
Programa
Fundações para Snowflake
7 h
As tabelas dinâmicas do Snowflake são uma ferramenta poderosa no conjunto de ferramentas de um engenheiro de dados. Eles são basicamente processos de atualização automáticos que usam consultas de transformação em tabelas base para criar novas tabelas.
As tabelas dinâmicas simplificam os pipelines de orquestração de dados onde a atualização dos dados é importante e são necessárias transformações complexas baseadas em SQL. Eles usam um tempo baseado em atraso para atualizar as tabelas com base nas alterações nas tabelas base.
As melhorias recentes reforçaram suas capacidades, permitindo a propagação de dados quase em tempo real e uma integração mais profunda com o ecossistema da Snowflake (refresque sua memória com este curso introdutório).
Este guia mostra como funcionam as Tabelas Dinâmicas, como implementá-las de forma eficaz e como monitorar e otimizar o desempenho. No final, você vai estar pronto pra avaliar e testar essas implementações pra ver se elas atendem às necessidades de dados da sua organização.
As tabelas dinâmicas são uma classe totalmente gerenciada de objetos de banco de dados Snowflake que ajudam a simplificar e automatizar os pipelines de dados.
Em vez de usar ferramentas de orquestração externas ou tentar sincronizar atualizações manuais com as atualizações da tabela de origem, as Tabelas Dinâmicas são atualizadas automaticamente com base nas alterações dos dados de origem e nas metas de atualização definidas. Isso permite que os profissionais de dados criem transformações de dados flexíveis e atualizem conforme necessário quando os dados mudam.
Diferente das visualizações, que exigem que o usuário calcule a tabela quando ela é consultada, as Tabelas Dinâmicas permanecem calculadas, o que melhora a velocidade das consultas. Da mesma forma, enquanto as visualizações materializadas oferecem o mesmo tipo de dados em cache, as Tabelas Dinâmicas podem usar coisas como junções, uniões e visualizações aninhadas que as visualizações materializadas não conseguem.
Originalmente criado pra preencher a lacuna entre os canais tradicionais de ELT e os canais de ELT pipelines ELT e as arquiteturas orientadas a eventos, as tabelas dinâmicas representam o desenvolvimento contínuo da Snowflake para o processamento de dados declarativo e sensível a dependências.
Tudo o que você precisa fazer é escrever a consulta SQL SELECT que define sua tabela dinâmica com um TARGET_LAG definido que determina a frequência de atualização.
Por exemplo, um “ TARGET_LAG ” de cinco minutos quer dizer que a tabela dinâmica não está mais do que cinco minutos atrás da tabela base. A melhor parte é que tudo isso é gerenciado pelo mecanismo de atualização interno da Snowflake, o que nos poupa de ter que projetar pipelines complexos!
Para implementar tabelas dinâmicas de forma eficaz, vamos analisar algumas das implementações técnicas subjacentes do Snowflake para entender seus pontos fortes e fracos.
Assim como as visualizações materializadas, as tabelas dinâmicas oferecem um comportamento de atualização de dados persistente e automatizado. Mas, diferente das visualizações materializadas, elas permitem transformações mais complexas, como uniões e junções.
Isso permite a criação de várias tabelas dinâmicas menores que podem ser usadas em tabelas dinâmicas maiores.
