
Lernpfad
Grundlagen des maschinellen Lernens in Python
16 Std.
Das Training von KI-Modellen ist als eine der möglichen Anwendungen von KI in der Datenwissenschaft auf dem Vormarsch. Genauer gesagt, kann das maschinelle Lernen mit Snowflake Cortex AI durchgeführt werden.
In diesem Leitfaden erfahren wir, was Snowflake Cortex AI ist und was sie kann. Außerdem bieten wir eine einfache Anleitung, wie du mit Python und etwas SQL in maschinelles Lernen und KI einsteigen kannst. Wenn du neu bei Snowflake bist, schau dir unseren Einführung in Snowflake um auf den neuesten Stand zu kommen.
Snowflake Cortex AI ist eine leistungsstarke Funktion, die in die Snowflake AI Data Cloud integriert wurde, um maschinelles Lernen (ML) direkt in der Snowflake-Umgebung zu ermöglichen.
Sie ermöglicht die nahtlose Integration von Python ML-Modellen mit Snowflake-Daten, so dass Unternehmen Einblicke, Vorhersagen und fortschrittliche Analysen aus großen Datensätzen ableiten können, während sie die Cloud-Infrastruktur nutzen.
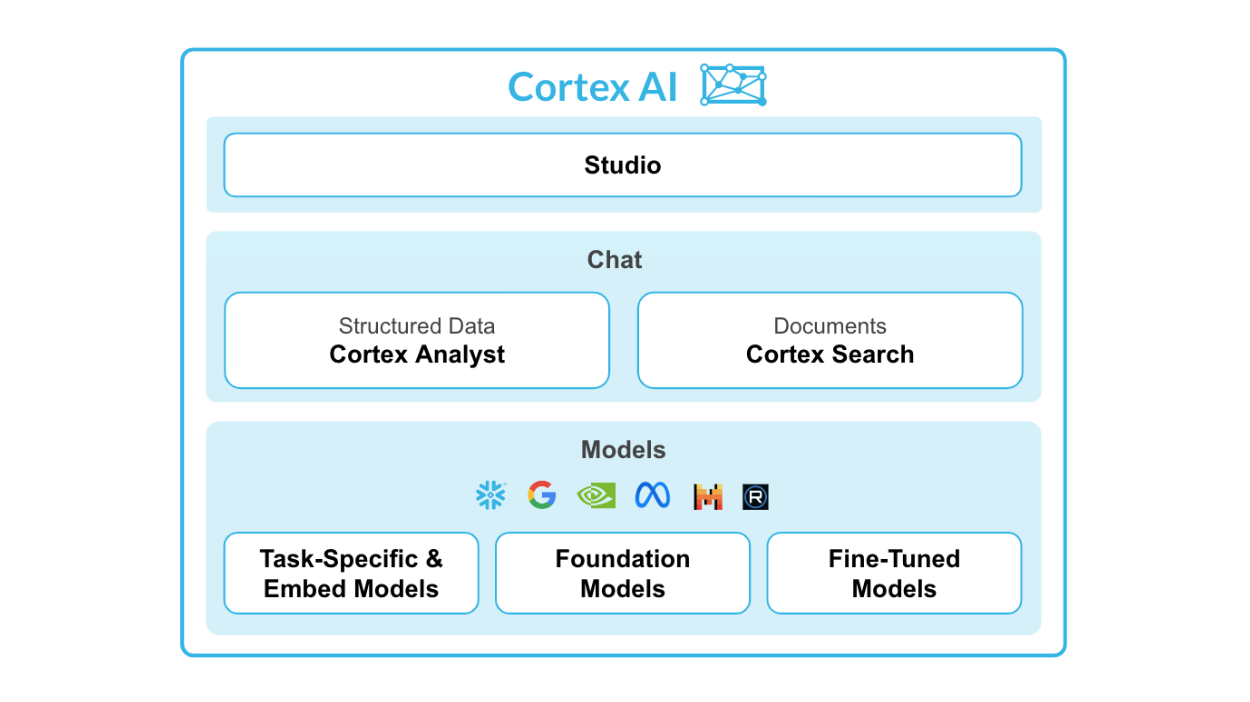
Quelle: Snowflake Cortex AI
Die wichtigsten Merkmale von Snowflake Cortex AI:
Snowflake Cortex besteht aus zwei Hauptteilen - ML-Funktionen und ML-Funktionen.
Für LLM-Funktionen hast du:
Wir werden uns die einzelnen Funktionen weiter unten im Detail ansehen.
Für ML-Funktionen hast du:
Willst du herausfinden, wo du Snowflake und seine Funktionen lernen kannst? Unser Anfänger Schneeflocken-Tutorial und Snowflake Zertifizierungsleitfaden werden dir helfen.
Sehen wir uns nun die Vorteile an, die sich aus der gemeinsamen Nutzung dieser Tools ergeben.
Einige der wichtigsten Vorteile von Snowflake Cortex AI sind:
Erstens ist Snowflake Cortex AI perfekt für Unternehmen, die ihre Data-Science-Fähigkeiten ohne große Investitionen in Ressourcen verbessern wollen. Dank der No-Code-Umgebung können auch technisch nicht versierte Nutzer ML-Modelle leicht entwickeln und einsetzen.
Das ist vor allem für kleinere Unternehmen oder Start-ups nützlich, die vielleicht nicht das Budget haben, um ein Team von Datenwissenschaftlern einzustellen oder in teure LLMs zu investieren.
