
Track
Snowflake Foundations
7 hr
Snowflake’s Dynamic Tables are a powerful tool in a data engineer’s pipeline toolbelt. They’re essentially automated refresh processes that use transformation queries on base tables to generate new tables.
Dynamic Tables simplify data orchestration pipelines where data freshness is important and complex SQL-based transformations are necessary. They use lag-based timing to refresh tables based on changes in base tables.
Recent enhancements have bolstered their capabilities, enabling near-real-time data propagation and deeper integration within Snowflake’s ecosystem (get a refresher with this introduction course).
This guide explores how Dynamic Tables function, how to implement them effectively, and how to monitor and optimize performance. By the end, you'll be equipped to assess and test these implementations to see if they fit your organization’s data needs.
Dynamic Tables are a fully managed class of Snowflake database objects that help streamline and automate data pipelines.
Instead of using external orchestration tools or trying to time manual refreshes with source table updates, Dynamic Tables automatically update based on source data changes and defined freshness targets. This allows data professionals to build data transformations that are flexible and update as needed when data changes.
Unlike views which require the user to compute the table when it is queried, Dynamic Tables stay calculated which improves query speeds. Likewise, while materialized views offer the same kind of cached data, Dynamic Tables are able to utilize things like joins, unions, and nested views that materialized views cannot.
Originally introduced to bridge the gap between traditional ELT pipelines and event-driven architectures, Dynamic Tables represent Snowflake’s continued development for declarative and dependency-aware data processing.
All you have to do is write the SQL SELECT query that defines your Dynamic Table with a defined TARGET_LAG which dictates the refresh frequency.
For example, a TARGET_LAG of five minutes means the Dynamic Table is no more than five minutes behind the base table. The best part is that this is all managed by Snowflake’s own internal refresh engine and saves us from having to design complex pipelines!
To effectively implement dynamic tables, we’ll dig into some of the underlying technical implementations from Snowflake to understand their strengths and weaknesses.
Much like materialized views, Dynamic Tables provide persistent and automated data refresh behavior. However, unlike materialized views, they allow for more complex transformations by allowing things like unions and joins.
This allows for the creation of multiple smaller Dynamic Tables that can then feed into larger dynamic tables.
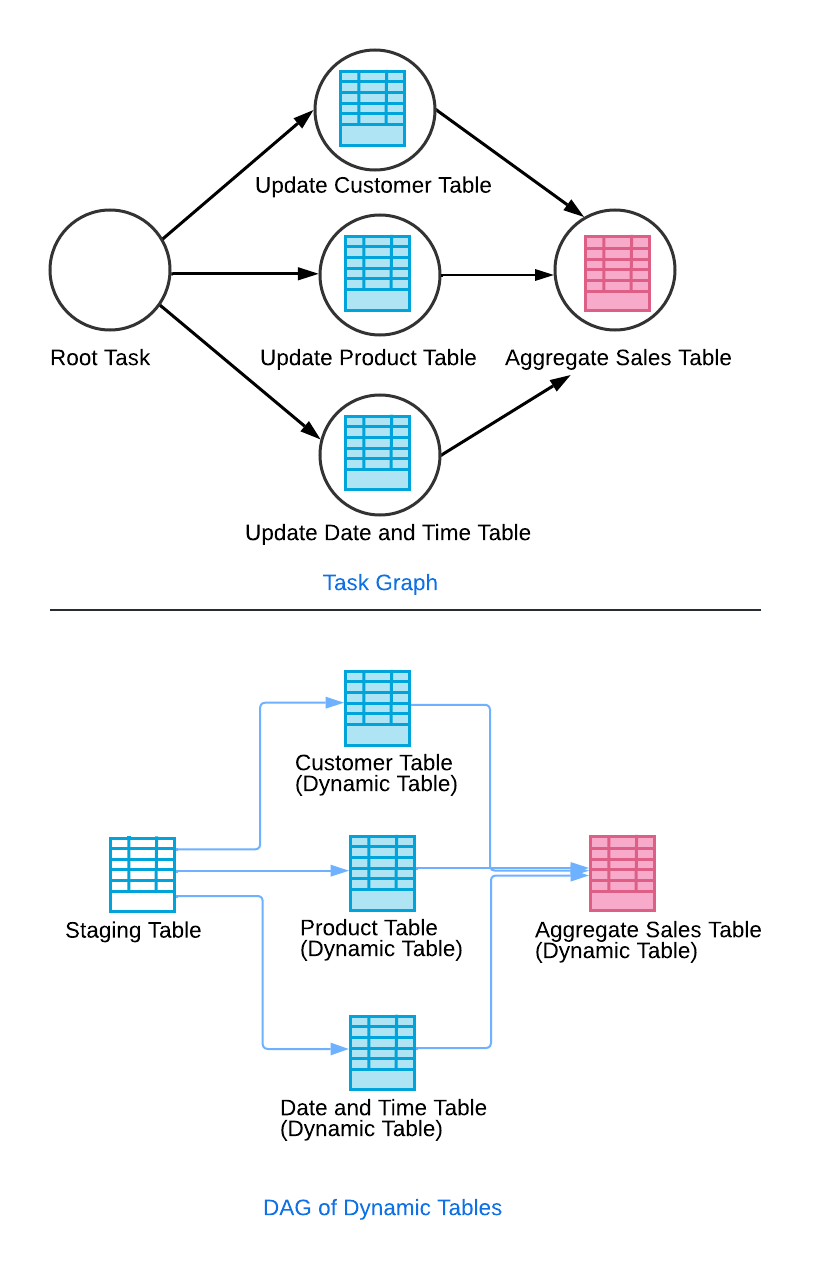
A key innovation is Snowflake’s use of an automated dependency graph. Either you can create a dynamic aggregate table that updates as base tables update, or you can build layers of Dynamic Tables using directed acyclic graphs. This works by updating a base staging table, which triggers the update of a downstream dynamic table.
