Program
Analis Data dalam Python
36 Hr
Dalam data science dan machine learning, kemampuan untuk mengungkap pola tersembunyi dan mengelompokkan titik data yang serupa adalah keterampilan penting. Algoritma klastering memainkan peran kunci dalam proses ini.
Klastering adalah teknik mendasar dalam machine learning dan data science yang melibatkan pengelompokan titik data yang serupa. Ini adalah metode pembelajaran tanpa supervisi, yang berarti tidak memerlukan data berlabel untuk menemukan pola.
Tujuan utama klastering adalah untuk:
Meskipun ada banyak algoritma klastering (Anda mungkin pernah mendengar K-means atau klastering hierarkis), DBSCAN menawarkan keunggulan unik. Sebagai metode berbasis kepadatan, DBSCAN memiliki beberapa kekuatan:
Dalam artikel ini, kita akan membahas apa itu algoritma DBSCAN, bagaimana DBSCAN bekerja, cara mengimplementasikannya di Python, dan kapan menggunakannya dalam proyek data science Anda.
DBSCAN, singkatan dari Density-Based Spatial Clustering of Applications with Noise, adalah algoritma klastering yang kuat yang mengelompokkan titik-titik yang saling berdekatan dalam ruang data. Tidak seperti beberapa algoritma klastering lainnya, DBSCAN tidak mengharuskan Anda menentukan jumlah klaster terlebih dahulu, sehingga sangat berguna untuk analisis data eksploratori.
Algoritma ini bekerja dengan mendefinisikan klaster sebagai wilayah padat yang dipisahkan oleh wilayah dengan kepadatan lebih rendah. Pendekatan ini memungkinkan DBSCAN menemukan klaster dengan bentuk sebarang dan mengidentifikasi outlier sebagai noise.
DBSCAN berputar di sekitar tiga konsep kunci:
Gambar oleh penulis
Diagram di atas menggambarkan konsep-konsep ini. Titik inti (biru) membentuk jantung klaster, titik batas (oranye) berada di tepi klaster, dan titik noise (merah) terisolasi.
DBSCAN menggunakan dua parameter utama:
Dengan menyesuaikan parameter ini, Anda dapat mengontrol bagaimana algoritma mendefinisikan klaster, memungkinkannya beradaptasi dengan berbagai jenis dataset dan kebutuhan klastering.
Pada bagian berikutnya, kita akan melihat bagaimana algoritma DBSCAN bekerja, menelusuri proses langkah demi langkah untuk mengidentifikasi klaster dalam data.
DBSCAN beroperasi dengan memeriksa lingkungan sekitar setiap titik dalam dataset. Algoritma mengikuti proses bertahap untuk mengidentifikasi klaster berdasarkan kepadatan titik data. Berikut penjelasan cara kerja DBSCAN:
Proses ini memungkinkan DBSCAN membentuk klaster dengan bentuk sebarang dan secara efektif mengidentifikasi outlier. Kemampuan algoritma untuk menemukan klaster tanpa menentukan jumlah klaster sebelumnya adalah salah satu kekuatannya.
Penting untuk dicatat bahwa pemilihan ε dan MinPts dapat sangat memengaruhi hasil klastering. Pada bagian berikutnya, kita akan membahas cara memilih parameter ini secara efektif dan memperkenalkan metode seperti grafik k-distance untuk pemilihan parameter.
Untuk memahami sepenuhnya bagaimana DBSCAN membentuk klaster, penting memahami dua konsep kunci: keterjangkauan kepadatan (density reachability) dan konektivitas kepadatan (density connectivity).
Titik q dapat dijangkau secara kepadatan dari titik p jika:
1. p adalah titik inti (memiliki setidaknya MinPts dalam jarak ε)
2. Ada rangkaian titik p = p1, ..., pn = q di mana setiap pi+1 dapat dijangkau secara kepadatan langsung dari pi.
Sederhananya, Anda dapat mencapai q dari p dengan melangkah melalui titik-titik inti, di mana setiap langkah tidak lebih besar dari ε.
Dua titik p dan q terhubung secara kepadatan jika ada titik o sedemikian rupa sehingga baik p maupun q dapat dijangkau secara kepadatan dari o.
Konektivitas kepadatan adalah dasar pembentukan klaster dalam DBSCAN. Semua titik dalam suatu klaster saling terhubung secara kepadatan, dan jika suatu titik terhubung secara kepadatan dengan titik mana pun dalam klaster, ia juga termasuk dalam klaster tersebut.
