Cursus
Fondations Snowflake
7 h
Snowflake est une plateforme de données cloud-native largement utilisée par les professionnels des données en raison de son évolutivité, de ses performances et de sa simplicité, ce qui la rend idéale pour tous les domaines, de l'analytique à la science des données. Cependant, pour tirer le meilleur parti de l'outil, il est essentiel de maîtriser l'ingestion de données Snowflake. Si vous êtes nouveau sur la plateforme, je vous suggère de commencer par ce Tutoriel Snowflake pour les débutants pour vous familiariser avec son architecture.
Des pipelines d'ingestion de données efficaces et correctement développés sont essentiels pour garantir la disponibilité et la fiabilité des données pour les cas d'utilisation en aval. Qu'il s'agisse de mises à jour périodiques par lots ou de flux de données en temps réel, le choix de la bonne méthode et des bons outils d'ingestion a un impact direct sur les performances et la maintenabilité de votre pipeline de données.
Avant de plonger dans les détails, il est essentiel de comprendre quelques concepts clés sur les flux de données.. :
L'ingestion de données est le processus qui consiste à transférer des données provenant de diverses sources dans une base de données en vue de leur stockage, de leur traitement et de leur analyse. Que vos données proviennent d'un stockage dans le cloud, de bases de données, d'applications ou de flux d'événements, l'ingestion agit comme la première étape du cycle de vie des données au sein de Snowflake.
L'architecture unique de Snowflake sépare le calcul et le stockage. Cela permet de simplifier le processus d'ingestion des données sans affecter les performances analytiques. L'ingestion peut cibler des étapes internes (au sein de Snowflake) ou externes (comme S3 ou Azure Blob Storage), en fonction de la source de données et du cas d'utilisation. Pour en savoir plus, cet article propose une plongée en profondeur dans l'architecture Snowflake.
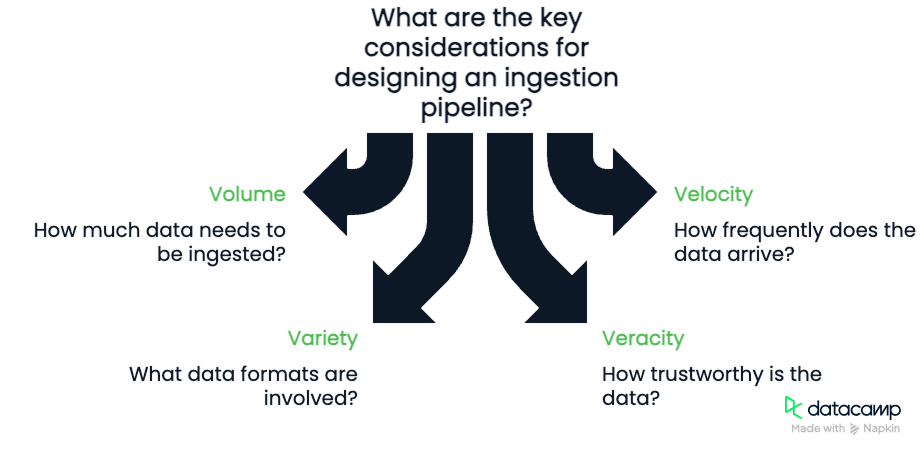
Lors de la conception d'un pipeline d'ingestion, gardez à l'esprit les Les quatre V des données:
Il est important de tenir compte de ces quatre éléments. Le volume et la vitesse nous obligeront à tenir compte de la largeur de bande disponible pour notre pipeline et de sa capacité à traiter les données. La variété et la véracité exigeront que nous développions des pipelines robustes et flexibles capables de contrôler la qualité des données au fur et à mesure qu'elles circulent.
Examinons quelques-unes des méthodes d'ingestion de données dont nous disposons dans Snowflake. Certaines méthodes impliquent l'utilisation d'une commande comme COPY INTO, Snowpipe, ou Snowpipe streaming.
