
Programa
Fundamentos de machine learning Em Python
16 h
O treinamento de modelos de IA tem aumentado como uma das possíveis aplicações da IA na ciência de dados. Mais especificamente, o aprendizado de máquina pode ser feito usando o Snowflake Cortex AI.
Neste guia, abordaremos áreas sobre o que é a IA do Snowflake Cortex e o que ela pode fazer. Além disso, forneceremos um tutorial simples sobre como você pode começar a usar o aprendizado de máquina e a IA usando Python e um pouco de SQL. Se você é novo no Snowflake, confira nosso Curso de introdução ao Snowflake para você se familiarizar com o assunto.
O Snowflake Cortex AI é um recurso avançado integrado ao Snowflake AI Data Cloud, projetado para facilitar as operações de aprendizado de máquina (ML) diretamente no ambiente do Snowflake.
Ele permite a integração perfeita dos modelos Python ML com os dados do Snowflake, possibilitando que as organizações obtenham insights, previsões e análises avançadas de grandes conjuntos de dados, aproveitando a infraestrutura de nuvem.
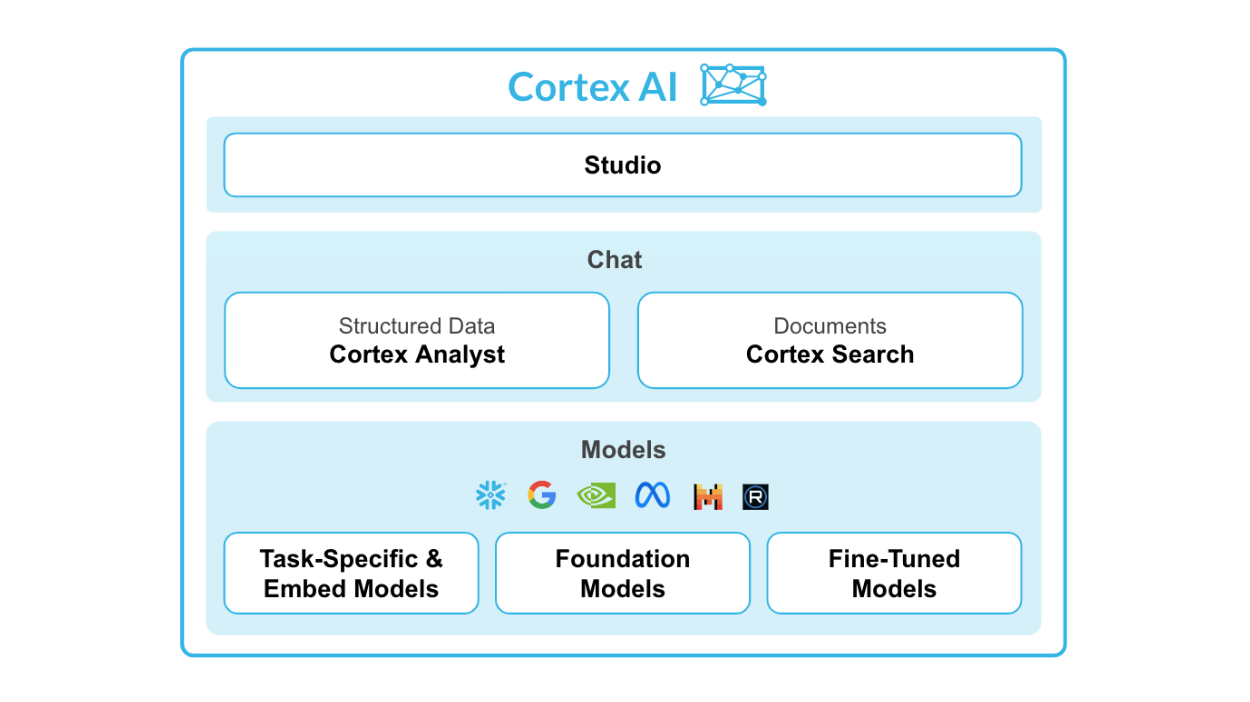
Fonte: IA do Cortex Snowflake
Principais recursos do Snowflake Cortex AI:
O Snowflake Cortex é composto por duas partes principais: funções de ML e funções de ML.
Para as funções do LLM, você tem:
Veremos cada função em detalhes mais adiante.
Para as funções de ML, você tem:
Você quer saber onde aprender o Snowflake e suas funções? Nosso tutorial de floco de neve para iniciantes Tutorial de floco de neve para iniciantes e Guia de certificação do Snowflake ajudarão você.
Vejamos agora os benefícios de usar essas ferramentas em conjunto.
Alguns dos principais benefícios do uso do Snowflake Cortex AI são:
Em primeiro lugar, o Snowflake Cortex AI é perfeito para empresas que buscam aprimorar seus recursos de ciência de dados sem um investimento significativo em recursos. Com seu ambiente sem código, até mesmo usuários não técnicos podem desenvolver e implementar facilmente modelos de ML.
Isso é especialmente útil para empresas menores ou startups que talvez não tenham o orçamento para contratar uma equipe de cientistas de dados ou investir em LLMs caros.
Em segundo lugar, ao integrar o Python ao ambiente de computação da Snowflake, os usuários podem aproveitar a vasta biblioteca de ferramentas e algoritmos de aprendizado de máquina do Python disponíveis. Isso significa que eles podem criar modelos mais avançados e precisos sem precisar aprender novas linguagens de programação.
Por fim, as empresas que já adotaram o ambiente Snowflake colherão todos os benefícios do Cortex AI, pois ele se integra perfeitamente ao data warehouse existente, eliminando a necessidade de infraestrutura adicional ou migração de dados.
Com o Snowflake Cortex AI, as empresas podem implementar o aprendizado de máquina de forma fácil e eficiente em seus processos de negócios.
Neste tutorial, você verá o processo de configuração de um pipeline de aprendizado de máquina usando Python e Snowflake Cortex AI.