Zweitens können die Nutzerinnen und Nutzer durch die Integration von Python in die Snowflake-Rechenumgebung von der riesigen Bibliothek der verfügbaren Python-Algorithmen und -Tools für maschinelles Lernen profitieren. Das bedeutet, dass sie fortschrittlichere und genauere Modelle erstellen können, ohne neue Programmiersprachen lernen zu müssen.
Unternehmen, die bereits die Snowflake-Umgebung eingeführt haben, können die Vorteile von Cortex AI in vollem Umfang nutzen, da es sich nahtlos in ihr bestehendes Data Warehouse integriert und keine zusätzliche Infrastruktur oder Datenmigration erforderlich ist.
Mit Snowflake Cortex AI können Unternehmen maschinelles Lernen einfach und effizient in ihre Geschäftsprozesse integrieren.
In diesem Tutorial gehen wir durch den Prozess der Einrichtung einer Pipeline für maschinelles Lernen mit Python und Snowflake Cortex AI.
Bevor du mit Snowflake Cortex AI an ML arbeitest, solltest du sicherstellen, dass du die folgenden Voraussetzungen erfüllst:
Zuerst brauchst du eine Snowflake-Instanz, in der deine Daten gespeichert und verarbeitet werden. Du kannst dich anmelden auf der Snowflake-Website.
Fülle im Anmeldeformular alle deine Kontodaten aus und beachte, dass du auf der zweiten Seite die folgenden Auswahlen triffst. Wähle für dieses Tutorial die Standard-Edition und Amazon Web Services, um es einfacher und reproduzierbarer zu machen. Für den Server wählst du US West (Oregon), wo du die beste Auswahl an LLM-Funktionen findest.

Sobald du diese Optionen ausgewählt hast, klickst du auf Loslegen, um die Aktivierungs-E-Mail zu erhalten. Klicke auf deine E-Mail, um dein Konto zu aktivieren, und schon ist dein Snowflake-Konto einsatzbereit.
Als Nächstes musst du noch einige andere Anforderungen an die Software erfüllen.
Hier ist eine einfache Liste mit Dingen, die man dabei haben sollte:
Bevor du mit einer Analyse beginnst, installiere alle relevanten Pakete, damit deine Programmierumgebung bereit ist.
Um die notwendigen Pakete zu installieren, kannst du pip:
pip install snowflakepip install python-dotenvNachdem du die Bibliotheken installiert hast, musst du deinen Arbeitsordner und deine Dateien einrichten, um zu beginnen.
Ich habe einen Ordner mit dem Namen Cortex AI Tutorial erstellt und eine neue .env Datei mit den folgenden Informationen hinzugefügt :
SNOWFLAKE_ACCOUNT = "<YOUR_ACCOUNT>" # eg. XXXX-XXXX
SNOWFLAKE_USER = "<YOUR_USER>"
SNOWFLAKE_USER_PASSWORD = "<YOUR_PASSWORD>"Nachdem du deine Kontoinformationen eingegeben hast, speicherst du die Datei und erstellst eine Python- oder Jupyter-Notebook-Datei im selben Ordner.
Nachdem du nun alles eingerichtet hast, können wir deine Python-Umgebung mit Snowflake verbinden.
Zunächst öffnest du deine Python-Datei und importierst alle notwendigen Bibliotheken. Hier ist der Code, um dies zu tun:
import os
from dotenv import load_dotenv
from snowflake.snowpark import Session
from snowflake.cortex import Summarize, Complete, ExtractAnswer, Sentiment, Translate, EmbedText768Als Nächstes musst du die Variablen laden, die du in der Datei.env gespeichert hast , die du zuvor gespeichert hast. Dadurch erhält Snowflake deine Zugangsdaten, um sich anzumelden und die Funktionen zu nutzen.
# Loads environment variables from .env
load_dotenv()
connection_params = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_USER_PASSWORD"],
}
Wenn du dich mit den Variablen verbunden hast, musst du eine Snowflake-Sitzung einrichten. Dies ist das Objekt, das alle deine Anfragen bearbeiten wird.
# Creates a Snowflake session
snowflake_session = Session.builder.configs(connection_params).create()Die LLM-Funktionen in Cortex AI ermöglichen es den Nutzern, das Potenzial von LLMs zu nutzen, ohne eigene KI-Modelle entwickeln zu müssen.
Diese Funktionen helfen dem durchschnittlichen Analytics-Nutzer mit KI-gestützter Analyse durch einige grundlegende Aufgaben.
Hier sind die Funktionen, die Snowflake Cortex hat:
Die Funktion "Zusammenfassen" wird verwendet, um eine Zusammenfassung der Daten auf der Grundlage der eingegebenen Daten zu erstellen.
Es nutzt LLMs, um Schlüsselinformationen zu identifizieren und sie in einem komprimierten Format zu präsentieren.
Wenn du zum Beispiel ein langes Textdokument hast und dir einen schnellen Überblick über den Inhalt verschaffen willst, kannst du die Funktion "Zusammenfassen" verwenden, um eine kurze Zusammenfassung zu erhalten, die die wichtigsten Punkte enthält. Das spart Zeit und ermöglicht eine schnellere Analyse von großen Datenmengen.
Die Eingabesprache ist zum Zeitpunkt der Erstellung dieses Artikels auf Englisch beschränkt.