La méthode d'ingestion la plus fondamentale de Snowflake est la commande COPY INTO. COPY INTO charge les données des fichiers stockés dans des étapes externes dans les tableaux de Snowflake. Il est idéal pour le chargement en masse de données historiques ou pour les mises à jour régulières par lots.
Vous pouvez charger des données depuis Amazon S3, Azure Blob Storage ou Google Cloud Storage en créant une étape externe qui connecte ces services cloud à Snowflake. Avec le chemin d'accès et les informations d'identification corrects, Snowflake lit et traite les fichiers efficacement.
COPY INTO prend en charge plusieurs formats : CSV, JSON, Avro, ORC et Parquet. Lors de la création du connecteur, il existe plusieurs options de type de format. La liste est assez longue, mais on y trouve souvent des paramètres permettant de définir des éléments tels que le format des dates, les délimiteurs (virgules ou autres valeurs), l'encodage, les options null, etc. Je vous recommande vivement de lire la documentation sur le site web de Snowflake pour obtenir tous les détails.
Vous pouvez configurer le paramètre ON_ERROR pour ignorer les lignes problématiques, interrompre le chargement ou consigner les erreurs. Combinez cela avec le site VALIDATION_MODE pour suivre et renvoyer les erreurs. Vous pouvez utiliser des tableaux de métadonnées tels que LOAD_HISTORY, qui permettent également de suivre le nombre d'erreurs survenues au cours d'un chargement.
Snowpipe permet une ingestion continue en détectant et en chargeant automatiquement les nouveaux fichiers au fur et à mesure qu'ils apparaissent dans une étape désignée. Cette fonctionnalité est intégrée à la plateforme Snowflake. Il offre une intégration automatique des fichiers, des déclencheurs basés sur des événements et une surveillance.
Snowpipe peut être configuré pour tester automatiquement les fichiers grâce à l'intégration avec les notifications de stockage dans le cloud, ce qui réduit la nécessité d'une exécution manuelle. Par exemple, Amazon S3 dispose de notifications d'événements qui alertent les utilisateurs sur les modifications apportées à un panier particulier.