Antes de começar a trabalhar no ML com o Snowflake Cortex AI, verifique se você atende aos seguintes requisitos:
Primeiro, você precisará de uma instância do Snowflake em que seus dados sejam armazenados e processados. Você pode se inscrever no site da Snowflake.
No formulário de inscrição, preencha todos os detalhes da sua conta e lembre-se de fazer as seguintes seleções na segunda página. Selecione a edição Standard para este tutorial e o Amazon Web Services para fins de simplicidade e reprodutibilidade. Para o servidor, escolha US West (Oregon) para obter a melhor seleção de funções de LLM disponíveis.

Depois que você tiver selecionado essas opções, clique em Get Started para receber o e-mail de ativação. Vá até seu e-mail para ativar sua conta e sua conta Snowflake estará pronta para ser usada.
Em seguida, você também precisará atender a alguns outros requisitos do software.
Aqui está uma lista simples de coisas que você deve ter:
Antes de você iniciar qualquer análise, instale todos os pacotes relevantes para que seu ambiente de codificação esteja pronto.
Para instalar os pacotes necessários, você pode usar o pip:
pip install snowflakepip install python-dotenvDepois de instalar as bibliotecas, você precisará configurar a pasta de trabalho e os arquivos para começar.
Criei uma pasta chamada Cortex AI Tutorial e incluí um novo arquivo .env com as seguintes informações:
SNOWFLAKE_ACCOUNT = "<YOUR_ACCOUNT>" # eg. XXXX-XXXX
SNOWFLAKE_USER = "<YOUR_USER>"
SNOWFLAKE_USER_PASSWORD = "<YOUR_PASSWORD>"Depois de inserir as informações da sua conta, salve o arquivo e crie um arquivo Python ou Jupyter Notebook na mesma pasta.
Agora que você já tem tudo pronto, vamos conectar seu ambiente Python ao Snowflake.
Para começar, abra o arquivo Python e importe todas as bibliotecas necessárias. Aqui está o código para você fazer isso:
import os
from dotenv import load_dotenv
from snowflake.snowpark import Session
from snowflake.cortex import Summarize, Complete, ExtractAnswer, Sentiment, Translate, EmbedText768Em seguida, você terá de carregar as variáveis salvas no arquivo.env que salvou anteriormente. Isso fornecerá à Snowflake as credenciais da sua conta para que você possa fazer login e usar as funções da empresa.
# Loads environment variables from .env
load_dotenv()
connection_params = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_USER_PASSWORD"],
}
Depois de se conectar usando as variáveis, você precisará configurar uma sessão do Snowflake. Esse é o objeto que tratará de todas as suas solicitações.
# Creates a Snowflake session
snowflake_session = Session.builder.configs(connection_params).create()As funções de LLM no Cortex AI permitem que os usuários aproveitem o potencial dos LLMs sem a necessidade de desenvolver seus próprios modelos de IA.
Essas funções ajudam a fornecer ao usuário médio de análise uma análise baseada em IA por meio de algumas tarefas básicas.
Aqui estão as funções que o Snowflake Cortex tem:
A função summarize é usada para gerar um resumo dos dados com base na entrada fornecida.
Ele usa LLMs para identificar informações importantes e apresentá-las em um formato condensado.
Por exemplo, se você tiver um documento de texto longo e quiser ter uma visão geral rápida de seu conteúdo, poderá usar a função resumir para obter um breve resumo que capture os pontos importantes. Isso economiza tempo e permite uma análise mais rápida de grandes quantidades de dados.
O idioma de entrada está atualmente limitado ao inglês no momento da redação deste artigo.
Veja o código abaixo para referência:
# Defines the Summarize LLM Function
def summarize(user_text):
summary = Summarize(text=user_text, session=snowflake_session)
return summaryA função de tradução é usada para converter texto de um idioma para outro.
Ele faz uso de algoritmos de aprendizado de máquina e modelos estatísticos para traduzir o texto com precisão.
Isso pode ser útil quando você trabalha com dados ou documentos em diferentes idiomas, pois facilita a comunicação e a compreensão.
Por exemplo, se você tiver um relatório escrito em espanhol e precisar apresentá-lo a um público de língua inglesa, poderá usar a função de tradução para converter rapidamente o texto. Isso elimina a necessidade de tradução manual e economiza tempo.
Veja o código abaixo para referência:
# Defines the Translate LLM Function
def translate(user_text):
translation = Translate(
text=user_text, from_language="en", to_language="ko", session=snowflake_session
)
return translationA função completa é uma função completa que pode ser usada para realizar tarefas específicas. Isso é feito por meio do uso de prompts de frases que orientam o modelo de IA a fornecer as informações necessárias para executar uma tarefa.
Veja o código abaixo para referência:
# Defines the Complete LLM Function
def complete(user_text):
completion = Complete(
model="snowflake-arctic",
prompt=f"Provide 3 relevant keywords from the following text: {user_text}",
session=snowflake_session,
)
return completionA função extrair resposta fornece uma resposta com base na pergunta fornecida ao modelo. A entrada deve estar em inglês em um formato de cadeia de caracteres ou JSON.
Veja o código abaixo para referência:
# Defines the Extract Answer LLM Function
def extract_answer(user_text):
answer = ExtractAnswer(
from_text=user_text,
question="What are some reasons why young adult South Koreans love coffee?",
session=snowflake_session,
)
return answerA função de sentimento fornece um número quantitativo com base no sentimento do texto fornecido. Ele gera um valor que varia de -1 a 1. Os valores com -1 são os mais negativos, 1 os mais positivos e os valores em torno de 0 são neutros.
Veja o código abaixo para referência:
# Defines the Sentiment LLM Function
def sentiment(user_text):
sentiment = Sentiment(text=user_text, session=snowflake_session)
return sentimentAs funções de texto incorporado incluem a função EMBED_TEXT_768 e a função EMBED_TEXT_1024. Eles criam incorporação de vetores de 768 e 1024 dimensões, respectivamente.