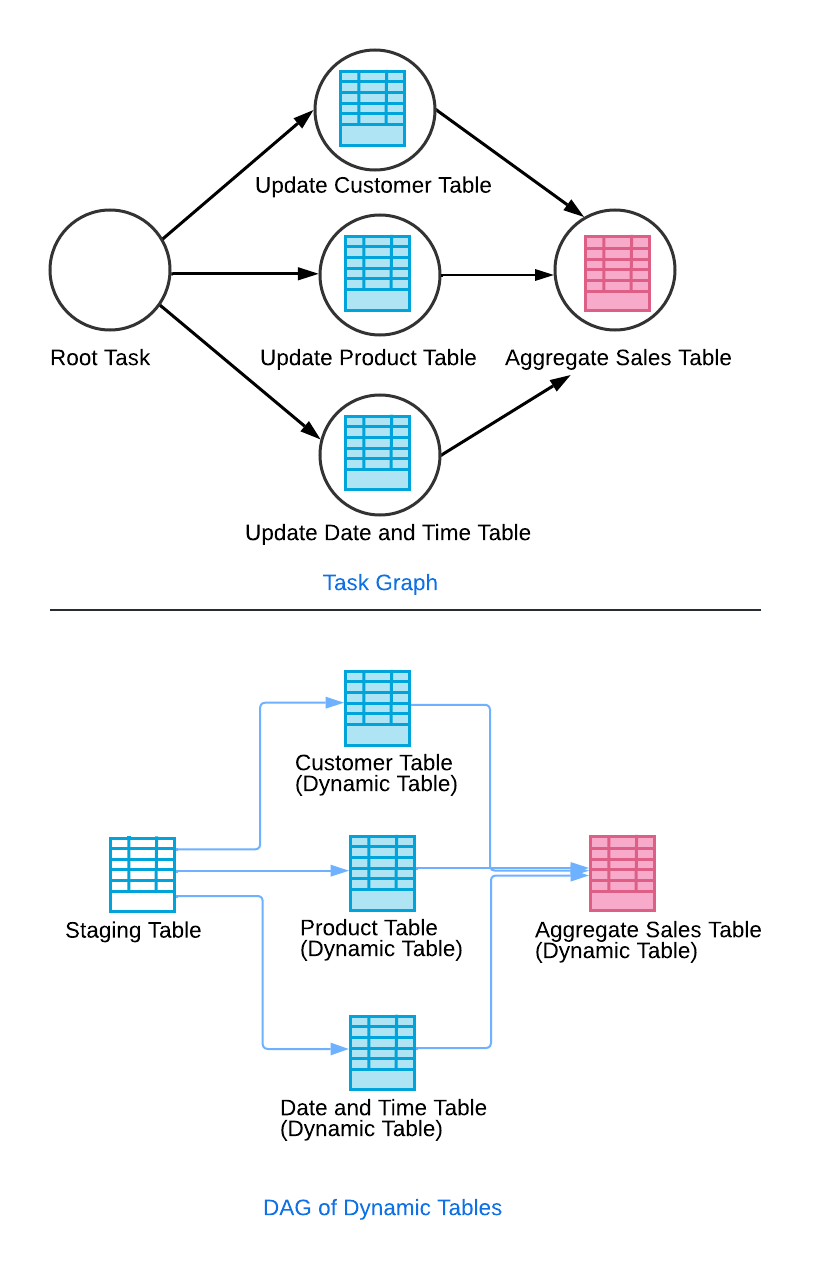
Uma inovação importante é o uso de um gráfico de dependências automatizado pelo Snowflake. Você pode criar uma tabela agregada dinâmica que atualiza conforme as tabelas base são atualizadas ou pode construir camadas de Tabelas Dinâmicas usando gráficos acíclicos direcionados. Isso funciona atualizando uma tabela de preparação base, que aciona a atualização de uma tabela dinâmica a jusante.
Depois que essas tabelas dinâmicas intermediárias forem atualizadas, a tabela dinâmica agregada final será atualizada. Tudo isso funciona com os workers de atualização do Snowflake, que procuram atualizações de dados e garantem que as tabelas de origem sejam atualizadas com os dados mais recentes.
Da documentação do Snowflake sobre como criar tabelas dinâmicas
Os principais mecanismos que você pode controlar ao criar tabelas dinâmicas são os modos de atualização, o atraso e os parâmetros do warehouse durante a criação. As tabelas dinâmicas têm dois modos de atualização:
Você pode definir manualmente o modo de atualização ou usar a opção “ REFRESH_MODE = AUTO ” na criação inicial da tabela dinâmica. Só fica ligado que, quando você usa AUTO, ele define o modo de atualização na hora que é criado e não é atualizado. Se o Snowflake achar que a atualização incremental não é eficiente, ele vai optar por fazer uma atualização completa.
A configuração “ WAREHOUSE ” escolhe o warehouse que vai ser usado para os recursos de computação. Escolha o que melhor se adapta às suas necessidades de computação e armazenamento de dados.
