
Cursus
Fondations Snowflake
7 h
Les tableaux dynamiques de Snowflake constituent un outil puissant dans la boîte à outils d'un ingénieur de données. Il s'agit essentiellement de processus de rafraîchissement automatisés qui utilisent des requêtes de transformation sur des tables de base pour générer de nouveaux tableaux.
Les tableaux dynamiques simplifient les pipelines d'orchestration des données lorsque la fraîcheur des données est importante et que des transformations SQL complexes sont nécessaires. Ils utilisent un timing basé sur le décalage pour actualiser les tableaux en fonction des modifications apportées aux tableaux de base.
De récentes améliorations ont renforcé leurs capacités, permettant une propagation des données en temps quasi réel et une intégration plus poussée au sein de l'écosystème Snowflake (rafraîchissez vos connaissances avec ce cours d'introduction). cours d'introduction).
Ce guide explique le fonctionnement des tableaux dynamiques, comment les mettre en œuvre efficacement, et comment surveiller et optimiser leurs performances. À la fin, vous serez en mesure d'évaluer et de tester ces implémentations afin de déterminer si elles répondent aux besoins de votre organisation en matière de données.
Les tableaux dynamiques sont une classe entièrement gérée d'objets de base de données Snowflake qui permettent de rationaliser et d'automatiser les pipelines de données.
Au lieu d'utiliser des outils d'orchestration externes ou d'essayer de synchroniser les actualisations manuelles avec les mises à jour des tableaux sources, les tableaux dynamiques se mettent automatiquement à jour en fonction des modifications apportées aux données sources et des objectifs de fraîcheur définis. Cela permet aux professionnels des données de créer des transformations de données flexibles et de les mettre à jour selon les besoins lorsque les données changent.
Contrairement aux vues qui nécessitent que l'utilisateur calcule le tableau lors de la requête, les tableaux dynamiques restent calculés, ce qui améliore la vitesse des requêtes. De même, alors que les vues matérialisées offrent le même type de données mises en cache, les tableaux dynamiques peuvent utiliser des éléments tels que les jointures, les unions et les vues imbriquées, ce qui n'est pas possible avec les vues matérialisées.
Initialement introduit pour combler le fossé entre les pipelines traditionnels de l'ELT et les programmes de formation en ligne, pipelines ELT et les architectures événementielles, les tableaux dynamiques représentent le développement continu de Snowflake en matière de traitement déclaratif et sensible aux dépendances des données.
Il vous suffit d'écrire la requête SQL SELECT qui définit votre tableau dynamique avec une fréquence d'actualisation définie ( TARGET_LAG ) qui détermine la fréquence d'actualisation.
Par exemple, une « TARGET_LAG » de cinq minutes signifie que le tableau dynamique n'est pas en retard de plus de cinq minutes par rapport au tableau de base. Le plus intéressant est que tout cela est géré par le moteur de rafraîchissement interne de Snowflake, ce qui nous évite de concevoir des pipelines complexes.
Afin de mettre en œuvre efficacement les tableaux dynamiques, nous allons examiner certaines des implémentations techniques sous-jacentes de Snowflake afin de comprendre leurs forces et leurs faiblesses.
Tout comme les vues matérialisées, les tableaux dynamiques offrent un comportement d'actualisation des données persistant et automatisé. Cependant, contrairement aux vues matérialisées, elles permettent des transformations plus complexes en autorisant des opérations telles que les unions et les jointures.
Cela permet de créer plusieurs tableaux dynamiques plus petits qui peuvent ensuite alimenter des tableaux dynamiques plus grands.