Consulte o código abaixo para obter referência sobre as funções do site EMBED_TEXT_768:
# Defines the Embed Text LLM Function
def embed_text(user_text):
embed_text = EmbedText768(text=user_text, model='snowflake-arctic-embed-m', session=snowflake_session)
return embed_textAgora, vamos reuni-las em uma função principal e executá-la em um texto de amostra para que você veja os resultados.
Usei um texto simples e curto para inserir no modelo, conforme mostrado abaixo:

Para facilitar a cópia e a colagem, aqui está o texto:
user_text = """
Young adults in South Korea are embracing coffee as a blend of energy, comfort, and culture.
Coffee isn't just about staying awake during demanding studies or work; it’s a cherished part of daily routines.
With South Korea's bustling café culture, coffee shops have become popular spaces for socializing, studying,
or just taking a break from the fast-paced city life.
The diversity of flavors and trendy cafés also offers a unique,
stylish experience that fits right into the evolving lifestyle of young adults,
who seek both connection and personal moments in the midst of it all.
"""Agora, vamos executar o código. Isso deve levar apenas alguns segundos.
Aqui estão os resultados:
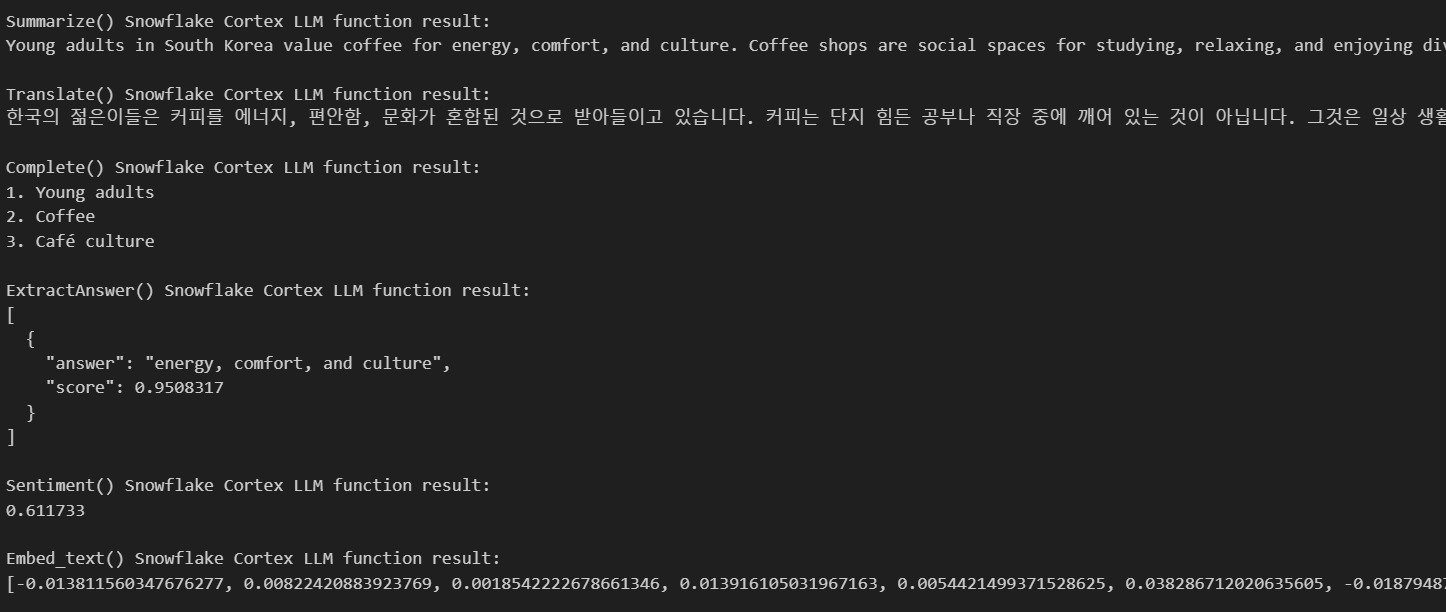
Como você pode ver, a IA nos forneceu todos os resultados necessários com base no texto que fornecemos. Ele nos forneceu um resumo, traduziu meu texto para o coreano, apresentou três palavras-chave com base no meu texto e forneceu algumas respostas com base nas minhas perguntas.
O Cortex AI também tem funções de ML que podem ser executadas usando apenas SQL. Aqui estão as várias funções que ele oferece.
A detecção de anomalias é essencial para identificar padrões incomuns que não se encaixam no comportamento esperado de seus dados. O Snowflake simplifica a detecção de anomalias, fornecendo funções integradas de aprendizado de máquina com base em uma máquina de aumento de gradiente (GBM) que permite que você identifique rapidamente as exceções em seus conjuntos de dados.
A detecção de anomalias é particularmente útil para tarefas como:
Para realizar a detecção de anomalias, você pode usar a classe ANOMALY_DETECTION (SNOWFLAKE.ML) do Snowflake. Esse comando cria um objeto de modelo de detecção de anomalias. Esta etapa ajusta seu modelo aos dados de treinamento.
Veja como você pode usá-lo:
CREATE [ OR REPLACE ] SNOWFLAKE.ML.ANOMALY_DETECTION <model_name>(
INPUT_DATA => <reference_to_training_data>,
[ SERIES_COLNAME => '<series_column_name>', ]
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
LABEL_COLNAME => '<label_column_name>',
[ CONFIG_OBJECT => <config_object> ]
)
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT = '<string_literal>' ]Depois de criar o objeto, você pode usar o método <model_name>!DETECT_ANOMALIES para executar a detecção de anomalias,
<model_name>!DETECT_ANOMALIES(
INPUT_DATA => <reference_to_data_to_analyze>,
TIMESTAMP_COLNAME => '<timestamp_column_name>',
TARGET_COLNAME => '<target_column_name>',
[ CONFIG_OBJECT => <configuration_object>, ]
[ SERIES_COLNAME => '<series_column_name>' ]
)Essa é a etapa de previsão real em que os valores discrepantes serão detectados usando o método.
Aqui está um exemplo de como a detecção de anomalias pode ser feita usando um conjunto de dados.