Snowpipe peut être connecté à un utilisateur qui voit ces notifications. Lorsqu'une notification d'événement est reçue par cet utilisateur, Snowpipe est déclenché pour commencer le processus d'ingestion des données.
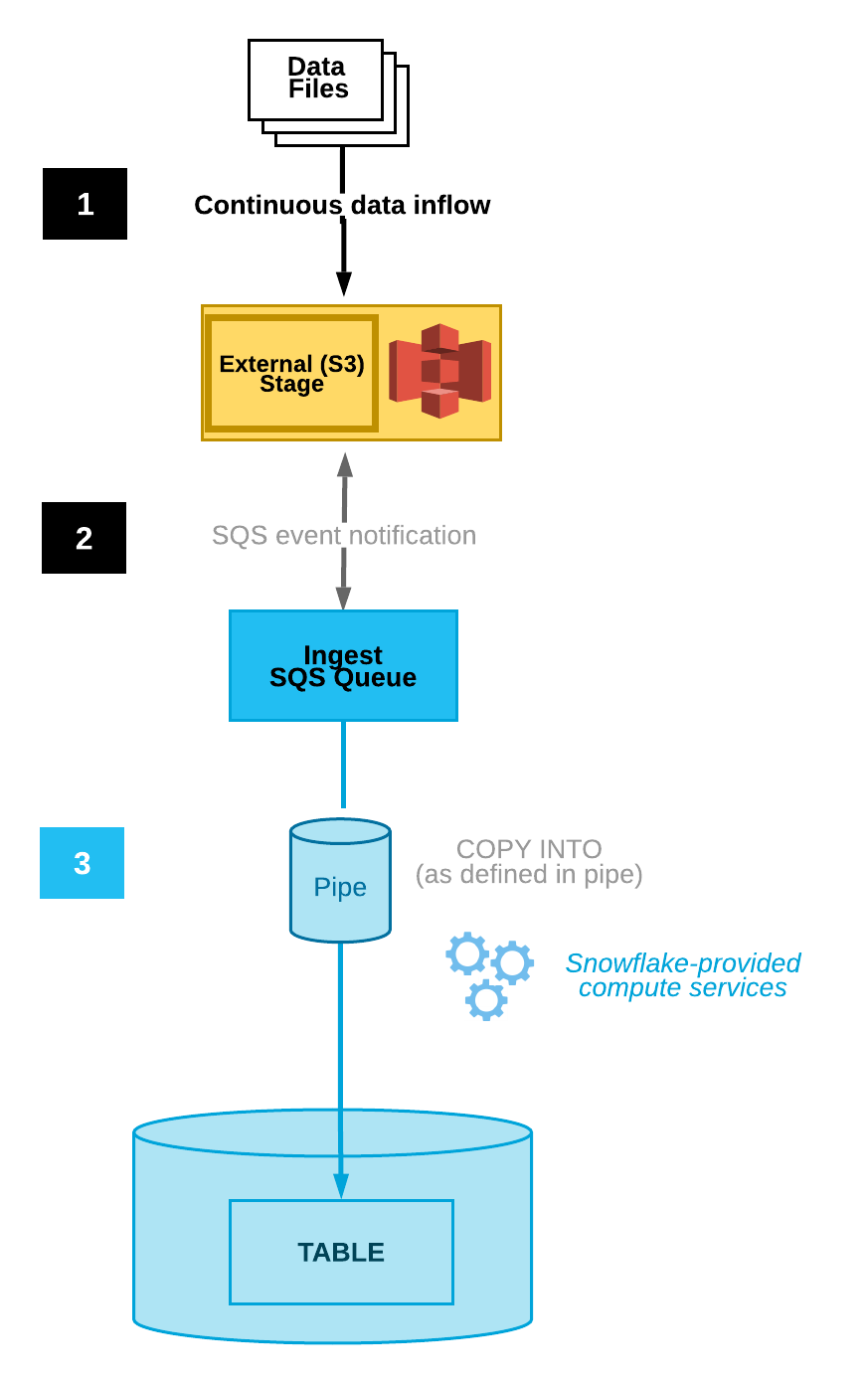
Diagramme d'ingestion automatisée de données(documentation Snowflake)
Snowflake propose différents outils de surveillance et de gestion des erreurs. Le tableau de métadonnées PIPE_USAGE_HISTORYpermet aux utilisateurs de consulter l'historique des chargements de données, tels que les octets et les fichiers ingérés. Le tableau VALIDATE_PIPE_LOAD vous fournira des informations sur les erreurs qui se sont produites.
Dans Snowpipe, il y a le paramètre ON_ERROR, qui nous permet de sauter des fichiers et d'envoyer des notifications qui nous avertissent des erreurs.
Snowpipe Streaming est la méthode la plus récente de Snowflake pour ingérer des données en streaming en temps réel avec une latence inférieure à la seconde. Contrairement à Snowpipe, qui réagit aux fichiers, Snowpipe Streaming ingère les données ligne par ligne via une API. Ces méthodes se complètent, offrant souplesse et efficacité.
Le SDK Ingest de Snowflake permet aux développeurs d'écrire des applications Java ou Scala qui poussent les données directement dans Snowflake à l'aide d'une file d'attente résidente en mémoire. Ces applications sont conçues pour accepter des données de niveau ligne provenant d'endroits tels que les sujets Apache Kafka et d'autres connecteurs de diffusion en continu.
Parfait pour la télémétrie, le flux de clics ou les données IoT, Snowpipe Streaming garantit une disponibilité des données en temps quasi réel avec une surcharge de stockage minimale et un débit élevé. Cette méthode d'ingestion est idéale lorsque vous avez besoin de données à grande vitesse et en temps quasi réel.
