
programa
Fundamentos del aprendizaje automático en Python
16 h
El entrenamiento de modelos de IA ha ido en aumento como una de las aplicaciones potenciales de la IA en la ciencia de datos. Más concretamente, el aprendizaje automático puede realizarse utilizando Snowflake Cortex AI.
En esta guía, cubriremos áreas sobre qué es la IA Snowflake Cortex y qué puede hacer. Además, proporcionaremos un sencillo tutorial sobre cómo iniciarse en el aprendizaje automático y la IA utilizando Python y algo de SQL. Si eres nuevo en Snowflake, consulta nuestro curso de Curso de introducción a Snowflake para ponerte al día.
Snowflake Cortex AI es una potente función integrada en Snowflake AI Data Cloud, diseñada para facilitar las operaciones de aprendizaje automático (ML) directamente dentro del entorno Snowflake.
Permite una integración perfecta de los modelos Python ML con los datos de Snowflake, lo que permite a las organizaciones obtener conocimientos, predicciones y análisis avanzados a partir de grandes conjuntos de datos, aprovechando al mismo tiempo la infraestructura de la nube.
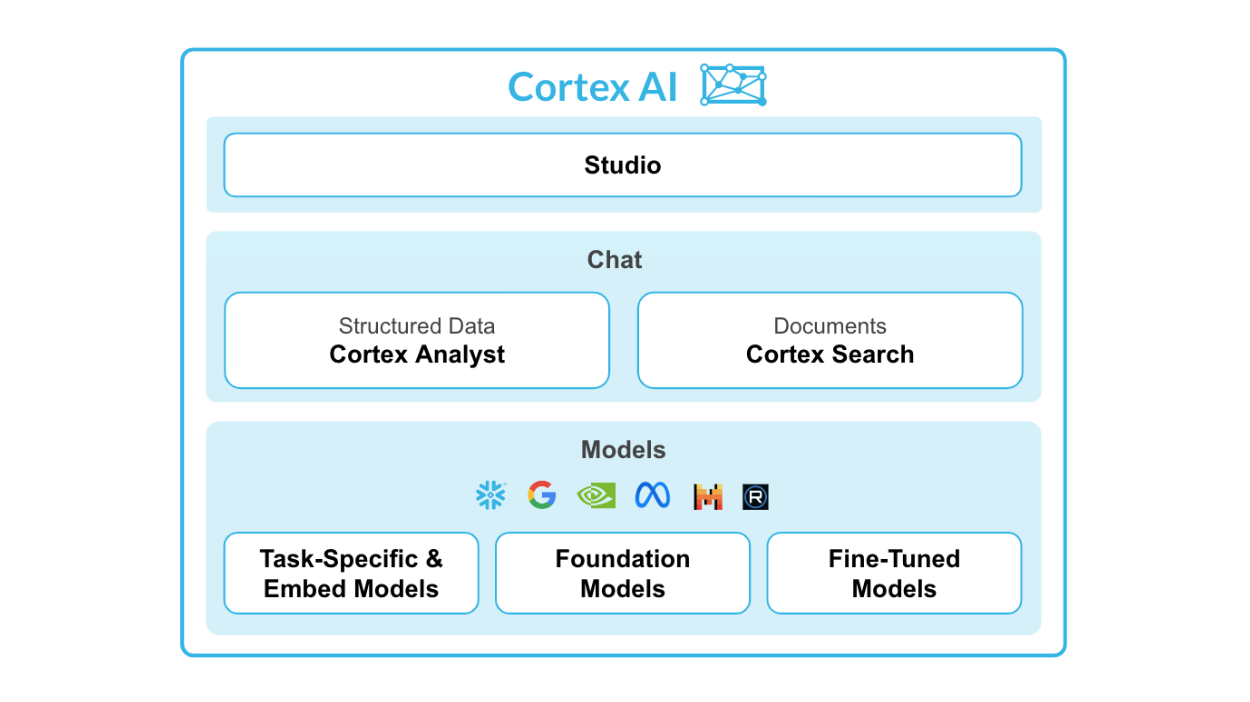
Fuente: Snowflake Cortex AI
Características principales de Snowflake Cortex AI:
Snowflake Cortex consta de dos partes principales: las funciones ML y las funciones ML.
Para las funciones de LLM, tienes:
Más adelante veremos cada función con más detalle.
Para las funciones ML, tienes:
¿Quieres saber dónde aprender Snowflake y sus funciones? Nuestro tutorial Tutorial de copos de nieve y Guía de certificación Snowflake te ayudarán.
Veamos ahora las ventajas de utilizar conjuntamente estas herramientas.
Algunas de las principales ventajas de utilizar Snowflake Cortex AI son:
En primer lugar, Snowflake Cortex AI es perfecto para las empresas que buscan mejorar sus capacidades de ciencia de datos sin una inversión significativa en recursos. Con su entorno sin código, incluso los usuarios sin conocimientos técnicos pueden desarrollar e implantar fácilmente modelos ML.
Esto es especialmente útil para las pequeñas empresas o startups que pueden no tener presupuesto para contratar a un equipo de científicos de datos o invertir en costosos LLM.
En segundo lugar, al integrar Python en el entorno informático de Snowflake, los usuarios pueden aprovechar la amplia biblioteca de algoritmos y herramientas de aprendizaje automático de Python disponibles. Esto significa que pueden crear modelos más avanzados y precisos sin tener que aprender nuevos lenguajes de programación.
Por último, las empresas que ya han adoptado el entorno Snowflake aprovecharían todas las ventajas de Cortex AI, ya que se integra perfectamente con su almacén de datos existente, eliminando la necesidad de infraestructura adicional o de migración de datos.
Con Snowflake Cortex AI, las empresas pueden implementar fácil y eficazmente el aprendizaje automático en sus procesos empresariales.