Efektivitas DBSCAN sangat bergantung pada pemilihan dua parameter utamanya: ε (epsilon) dan MinPts. Berikut pendekatan untuk memilih parameter ini:
Parameter ε menentukan jarak maksimum antara dua titik agar dianggap sebagai tetangga. Untuk memilih ε yang sesuai:
1. Gunakan pengetahuan domain: Jika Anda mengetahui jarak yang bermakna untuk masalah spesifik Anda, gunakan itu sebagai titik awal.
2. Grafik k-distance: Ini pendekatan yang lebih sistematis:
MinPts menentukan jumlah minimum titik yang diperlukan untuk membentuk wilayah padat. Berikut beberapa panduan:
1. Aturan umum: Titik awal yang baik adalah menetapkan MinPts = 2 * num_features, di mana num_features adalah jumlah dimensi dalam dataset Anda.
2. Pertimbangan noise: Jika data Anda memiliki noise atau Anda ingin mendeteksi klaster yang lebih kecil, Anda mungkin ingin menurunkan MinPts.
3. Ukuran dataset: Untuk dataset yang lebih besar, Anda mungkin perlu meningkatkan MinPts untuk menghindari terlalu banyak klaster kecil.
Ingat, pemilihan parameter dapat sangat memengaruhi hasil. Sering kali bermanfaat untuk bereksperimen dengan berbagai nilai dan mengevaluasi klaster yang dihasilkan guna menemukan kecocokan terbaik untuk dataset dan masalah Anda.
Pilihan metrik jarak dalam DBSCAN dapat sangat memengaruhi hasil klastering. Secara default, DBSCAN menggunakan jarak Euclidean, yang bekerja baik untuk klaster yang kompak dan menyerupai bola. Namun, ini mungkin tidak ideal untuk semua jenis data.
Anda dapat menentukan metrik alternatif, seperti:
Menyelaraskan metrik jarak dengan struktur data Anda memastikan bahwa klastering berbasis kepadatan mencerminkan kemiripan yang sebenarnya.
Dalam scikit-learn, parameter metric memungkinkan Anda menetapkannya secara eksplisit (misalnya, metric='cosine'). Beberapa metrik khusus mungkin memerlukan matriks jarak yang telah dihitung sebelumnya.
Karena DBSCAN bergantung pada nilai jarak absolut, fitur yang tidak diskalakan dapat menghasilkan hasil yang terdistorsi. Variabel dengan rentang lebih besar akan mendominasi perhitungan jarak, meskipun variabel tersebut tidak lebih penting. Ini dapat mencegah algoritma mengidentifikasi wilayah padat dalam data secara benar.
Untuk menghindarinya, penting untuk men-skala fitur agar kontribusinya setara. Pendekatan umum meliputi:
Standarisasi: Memusatkan fitur di sekitar nol dengan varians satu menggunakan StandardScaler.
Skala Min-Maks: Mengubah skala fitur ke rentang tetap (biasanya [0, 1]) menggunakan MinMaxScaler.
Pilih metode penskalaan yang sesuai dengan distribusi data Anda. Tanpa prapemrosesan yang tepat, DBSCAN mungkin gagal mendeteksi klaster yang bermakna—bahkan jika epsilon dan MinPts Anda sudah disetel dengan baik.