Dans le cadre de l'ingestion de données dans Snowflake à l'aide d'outils tels que Snowpipe et Snowpipe Streaming, certains outils sont nécessaires pour connecter correctement les pipelines de données. Un outil majeur est Kafka qui est couramment utilisé comme outil de communication entre les sources de données et Snowflake. Il existe également des outils tiers, tels que Fivetran et Matillion, qui peuvent également gérer l'ETL dans Snowflake.
Snowflake propose un connecteur Kafka qui lit les sujets Kafka et écrit les messages directement dans le stockage Snowflake. Les données sont publiées sur Kafka, et en utilisant Snowpipe ou Snowpipe Streaming, Snowflake peut récupérer ces données publiées et les transférer vers le stockage interne. Il s'agit d'un mode de transfert de données extrêmement souple. Je vous recommande ce cours Introduction à Apache Kafka, qui traite de la puissance et de l'évolutivité de Kafka.
Vous devrez configurer un travailleur Kafka Connect et définir des paramètres tels que les noms des sujets, la taille des tampons et les informations d'identification Snowflake afin de configurer correctement l'intégration.
Ces configurations nous permettent également de définir les types de données et les informations de métadonnées que nous souhaitons suivre. Les deux principaux moyens de définir ces connexions sont soit Confluent (une version gérée par un tiers d'Apache Kafka), soit manuellement à l'aide du kit de développement logiciel libre Apache Kafka JDK.
Quel que soit votre choix, suivez ces bonnes pratiques :
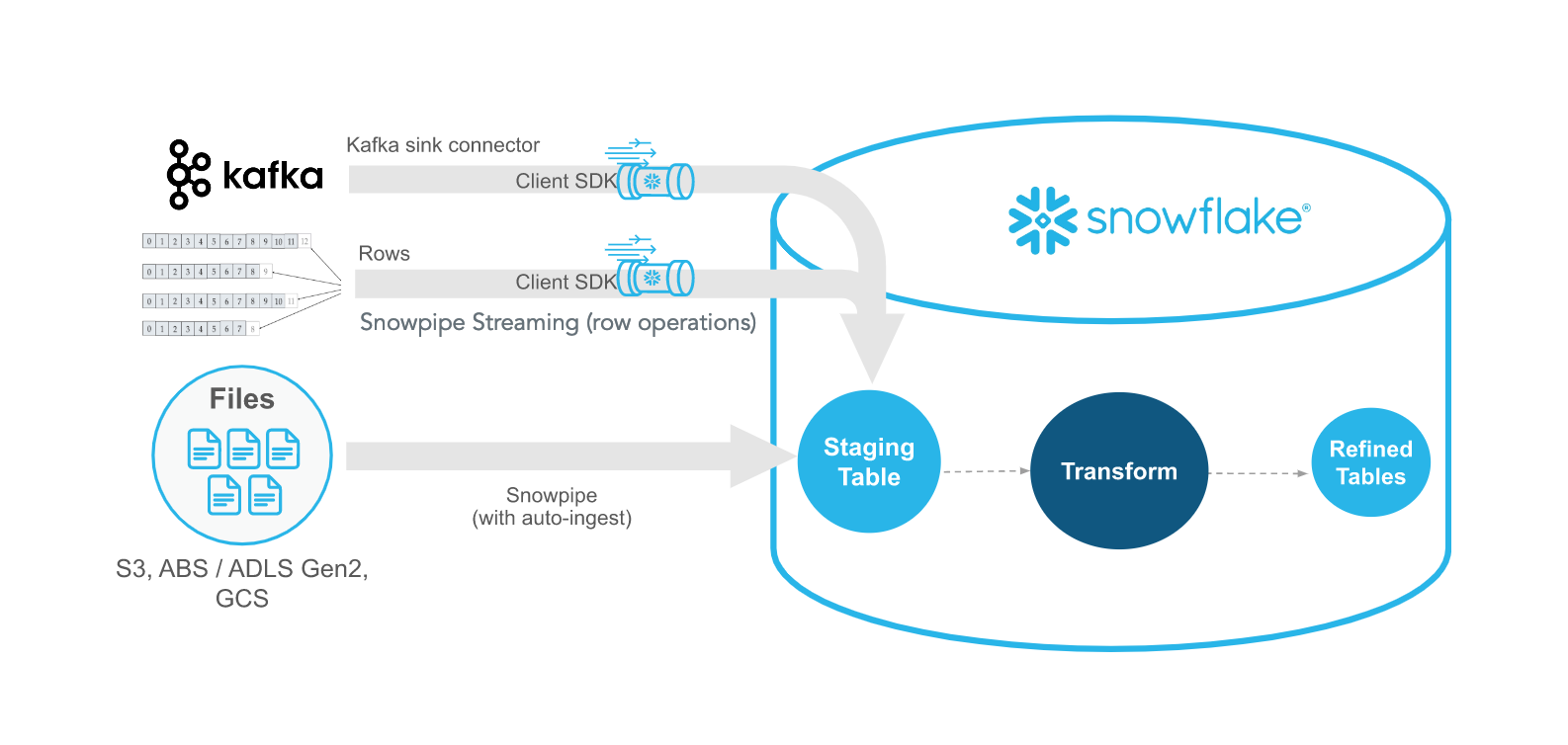
Exemple d'utilisation de Kafka avec Snowflake SDK pour le streaming de données(Documentation Snowflake)
En plus de Kafka, il existe des plateformes ETL tierces comme Fivetran, Matillion et Talend qui fournissent des solutions ETL/ELT gérées pour ingérer et transformer des données provenant de centaines de sources dans Snowflake. Ces plateformes tierces offrent souvent des solutions SaaS simplifiées et à faible code pour la gestion des données, mais le choix de ces plateformes a ses propres inconvénients.