En este tutorial, recorreremos el proceso de configuración de una canalización de aprendizaje automático utilizando Python y Snowflake Cortex AI.
Antes de empezar a trabajar en ML con Snowflake Cortex AI, asegúrate de que cumples los siguientes requisitos:
En primer lugar, necesitarás una instancia de Snowflake donde se almacenen y procesen tus datos. Puedes inscribirte en el sitio web de Snowflake.
En el formulario de inscripción, rellena todos los datos de tu cuenta y toma nota de hacer las siguientes selecciones en la segunda página. Selecciona la edición Estándar para este tutorial y Amazon Web Services en aras de la simplicidad y la reproducibilidad. Para el servidor, elige US West (Oregón) para la mejor selección de funciones LLM disponibles.

Una vez que hayas seleccionado estas opciones, haz clic en Empezar para recibir el correo electrónico de activación. Dirígete a tu correo electrónico para activar tu cuenta y tu cuenta Snowflake estará lista para funcionar.
A continuación, también tendrás que cumplir otros requisitos para el software.
Aquí tienes una sencilla lista de cosas que debes tener:
Antes de empezar cualquier análisis, instala todos los paquetes pertinentes para que tu entorno de codificación esté preparado.
Para instalar los paquetes necesarios, puedes utilizar pip:
pip install snowflakepip install python-dotenvDespués de instalar las bibliotecas, tendrás que configurar tu carpeta de trabajo y los archivos para empezar.
He creado una carpeta llamada Cortex AI Tutorial y he incluido un nuevo archivo .env que contiene la siguiente información:
SNOWFLAKE_ACCOUNT = "<YOUR_ACCOUNT>" # eg. XXXX-XXXX
SNOWFLAKE_USER = "<YOUR_USER>"
SNOWFLAKE_USER_PASSWORD = "<YOUR_PASSWORD>"Tras introducir la información de tu cuenta, guarda el archivo y crea un archivo Python o Jupyter Notebook en la misma carpeta.
Ahora que ya lo tienes todo preparado, vamos a conectar tu entorno Python a Snowflake.
Para empezar, abre tu archivo Python e importa todas las bibliotecas necesarias. Aquí tienes el código para hacerlo:
import os
from dotenv import load_dotenv
from snowflake.snowpark import Session
from snowflake.cortex import Summarize, Complete, ExtractAnswer, Sentiment, Translate, EmbedText768A continuación, tendrás que cargar las variables que guardaste en el archivo.env que guardaste anteriormente. Esto proporcionará a Snowflake las credenciales de tu cuenta para iniciar sesión y utilizar sus funciones.
# Loads environment variables from .env
load_dotenv()
connection_params = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_USER_PASSWORD"],
}
Una vez que te hayas conectado utilizando las variables, tendrás que establecer una sesión Snowflake. Este es el objeto que gestionará todas tus peticiones.
# Creates a Snowflake session
snowflake_session = Session.builder.configs(connection_params).create()Las funciones LLM de Cortex AI permiten a los usuarios aprovechar el potencial de los LLM sin necesidad de desarrollar sus propios modelos de IA.
Estas funciones ayudan a proporcionar al usuario medio de analítica un análisis potenciado por la IA mediante algunas tareas básicas.
Éstas son las funciones que tiene Snowflake Cortex:
La función resumir se utiliza para generar un resumen de los datos a partir de la información introducida.
Utiliza los LLM para identificar la información clave y presentarla en un formato condensado.
Por ejemplo, si tienes un documento de texto largo y quieres una visión rápida de su contenido, puedes utilizar la función resumir para obtener un breve resumen que recoja los puntos importantes. Esto ahorra tiempo y permite un análisis más rápido de grandes cantidades de datos.
El idioma de entrada se limita actualmente al inglés en el momento de escribir este artículo.
Consulta el código siguiente como referencia:
# Defines the Summarize LLM Function
def summarize(user_text):
summary = Summarize(text=user_text, session=snowflake_session)
return summaryLa función traducir se utiliza para convertir texto de un idioma a otro.
Utiliza algoritmos de aprendizaje automático y modelos estadísticos para traducir el texto con precisión.
Esto puede ser útil cuando se trabaja con datos o documentos en distintas lenguas, ya que permite una comunicación y comprensión más fáciles.
Por ejemplo, si tienes un informe escrito en español y necesitas presentarlo a un público de habla inglesa, puedes utilizar la función de traducción para convertir rápidamente el texto. Esto elimina la necesidad de traducción manual y ahorra tiempo.
Consulta el código siguiente como referencia:
# Defines the Translate LLM Function
def translate(user_text):
translation = Translate(
text=user_text, from_language="en", to_language="ko", session=snowflake_session
)
return translationLa función completa es una función redondeada que puede utilizarse para realizar tareas específicas. Esto se hace mediante el uso de frases que guían al modelo de IA para que proporcione la información necesaria para ejecutar una tarea.
Consulta el código siguiente como referencia:
# Defines the Complete LLM Function
def complete(user_text):
completion = Complete(
model="snowflake-arctic",
prompt=f"Provide 3 relevant keywords from the following text: {user_text}",
session=snowflake_session,
)
return completionLa función extraer respuesta da una respuesta basada en la pregunta proporcionada al modelo. La entrada debe estar en inglés en formato de cadena o JSON.
Consulta el código siguiente como referencia:
# Defines the Extract Answer LLM Function
def extract_answer(user_text):
answer = ExtractAnswer(
from_text=user_text,
question="What are some reasons why young adult South Koreans love coffee?",
session=snowflake_session,
)
return answerLa función de sentimiento proporciona un número cuantitativo basado en el sentimiento del texto proporcionado. Emite un valor que va de -1 a 1. Los valores con -1 son los más negativos 1 los más positivos, y los valores en torno a 0 son neutros.