Pada bagian ini, kita akan melihat implementasi DBSCAN menggunakan Python dan pustaka scikit-learn. Kita akan menggunakan dataset Make Moons untuk mendemonstrasikan prosesnya.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsImpor ini menyediakan alat yang diperlukan untuk manipulasi data, visualisasi, pembuatan dataset, dan mengimplementasikan algoritma DBSCAN.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)Kode ini membuat dataset sintetis menggunakan fungsi make_moons dari scikit-learn. Berikut deskripsi singkat datasetnya:
Fungsi make_moons menghasilkan dataset klasifikasi biner yang menyerupai dua bulan sabit yang saling bertautan. Dalam kasus kita:
n_samples=200)noise=0.05) agar dataset lebih realistisrandom_state=42 untuk reprodusibilitasDataset ini sangat berguna untuk mendemonstrasikan DBSCAN karena:
Mari visualisasikan dataset ini untuk lebih memahami strukturnya:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Ini akan menampilkan dua bentuk setengah bulan yang saling bertautan dalam dataset kita seperti di bawah ini
Kita menggunakan metode grafik k-distance untuk membantu memilih nilai epsilon yang sesuai:
plot_k_distance_graph yang menghitung jarak ke tetangga terdekat ke-k untuk setiap titik.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Keluaran
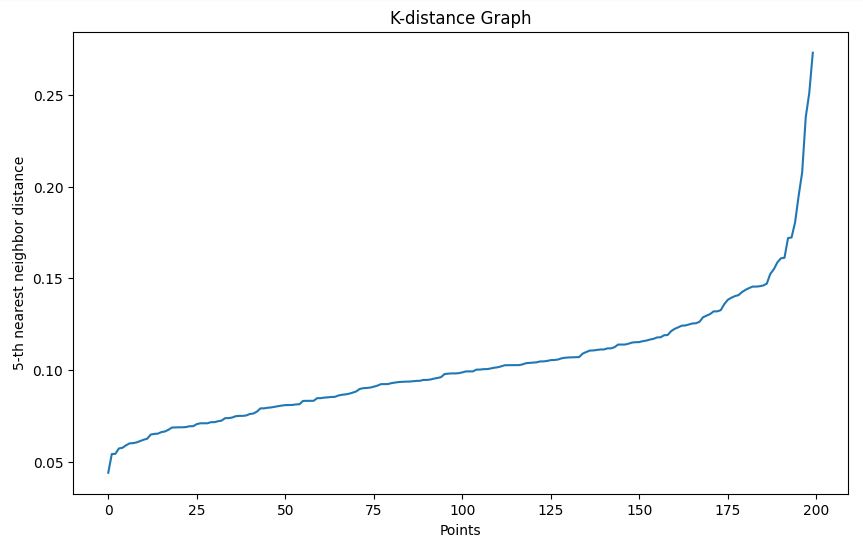
Dalam contoh kita, berdasarkan grafik k-distance, kita memilih epsilon sebesar 0,15.
Kita menggunakan implementasi DBSCAN dari scikit-learn:
epsilon=0.15 berdasarkan grafik k-distance.min_samples=5 (2 * num_features, karena data kita 2D).# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)Kita membuat scatter plot titik data kita, mewarnainya sesuai klaster yang ditetapkan. Titik yang diklasifikasikan sebagai noise biasanya diberi warna berbeda (sering kali hitam).
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Keluaran
Terakhir, kita mencetak jumlah klaster yang ditemukan dan jumlah titik yang diklasifikasikan sebagai noise. Ini memberi ringkasan singkat hasil klastering.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Keluaran
Number of clusters: 2
Number of noise points: 5
Implementasi ini menyediakan alur kerja lengkap dari pembuatan data hingga penafsiran hasil. Penting dicatat bahwa dalam skenario dunia nyata, Anda akan mengganti pembuatan data contoh dengan memuat dan melakukan prapemrosesan pada dataset Anda yang sebenarnya.
Ingat, kunci keberhasilan klastering DBSCAN sering kali terletak pada pemilihan parameter yang tepat. Jangan ragu untuk bereksperimen dengan nilai epsilon dan min_samples yang berbeda guna menemukan kecocokan terbaik untuk dataset Anda.
Meskipun DBSCAN dan K-Means sama-sama populer, keduanya memiliki karakteristik berbeda yang membuatnya cocok untuk jenis data dan kasus penggunaan yang berbeda. Mari bandingkan kedua algoritma ini untuk memahami kapan menggunakan masing-masing.
|
Fitur |
DBSCAN |
K-Means |
|
Bentuk Klaster |
Dapat mengidentifikasi klaster dengan bentuk sebarang |
Mengasumsikan klaster berbentuk konveks dan kira-kira bulat |
|
Jumlah Klaster |
Tidak memerlukan penentuan jumlah klaster terlebih dahulu |
Memerlukan penentuan jumlah klaster (K) di awal |
|
Penanganan Outlier |
Mengidentifikasi outlier sebagai titik noise |
Memaksa setiap titik masuk ke sebuah klaster, berpotensi mendistorsi bentuk klaster |
|
Sensitivitas terhadap Parameter |
Sensitif terhadap parameter epsilon dan MinPts |
Sensitif terhadap posisi centroid awal dan pilihan K |
|
Kepadatan Klaster |
Dapat menemukan klaster dengan kepadatan bervariasi |
Cenderung menemukan klaster dengan luas dan kepadatan yang serupa |
|
Skalabilitas |
Kurang efisien untuk dataset besar, terutama dengan data berdimensi tinggi |
Umumnya lebih efisien dan lebih skalabel untuk dataset besar |
|
Penanganan Klaster Non-Globular |
Berkinerja baik pada klaster non-globular |
Kesulitan dengan bentuk non-globular |
|
Konsistensi Hasil |
Menghasilkan hasil yang konsisten antar-run |
Hasil dapat bervariasi karena inisialisasi centroid acak |
Untuk mengilustrasikan perbedaan ini, mari terapkan kedua algoritma pada dataset berbentuk bulan sabit kita
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
Kode ini menerapkan DBSCAN dan K-Means pada dataset kita dan memvisualisasikan hasilnya berdampingan.