Primeiro, você pode criar um banco de dados acessando Data (Dados) na guia esquerda e, em seguida, Add Data (Adicionar dados), seguido de Load data into a Table (Carregar dados em uma tabela).

Na janela que aparece, clique em + Database (Banco de dados) e dê um nome ao seu banco de dados. Clique em Criar e, na janela pop-up principal, clique em Cancelar.
Isso criará um banco de dados vazio com o qual você poderá trabalhar.
Os exemplos abaixo foram adaptados da Documentação do Snowflake.
Para iniciar a detecção de anomalias, vá para uma nova planilha SQL, selecione o novo banco de dados como a fonte de dados e cole o código a seguir para criar uma tabela:
CREATE OR REPLACE TABLE historical_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN,
temperature NUMBER, humidity FLOAT, holiday VARCHAR);
// Creating the dataset
INSERT INTO historical_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'),
(1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null),
(1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'),
(2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);Seu código deve ser inserido em uma planilha SQL semelhante a esta:
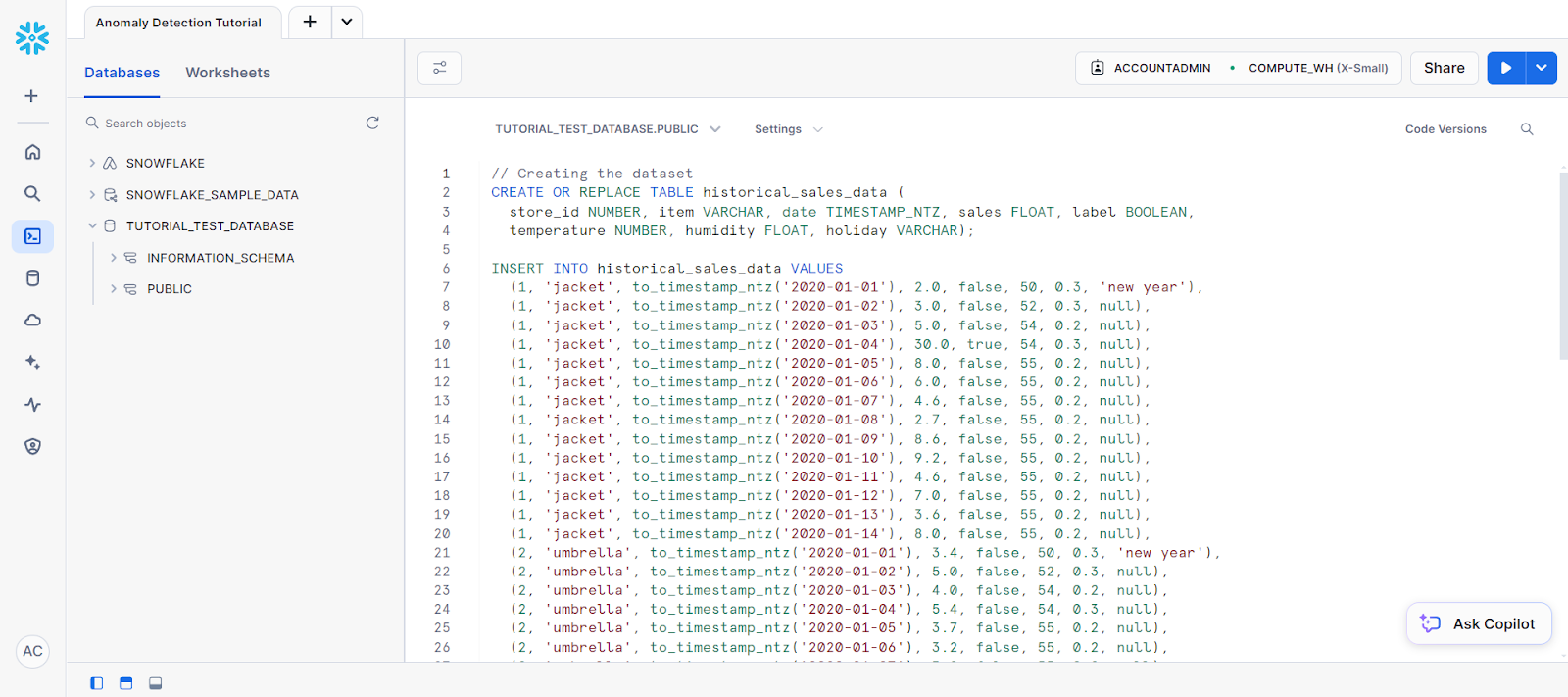
Em seguida, você verá os seguintes comandos para criar uma tabela chamada new_sales_data.
// Creating a new table and adding training data
CREATE OR REPLACE TABLE new_sales_data (
store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT,
temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO new_sales_data VALUES
(1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null),
(1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null),
(2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);Agora, crie o modelo de detecção de anomalias:
// Creating anomaly detection model object
CREATE OR REPLACE VIEW view_with_training_data
AS SELECT date, sales FROM historical_sales_data
WHERE store_id=1 AND item='jacket';
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model(
INPUT_DATA => TABLE(view_with_training_data),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '');Isso deve gerar um resultado informando que um modelo foi criado, conforme mostrado abaixo.

Em seguida, vamos usar o modelo de objeto para fazer algumas detecções.
