPUT_DATA => TABLE(input_view),
LABEL_COLNAME => 'label',
METRIC_COLNAME => 'metric'
);Vous devriez obtenir les résultats suivants :
La prévision est cruciale lorsque vous devez prédire des valeurs futures sur la base de données historiques. Qu'il s'agisse de prévoir les ventes, la consommation d'énergie ou le trafic web, les fonctions intégrées de Snowflake simplifient considérablement ces tâches.
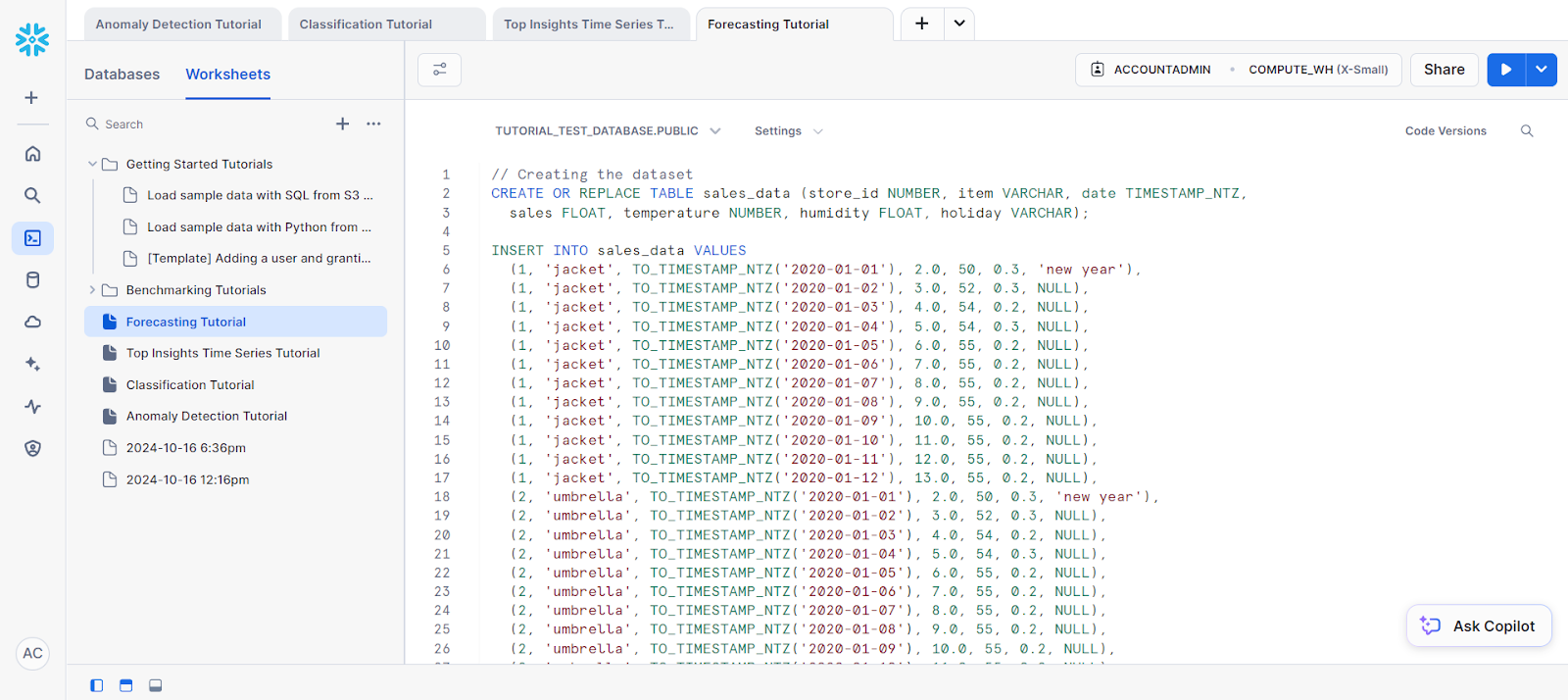
Pour notre exemple, essayons de faire des prévisions sur une seule série :
// Creating the dataset
CREATE OR REPLACE TABLE sales_data (store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ,
sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO sales_data VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL);
-- Future values for additional columns (features)
CREATE OR REPLACE TABLE future_features (store_id NUMBER, item VARCHAR,
date TIMESTAMP_NTZ, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO future_features VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL);Ensuite, séparons les données de formation de l'ensemble de données.