Keluaran
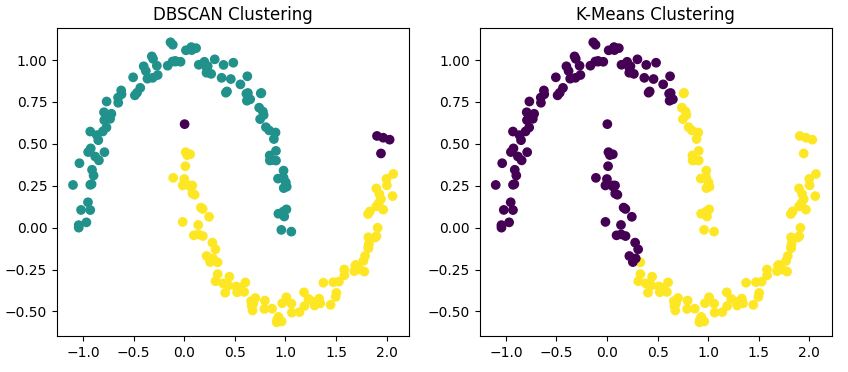
Anda akan melihat bahwa
Sekarang setelah kita melihat cara kerja DBSCAN dan membandingkannya dengan K-Means, mari lihat kapan DBSCAN adalah pilihan yang tepat untuk kebutuhan klastering kita. Sifat unik DBSCAN membuatnya sangat cocok untuk tipe data dan domain masalah tertentu.
Melanjutkan perbandingan sebelumnya, DBSCAN sangat unggul saat menangani bentuk klaster non-globular. Jika data Anda membentuk pola sebarang seperti bulan sabit yang kita bahas, DBSCAN kemungkinan mengungguli algoritma tradisional seperti K-Means.
Contohnya, dalam analisis geografis, formasi alami seperti sistem sungai atau perluasan kota sering membentuk bentuk tidak beraturan yang dapat diidentifikasi secara efektif oleh DBSCAN.
Salah satu keunggulan utama DBSCAN adalah kemampuannya menentukan jumlah klaster secara otomatis. Ini sangat berguna dalam analisis data eksploratori ketika Anda mungkin tidak memiliki pengetahuan sebelumnya tentang struktur dasar data Anda.
Pertimbangkan masalah segmentasi pasar: Anda mungkin tidak tahu sebelumnya berapa banyak kelompok pelanggan yang berbeda. DBSCAN dapat membantu mengungkap segmen ini tanpa mengharuskan Anda menebak jumlah klaster.
Pendekatan DBSCAN dalam menangani titik noise membuatnya tangguh terhadap outlier. Ini krusial dalam banyak dataset dunia nyata di mana kesalahan pengukuran atau anomali umum terjadi.
Misalnya, dalam sistem deteksi anomali untuk keamanan jaringan, DBSCAN dapat secara efektif memisahkan pola lalu lintas jaringan normal dari potensi ancaman keamanan.
Tidak seperti K-Means yang mengasumsikan klaster dengan kepadatan serupa, DBSCAN dapat mengidentifikasi klaster dengan kepadatan berbeda-beda. Ini sangat berguna ketika beberapa grup dalam data Anda lebih rapat daripada yang lain.
Contoh kasusnya adalah menganalisis distribusi galaksi dalam astronomi, di mana wilayah ruang berbeda memiliki kepadatan objek langit yang bervariasi.
Setelah mempelajari kapan menggunakan DBSCAN, mari lihat kelemahannya dan sekilas dua alternatifnya, OPTICS dan HDBSCAN.
Meskipun DBSCAN kuat, penting untuk menyadari keterbatasannya:
Untuk meningkatkan klastering, terapkan teknik reduksi dimensi seperti PCA, t-SNE, atau UMAP sebelum menggunakan DBSCAN. Ini mengurangi noise dan meningkatkan kemampuan algoritme mendeteksi wilayah padat.
Alternatif yang berguna untuk DBSCAN adalah OPTICS (Ordering Points To Identify the Clustering Structure). Metode ini mengatasi keterbatasan DBSCAN yang menggunakan nilai epsilon tetap dengan menyesuaikan ambang batas lingkungan secara dinamis.