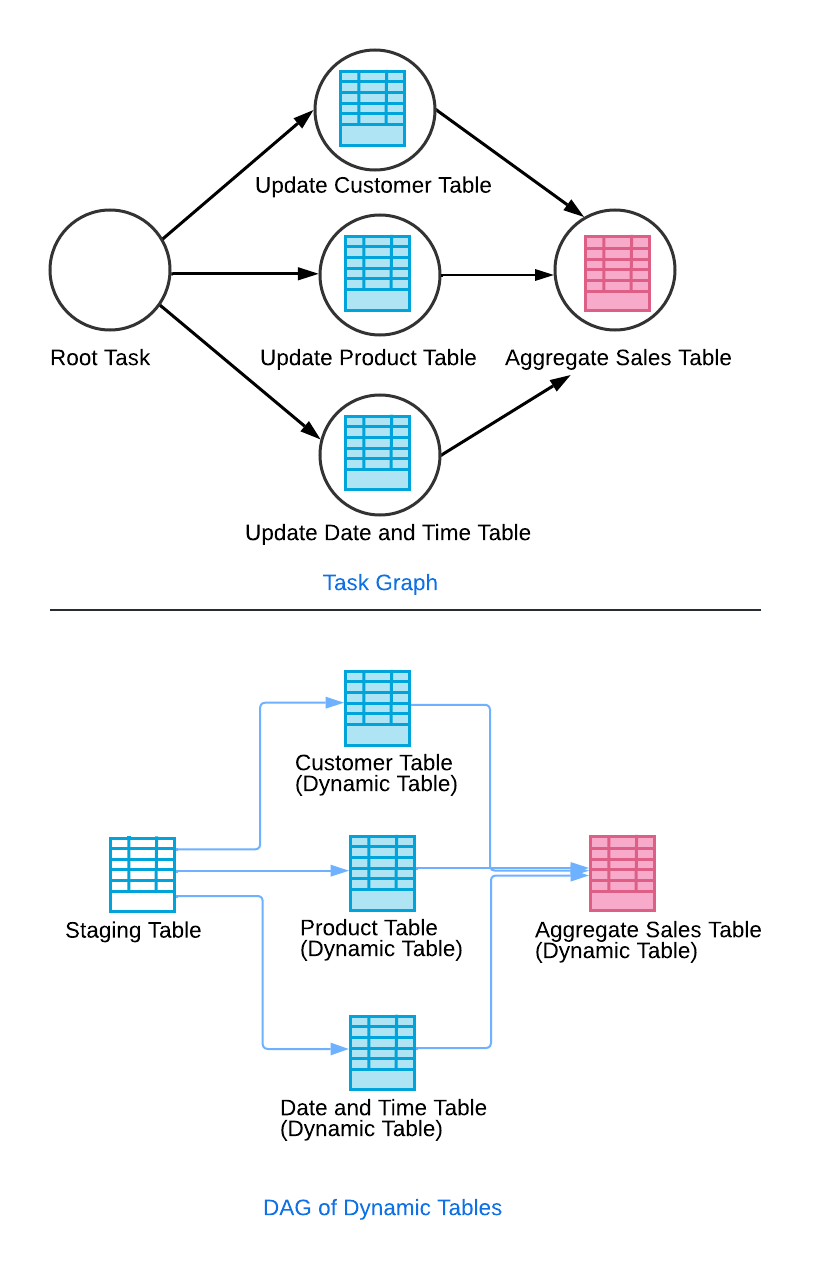
L'une des innovations majeures de Snowflake réside dans l'utilisation d'un graphe de dépendances automatisé. Vous pouvez créer un tableau agrégé dynamique qui se met à jour lorsque les tableaux de base sont mis à jour, ou vous pouvez créer des couches de tableaux dynamiques à l'aide de graphes acycliques dirigés. Cela fonctionne en mettant à jour un tableau de préparation de base, qui déclenche la mise à jour d'un tableau dynamique en aval.
Une fois ces tableaux dynamiques intermédiaires mis à jour, le tableau dynamique agrégé final est mis à jour. Tout cela fonctionne grâce aux workers de rafraîchissement de Snowflake, qui recherchent les mises à jour des données et s'assurent que les tableaux sources sont actualisés avec les dernières données disponibles.