// Perform anomaly detection
CREATE OR REPLACE VIEW view_with_data_to_analyze
AS SELECT date, sales FROM new_sales_data
WHERE store_id=1 and item='jacket';
CALL basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
);Aqui está o resultado da detecção:
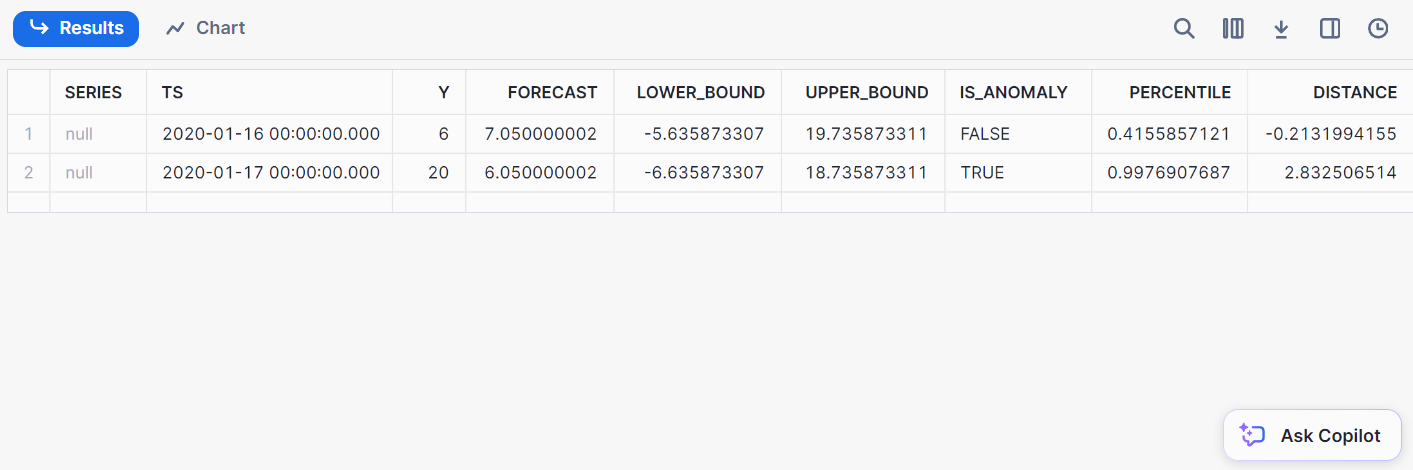
Classificação envolve a categorização de dados em classes predefinidas. Com o Snowflake, você pode classificar os dados diretamente de dentro do Snowflake, eliminando a necessidade de exportar dados para ambientes externos de ML.
Para começar, crie um conjunto de dados de amostra usando o código a seguir:
// Creating binary class dataset
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating,
FALSE AS label,
'not_interested' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating,
FALSE AS label,
'add_to_wishlist' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating,
TRUE AS label,
'purchase' AS class
FROM TABLE(GENERATOR(rowCount => 100))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
);Para fins de dados de treinamento, vamos criar uma nova exibição.
// Creating view for training data
CREATE OR REPLACE view binary_classification_view AS
SELECT user_interest_score, user_rating, label
FROM training_purchase_data;
SELECT * FROM binary_classification_view ORDER BY RANDOM(42) LIMIT 5;Essa exibição deve gerar os seguintes resultados:
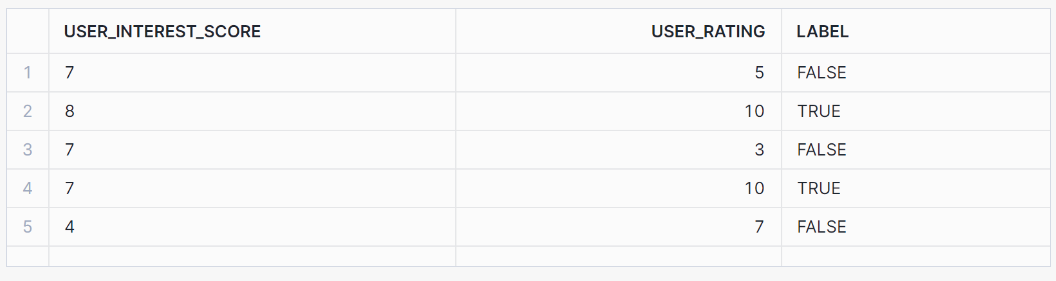
Em seguida, vamos treinar o modelo com base em nossos dados de treinamento:
// Training a binary classification model
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label'
);Para realizar a classificação, use o método PREDICT:
// Performing prediction using PREDICT method
SELECT model_binary!PREDICT(INPUT_DATA => {*})
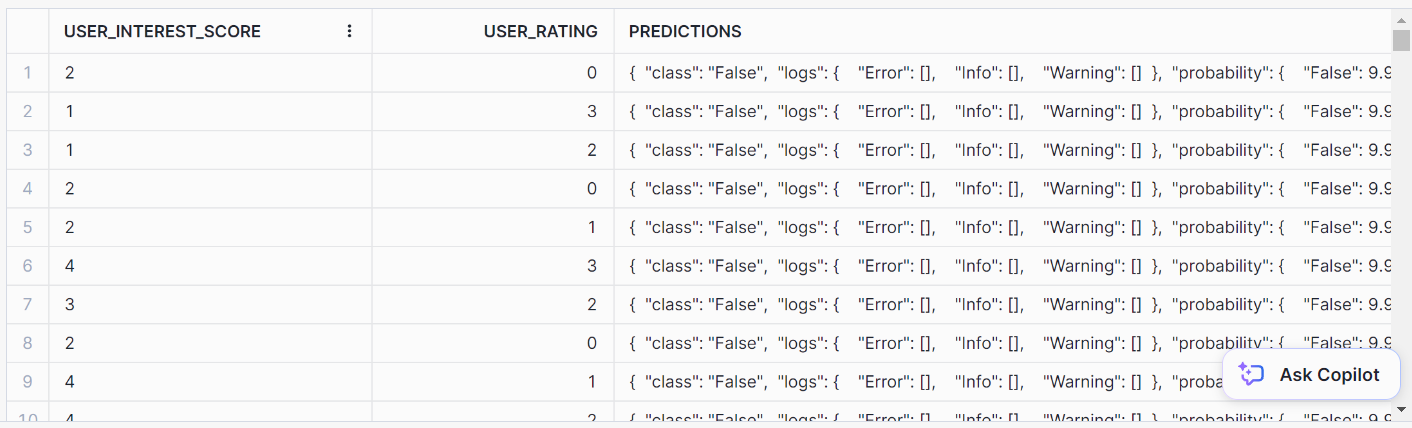
AS prediction FROM prediction_purchase_data;Aqui está o resultado da previsão:
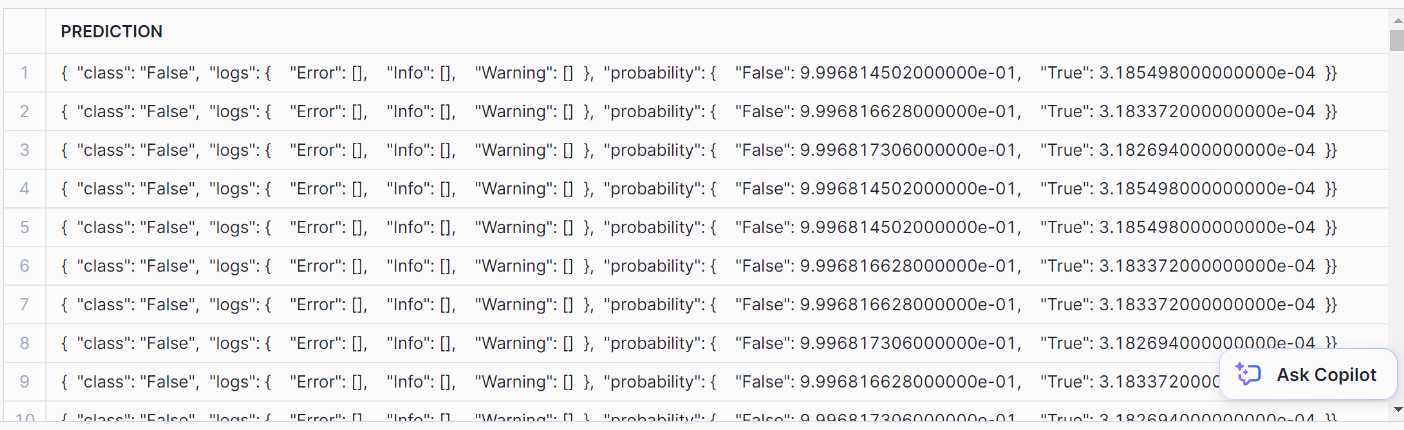
Para formatá-lo bem, use esta instrução SQL:
// Formatting SQL predictions