Siehe den Code unten als Referenz:
# Defines the Summarize LLM Function
def summarize(user_text):
summary = Summarize(text=user_text, session=snowflake_session)
return summaryDie Übersetzungsfunktion wird verwendet, um Text von einer Sprache in eine andere zu übersetzen.
Es nutzt maschinelle Lernalgorithmen und statistische Modelle, um den Text genau zu übersetzen.
Dies kann nützlich sein, wenn du mit Daten oder Dokumenten in verschiedenen Sprachen arbeitest, da dies die Kommunikation und das Verständnis erleichtert.
Wenn du zum Beispiel einen Bericht auf Spanisch geschrieben hast und ihn einem englischsprachigen Publikum präsentieren musst, kannst du den Text mit der Übersetzungsfunktion schnell umwandeln. Dadurch entfällt die Notwendigkeit einer manuellen Übersetzung und du sparst Zeit.
Siehe den Code unten als Referenz:
# Defines the Translate LLM Function
def translate(user_text):
translation = Translate(
text=user_text, from_language="en", to_language="ko", session=snowflake_session
)
return translationDie vollständige Funktion ist eine allumfassende Funktion, die zur Ausführung bestimmter Aufgaben verwendet werden kann. Dies geschieht durch die Verwendung von Satzaufforderungen, die das KI-Modell anleiten, die notwendigen Informationen zur Ausführung einer Aufgabe zu liefern.
Siehe den Code unten als Referenz:
# Defines the Complete LLM Function
def complete(user_text):
completion = Complete(
model="snowflake-arctic",
prompt=f"Provide 3 relevant keywords from the following text: {user_text}",
session=snowflake_session,
)
return completionDie Funktion "Antwort extrahieren" gibt eine Antwort basierend auf der Frage, die dem Modell gestellt wurde. Die Eingabe muss in Englisch in einem String- oder JSON-Format erfolgen.
Siehe den Code unten als Referenz:
# Defines the Extract Answer LLM Function
def extract_answer(user_text):
answer = ExtractAnswer(
from_text=user_text,
question="What are some reasons why young adult South Koreans love coffee?",
session=snowflake_session,
)
return answerDie Sentiment-Funktion liefert eine quantitative Zahl, die auf dem Sentiment des bereitgestellten Textes basiert. Sie gibt einen Wert aus, der zwischen -1 und 1 liegt. Werte mit -1 sind die negativsten, 1 die positivsten, und Werte um 0 sind neutral.
Siehe den Code unten als Referenz:
# Defines the Sentiment LLM Function
def sentiment(user_text):
sentiment = Sentiment(text=user_text, session=snowflake_session)
return sentimentZu den Funktionen zum Einbetten von Text gehören die Funktion EMBED_TEXT_768 und die Funktion EMBED_TEXT_1024. Sie erzeugen Vektoreinbettungen mit 768 bzw. 1024 Dimensionen.
Im folgenden Code findest du Hinweise zu den Funktionen von EMBED_TEXT_768:
# Defines the Embed Text LLM Function
def embed_text(user_text):
embed_text = EmbedText768(text=user_text, model='snowflake-arctic-embed-m', session=snowflake_session)
return embed_textJetzt wollen wir sie alle in einer Hauptfunktion zusammenfassen und sie durch einen Beispieltext laufen lassen, um die Ergebnisse zu sehen.
Ich habe einen einfachen, kurzen Text verwendet, den ich in das Modell eingegeben habe, wie unten gezeigt:

Um das Kopieren und Einfügen zu erleichtern, hier der Text:
user_text = """
Young adults in South Korea are embracing coffee as a blend of energy, comfort, and culture.
Coffee isn't just about staying awake during demanding studies or work; it’s a cherished part of daily routines.
With South Korea's bustling café culture, coffee shops have become popular spaces for socializing, studying,
or just taking a break from the fast-paced city life.
The diversity of flavors and trendy cafés also offers a unique,
stylish experience that fits right into the evolving lifestyle of young adults,
who seek both connection and personal moments in the midst of it all.
"""Jetzt lass uns den Code ausführen. Es sollte nur ein paar Sekunden dauern.