Extrait de la documentation Snowflake sur la création de tableaux dynamiques
Les principaux mécanismes que vous pouvez contrôler lors de la création de tableaux dynamiques sont les modes d'actualisation, le décalage et les paramètres d'entrepôt. Les tableaux dynamiques prennent en charge deux modes d'actualisation :
Vous pouvez définir manuellement le mode de rafraîchissement ou utiliser l'REFRESH_MODE = AUTO lors de la création initiale du tableau dynamique. Veuillez noter que lorsque vous utilisez AUTO, le mode de rafraîchissement est défini lors de la création et n'est pas mis à jour. Si Snowflake détermine que l'actualisation incrémentielle est inefficace, il choisira alors de procéder à une actualisation complète.
Le paramètre « WAREHOUSE » (Emplacement du magasin de ressources) détermine l'entrepôt qui sera utilisé pour les ressources informatiques. Veuillez vous assurer de sélectionner celui qui correspond le mieux à vos besoins en matière de calcul et de stockage de données.
Le concept le plus important est peut-être celui de décalage. La méthode la plus courante pour déterminer le décalage consiste à utiliser l'TARGET_LAG, qui définit le délai acceptable entre les données source et les tableaux dynamiques. TARGET_LAG = DOWNSTREAMSi vous travaillez avec un pipeline plus complexe où d'autres tableaux dynamiques dépendent d'autres tableaux dynamiques, vous pouvez choisir de définir l'option « Ignorer les tableaux dynamiques » dans le menu contextuel de la table.
En définissant l'TARGET_LAG, sur DOWNSTREAM, il examine les tableaux dynamiques en aval qui dépendent du tableau dynamique actuel pour la synchronisation.
|
Concept source |
Fonctionnalité héritée dans les tableaux dynamiques |
Comment les tableaux dynamiques améliorent cela |
|
Tableaux traditionnels |
Stockage persistant ; réutilisabilité en aval |
Mise à jour et maintenance automatiques ; aucun chargement manuel de données ni déclencheur requis. |
|
Vues |
Logique SQL déclarative ; aucun code procédural n'est nécessaire. |
Sortie matérialisée pour de meilleures performances ; fraîcheur gérée via TARGET_LAG |
|
Vues matérialisées |
Actualisation automatique ; gestion de l'état |
Prend en charge les transformations complexes ; suivi intégré des dépendances à toutes les étapes |
Chaque tableau dynamique contribue à un DAG, ce qui permet à Snowflake de coordonner les actualisations sur plusieurs tableaux. Cela garantit l'exactitude et l'efficacité, en particulier dans les pipelines à plusieurs étapes.
Snowsight fournit une interface visuelle permettant d'explorer ce DAG, en affichant les dépendances, les temps de rafraîchissement et les mesures de latence. Il s'agit d'un avantage majeur pour le débogage et l'analyse d'impact. Veuillez lire cet article sur les les pipelines de données Snowflake pour plus d'informations sur le fonctionnement de l'architecture Snowflake.
Explorons maintenant quelques-unes des autres fonctionnalités clés des tableaux dynamiques et leurs avantages.
Les tableaux dynamiques éliminent le besoin d'orchestration externe (par exemple, Airflow ou dbt Cloud) en gérant le suivi des dépendances et la logique d'actualisation de manière native dans Snowflake.
Cela présente plusieurs avantages, notamment :
Toutes ces caractéristiques permettent aux tableaux dynamiques d'exceller dans les situations où des données actualisées et en temps quasi réel sont nécessaires. Pensez à des éléments tels que les tableaux de bord en temps réel et les flux de travail CDC. De plus, vous pouvez enchaîner plusieurs tableaux dynamiques dans un ordre précis pour effectuer des transformations en plusieurs étapes.