Talvez o conceito mais importante seja o atraso. A maneira mais comum de determinar o atraso é usar um TARGET_LAG, que define o atraso aceitável entre os dados de origem e as tabelas dinâmicas. Se você estiver trabalhando com um pipeline um pouco mais complexo, em que outras tabelas dinâmicas dependem de outras tabelas dinâmicas, você pode optar por definir um TARGET_LAG = DOWNSTREAM.
Ao definir o parâmetro " TARGET_LAG " como " DOWNSTREAM ", ele procura as tabelas dinâmicas a jusante que dependem da tabela dinâmica atual para o tempo.
|
Conceito de origem |
Recurso herdado em tabelas dinâmicas |
Como as tabelas dinâmicas melhoram isso |
|
Tabelas tradicionais |
Armazenamento persistente; reutilização a jusante |
Mantido e atualizado automaticamente; sem necessidade de carregamento manual de dados ou acionadores |
|
Visualizações |
Lógica SQL declarativa; sem necessidade de código procedural |
Saída materializada para um desempenho melhor; atualização gerenciada por meio de TARGET_LAG |
|
Visualizações materializadas |
Atualização automática; gerenciamento de estado |
Suporta transformações complexas; rastreamento integrado de dependências entre etapas |
Cada tabela dinâmica contribui para um DAG, permitindo que o Snowflake coordene atualizações em várias tabelas. Isso garante que tudo funcione direitinho e com eficiência, principalmente em tubulações com várias etapas.
O Snowsight tem uma interface visual pra explorar esse DAG, mostrando dependências, tempos de atualização e métricas de atraso. Isso é uma grande vantagem pra depuração e análise de impacto. Não deixe de ler este artigo sobre pipelines de dados do Snowflake para saber mais sobre como funciona a arquitetura do Snowflake.
Vamos ver algumas das outras funcionalidades importantes das Tabelas Dinâmicas e suas vantagens.
As tabelas dinâmicas eliminam a necessidade de orquestração externa (por exemplo, Airflow ou dbt Cloud) ao lidar com o rastreamento de dependências e a lógica de atualização de forma nativa no Snowflake.
Isso traz várias vantagens, como:
Tudo isso faz com que as Tabelas Dinâmicas sejam ótimas pra quando a gente precisa de dados atualizados e quase em tempo real. Pense em coisas como painéis em tempo real e fluxos de trabalho CDC. Além disso, você pode encadear várias Tabelas Dinâmicas em sequência para transformações em várias etapas.
Em vez de definir prazos de atualização manual usando tarefas CRON, as Tabelas Dinâmicas usam TARGET_LAG para verificar as tabelas de origem. Para tabelas de dados em tempo real, isso quer dizer que, assim que a Tabela Dinâmica fica fora de sincronia pelo atraso designado, ela é atualizada automaticamente.
Embora sejam bem parecidas, as tabelas dinâmicas são frequentemente usadas como uma alternativa aos fluxos e às visualizações materializadas. As visualizações materializadas são ótimas se você precisa que os dados estejam sempre atualizados e estiver usando uma lógica simples em uma tabela base única.
Os fluxos são perfeitos pra implementar o CDC manualmente e entender como os dados mudam com o tempo. As tabelas dinâmicas são perfeitas quando você quer uma maneira simples de implementar atualizações regulares em consultas complexas de transformação de dados.
Para mais considerações sobre como estruturar dados no Snowflake, este curso sobre modelagem de dados no Snowflake é um excelente recurso.
Vamos ver como configurar tabelas dinâmicas usando padrões de sintaxe e as melhores práticas. Começar a usar isso é relativamente fácil, mas entender bem os parâmetros vai te ajudar a aproveitar ao máximo suas tabelas dinâmicas.
Aqui está um exemplo de código que mostra como podemos criar uma tabela dinâmica usando nossa tabela raw_sales como base. Dá uma olhada e vamos explicar tudo em detalhes a seguir.