Consulta el código siguiente como referencia:
# Defines the Sentiment LLM Function
def sentiment(user_text):
sentiment = Sentiment(text=user_text, session=snowflake_session)
return sentimentLas funciones de incrustación de texto incluyen la función EMBED_TEXT_768 y la función EMBED_TEXT_1024. Crean incrustaciones vectoriales de 768 y 1024 dimensiones respectivamente.
Consulta el siguiente código de referencia sobre las funciones EMBED_TEXT_768:
# Defines the Embed Text LLM Function
def embed_text(user_text):
embed_text = EmbedText768(text=user_text, model='snowflake-arctic-embed-m', session=snowflake_session)
return embed_textAhora vamos a ponerlos todos juntos en una función principal y a ejecutarla a través de un texto de muestra para ver los resultados.
He utilizado un texto sencillo y breve para introducirlo en el modelo, como se muestra a continuación:

Para facilitar el copiar y pegar, aquí está el texto:
user_text = """
Young adults in South Korea are embracing coffee as a blend of energy, comfort, and culture.
Coffee isn't just about staying awake during demanding studies or work; it’s a cherished part of daily routines.
With South Korea's bustling café culture, coffee shops have become popular spaces for socializing, studying,
or just taking a break from the fast-paced city life.
The diversity of flavors and trendy cafés also offers a unique,
stylish experience that fits right into the evolving lifestyle of young adults,
who seek both connection and personal moments in the midst of it all.
"""Ahora, vamos a ejecutar el código. Sólo te llevará unos segundos.
Aquí tienes los resultados:
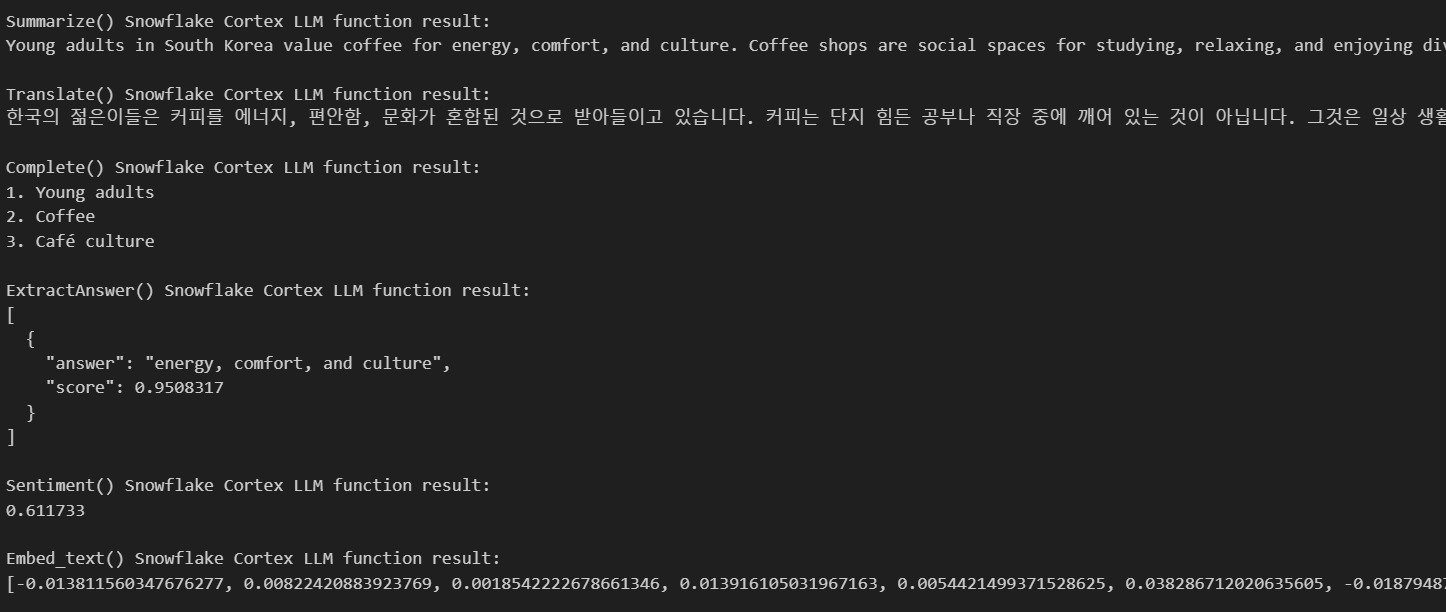
Como puedes ver, la IA nos ha dado todos los resultados que necesitamos basándose en el texto que le hemos proporcionado. Nos dio un resumen, tradujo mi texto al coreano, me dio tres palabras clave basadas en mi texto y me dio algunas respuestas basadas en mis preguntas.
Cortex AI también tiene funciones ML que pueden ejecutarse utilizando sólo SQL. Éstas son las diversas funciones que ofrece.
La detección de anomalías es esencial para identificar patrones inusuales que no se ajustan al comportamiento esperado de tus datos. Snowflake simplifica la detección de anomalías proporcionando funciones integradas de aprendizaje automático basadas en una máquina de refuerzo de gradiente (GBM) que te permite identificar rápidamente los valores atípicos en tus conjuntos de datos.
La detección de anomalías es especialmente útil para tareas como:
Para realizar la detección de anomalías, se puede utilizar la clase Snowflake ANOMALY_DETECTION (SNOWFLAKE.ML). Este comando crea un objeto modelo de detección de anomalías. Este paso ajusta tu modelo a los datos de entrenamiento.
A continuación te explicamos cómo puedes utilizarlo:
CREATE [ OR REPLACE ] SNOWFLAKE.ML.ANOMALY_DETECTION <model_name>(
INPUT_DATA => <reference_to_training_data>,
[ SERIES_COLNAME => '<series_column_name>', ]
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
LABEL_COLNAME => '<label_column_name>',
[ CONFIG_OBJECT => <config_object> ]
)
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT = '<string_literal>' ]Una vez creado el objeto, puedes utilizar el método <nombre_modelo>!DETECT_ANOMALIES para realizar la detección de anomalías,
<model_name>!DETECT_ANOMALIES(
INPUT_DATA => <reference_to_data_to_analyze>,
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
[ CONFIG_OBJECT => <configuration_object>, ]
[ SERIES_COLNAME => '<series_column_name>' ]
)Este es el paso de predicción real en el que se detectarán los valores atípicos mediante el método.