Au lieu de définir des délais de rafraîchissement manuels à l'aide de tâches CRON, les tableaux dynamiques utilisent l'TARGET_LAG pour vérifier les tableaux sources. Pour les tableaux de données en temps réel, cela signifie que dès que le tableau dynamique n'est plus synchronisé en raison du décalage désigné, il se met automatiquement à jour.
Bien qu'ils soient très similaires, les tableaux dynamiques sont souvent utilisés comme alternative aux flux et aux vues matérialisées. Les vues matérialisées sont idéales si vous avez besoin que les données soient toujours à jour et que vous utilisez une logique simple sur un tableau de base unique.
Les flux sont parfaits pour implémenter manuellement la CDC et pour comprendre comment les données évoluent au fil du temps. Les tableaux dynamiques sont parfaits lorsque vous souhaitez mettre en œuvre de manière simple des mises à jour régulières de requêtes de transformation de données complexes.
Pour plus d'informations sur la manière de structurer les données dans Snowflake, veuillez consulter ce cours sur la modélisation des données dans Snowflake est une excellente ressource.
Voyons comment configurer des tableaux dynamiques à l'aide de modèles de syntaxe et des meilleures pratiques. Il est relativement facile de les mettre en place, mais une compréhension approfondie des paramètres vous permettra de tirer le meilleur parti de vos tableaux dynamiques.
Voici un exemple de code illustrant comment créer un tableau dynamique à partir de notre tableau d'raw_sales. Veuillez examiner cela et nous vous expliquerons tout en détail par la suite.
# Your Dynamic Table parameters
CREATE OR REPLACE Dynamic Table sales_agg
TARGET_LAG = '5 minutes'
WAREHOUSE = 'prod_wh'
REFRESH_MODE = auto
INITIALIZE = on_create
AS
# Your SQL query for the table itself
SELECT
store_id,
SUM(amount) AS total_sales,
COUNT(*) AS sale_count
FROM raw_sales
GROUP BY store_id;La seconde moitié devrait être assez simple ; il s'agit de notre déclaration d'SELECT, qui définit les données du tableau. La première moitié avant la déclaration d'SELECT s correspond à l'ensemble de nos paramètres de création :
TARGET_LAG: Spécifie les exigences en matière de fraîcheur comme expliqué ci-dessus. Vous pouvez définir ici une période ou saisir « EN AVAL » si un autre tableau dynamique utilise ces données.WAREHOUSE: Détermine les ressources informatiques. Veuillez vous assurer de sélectionner le bon entrepôt Snowflake afin de disposer de ressources suffisantes pour générer le tableau de manière rentable.REFRESH_MODE: Peut être explicitement défini sur INCREMENTAL ou FULL. J'ai sélectionné « Déterminer la méthode optimale » ( AUTO ) pour permettre à Snowflake de déterminer la méthode optimale.INITIALIZE: Détermine quand le tableau est initialisé. L'ON_CREATE, le tableau est initialisé immédiatement. En le définissant sur « ON_SCHEDULE », le tableau sera initialisé une fois la première période de décalage atteinte.Veuillez noter que Snowflake nécessite le suivi des modifications pour prendre correctement en charge les actualisations incrémentielles, ce qui signifie qu'elles sont automatiquement activées pour les tableaux dynamiques incrémentiels.
Si vous souhaitez vérifier manuellement, vous pouvez utiliser la commande ALTER TABLE. L'activation du suivi des modifications permet également de remonter dans le temps si nous avons besoin de restaurer des versions antérieures des tableaux.
Il existe deux nuances à l'utilisation des tableaux dynamiques : leur clonage et leur connexion aux tableaux Snowflake Iceberg, qui sont construits sur des tables externes. tables Apache Iceberg tableaux.
Pour les tables Iceberg, rien ne change lors de l'installation. Le principal avantage des tableaux dynamiques basés sur les tableaux Snowflake Iceberg réside dans le fait qu'ils vous permettent de continuer à traiter les données externes sans ingestion continue ni duplication des données.