Hier sind die Ergebnisse:
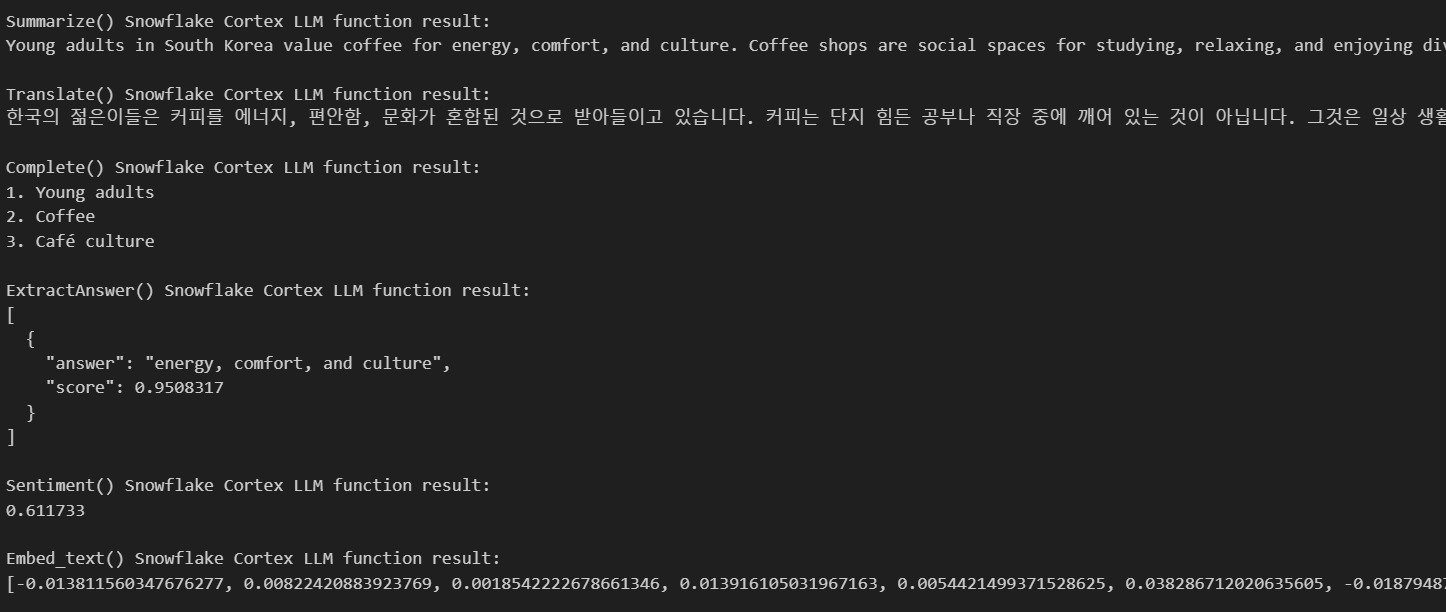
Wie du siehst, hat uns die KI alle Ergebnisse geliefert, die wir auf der Grundlage des von uns angegebenen Textes benötigen. Es gab uns eine Zusammenfassung, übersetzte meinen Text ins Koreanische, nannte mir drei Schlüsselwörter, die auf meinem Text basierten, und gab einige Antworten auf meine Fragen.
Cortex AI hat auch ML-Funktionen, die nur mit SQL ausgeführt werden können. Hier sind die verschiedenen Funktionen, die es bietet.
Die Erkennung von Anomalien ist wichtig, um ungewöhnliche Muster zu erkennen, die nicht zu dem erwarteten Verhalten deiner Daten passen. Snowflake vereinfacht die Erkennung von Anomalien durch integrierte maschinelle Lernfunktionen, die auf einer Gradient-Boosting-Maschine (GBM) basieren, mit der du schnell Ausreißer in deinen Datensätzen identifizieren kannst.
Die Erkennung von Anomalien ist besonders nützlich für Aufgaben wie:
Um Anomalien zu erkennen, kann die Snowflake-Klasse ANOMALY_DETECTION (SNOWFLAKE.ML) verwendet werden. Dieser Befehl erstellt ein Modellobjekt für die Anomalieerkennung. Dieser Schritt passt dein Modell an die Trainingsdaten an.
Hier erfährst du, wie du es verwenden kannst:
CREATE [ OR REPLACE ] SNOWFLAKE.ML.ANOMALY_DETECTION <model_name>(
INPUT_DATA => <reference_to_training_data>,
[ SERIES_COLNAME => '<series_column_name>', ]
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
LABEL_COLNAME => '<label_column_name>',
[ CONFIG_OBJECT => <config_object> ]
)
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT = '<string_literal>' ]Sobald du das Objekt erstellt hast, kannst du die Methode <model_name>!DETECT_ANOMALIES verwenden, um eine Anomalieerkennung durchzuführen,
<model_name>!DETECT_ANOMALIES(
INPUT_DATA => <reference_to_data_to_analyze>,
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
[ CONFIG_OBJECT => <configuration_object>, ]
[ SERIES_COLNAME => '<series_column_name>' ]
)Dies ist der eigentliche Vorhersageschritt, bei dem die Ausreißer mithilfe der Methode ermittelt werden.
Hier ist ein Beispiel dafür, wie die Erkennung von Anomalien mithilfe eines Datensatzes durchgeführt werden kann.
Zuerst kannst du eine Datenbank erstellen, indem du auf der linken Registerkarte auf Daten gehst und dann auf Daten hinzufügen und anschließend auf Daten in eine Tabelle laden.

In dem Fenster, das sich öffnet, klickst du auf + Datenbank und gibst deiner Datenbank einen Namen. Klicke auf "Erstellen" und dann im Hauptfenster auf "Abbrechen".
Dadurch wird eine leere Datenbank erstellt, mit der du arbeiten kannst.
Die folgenden Beispiele wurden aus der Schneeflocken-Dokumentation.