He aquí un ejemplo de cómo puede realizarse la detección de anomalías utilizando un conjunto de datos.
Primero, puedes crear una base de datos yendo a Datos en la pestaña izquierda, y luego a Añadir datos, seguido de Cargar datos en una Tabla.

En la ventana que aparece, haz clic en + Base de datos y dale un nombre a tu base de datos. Haz clic en Crear y, a continuación, en la ventana emergente principal, haz clic en Cancelar.
Esto creará una base de datos vacía con la que podrás trabajar.
Los siguientes ejemplos se han adaptado de la Documentación de Snowflake.
Para comenzar la detección de anomalías, ve a una nueva hoja de cálculo SQL, selecciona tu nueva base de datos como fuente de datos y pega el siguiente código para crear una tabla:
CREAR O SUSTITUIR TABLA historical_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN,
temperatura NÚMERO, humedad FLOT, vacaciones VARCHAR);
// Creating the dataset
INSERT INTO historical_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'),
(1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'),
(2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);Tu código debe ir en una hoja de cálculo SQL que tenga este aspecto:
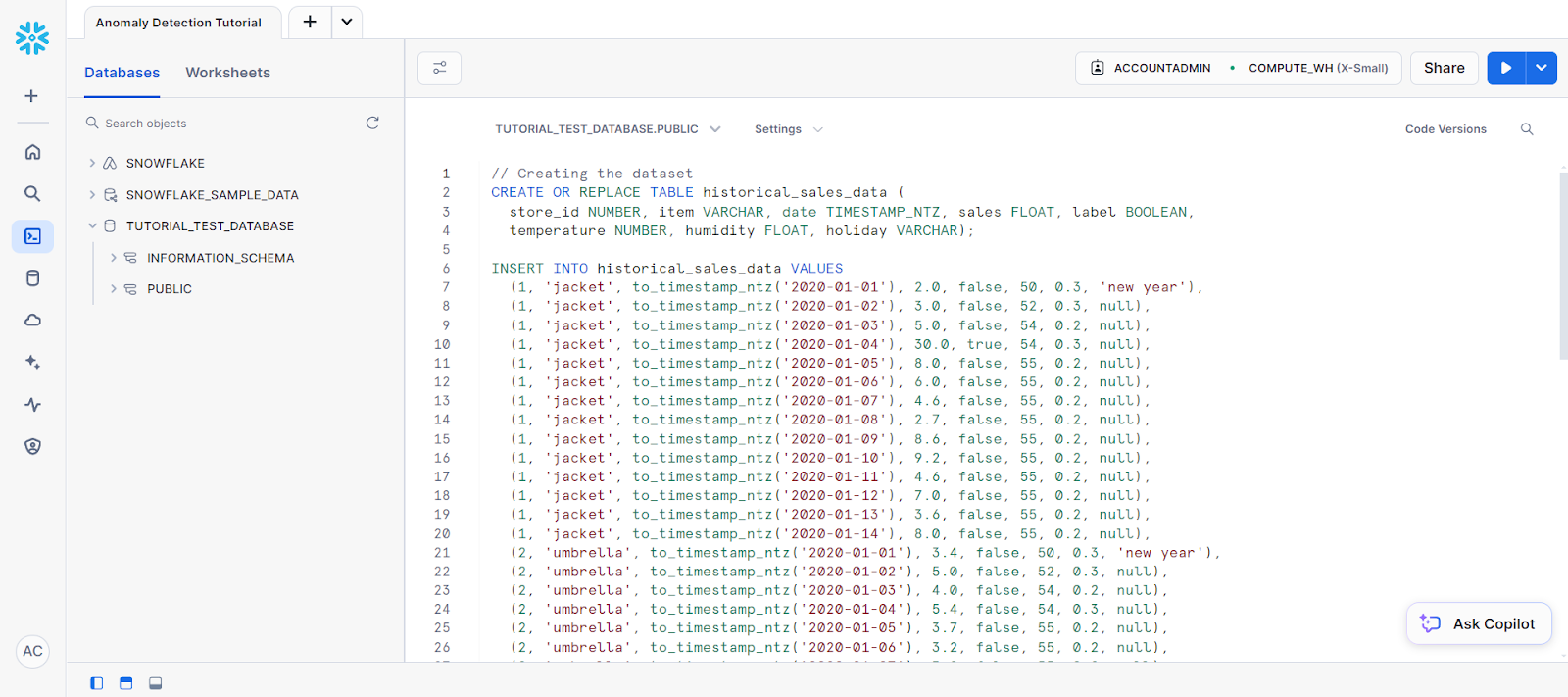
A esto le siguen las siguientes sentencias para crear una tabla llamada new_sales_data.
// Creating a new table and adding training data
CREATE OR REPLACE TABLE new_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT,
temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO new_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);Ahora, crea el modelo de detección de anomalías:
// Creating anomaly detection model object
CREATE OR REPLACE VIEW view_with_training_data
AS SELECT date, sales FROM historical_sales_data
WHERE store_id=1 AND item='jacket';
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model(
INPUT_DATA => TABLE(view_with_training_data),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '');Esto debería crear un resultado indicando que se ha creado un modelo, como se muestra a continuación.

A continuación, vamos a utilizar el modelo de objetos para realizar alguna detección.