OPTICS lebih efektif pada dataset dengan klaster berkepadatan berbeda dan dapat mengungkap struktur klaster yang mungkin terlewat oleh DBSCAN. Scikit-learn menyertakan OPTICS dalam modul klasteringnya, dan menggunakan antarmuka yang sama dengan DBSCAN.
HDBSCAN (Hierarchical DBSCAN) adalah perluasan modern dari DBSCAN yang membangun hierarki klaster berdasarkan tingkat kepadatan yang bervariasi. Metode ini menghilangkan kebutuhan memilih epsilon secara manual dan sering memberikan hasil lebih baik dengan penyetelan parameter yang lebih sedikit.
HDBSCAN cenderung mengungguli DBSCAN standar pada dataset dunia nyata yang bising atau tidak seimbang. Tersedia sebagai paket Python mandiri (hdbscan) dan terintegrasi baik dengan scikit-learn.
DBSCAN digunakan di berbagai domain.
Dalam sistem informasi geografis (GIS), DBSCAN dapat mengidentifikasi area dengan aktivitas atau minat tinggi. Misalnya, studi berjudul ‘Uncovering urban human mobility from large scale taxi GPS data’ menunjukkan bagaimana DBSCAN dapat mendeteksi hotspot perkotaan dari data GPS taksi.
Aplikasi ini menunjukkan kemampuan DBSCAN mengidentifikasi wilayah aktivitas padat dalam data spasial, yang penting untuk perencanaan kota dan manajemen transportasi.
DBSCAN dapat mengelompokkan piksel menjadi objek berbeda untuk tugas seperti pengenalan objek pada gambar. Sebuah studi berjudul 'Segmentation of Brain Tumour from MRI Image – Analysis of K-means and DBSCAN Clustering' menunjukkan efektivitas DBSCAN dalam analisis citra medis.
Para peneliti menggunakan DBSCAN untuk secara akurat melakukan segmentasi tumor otak pada hasil MRI, menunjukkan potensinya dalam diagnosis berbantuan komputer dan pencitraan medis.
Dalam deteksi penipuan atau pemantauan kesehatan sistem, DBSCAN dapat mengisolasi pola yang tidak biasa. Studi berjudul 'Efficient density and cluster-based incremental outlier detection in data streams' menunjukkan penerapan algoritma DBSCAN yang dimodifikasi untuk deteksi anomali secara real time.
Para peneliti menerapkan versi inkremental DBSCAN untuk mendeteksi outlier pada data streaming, yang memiliki potensi aplikasi dalam deteksi penipuan dan pemantauan kesehatan sistem.
Studi ini menunjukkan bagaimana DBSCAN dapat diadaptasi untuk mengidentifikasi pola tidak biasa dalam aliran data kontinu, kemampuan penting untuk sistem deteksi penipuan real time.
DBSCAN dapat mengelompokkan pengguna dengan preferensi serupa, membantu menghasilkan rekomendasi yang lebih akurat. Misalnya, studi berjudul "Multi-Cloud Based Service Recommendation System Using DBSCAN Algorithm" menunjukkan penerapan DBSCAN dalam meningkatkan collaborative filtering untuk sistem rekomendasi. Para peneliti menggunakan DBSCAN sebagai bagian dari pendekatan klastering untuk mengelompokkan pengguna berdasarkan preferensi dan penilaian film mereka, yang meningkatkan akurasi rekomendasi film.
Pendekatan ini menunjukkan bagaimana DBSCAN dapat meningkatkan rekomendasi yang dipersonalisasi di domain seperti layanan streaming hiburan.
DBSCAN adalah alat yang kuat dalam perangkat data scientist, sangat berharga saat menangani dataset yang kompleks dan bising di mana jumlah klaster tidak diketahui. Namun, seperti algoritma lainnya, ini bukan solusi serba guna.
Kunci klastering yang sukses terletak pada pemahaman data Anda, kekuatan dan keterbatasan berbagai algoritma, serta memilih alat yang tepat untuk tugasnya. Dalam banyak kasus, mencoba beberapa pendekatan klastering, termasuk DBSCAN dan K-Means, dan membandingkan hasilnya dapat memberikan wawasan berharga tentang struktur data Anda.
Dengan latihan dan pengalaman, Anda akan mengembangkan intuisi tentang kapan DBSCAN kemungkinan akan mengungkap pola tersembunyi dalam data Anda.
Anda dapat mempelajari lebih lanjut tentang berbagai teknologi dan metode yang dibahas dalam postingan ini di DataCamp melalui sumber berikut:
Kursus Teratas DataCamp
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