# Your Dynamic Table parameters
CREATE OR REPLACE Dynamic Table sales_agg
TARGET_LAG = '5 minutes'
WAREHOUSE = 'prod_wh'
REFRESH_MODE = auto
INITIALIZE = on_create
AS
# Your SQL query for the table itself
SELECT
store_id,
SUM(amount) AS total_sales,
COUNT(*) AS sale_count
FROM raw_sales
GROUP BY store_id;A segunda metade deve ser bem simples; essa é a nossa declaração “ SELECT ”, que define os dados na tabela. A primeira metade antes da instrução SELECT são todos os nossos parâmetros de criação:
TARGET_LAG: Especifica os requisitos de frescor, como explicado acima. Você pode definir um período aqui ou escrever “DOWNSTREAM” se houver outra Tabela Dinâmica usando esses dados.WAREHOUSE: Define os recursos de computação. Certifique-se de selecionar o warehouse Snowflake certo para ter recursos suficientes para gerar a tabela de maneira econômica.REFRESH_MODE: Pode ser explicitamente definido como INCREMENTAL ou FULL. Eu escolhi “ AUTO ” (Deixar o Snowflake determinar o método ideal) para deixar o Snowflake decidir o melhor jeito de fazer isso.INITIALIZE: Diz quando a tabela é inicializada. Se você colocar “ ON_CREATE ”, a tabela é inicializada imediatamente. Definir como “ ON_SCHEDULE ” vai inicializar a tabela assim que o primeiro período de atraso for atingido.Lembre-se de que o Snowflake vai precisar do rastreamento de alterações para dar suporte às atualizações incrementais, o que significa que elas são ativadas automaticamente para tabelas dinâmicas incrementais!
Se você quiser conferir manualmente, dá uma olhada no comando “ ALTER TABLE ”. Ter o controle de alterações ativado também permite viajar no tempo caso precisemos restaurar versões históricas das tabelas.
Duas coisas diferentes nas Tabelas Dinâmicas são cloná-las e conectá-las às tabelas Snowflake Iceberg, que são feitas em tabelas externas. tabelas Apache Iceberg tabelas.
Para tabelas Iceberg, nada muda durante a configuração. A principal vantagem das tabelas dinâmicas criadas nas tabelas Snowflake Iceberg é que elas permitem continuar processando os dados externos sem precisar fazer a ingestão contínua ou duplicar os dados.
A clonagem é possível graças ao recurso de viagem no tempo do Snowflake, e podemos copiar uma versão mais antiga da nossa tabela dinâmica usando o comando “ CLONE ” da seguinte maneira:
CREATE Dynamic Table clone_sales_agg
CLONE sales_agg
AT (OFFSET => -24*60*60) –-24 hours ago
TARGET_LAG = DOWNSTREAM
WAREHOUSE = sales_whA ressalva aqui é que tabelas clonadas podem não compartilhar todos os metadados da tabela de origem e ocupam espaço de armazenamento extra. Tenha cuidado com a clonagem e certifique-se de que ela é necessária.
É uma boa ideia praticar a configuração de Tabelas Dinâmicas para testar a funcionalidade. Aqui vai um guia geral sobre como testar tabelas dinâmicas:
raw_sales ” com carimbos de data/hora.TARGET_LAG = '1 minute' para ver as atualizações em ação.Uma coisa que você pode fazer é criar um fluxo que olha para um bucket S3 onde você pode enviar dados de vez em quando. Conforme esses dados mudam, você pode ver como sua Tabela Dinâmica é atualizada. Você pode seguir este tutorial para ver maneiras simples de configurar a ingestão de dados do Snowflake. a ingestão de dados do Snowflake e, em seguida, consultar este tutorial para obter mais informações sobre como criar tabelas no Snowflake.
O Snowflake tem várias ferramentas pra te ajudar a monitorar e gerenciar tabelas dinâmicas de forma eficaz, como usar o Snowsight ou fazer consultas. Certifique-se de que você tem privilégios de monitoramento na sua conta para ver essas informações!
Usar o Snowsight para monitorar tabelas dinâmicas é simples:
O Snowsight pode fornecer informações importantes, como a forma como a tabela dinâmica foi criada, o DAG, o histórico de atualizações e as métricas.
Para fazer a mesma coisa com SQL, usaríamos o comando ` SHOW DYNAMIC TABLES `.
Por exemplo, se eu quiser ver todas as tabelas dinâmicas relacionadas a vendas:
SHOW Dynamic Tables LIKE ‘sales_%' IN SCHEMA mydb.myschema;Isso dá informações como quando a tabela foi criada, o tamanho dela, o atraso do destino e o status mais recente.
Provavelmente vai chegar um momento em que você vai querer modificar ou suspender sua tabela dinâmica. Felizmente, a Snowflake facilita tudo isso.