Le clonage est possible grâce à la fonctionnalité « voyage dans le temps » de Snowflake, et nous pouvons copier une version plus ancienne de notre tableau dynamique à l'aide de la commande « CLONE » comme suit :
CREATE Dynamic Table clone_sales_agg
CLONE sales_agg
AT (OFFSET => -24*60*60) –-24 hours ago
TARGET_LAG = DOWNSTREAM
WAREHOUSE = sales_whIl convient toutefois de noter que les tableaux clonés peuvent ne pas partager toutes les métadonnées du tableau source et qu'ils occupent un espace de stockage supplémentaire. Soyez prudent lorsque vous clonez et assurez-vous que cela est nécessaire.
Il est recommandé de s'entraîner à configurer des tableaux dynamiques afin de tester leur fonctionnalité. Voici un guide général sur la manière de tester les tableaux dynamiques :
raw_sales s simple avec des horodatages.TARGET_LAG = '1 minute' pour observer les actualisations en action.Vous pouvez créer un flux qui examine un compartiment S3 dans lequel vous pouvez télécharger régulièrement des données. À mesure que ces données changent, vous pouvez voir comment votre tableau dynamique se met à jour. Veuillez suivre ce tutoriel pour découvrir des méthodes simples de configuration de l'ingestion de données Snowflake. l'ingestion de données Snowflake, puis consulter ce tutoriel pour plus d'informations sur la création de tableaux dans Snowflake.
Snowflake fournit plusieurs outils pour vous aider à surveiller et gérer efficacement les tableaux dynamiques, tels que Snowsight ou les requêtes. Veuillez vous assurer que vous disposez des privilèges de surveillance sur votre compte pour afficher ces informations.
L'utilisation de Snowsight pour surveiller les tableaux dynamiques est simple :
Snowsight peut fournir des informations très utiles, telles que la manière dont le tableau dynamique a été créé, le DAG, l'historique des actualisations et les métriques.
Pour effectuer la même opération avec SQL, nous utiliserions la commande « SHOW DYNAMIC TABLES ».
Par exemple, si je souhaite consulter tous mes tableaux dynamiques liés aux ventes :
SHOW Dynamic Tables LIKE ‘sales_%' IN SCHEMA mydb.myschema;Cela fournit des informations telles que la date de création du tableau, sa taille, son retard cible et son dernier état.
Il se peut que vous souhaitiez modifier ou suspendre votre tableau dynamique. Heureusement, Snowflake vous facilite la tâche.
Pour suspendre votre tableau, nous utilisons ALTER DYNAMIC TABLE et SUSPEND:
ALTER Dynamic Table sales_agg SUSPEND;Pour résumer, nous procédons de la même manière, mais avec l'RESUME:
ALTER Dynamic Table sales_agg RESUME;Pour modifier les paramètres, nous pouvons également utiliser la ligne « ALTER DYNAMIC TABLE » et « SET » le paramètre spécifique que nous souhaitons modifier :
ALTER Dynamic Table sales_agg SET TARGET_LAG = '10 minutes';La meilleure façon de gérer les dépendances et de minimiser les interruptions opérationnelles est de vous assurer que vous ne suspendez pas les tableaux critiques. Si vous envisagez de modifier le délai, assurez-vous de bien comprendre l'impact que cela pourrait avoir sur le timing des tableaux en aval.
Nous avons appris que les tableaux dynamiques sont très utiles, mais ils présentent encore quelques limites et considérations.
Il existe certaines restrictions concernant les types de comptes et de sources. Les contraintes actuelles sont les suivantes :
ACCESS_HISTORY.D'autres éléments à prendre en considération sont le clonage, le voyage dans le temps et le contrôle d'accès. Le voyage dans le temps est peut-être le plus simple, car il nécessite une valeur minimale d'un jour. Il n'est pas possible de désactiver le voyage dans le temps en réglant l'DATA_RETENTION_TIME_IN_DAYS sur 0.