SELECT *, model_binary!PREDICT(INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data;Você deve chegar a esse formato de saída simples para as previsões:
O Top Insights é uma ferramenta de monitoramento que procura flutuações em suas métricas ao longo do tempo por meio de uma análise de série temporal. Usando um modelo de árvore de decisão, o Top Insights pode identificar os fatores mais importantes que contribuem para o aumento ou a redução de uma determinada métrica.
Vamos dar uma olhada em um exemplo de análise de série temporal usando essa função.
Em primeiro lugar, vamos criar um conjunto de dados:
// Creating dataset
CREATE OR REPLACE TABLE input_table(
ds DATE, metric NUMBER, dim_country VARCHAR, dim_vertical VARCHAR);
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, seq4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'canada' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'fashion' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'tech' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 4, 1)) AS ds,
UNIFORM(1, 10, RANDOM()) AS metric,
'france' AS dim_country,
'auto' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
-- Data for the test group
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(300, 320, RANDOM()) AS metric,
'usa' AS dim_country,
'auto' AS dim_vertica
FROM TABLE(GENERATOR(ROWCOUNT => 365));
INSERT INTO input_table
SELECT
DATEADD(day, SEQ4(), DATE_FROM_PARTS(2020, 8, 1)) AS ds,
UNIFORM(400, 420, RANDOM()) AS metric,
'usa' AS dim_country,
'finance' AS dim_vertical
FROM TABLE(GENERATOR(ROWCOUNT => 365));
// Creating new view and adding labels to timestamps
CREATE OR REPLACE VIEW input_view AS (
SELECT
metric,
dim_country as country,
dim_vertical as vertical,
ds >= '2021-01-01' AS label
FROM input_table
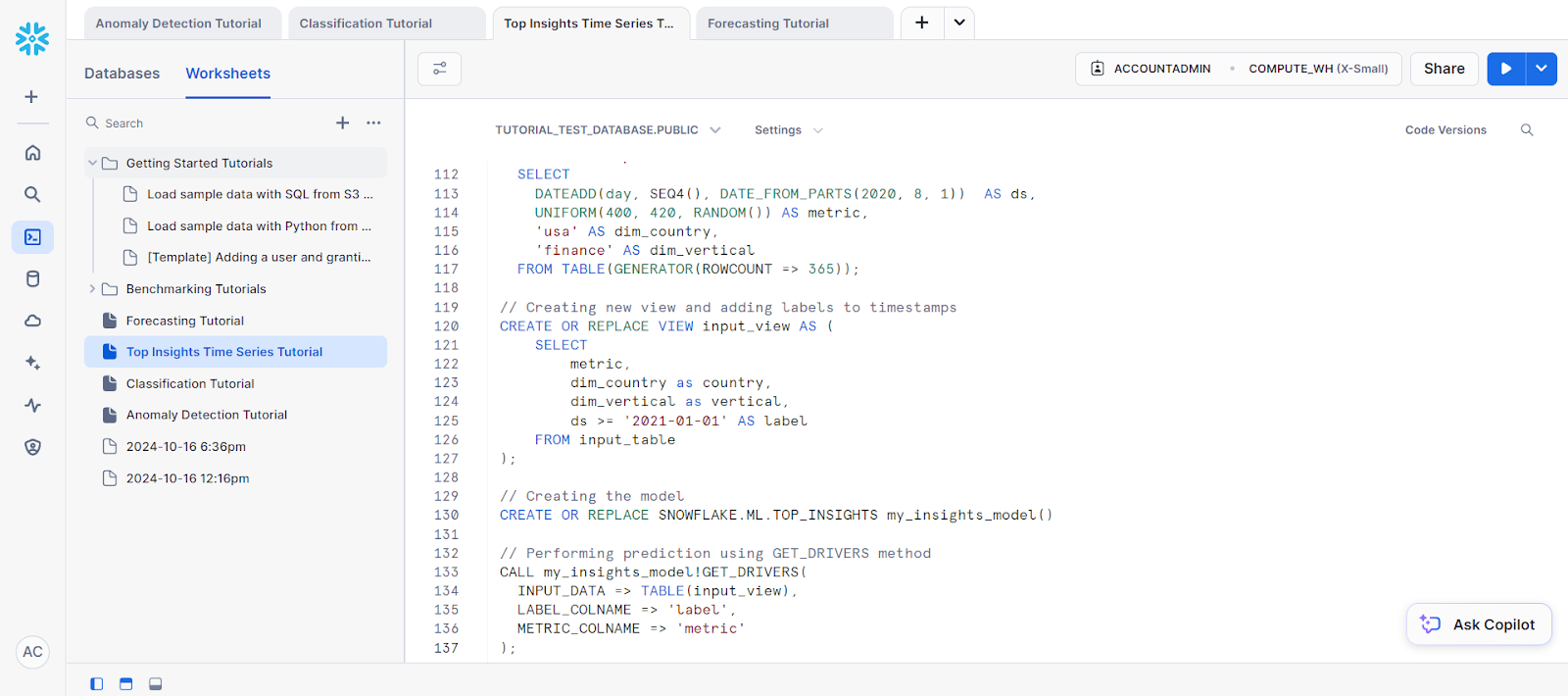
);Em seguida, precisamos criar o objeto de modelo para a previsão. Isso é necessário para que você possa acessar o método GET_DRIVERS.