Um mit der Anomalieerkennung zu beginnen, öffnest du ein neues SQL-Arbeitsblatt, wählst deine neue Datenbank als Datenquelle aus und fügst den folgenden Code ein, um eine Tabelle zu erstellen:
CREATE OR REPLACE TABLE historical_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN,
Temperatur NUMBER, Feuchtigkeit FLOAT, Urlaub VARCHAR);
// Creating the dataset
INSERT INTO historical_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'),
(1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'),
(2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);Dein Code sollte in einem SQL-Arbeitsblatt stehen, das wie folgt aussieht:
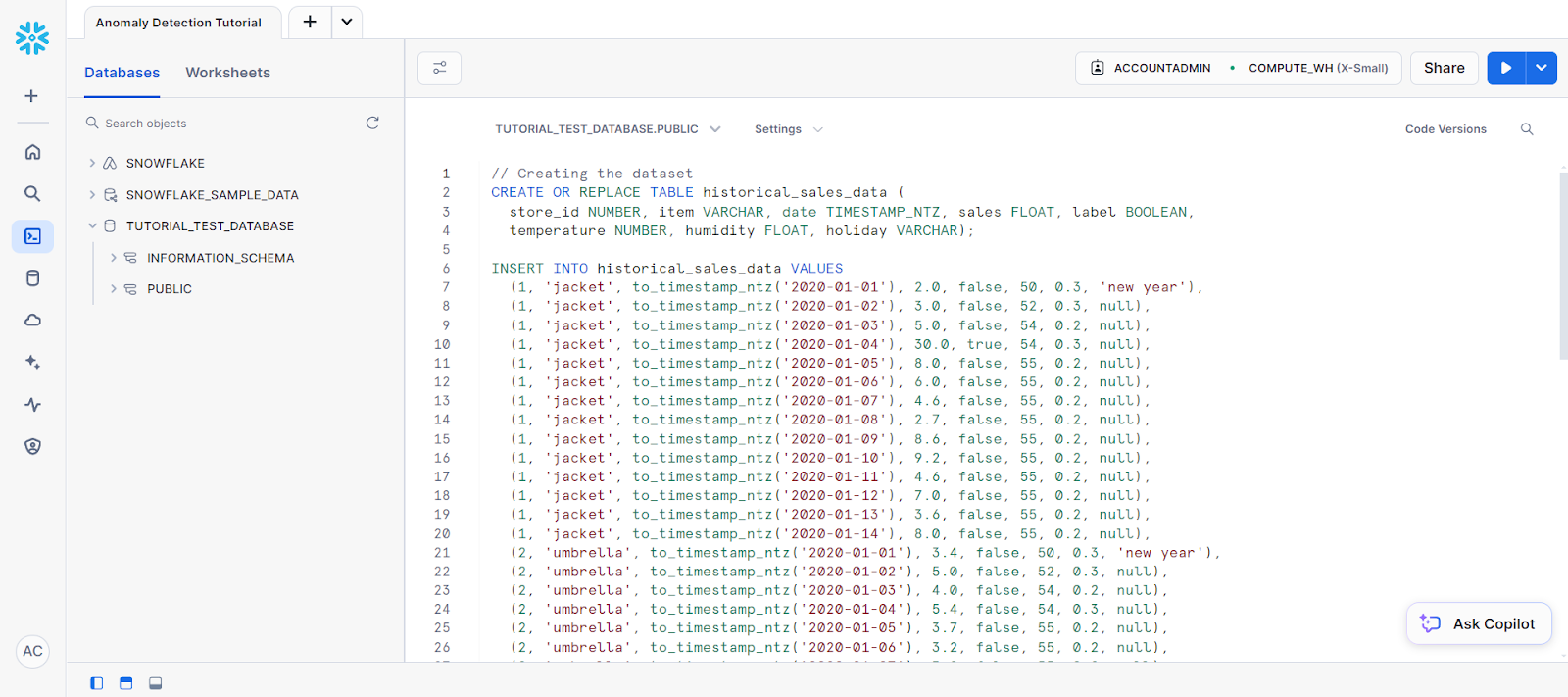
Es folgen die folgenden Anweisungen, um eine Tabelle namens new_sales_data zu erstellen.
// Creating a new table and adding training data
CREATE OR REPLACE TABLE new_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT,
temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO new_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);Jetzt erstellst du das Modell zur Erkennung von Anomalien:
// Creating anomaly detection model object
CREATE OR REPLACE VIEW view_with_training_data
AS SELECT date, sales FROM historical_sales_data
WHERE store_id=1 AND item='jacket';
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model(
INPUT_DATA => TABLE(view_with_training_data),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '');Dies sollte zu einem Ergebnis führen, das besagt, dass ein Modell erstellt wurde (siehe unten).

Als Nächstes verwenden wir das Objektmodell, um eine Erkennung durchzuführen.