// Perform anomaly detection
CREATE OR REPLACE VIEW view_with_data_to_analyze
AS SELECT date, sales FROM new_sales_data
WHERE store_id=1 and item='jacket';
CALL basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
);Aquí tienes el resultado de la detección:
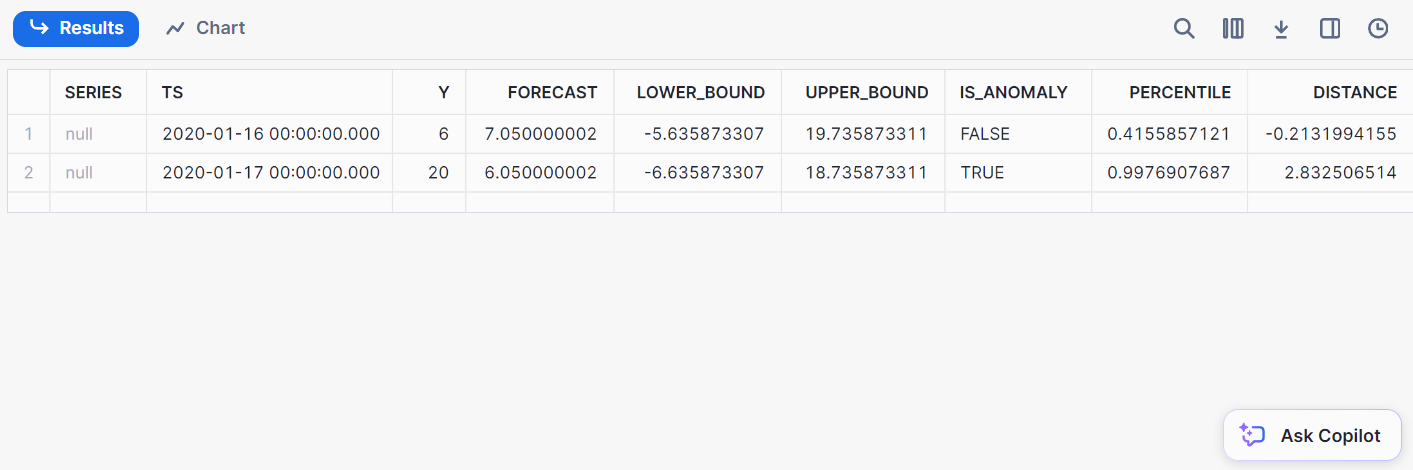
Clasificación consiste en clasificar los datos en clases predefinidas. Con Snowflake, puedes clasificar los datos directamente desde dentro de Snowflake, eliminando la necesidad de exportarlos a entornos de ML externos.
Para empezar, crea un conjunto de datos de muestra utilizando el código siguiente:
// Creating binary class dataset
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating,
FALSE AS label,
'not_interested' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating,
FALSE AS label,
'add_to_wishlist' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating,
TRUE AS label,
'purchase' AS class
FROM TABLE(GENERATOR(rowCount => 100))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
);Para los datos de entrenamiento, vamos a crear una nueva vista.
// Creating view for training data
CREATE OR REPLACE view binary_classification_view AS
SELECT user_interest_score, user_rating, label
FROM training_purchase_data;
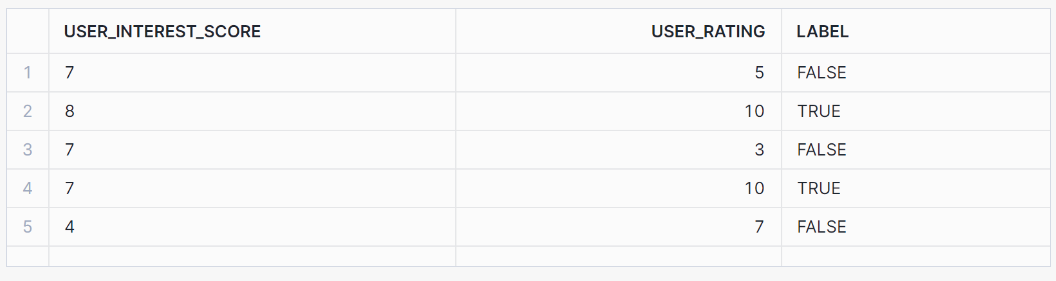
SELECT * FROM binary_classification_view ORDER BY RANDOM(42) LIMIT 5;Esta vista debería mostrar los siguientes resultados:
A continuación, vamos a entrenar el modelo basándonos en nuestros datos de entrenamiento:
// Training a binary classification model
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label'
);Para realizar la clasificación, utiliza el método PREDICT:
// Performing prediction using PREDICT method
SELECT model_binary!PREDICT(INPUT_DATA => {*})