// Creating the model
CREATE OR REPLACE SNOWFLAKE.ML.TOP_INSIGHTS my_insights_model()Por fim, para a previsão, chame o método GET_DRIVERS.
// Performing prediction using GET_DRIVERS method
CALL my_insights_model!GET_DRIVERS(
INPUT_DATA => TABLE(input_view),
LABEL_COLNAME => 'label',
METRIC_COLNAME => 'metric'
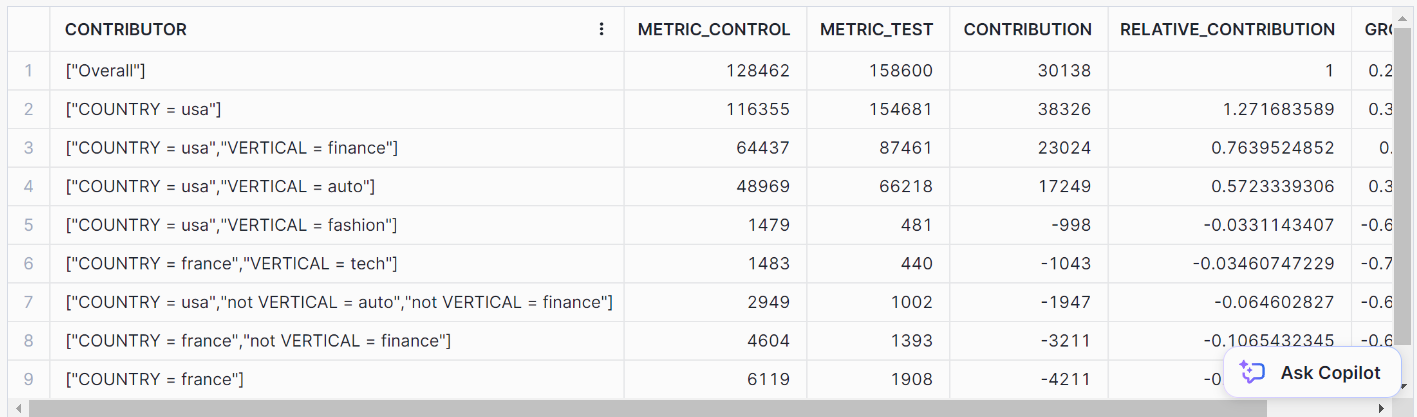
);Isso deve fornecer a você os seguintes resultados:
A previsão é crucial quando você precisa prever valores futuros com base em dados históricos. Seja na previsão de vendas, no consumo de energia ou no tráfego da Web, as funções integradas do Snowflake tornam essas tarefas muito mais simples.
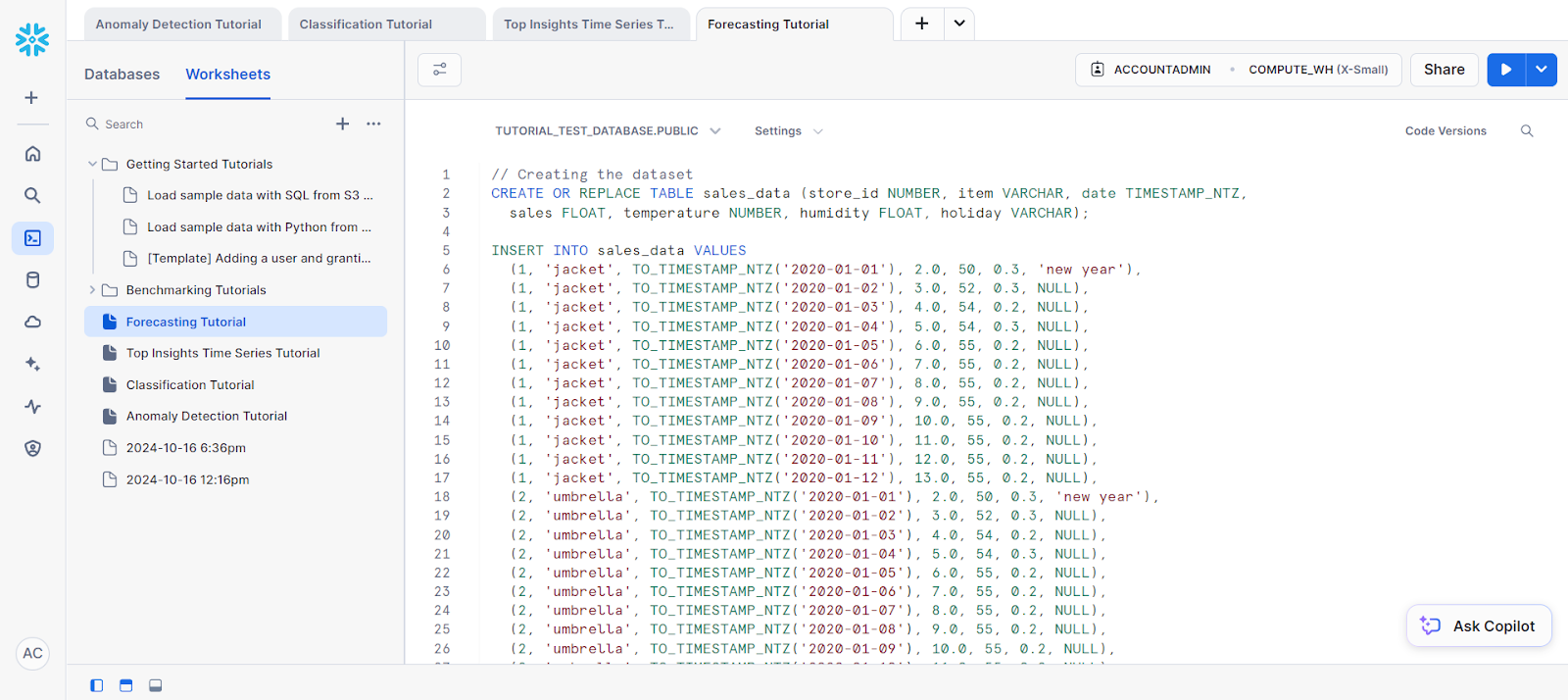
Para o nosso exemplo, vamos fazer uma previsão em uma única série:
// Creating the dataset
CREATE OR REPLACE TABLE sales_data (store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ,
sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO sales_data VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 50, 0.3, 'new year'),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-03'), 4.0, 54, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-04'), 5.0, 54, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-05'), 6.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-06'), 7.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-07'), 8.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-08'), 9.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-09'), 10.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-10'), 11.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-11'), 12.0, 55, 0.2, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-12'), 13.0, 55, 0.2, NULL);
-- Future values for additional columns (features)
CREATE OR REPLACE TABLE future_features (store_id NUMBER, item VARCHAR,
date TIMESTAMP_NTZ, temperature NUMBER, humidity FLOAT, holiday VARCHAR);
INSERT INTO future_features VALUES
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(1, 'jacket', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-13'), 52, 0.3, NULL),