Lorsque vous clonez un tableau dynamique, veuillez noter que toutes les métadonnées ne sont pas enregistrées. De plus, vous ne pouvez pas cloner les tableaux dynamiques Iceberg. Si vous clonez un tableau dynamique qui dépend d'un tableau dynamique Iceberg, ce tableau dynamique Iceberg n'est pas déplacé vers le nouvel emplacement.
La création et l'utilisation de tableaux dynamiques nécessitent les rôles d'accès CREATE DYNAMIC TABLE, SELECT et USAGE pour la base de données et le schéma parents.
Si vous vous souvenez de ces contraintes, vous devriez avoir moins de difficultés avec les tableaux dynamiques.
En raison de leur méthodologie de mise en œuvre simple, il est facile de surcharger le système. Une erreur courante consiste à traiter les tableaux dynamiques comme un pipeline de données en temps réel. Ils ne sont pas destinés à remplacer les sources de données en temps réel ; il convient plutôt de tenir compte des exigences en matière de timing et d'actualité des données. Par exemple, nous pouvons suivre ces bonnes pratiques :
REFRESH_MODE = incremental lorsque cela est possible afin de ne pas avoir à recréer l'intégralité du tableau dynamique à chaque chargement.TARGET_LAG afin d'équilibrer les coûts et les besoins des parties prenantes en matière de fraîcheur des données.WAREHOUSE » de taille appropriée afin d'optimiser les ressources informatiques utilisées.SELECT imbriquées.En suivant ces conseils simples, vous contribuerez au bon fonctionnement de vos tableaux dynamiques. Une utilisation judicieuse peut réellement simplifier vos pipelines de données critiques à moindre coût, mais une utilisation imprudente peut créer davantage de problèmes à l'avenir.
Comme nous l'avons mentionné, l'utilisation de tableaux dynamiques implique des coûts de stockage et de calcul. Nous pouvons vous présenter quelques stratégies pour comprendre ces coûts et comment les gérer dans Snowflake.
Le coût lié à l'utilisation de tableaux dynamiques comprend deux éléments principaux : le stockage et le calcul. Chacun d'entre eux comporte plusieurs éléments, nous allons donc les examiner en détail.
En ce qui concerne les coûts de stockage, vous serez facturé pour le stockage des résultats matérialisés de chaque tableau dynamique. Il existe également des coûts supplémentaires pour des services tels que le voyage dans le temps, le stockage sécurisé et le clonage.
La seule exception concerne les tableaux dynamiques de type iceberg, pour lesquels vous n'aurez aucun coût de stockage Snowflake, car ils sont stockés en externe. Vous pouvez limiter ces coûts en réduisant autant que possible la taille de votre tableau dynamique ou en minimisant le nombre de clonages et les déplacements temporels.
Les coûts informatiques se divisent en deux grandes catégories : l'entrepôt virtuel et les services informatiques Cloud. Les entrepôts virtuels deviendront les ressources que vous utiliserez pour initialiser et actualiser vos tableaux ; pensez aux coûts associés à l'exécution de la requête.
Les services cloud sont davantage axés sur l'automatisation offerte par Snowflake. Il s'agit notamment d'identifier les modifications apportées aux objets de base sous-jacents et de maintenir les DAG. Pensez à tout le travail en arrière-plan effectué par Snowflake pour assurer le bon fonctionnement de vos tableaux dynamiques.
Cette fonction dépend du décalage défini pour votre tableau, et le coût est directement associé à la fréquence définie.
Pour obtenir un aperçu complet de la composition de ces coûts, veuillez consulter la documentation sur les coûts de Snowflake. documentation relative aux coûts de Snowflake, qui détaille les différents éléments.
Snowflake facilite le suivi de ces coûts grâce à Snowsight. Refresh History Vous pouvez vous rendre dans Surveillance, puis Tableaux dynamiques comme d'habitude. Sous la page du tableau dynamique, vous trouverez un onglet Crédits de l'entrepôt qui vous indiquera les crédits utilisés.