Certains aspects doivent être soigneusement pris en compte lors de l'utilisation d'outils ETL tiers, tels que le coût et la flexibilité. Bien qu'il s'agisse sans aucun doute d'approches simplifiées pour ingérer des données dans Snowflake, il peut y avoir certaines restrictions qui les rendront finalement plus difficiles à utiliser.
Compte tenu de ces contraintes, vous devez prendre en considération les éléments suivants avant de choisir l'outil adéquat :
Bien que la conception d'un pipeline soit un travail difficile, il existe des concepts généraux et des bonnes pratiques que vous pouvez suivre pour vous faciliter la tâche. Ces mesures visent à améliorer l'efficacité et à réduire les coûts.
Réduisez la taille de vos fichiers pour diminuer le coût du stockage des données en utilisant des formats de fichiers tels que gzip ou Parquet. En outre, lorsque les données sont transférées, il est souvent préférable de privilégier un nombre réduit de fichiers de grande taille plutôt que de nombreux fichiers de petite taille pour votre processus de copie. Les fichiers volumineux uniques ont moins d'impact sur le réseau que le transfert de plusieurs fichiers plus petits. Enfin, programmez les gros travaux par lots pendant les heures creuses si les coûts de calcul et de réseau vous préoccupent.
Enfin, veillez à gérer l'évolution des schémas dans vos pipelines. Certains types de données, tels que Parquet, permettent naturellement l'évolution des schémas. Cela signifie que si le schéma de données peut changer par rapport à la source de données, cela n'a pas d'incidence sur les données historiques et maintient la compatibilité ascendante/descendante des données.
Un autre élément à prendre en compte lors de l'ingestion des données est la garantie de la qualité et de l'observabilité des données. Une façon intelligente de procéder consiste à mettre en scène les données avant de les intégrer dans le stockage final de votre base de données. Vous pouvez vérifier les hachages et les métadonnées pour vous assurer de l'exactitude des données et de l'absence de corruption. De même, au lieu de permettre aux utilisateurs d'accéder directement aux données elles-mêmes, la construction de vues qui peuvent combiner des sources de données disparates peut offrir une meilleure expérience à l'utilisateur.