Once those intermediate Dynamic Tables are updated, the final aggregate Dynamic Table updates. All this operates with Snowflake’s refresh workers looking for data updates and making sure source tables refresh with up-to-date data.
From Snowflake Documentation on Creating Dynamic Tables
The main mechanisms that you can control when creating Dynamic Tables are refresh modes, lag, and warehouse parameters during creation. Dynamic Tables support two refresh modes:
You can either manually define the refresh mode, or you can use REFRESH_MODE = AUTO in the initial creation of the dynamic table. Just be aware when using AUTO that it sets the refresh mode at creation and is not updated. If Snowflake determinesthat incremental refresh is inefficient, then it will choose to do a full refresh.
The WAREHOUSE setting determines the warehouse that will be utilized for compute resources. Make sure to select the right one that fits your computational and data storage needs.
Perhaps the most important concept is the lag. The most common way to determine lag is to use TARGET_LAG which defines the acceptable delay between source data and dynamic tables. If you are working with a somewhat more complex pipeline where other Dynamic Tables rely on other dynamic tables, you can choose to set TARGET_LAG = DOWNSTREAM.
By setting the TARGET_LAG to DOWNSTREAM it looks at the downstream Dynamic Tables which rely on the current Dynamic Table for timing.
|
Source Concept |
Inherited Feature in Dynamic Tables |
How Dynamic Tables Improve It |
|
Traditional Tables |
Persistent storage; downstream reusability |
Automatically maintained and refreshed; no manual data loads or triggers needed |
|
Views |
Declarative SQL logic; no need for procedural code |
Materialized output for better performance; freshness managed via TARGET_LAG |
|
Materialized Views |
Automatic refresh; state management |
Supports complex transformations; integrated dependency tracking across stages |
Each Dynamic Table contributes to a DAG, allowing Snowflake to coordinate refreshes across multiple tables. This ensures correctness and efficiency, particularly in multi-stage pipelines.
Snowsight provides a visual interface for exploring this DAG, showing dependencies, refresh times, and lag metrics. This is a major advantage for debugging and impact analysis. Be sure to read this article on Snowflake data pipelines for more info on how Snowflake’s architecture functions.
Let’s get into some of the other key features of Dynamic Tables and their advantages.
Dynamic Tables eliminate the need for external orchestration (e.g., Airflow or dbt Cloud) by handling dependency tracking and refresh logic natively in Snowflake.
This has a number of advantages, including:
All these allow Dynamic Tables to excel in situations where up-to-date and near real-time data is necessary. Think things like real-time dashboards and CDC workflows. Plus, you can chain multiple Dynamic Tables in sequence for multi-stage transformations.
Instead of defining manual refresh timelines using CRON jobs, Dynamic Tables use TARGET_LAG to check against source tables. For streaming real-time data tables, this means that as soon as the Dynamic Table is out of sync by the designated lag, it automatically updates.
While they are very similar, Dynamic Tables are often used as an alternative to Streams and materialized views. Materialized views are great if you require data to always be current and you are using a simple logic on a singular base table.
Streams are ideal for implementing CDC manually and for understanding how data changes over time. Dynamic Tables are perfect when you want a simple way to implement regularly scheduled updates to complex data transformation queries.
For more considerations on how to structure data in Snowflake, this course on data modeling in Snowflake is an excellent resource.
Let’s walk through how to set up Dynamic Tables using syntax patterns and best practices. Getting these going is relatively easy, but understanding the parameters thoroughly will allow you to get the most out of your dynamic tables.
Here’s some sample code for how we might want to create a Dynamic Table using our table raw_sales as the base. Look it over and we’ll break it down next.