Para suspender sua tabela, usamos ALTER DYNAMIC TABLE e SUSPEND:
ALTER Dynamic Table sales_agg SUSPEND;Pra resumir, fazemos a mesma coisa, mas com RESUME:
ALTER Dynamic Table sales_agg RESUME;Para mudar os parâmetros, também dá pra usar a linha “ ALTER DYNAMIC TABLE ” e “ SET ” o parâmetro específico que a gente quer mudar:
ALTER Dynamic Table sales_agg SET TARGET_LAG = '10 minutes';A melhor maneira de gerenciar dependências e minimizar interrupções operacionais é garantir que você não esteja suspendendo tabelas críticas. Se você está pensando em mudar a quantidade de atraso, entenda como isso pode afetar o tempo das tabelas a jusante.
A gente aprendeu que as Tabelas Dinâmicas são super úteis, mas ainda têm algumas limitações e coisas pra prestar atenção.
Tem algumas limitações de conta e tipo de fonte. As limitações atuais incluem:
ACCESS_HISTORY ” (Rastreamento de auditoria do SQL Server).Outras coisas a considerar são clonagem, viagem no tempo e controle de acesso. A viagem no tempo pode ser a mais simples, já que precisa de só um dia. Não dá pra desligar a viagem no tempo colocando o parâmetro “ DATA_RETENTION_TIME_IN_DAYS ” em 0.
Quando você clona uma tabela dinâmica, lembre-se de que nem todos os metadados são salvos. Além disso, você não pode clonar tabelas dinâmicas do Iceberg. Se você clonar uma tabela dinâmica que depende de uma tabela dinâmica Iceberg, essa tabela dinâmica Iceberg não será realocada para o novo local.
Para criar e usar tabelas dinâmicas, você precisa das funções de acesso CREATE DYNAMIC TABLE, SELECT e USAGE para o banco de dados pai e o esquema.
Se você se lembrar dessas restrições, vai ter menos problemas com tabelas dinâmicas!
Graças à sua metodologia de implementação simples, pode ser fácil sobrecarregar o sistema. Um erro comum é tratar as Tabelas Dinâmicas como um canal de dados em tempo real. Elas não são pra substituir fontes de dados em tempo real; em vez disso, devemos pensar nos requisitos de tempo e atualização dos dados. Por exemplo, a gente pode seguir essas dicas:
REFRESH_MODE = incremental sempre que possível, para que não precisemos recriar toda a tabela dinâmica a cada carregamento.TARGET_LAG ” pra equilibrar o custo e a necessidade de atualização dos dados das pessoas envolvidas.WAREHOUSE adequado para otimizar os recursos de computação que estão sendo usados.SELECT ” aninhadas.Seguir essas dicas simples pode ajudar a manter suas tabelas dinâmicas funcionando perfeitamente. Usá-los com sabedoria pode realmente simplificar seus pipelines de dados críticos com um custo mínimo, mas usá-los de forma imprudente pode criar mais problemas no futuro!
Como falamos, tem custos de armazenamento e computação associados ao uso de tabelas dinâmicas. A gente pode mostrar algumas estratégias pra entender esses custos e como gerenciá-los no Snowflake.
Tem duas partes importantes no custo de usar tabelas dinâmicas: armazenamento e computação. Cada um deles tem algumas partes, então vamos dar uma olhada em cada uma delas.
Para os custos de armazenamento, você vai pagar pelo armazenamento dos resultados materializados de cada tabela dinâmica. Também tem custos extras pra coisas como viagem no tempo, armazenamento à prova de falhas e clonagem.
A única exceção são as tabelas dinâmicas iceberg, nas quais você não terá nenhum custo de armazenamento do Snowflake, pois elas são armazenadas externamente. Você pode reduzir esses custos tornando sua tabela dinâmica o mais enxuta possível ou minimizando a quantidade de clonagem e viagem no tempo.
Os custos de computação são divididos em duas partes principais: warehouse virtual e computação em nuvem. Os warehouses virtuais vão ser os recursos que você vai usar pra realmente inicializar e atualizar suas tabelas; pense nos custos associados à execução da consulta.