AS prediction FROM prediction_purchase_data;Esta es la predicción:
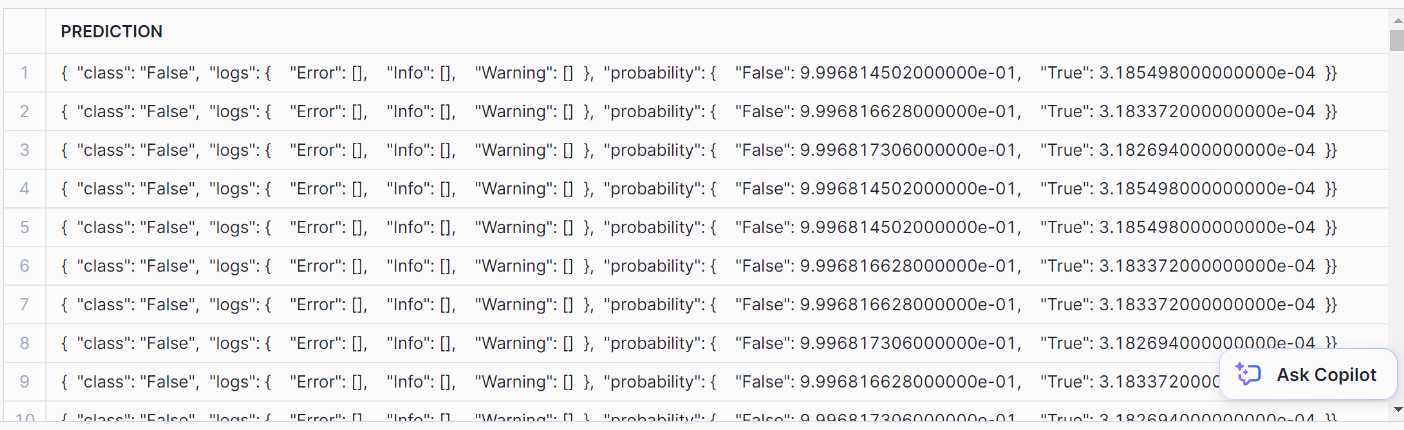
Para formatearlo bien, utiliza esta sentencia SQL:
// Formatting SQL predictions
SELECT *, model_binary!PREDICT(INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data;Deberías llegar a este formato de salida ordenado para las predicciones:
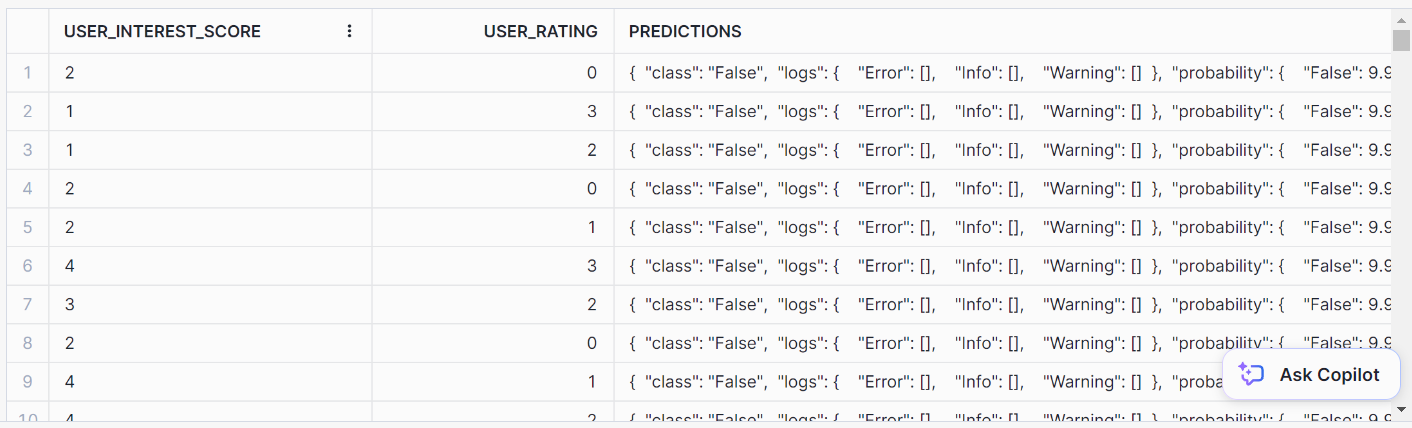
Top Insights es una herramienta de monitorización para buscar fluctuaciones en tus métricas a lo largo del tiempo mediante un análisis de series temporales. Utilizando un modelo de árbol de decisión, Top Insights puede identificar los factores más significativos que contribuyen a un aumento o disminución de una métrica concreta.
Veamos un ejemplo de análisis de series temporales utilizando esta función.
En primer lugar, vamos a crear un conjunto de datos:
// Creating dataset
CREATE OR REPLACE TABLE input_table(
ds DATE, metric NUMBER, dim_country VARCHAR, dim_vertical VARCHAR);
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, seq4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
-- Data for the test group
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(300, 320, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertica
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(400, 420, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
// Creating new view and adding labels to timestamps
CREATE OR REPLACE VIEW input_view AS (
SELECT
metric,
dim_country as country,
dim_vertical as vertical,
ds >= '2021-01-01' AS label
FROM input_table
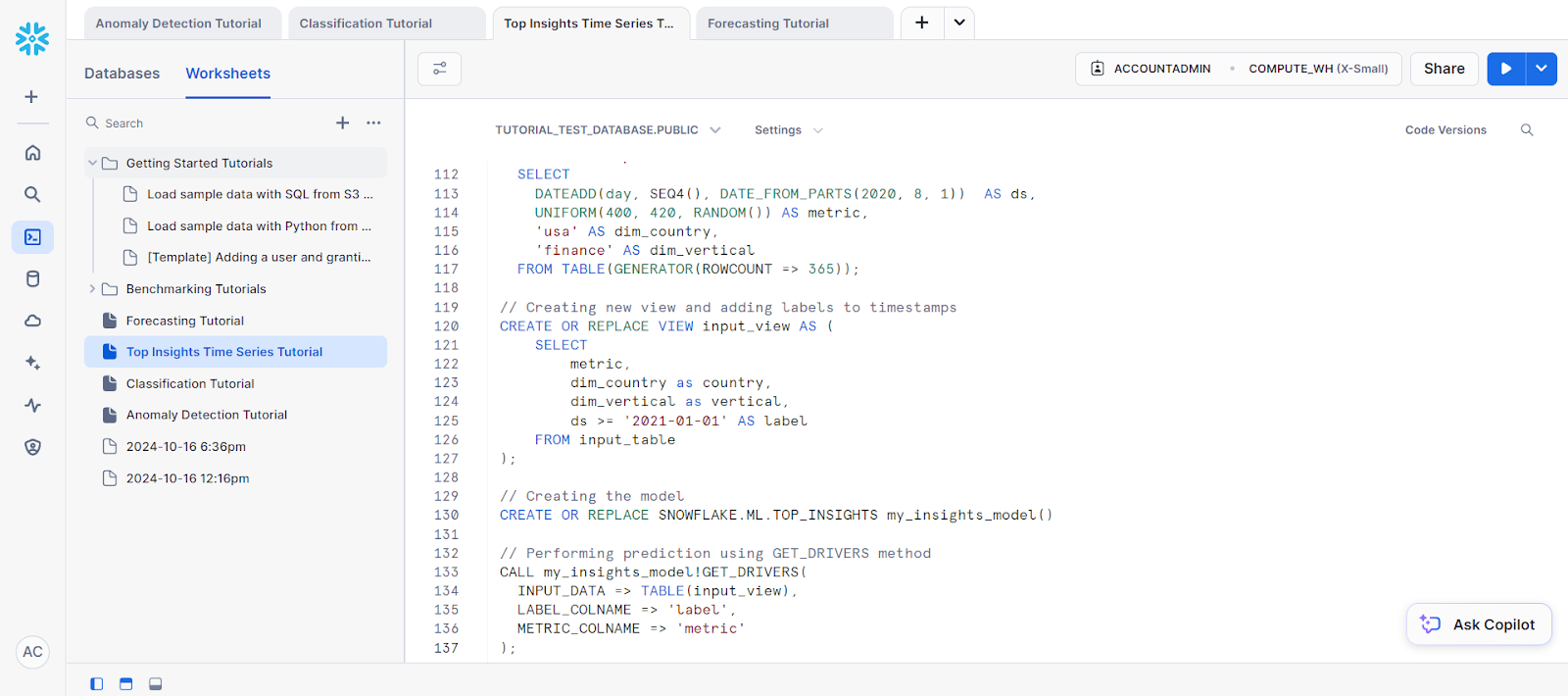
);A continuación, tenemos que crear el objeto modelo para la predicción. Es necesario para acceder al método GET_DRIVERS.