# Your Dynamic Table parameters
CREATE OR REPLACE Dynamic Table sales_agg
TARGET_LAG = '5 minutes'
WAREHOUSE = 'prod_wh'
REFRESH_MODE = auto
INITIALIZE = on_create
AS
# Your SQL query for the table itself
SELECT
store_id,
SUM(amount) AS total_sales,
COUNT(*) AS sale_count
FROM raw_sales
GROUP BY store_id;The second half should be pretty straightforward; that’s our SELECT statement, which defines the data in the table. The first half before the SELECT statement are all our creation parameters:
TARGET_LAG: Specifies freshness requirement as explained above. You can either set a timeframe here or write “DOWNSTREAM” if there is another Dynamic Table that is using this data.WAREHOUSE: Determines compute resources. Make sure to select the right Snowflake warehouse to have enough resources to generate the table in a cost-effective wayREFRESH_MODE: Can be explicitly set to INCREMENTAL or FULL. I have chosen AUTO to let Snowflake determine the optimal method.INITIALIZE: Determines when the table is initialized. ON_CREATE means the table is initialized immediately. Setting it to ON_SCHEDULE will initialize the table once the first lag period is reached.Note that Snowflake will require change tracking to properly support incremental refreshes, which means they are automatically turned on for incremental dynamic tables!
If you want to check it manually, you can use the ALTER TABLE command. Having change tracking on also allows for time travel in the event we need to restore historical versions of tables.
Two nuances to Dynamic Tables are cloning them and connecting them to Snowflake Iceberg tables, which are built on external Apache Iceberg tables.
For Iceberg tables, nothing changes during set-up. The main benefit of Dynamic Tables built on Snowflake Iceberg tables is that they allow you to continue processing the external data without continuous ingestion or duplication of the data.
Cloning is possible thanks to Snowflake’s time travel, and we can copy an older version of our Dynamic Table, using the CLONE command like so:
CREATE Dynamic Table clone_sales_agg
CLONE sales_agg
AT (OFFSET => -24*60*60) –-24 hours ago
TARGET_LAG = DOWNSTREAM
WAREHOUSE = sales_whThe caveat here is that cloned tables might not share all the metadata of the source table, and they take up extra storage space. Be mindful with cloning and make sure it’s necessary.
It is a good idea to practice setting up Dynamic Tables to test the functionality. Here is a general guide on how to test dynamic tables:
raw_sales table with timestamps.TARGET_LAG = '1 minute' to see refreshes in action.Something you can do is to create a stream which looks at an S3 bucket where you can periodically upload data. As this data changes, you can see how your Dynamic Table updates. You can follow this tutorial for simple ways to set up Snowflake data ingestion and then look to this tutorial for more information on creating tables in Snowflake.
Snowflake provides several tools to help you monitor and manage Dynamic Tables effectively, such as using Snowsight or querying. Make sure you have monitor privileges on your account to see this information!
Using Snowsight to monitor Dynamic Tables is simple:
Snowsight can provide great information, such as how the Dynamic Table was created, the DAG, and the refresh history and metrics.
To do the same thing with SQL, we would use the SHOW DYNAMIC TABLES command.
For instance, if I’m interested in seeing all my sales-related dynamic tables:
SHOW Dynamic Tables LIKE ‘sales_%' IN SCHEMA mydb.myschema;This provides information like when the table was created, its size, target lag, and its latest status.
There will probably come a time when you want to modify or suspend your dynamic table. Thankfully, Snowflake makes it simple.
To suspend your table, we use ALTER DYNAMIC TABLE and SUSPEND:
ALTER Dynamic Table sales_agg SUSPEND;To resume it late, we do the same but with RESUME:
ALTER Dynamic Table sales_agg RESUME;To change parameters, we can also use the ALTER DYNAMIC TABLE line and SET the specific parameter we want to change:
ALTER Dynamic Table sales_agg SET TARGET_LAG = '10 minutes';The best way to manage dependencies and minimize operational disruptions is to make sure you are not suspending critical tables. If you are planning to change the amount of lag, make sure you understand how that might impact the timing of downstream tables.
We’ve learned that Dynamic Tables are very useful, but they still have a few limits and considerations.
There are some account and source type limitations. Current constraints include:
ACCESS_HISTORY auditing viewOther things to consider are cloning, time travel, and access control. Time travel might be the simplest, as it requires a minimum value of 1 day. You cannot turn off time travel by setting the DATA_RETENTION_TIME_IN_DAYS to 0.
When cloning a dynamic table, be aware that not all meta data is saved. Also, you are not able to clone Iceberg dynamic tables. If you clone a Dynamic Table that relies on an Iceberg dynamic table, that Iceberg Dynamic Table is not relocated to the new location.