// Perform anomaly detection
CREATE OR REPLACE VIEW view_with_data_to_analyze
AS SELECT date, sales FROM new_sales_data
WHERE store_id=1 and item='jacket';
CALL basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
);Hier ist das Ergebnis der Erkennung:
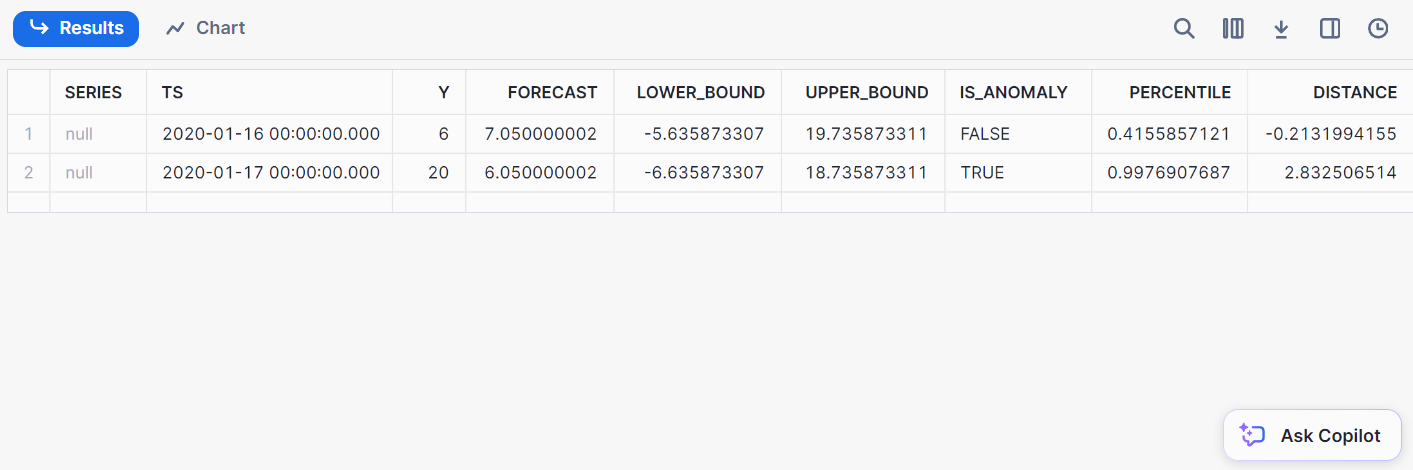
Klassifizierung beinhaltet die Einteilung von Daten in vordefinierte Klassen. Mit Snowflake kannst du Daten direkt aus Snowflake heraus klassifizieren, sodass der Datenexport in externe ML-Umgebungen entfällt.
Um zu beginnen, erstelle einen Beispieldatensatz mit dem folgenden Code:
// Creating binary class dataset
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating,
FALSE AS label,
'not_interested' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating,
FALSE AS label,
'add_to_wishlist' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating,
TRUE AS label,
'purchase' AS class
FROM TABLE(GENERATOR(rowCount => 100))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
);Für die Trainingsdaten wollen wir eine neue Ansicht erstellen.
// Creating view for training data
CREATE OR REPLACE view binary_classification_view AS
SELECT user_interest_score, user_rating, label
FROM training_purchase_data;
SELECT * FROM binary_classification_view ORDER BY RANDOM(42) LIMIT 5;Diese Ansicht sollte die folgenden Ergebnisse ausgeben:
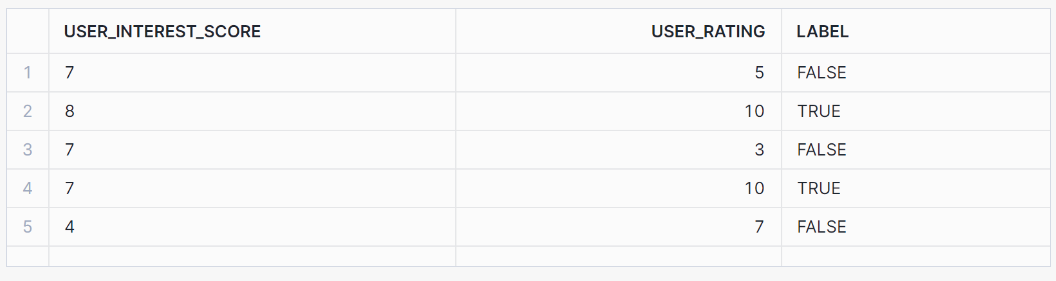
Als Nächstes trainieren wir das Modell auf der Grundlage unserer Trainingsdaten:
// Training a binary classification model
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label'
);Um eine Klassifizierung vorzunehmen, verwende die Methode PREDICT:
// Performing prediction using PREDICT method
SELECT model_binary!PREDICT(INPUT_DATA => {*})
AS prediction FROM prediction_purchase_data;So sieht die Vorhersage aus:
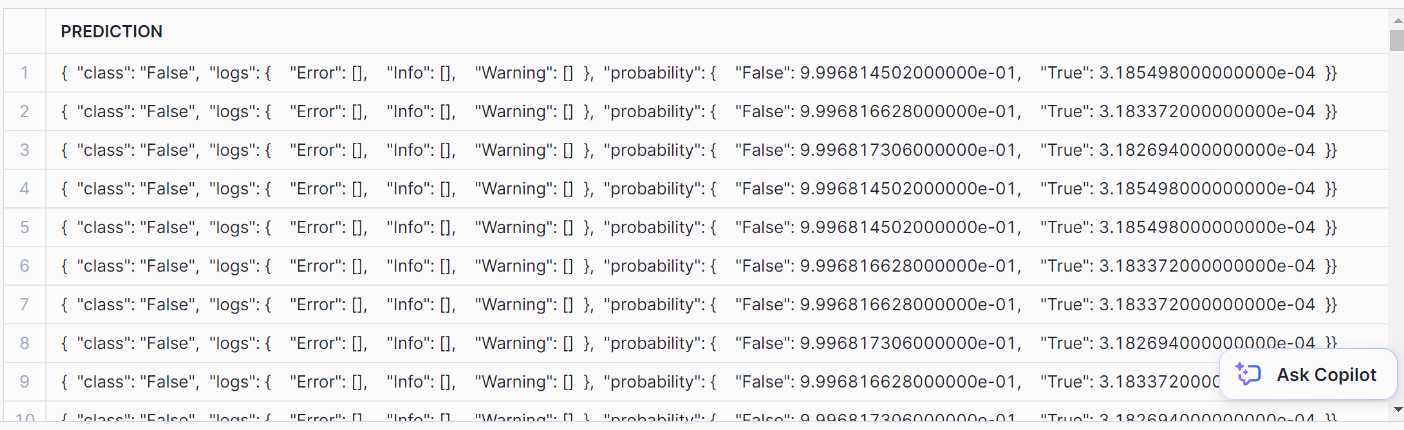
Um es schön zu formatieren, verwende diese SQL-Anweisung:
// Formatting SQL predictions
SELECT *, model_binary!PREDICT(INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data;Du solltest dieses ordentliche Ausgabeformat für die Vorhersagen erhalten:
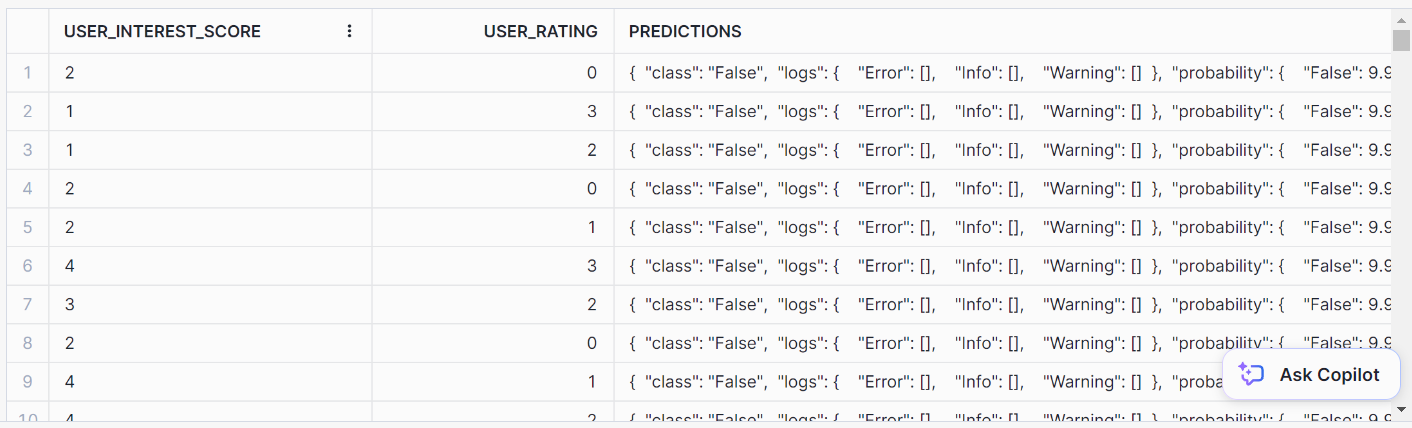
Top Insights ist ein Monitoring-Tool, mit dem du durch eine Zeitreihenanalyse Schwankungen in deinen Kennzahlen im Laufe der Zeit feststellen kannst. Mithilfe eines Entscheidungsbaummodells kann Top Insights die wichtigsten Faktoren identifizieren, die zu einem Anstieg oder Rückgang einer bestimmten Kennzahl beitragen.
Schauen wir uns ein Beispiel für eine Zeitreihenanalyse mit dieser Funktion an.
Als erstes erstellen wir einen Datensatz:
// Creating dataset
CREATE OR REPLACE TABLE input_table(
ds DATE, metric NUMBER, dim_country VARCHAR, dim_vertical VARCHAR);
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, seq4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
-- Data for the test group
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(300, 320, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertica
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(400, 420, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
// Creating new view and adding labels to timestamps
CREATE OR REPLACE VIEW input_view AS (
SELECT
metric,
dim_country as country,
dim_vertical as vertical,
ds >= '2021-01-01' AS label
FROM input_table
);Als Nächstes müssen wir das Modellobjekt für die Vorhersage erstellen. Dies wird benötigt, um auf die Methode GET_DRIVERS zuzugreifen.
// Creating the model
CREATE OR REPLACE SNOWFLAKE.ML.TOP_INSIGHTS my_insights_model()Für die Vorhersage rufst du schließlich die Methode GET_DRIVERS auf.