(2, 'umbrella', TO_TIMESTAMP_NTZ('2020-01-14'), 53, 0.3, NULL);Em seguida, vamos separar os dados de treinamento do conjunto de dados.
// Creating a view for training data
CREATE OR REPLACE VIEW v1 AS SELECT date, sales
FROM sales_data WHERE store_id=1 AND item='jacket';
SELECT * FROM v1;Antes de iniciar a previsão, você precisará treinar o modelo com base nos dados de treinamento que selecionou.
Veja como você pode fazer isso:
// Training a forecasting model
CREATE SNOWFLAKE.ML.FORECAST model1(
INPUT_DATA => TABLE(v1),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales'
);Por fim, para a previsão, você pode chamar o método FORECAST para realizar a etapa de previsão.
// Performing the forecast by calling the FORECAST method
call model1!FORECAST(FORECASTING_PERIODS => 5);Esse é o resultado de nossa previsão.
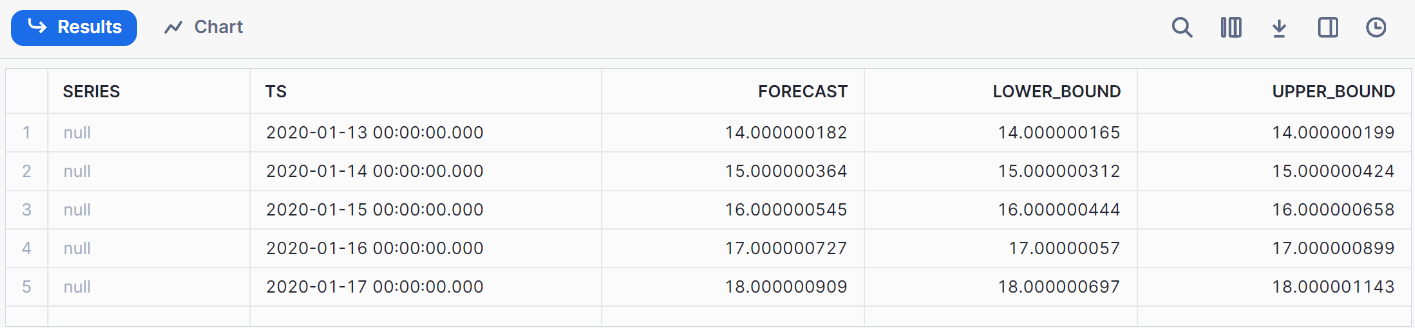
Você pode monitorar o desempenho do modelo criando painéis no Snowflake usando integrações de terceiros (como o Tableau) ou consultando os registros do Snowflake. Algumas métricas úteis, como exatidão, precisão e recuperação, podem ser usadas para rastrear modelos.
O Snowflake Cortex AI simplifica o aprendizado de máquina, permitindo a integração perfeita de modelos da plataforma Snowflake. Este tutorial orientou você no uso das funções do Snowflake Cortex AI e do Snowflake Cortex ML.
Essa solução aproveita a escalabilidade do Snowflake e a flexibilidade do Python, tornando-a ideal para organizações que desejam implementar o aprendizado de máquina sem mover os dados para fora da nuvem.
Você está procurando mais recursos sobre o Snowflake? Você vai gostar do nosso Tutorial para iniciantes sobre flocos de neve e do nosso Guia do Snowpark. Se você estiver procurando por algo mais abrangente, então o Introdução ao Snowflake pode ser o curso certo para você.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
5 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Thushan Ganegedara