Creating and using Dynamic Tables requires the CREATE DYNAMIC TABLE, SELECT, and USAGE access roles for the parent database and schema.
If you remember these constraints, then you should have less trouble with dynamic tables!
Thanks to their simple implementation methodology, it can be easy to overload the system. A common mistake is to treat Dynamic Tables like a real-time data pipeline. They are not meant to replace real-time data sources; instead we should consider timing and data recency requirements. For instance, we can follow these best practices:
REFRESH_MODE = incremental when possible so we are not recreating the entire Dynamic Table with each loadTARGET_LAG to balance cost and data freshness needs of the stakeholder.WAREHOUSE to optimize compute resources being usedSELECT statements.Following these simple tips can help keep your Dynamic Tables humming along. Using them wisely can really simplify your critical data pipelines with minimal cost, but using them recklessly can create more problems down the road!
As we mentioned, there are storage and compute costs associated with using dynamic tables. We can show some strategies for understanding these costs and how to manage them in Snowflake.
There are two big parts to the cost of using dynamic tables: storage and compute. Each of these have a few pieces to them so let's dive into each.
For storage costs, you will be charged for storing the materialized results of each dynamic table. There are also additional costs for things like Time Travel, fail-safe storage, and cloning.
The one exception is dynamic iceberg tables, where you won’t get any Snowflake storage costs since they’re stored externally. You can limit these costs by either making your Dynamic Table as lean as possible or minimizing the amount of cloning and time travel.
Compute costs come in two big parts: virtual warehouse and Cloud Services compute. Virtual warehouses are going to be the resources you use to actually initialize and refresh your tables; think of the costs associated with running the query.
The Cloud Services compute is more about the automation Snowflake provides. These include identifying changes in underlying base objects and maintaining the DAGs. Think of all the background work Snowflake does in order to keep your Dynamic Tables functioning.
This is a function of your defined table lag, and the cost is directly associated with that defined frequency.
For a full picture of how these costs come together, refer to Snowflake’s cost documentation, which breaks down the components.
Snowflake makes monitoring these costs easy using Snowsight. You can go to Monitoring, then Dynamic Tables as usual, and under the dynamic table’s page, there is a Refresh History tab that will show you the warehouse credits used.
If you would like to see the broader usage of your account, you can also use the following query:
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.METERING_HISTORY;This will output the costs incurred by different services on the account and can be tied to your dynamic tables.
Additionally, I recommend testing on a dedicated warehouse so you can fully understand the warehouse costs associated with the dynamic table. Once you get a feel for the cost, you can move them to your shared warehouses.
If you would like to save on costs, consider using things like auto-suspension. Suspended Dynamic Tables are only charged for storage and not for any refresh resources.
You can also use transient Dynamic Tables that have no fail-safe storage costs. Plus, if you optimize your TARGET_LAG to the right frequency and use incremental refresh where possible, you can save on a lot of compute costs.
As always, writing good SQL and optimized transformations are also a great way to reduce compute resource usage.
Dynamic Tables can be used anywhere you want to replace a complicated, finicky time-based reload ETL pipeline with a simplified lag-based and self-managed pipeline.
Here are some deployment use cases that might be useful for your particular industry.
For finance-based organizations, it might be useful to have periodic refreshes of transactional data, like fraud detection or chargebacks.
Since we don’t need up-to-the-second data, we might like a TARGET_LAG of 10 minutes for general system health dashboards. Perhaps you have a data science model that saves all fraud alerts into one table and a third-party chargeback monitoring system which saves to another table.
You can bring these two together into an aggregated table simply without the need for complex Airflow DAGs. This should simplify and improve querying performance.
Perhaps for retail analytics, we are interested in how different regions are performing. It’s possible each region has their own central database that pushes data periodically, but slightly off-sync. Instead of building out ETL pipelines which have to tailor their timings to each database, we can build a Dynamic Table which aggregates these all together as needed based on lags from each table. This reduces pipeline complexity and minimizes the need for constant maintenance.
Some other scenarios might involve:
Snowflake Dynamic Tables are an amazing tool to help you simplify complex time-based ETL pipelines. They offer an elegant balance between automation, flexibility, and performance. Just remember some best practices like testing with non-critical pipelines to understand data refresh behavior, monitoring your lag and cost metrics, and assessing the visual DAGs to understand dependencies.
Dynamic Tables are not a full replacement for Streams and Tasks in every scenario, but they offer a robust new option that minimizes code and maximizes efficiency. Use them wisely, and you can really make your life a lot easier. For more information on Snowflake and some SQL refreshers, check the following resources:
Top Snowflake Courses
Track
Course
Course
blog
Bex Tuychiev
12 min
blog
Tim Lu
12 min
Tutorial
Bex Tuychiev
Tutorial
Bex Tuychiev
Tutorial
Tim Lu
Tutorial
Tim Lu