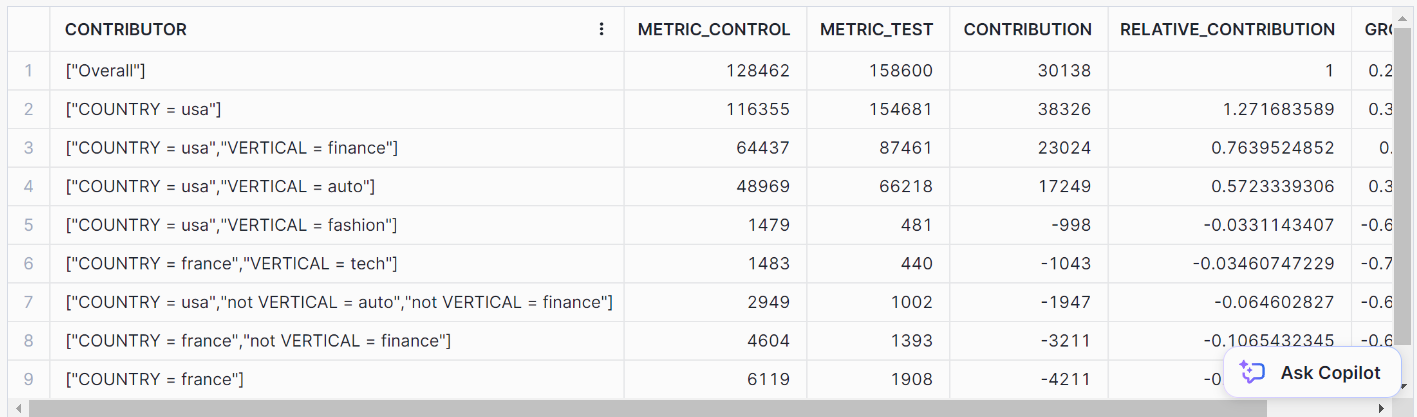
// Performing prediction using GET_DRIVERS method
CALL my_insights_model!GET_DRIVERS(
INPUT_DATA => TABLE(input_view),
LABEL_COLNAME => 'label',
METRIC_COLNAME => 'metric'
);Das sollte dir die folgenden Ergebnisse liefern:
Prognosen sind wichtig, wenn du auf der Grundlage historischer Daten zukünftige Werte vorhersagen musst. Ob es um Umsatzprognosen, die Vorhersage des Energieverbrauchs oder die Vorhersage des Web-Traffics geht, die integrierten Funktionen von Snowflake machen diese Aufgaben viel einfacher.
Für unser Beispiel wollen wir eine Prognose für eine einzelne Reihe erstellen:
// Creating the dataset
CREATE OR REPLACE TABLE sales_data (store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ,
sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO sales_data VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL);
-- Future values for additional columns (features)
CREATE OR REPLACE TABLE future_features (store_id NUMBER, item VARCHAR,
date TIMESTAMP_NTZ, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO future_features VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL);Als Nächstes trennen wir die Trainingsdaten vom Datensatz.
// Creating a view for training data
CREATE OR REPLACE VIEW v1 AS SELECT date, sales
FROM sales_data WHERE store_id=1 AND item='jacket';
SELECT * FROM v1;Bevor du mit der Vorhersage beginnen kannst, musst du dein Modell auf der Grundlage der ausgewählten Trainingsdaten trainieren.
So kannst du es tun:
// Training a forecasting model
CREATE SNOWFLAKE.ML.FORECAST model1(
INPUT_DATA => TABLE(v1),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales'
);Schließlich kannst du für die Vorhersage die Methode FORECAST aufrufen, um den Vorhersageschritt durchzuführen.
// Performing the forecast by calling the FORECAST method
call model1!FORECAST(FORECASTING_PERIODS => 5);Das ist das Ergebnis unserer Vorhersage.
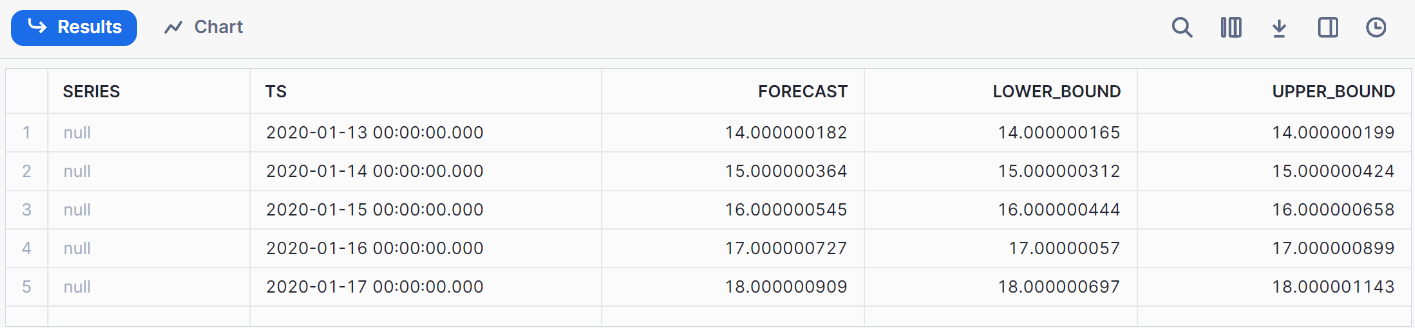
Die Überwachung der Modellleistung kann durch die Erstellung von Dashboards in Snowflake mithilfe von Drittanbieter-Integrationen (wie Tableau) oder durch die Abfrage von Snowflake-Protokollen erfolgen. Einige nützliche Metriken wie Genauigkeit, Präzision und Wiedererkennung können für Tracking-Modelle verwendet werden.
Snowflake Cortex AI vereinfacht das maschinelle Lernen, indem es die nahtlose Integration von Modellen aus der Snowflake-Plattform ermöglicht. Dieses Tutorial führt dich durch die Nutzung der Snowflake Cortex AI und Snowflake Cortex ML Funktionen.
Diese Lösung nutzt die Skalierbarkeit von Snowflake und die Flexibilität von Python und ist damit ideal für Unternehmen, die maschinelles Lernen implementieren wollen, ohne Daten außerhalb der Cloud zu verschieben.
Du suchst nach weiteren Informationen über Snowflake? Das wird dir gefallen Schneeflocken-Tutorial für Anfänger und unser Snowpark Anleitung. Wenn du nach etwas Umfassenderem suchst, dann ist die Einführung in Snowflake vielleicht der richtige Kurs für dich.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.