// Creating a view for training data
CREATE OR REPLACE VIEW v1 AS SELECT date, sales
FROM sales_data WHERE store_id=1 AND item='jacket';
SELECT * FROM v1;Avant de commencer vos prévisions, vous devez entraîner votre modèle sur la base des données d'entraînement que vous avez sélectionnées.
Voici comment vous pouvez le faire :
// Training a forecasting model
CREATE SNOWFLAKE.ML.FORECAST model1(
INPUT_DATA => TABLE(v1),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales'
);Enfin, pour la prévision, vous pouvez appeler la méthode FORECAST pour effectuer l'étape de prédiction.
// Performing the forecast by calling the FORECAST method
call model1!FORECAST(FORECASTING_PERIODS => 5);C'est le résultat de nos prévisions.
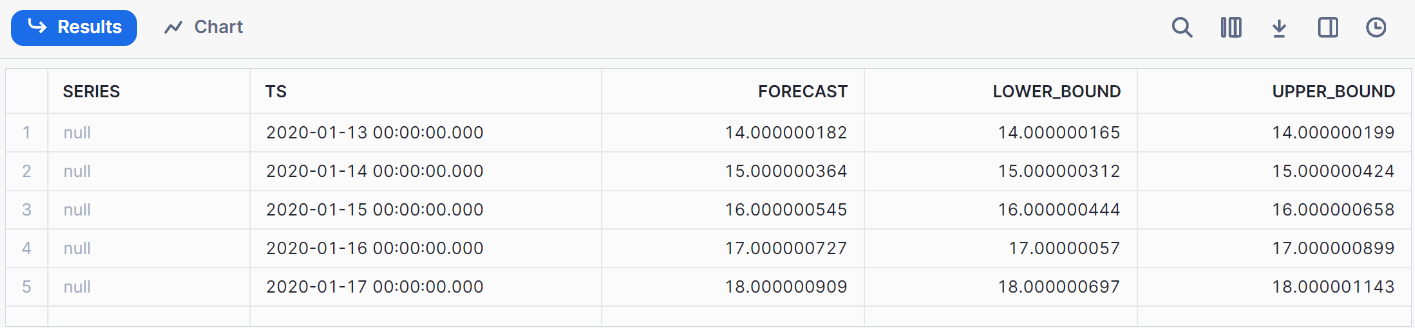
Le suivi des performances du modèle peut être effectué en créant des tableaux de bord dans Snowflake à l'aide d'intégrations tierces (comme Tableau) ou en interrogeant les journaux de Snowflake. Certaines mesures utiles telles que l'exactitude, la précision et le rappel peuvent être utilisées pour le suivi des modèles.
Snowflake Cortex AI simplifie l'apprentissage automatique en permettant une intégration transparente des modèles de la plateforme Snowflake. Ce tutoriel vous a guidé dans l'utilisation des fonctions Snowflake Cortex AI et Snowflake Cortex ML.
Cette solution tire parti de l'évolutivité de Snowflake et de la flexibilité de Python, ce qui la rend idéale pour les organisations qui souhaitent mettre en œuvre l'apprentissage automatique sans déplacer les données en dehors du nuage.
Vous cherchez d'autres ressources sur le flocon de neige ? Vous aimerez notre Tutoriel du flocon de neige pour débutants et notre Guide du parc à neige. Si vous recherchez quelque chose de plus complet, vous pouvez consulter le document suivant Introduction à Snowflake est peut-être le cours qu'il vous faut.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min