Si vous souhaitez obtenir des informations plus détaillées sur l'utilisation de votre compte, vous pouvez également utiliser la requête suivante :
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.METERING_HISTORY;Cela affichera les coûts engagés par les différents services sur le compte et pourra être lié à vos tableaux dynamiques.
De plus, je vous recommande d'effectuer des tests sur un entrepôt dédié afin de bien comprendre les coûts d'entreposage associés au tableau dynamique. Une fois que vous avez une idée du coût, vous pouvez les transférer vers vos entrepôts partagés.
Si vous souhaitez réduire vos coûts, envisagez d'utiliser des fonctionnalités telles que la suspension automatique. Les tableaux dynamiques suspendus sont uniquement facturés pour le stockage et non pour les ressources de rafraîchissement.
Vous pouvez également utiliser des tableaux dynamiques transitoires qui n'ont pas de coûts de stockage à sécurité intégrée. De plus, en optimisant la fréquence de votre requête TARGET_LAG et en utilisant la mise à jour incrémentielle lorsque cela est possible, vous pouvez réduire considérablement vos coûts informatiques.
Comme toujours, l'écriture de code SQL de qualité et l'optimisation des transformations constituent également un excellent moyen de réduire l'utilisation des ressources informatiques.
Les tableaux dynamiques peuvent être utilisés partout où vous souhaitez remplacer un pipeline ETL complexe et fastidieux basé sur le temps par un pipeline simplifié, basé sur le décalage et autogéré.
Voici quelques cas d'utilisation qui pourraient être utiles pour votre secteur d'activité.
Pour les organisations financières, il peut être utile de procéder à des actualisations périodiques des données transactionnelles, par exemple pour la détection des fraudes ou les rétrofacturations.
TARGET_LAG Étant donné que nous n'avons pas besoin de données actualisées à la seconde près, nous pourrions opter pour une fréquence de collecte de données de 10 minutes pour les tableaux de bord généraux sur l'état du système. Vous disposez peut-être d'un modèle de science des données qui enregistre toutes les alertes de fraude dans un tableau et d'un système tiers de surveillance des rétrofacturation qui les enregistre dans un autre tableau.
Vous pouvez regrouper ces deux éléments dans un tableau agrégé en toute simplicité, sans avoir recours à des DAG Airflow complexes. Cela devrait simplifier et améliorer les performances des requêtes.
Dans le domaine de l'analyse commerciale, nous sommes peut-être intéressés par les performances des différentes régions. Il est possible que chaque région dispose de sa propre base de données centrale qui transmet les données périodiquement, mais avec un léger décalage. Au lieu de créer des pipelines ETL dont le timing doit être adapté à chaque base de données, nous pouvons créer un tableau dynamique qui agrège toutes ces données selon les besoins, en fonction des décalages de chaque tableau. Cela réduit la complexité du pipeline et minimise le besoin d'une maintenance constante.
D'autres scénarios pourraient inclure :
Les tableaux dynamiques Snowflake constituent un outil remarquable pour simplifier les pipelines ETL complexes basés sur le temps. Ils offrent un équilibre raffiné entre automatisation, flexibilité et performance. Il suffit de garder à l'esprit certaines bonnes pratiques, telles que tester avec des pipelines non critiques pour comprendre le comportement de rafraîchissement des données, surveiller vos indicateurs de retard et de coût, et évaluer les DAG visuels pour comprendre les dépendances.
Les tableaux dynamiques ne remplacent pas complètement les flux et les tâches dans tous les cas, mais ils constituent une nouvelle option robuste qui réduit le code et optimise l'efficacité. Utilisez-les judicieusement, et vous vous simplifierez considérablement la vie. Pour plus d'informations sur Snowflake et quelques rappels sur le langage SQL, veuillez consulter les ressources suivantes :
Meilleurs cours Snowflake
Cursus
Cours
Cours