// Creating the model
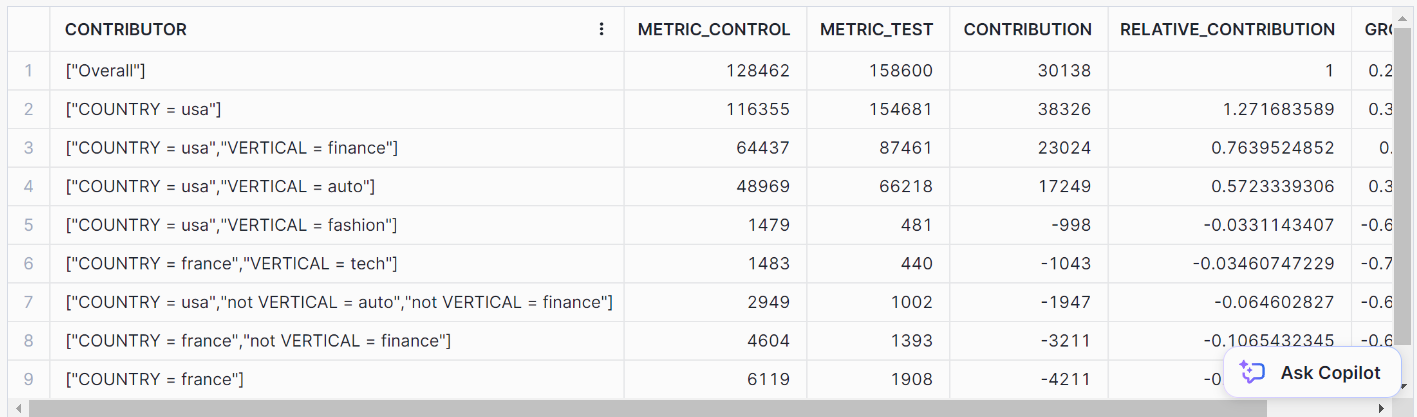
CREATE OR REPLACE SNOWFLAKE.ML.TOP_INSIGHTS my_insights_model()Por último, para la predicción, llama al método GET_DRIVERS.
// Performing prediction using GET_DRIVERS method
CALL my_insights_model!GET_DRIVERS(
INPUT_DATA => TABLE(input_view),
LABEL_COLNAME => 'label',
METRIC_COLNAME => 'metric'
);Esto debería darte los siguientes resultados:
La previsión es crucial cuando necesitas predecir valores futuros basándote en datos históricos. Ya se trate de la previsión de ventas, la predicción del consumo de energía o la previsión del tráfico web, las funciones integradas de Snowflake simplifican mucho estas tareas.