Enfin, vous devez surveiller et enregistrer en permanence l'état de votre pipeline de données. Mettez en place des tableaux de bord en utilisant les vues de métadonnées de Snowflake ou des outils d'observabilité externes comme DataDog ou Monte Carlo pour suivre le succès de l'ingestion, la latence et les échecs.
Nous allons ici couvrir quelques exemples de haut niveau sur la façon dont vous pouvez construire des pipelines dans Snowflake. Remarque, vos étapes exactes peuvent être différentes selon la manière dont votre administrateur de données a configuré votre environnement Snowflake. Veillez à respecter les meilleures pratiques de votre organisation !
Tout d'abord, quelques conditions préalables. Vous aurez besoin d'un compte Snowflake qui vous permettra de gérer la base de données. Parmi les autorisations d'accès courantes dont vous aurez besoin figure la possibilité de créer des schémas. Deuxièmement, vous devez vous assurer que le serveur sur lequel vous vous trouvez a accès au seau de stockage cloud externe ou au stockage interne où vous stockez les données. Parlez-en à votre administrateur de base de données.
COPY INTOVoyons un exemple simple de chargement d'un fichier CSV dans votre base de données Snowflake.
1. Préparer et télécharger les données Formatez vos fichiers (par exemple, CSV) et téléchargez-les dans votre panier de stockage en nuage.
2. Créer une étape et un format de fichier
/* specify the file format */CREATE FILE FORMAT my_csv_format TYPE = 'CSV'
/* this will help if there are double quotes or apostrophes in your data */
FIELD_OPTIONALLY_ENCLOSED_BY='"';
/* Stage the data using the credentials you have */
CREATE STAGE my_stage URL='s3://my-bucket/data/' CREDENTIALS=(AWS_KEY_ID='...' AWS_SECRET_KEY='...');3. Lancez COPY INTO et vérifiez
COPY INTO my_table FROM @my_stage FILE_FORMAT = (FORMAT_NAME = 'my_csv_format');SELECT * FROM my_table;La création d'une ingestion automatisée à l'aide de Snowpipe peut être très simple !
1. Créer un Snowpipe
CREATE PIPE my_pipe
AUTO_INGEST = TRUE
AWS_SNS_TOPIC = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket'
AS
COPY INTO my_table
FROM @my_stage
FILE_FORMAT = (TYPE = ‘CSV’);2. Configurez les événements de stockage dans le cloud Configurez la notification des seaux S3 pour déclencher le tuyau à l'aide de SNS/SQS. Pour plus de détails, je vous conseille de suivre ce guide sur AWS SNS de DataCamp.
3. Surveiller l'ingestion
Veillez à interroger le tableau de métadonnées SNOWPIPE_EXECUTION_HISTORY pour visualiser l'activité des tuyaux.
La mise en place de Snowpipe Streaming peut être assez intense et est un peu plus détaillée que ce que nous pouvons couvrir ici. Je couvrirai certaines des étapes fondamentales, mais je vous recommande surtout de lire les exemples de la documentation sur le Streaming de documentation de Snowflake Streaming pour savoir comment construire le SDK client.
profile.json. Les propriétés requises concernent les identifiants d'autorisation, l'URL de Snowflake et l'utilisateur. Cela permet au SDK de se connecter à votre serveur Snowflake. Rédigez le reste de votre script Java pour gérer l'arrivée des données, y compris la méthode insertRows.Snowflake offre une suite robuste et flexible de méthodes d'ingestion de données, des chargements par lots traditionnels au streaming en temps réel. En comprenant les outils et les techniques disponibles, les équipes chargées des données peuvent concevoir des pipelines fiables, performants et rentables. Que vous débutiez ou que vous optimisiez une solution à l'échelle de l'entreprise, la maîtrise de l'ingestion de données Snowflake est une étape essentielle dans la mise en place d'une pile de données moderne. Si vous souhaitez en savoir plus sur Snowflake, je vous recommande vivement les ressources suivantes :
Principaux cours sur les Snowflakes
Cursus
Cours
Cours