A computação dos Serviços em Nuvem tem mais a ver com a automação que a Snowflake oferece. Isso inclui identificar mudanças nos objetos base e manter os DAGs. Pensa em todo o trabalho que o Snowflake faz nos bastidores pra manter suas tabelas dinâmicas funcionando.
Isso depende do atraso da tabela que você definiu, e o custo está diretamente ligado à frequência definida.
Para ter uma visão geral de como esses custos se somam, confira a documentação de custos da Snowflake, que detalha os componentes.
A Snowflake facilita o monitoramento desses custos usando o Snowsight. Você pode ir para Monitoramento, depois Tabelas dinâmicas, como de costume, e na página da tabela dinâmica, tem uma aba Chamadas de tabela ( Refresh History ) que mostra os créditos do warehouse usados.
Se você quiser ver o uso mais amplo da sua conta, também pode usar a seguinte consulta:
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.METERING_HISTORY;Isso vai mostrar os custos que os diferentes serviços geraram na conta e pode ser conectado às suas tabelas dinâmicas.
Além disso, recomendo testar em um warehouse dedicado para que você possa entender completamente os custos de warehouse associados à tabela dinâmica. Depois de ter uma ideia do custo, você pode transferi-los para seus warehouses compartilhados.
Se você quer economizar, pense em usar coisas como a suspensão automática. As tabelas dinâmicas suspensas só são cobradas pelo armazenamento e não por recursos de atualização.
Você também pode usar Tabelas Dinâmicas transitórias, que não têm custos de armazenamento à prova de falhas. Além disso, se você otimizar seu TARGET_LAG para a frequência certa e usar a atualização incremental sempre que possível, poderá economizar bastante em custos de computação.
Como sempre, escrever um bom SQL e fazer transformações otimizadas também é uma ótima maneira de reduzir o uso de recursos de computação.
As tabelas dinâmicas podem ser usadas em qualquer lugar que você quiser substituir um pipeline ETL complicado e baseado em tempo por um pipeline simplificado, baseado em atrasos e autogerenciado.
Aqui estão alguns casos de uso de implantação que podem ser úteis para o seu setor específico.
Para empresas financeiras, pode ser legal atualizar de vez em quando os dados das transações, tipo detecção de fraudes ou estornos.
Como não precisamos de dados atualizados a cada segundo, podemos preferir um intervalo de 10 minutos entre os e TARGET_LAG es para painéis gerais de integridade do sistema. Talvez você tenha um modelo de ciência de dados que salva todos os alertas de fraude em uma tabela e um sistema de monitoramento de estornos de terceiros que salva em outra tabela.
Você pode juntar esses dois em uma tabela agregada de forma simples, sem precisar de DAGs Airflow complexos. Isso deve simplificar e melhorar o desempenho das consultas.
Talvez, para a análise de varejo, a gente queira saber como estão as coisas em diferentes regiões. É possível que cada região tenha seu próprio banco de dados central que envia dados periodicamente, mas com uma pequena diferença de sincronização. Em vez de criar pipelines ETL que precisam ajustar seus tempos para cada banco de dados, podemos criar uma tabela dinâmica que agrega tudo isso conforme necessário, com base nos atrasos de cada tabela. Isso reduz a complexidade da tubulação e minimiza a necessidade de manutenção constante.
Outros cenários podem incluir:
As tabelas dinâmicas do Snowflake são uma ferramenta incrível para te ajudar a simplificar pipelines ETL complexos baseados em tempo. Eles oferecem um equilíbrio elegante entre automação, flexibilidade e desempenho. Lembre-se de algumas práticas recomendadas, como testar com pipelines não críticos para entender o comportamento da atualização de dados, monitorar suas métricas de atraso e custo e avaliar os DAGs visuais para entender as dependências.
As tabelas dinâmicas não substituem totalmente os fluxos e as tarefas em todos os cenários, mas oferecem uma nova opção robusta que minimiza o código e maximiza a eficiência. Use-os com sabedoria e você pode realmente facilitar muito a sua vida. Para saber mais sobre o Snowflake e dar uma atualizada no SQL, dá uma olhada nesses recursos:
Cursos mais populares da Snowflake
Programa
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Tim Lu
11 min
Tutorial
Joleen Bothma
Tutorial
Allan Ouko
Tutorial
Karlijn Willems