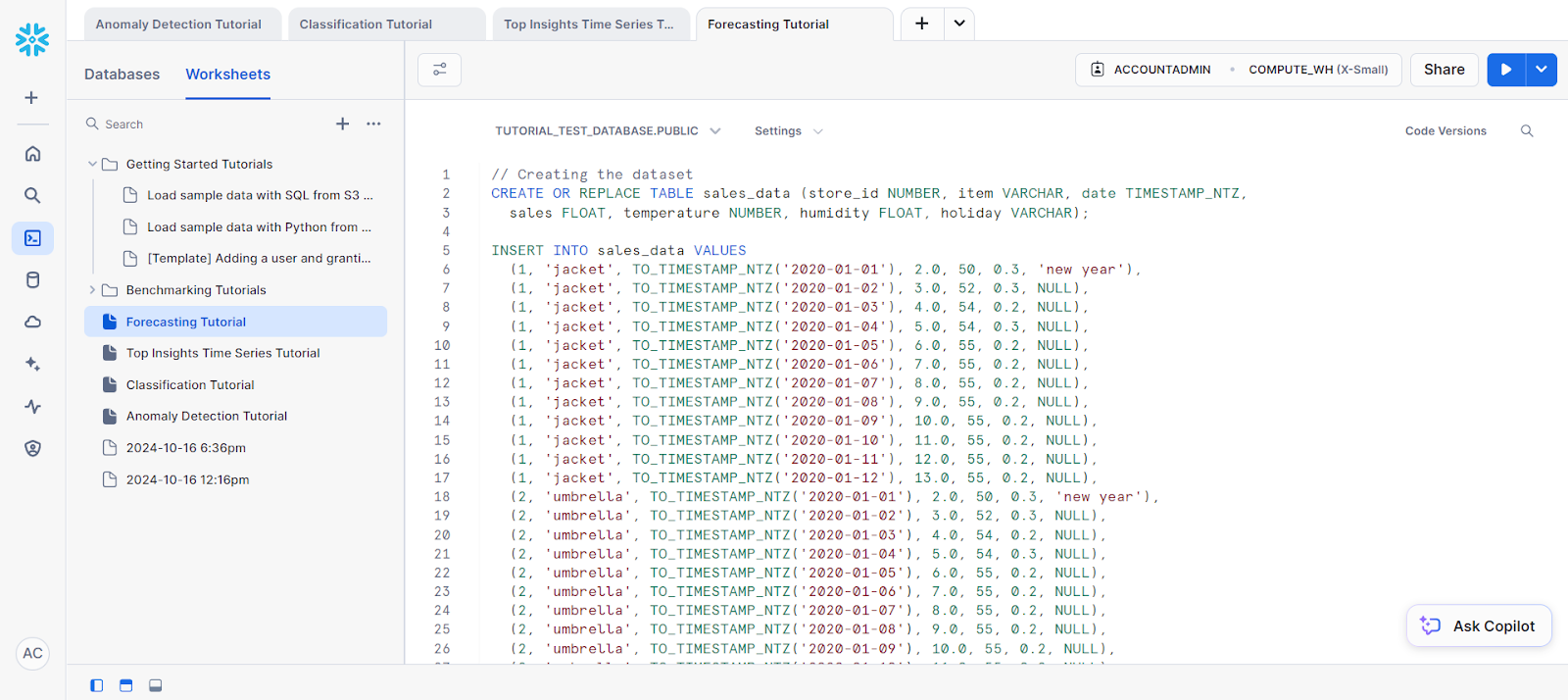
Para nuestro ejemplo, vamos a hacer una previsión sobre una sola serie:
// Creating the dataset
CREATE OR REPLACE TABLE sales_data (store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ,
sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO sales_data VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL);
-- Future values for additional columns (features)
CREATE OR REPLACE TABLE future_features (store_id NUMBER, item VARCHAR,
date TIMESTAMP_NTZ, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO future_features VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL);A continuación, vamos a separar los datos de entrenamiento del conjunto de datos.
// Creating a view for training data
CREATE OR REPLACE VIEW v1 AS SELECT date, sales
FROM sales_data WHERE store_id=1 AND item='jacket';
SELECT * FROM v1;Antes de empezar a hacer previsiones, tendrás que entrenar tu modelo basándote en los datos de entrenamiento que hayas seleccionado.
He aquí cómo puedes hacerlo:
// Training a forecasting model
CREATE SNOWFLAKE.ML.FORECAST model1(
INPUT_DATA => TABLE(v1),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales'
);Por último, para la predicción, puedes llamar al método PREVISIÓN para realizar el paso de predicción.
// Performing the forecast by calling the FORECAST method
call model1!FORECAST(FORECASTING_PERIODS => 5);Éste es el resultado de nuestra previsión.
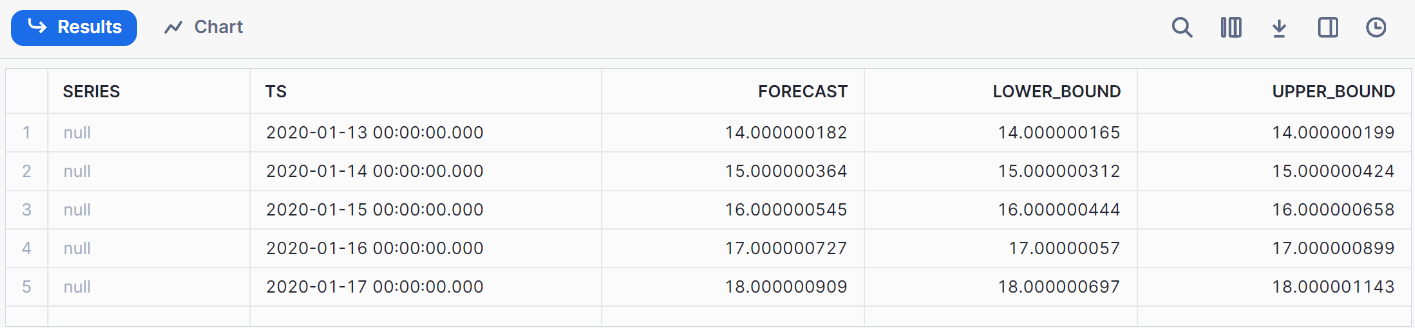
La supervisión del rendimiento del modelo puede hacerse creando cuadros de mando en Snowflake utilizando integraciones de terceros (como Tableau) o consultando los registros de Snowflake. Algunas métricas útiles como la exactitud, la precisión y el recuerdo pueden utilizarse para los modelos de seguimiento.
Snowflake Cortex AI simplifica el aprendizaje automático permitiendo una integración perfecta de los modelos de la plataforma Snowflake. Este tutorial te guiará en el uso de las funciones Snowflake Cortex AI y Snowflake Cortex ML.
Esta solución aprovecha la escalabilidad de Snowflake y la flexibilidad de Python, por lo que es ideal para las organizaciones que quieren implantar el aprendizaje automático sin mover los datos fuera de la nube.
¿Buscas más recursos sobre Copo de nieve? Te gustará nuestro Tutorial para principiantes sobre copos de nieve y nuestra Guía de Snowpark. Si buscas algo más completo, entonces la Introducción a Snowflake puede ser el curso adecuado para ti.
Los mejores cursos de DataCamp
programa
Curso
Curso
Tutorial
Duong Vu
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

