Programma
Analista dati in Python
36 h
Nella data science e nel machine learning, la capacità di scoprire schemi nascosti e raggruppare punti dati simili è una competenza importante. Gli algoritmi di clustering svolgono un ruolo chiave in questo processo.
Il clustering è una tecnica fondamentale di machine learning e data science che consiste nel raggruppare tra loro punti dati simili. È un metodo di apprendimento non supervisionato, il che significa che non richiede dati etichettati per trovare pattern.
L'obiettivo principale del clustering è:
Sebbene esistano numerosi algoritmi di clustering (potresti aver sentito parlare di K-means o di clustering gerarchico), DBSCAN offre vantaggi unici. In quanto metodo basato sulla densità, DBSCAN ha diversi punti di forza:
In questo articolo vedremo cos'è l'algoritmo DBSCAN, come funziona, come implementarlo in Python e quando usarlo nei tuoi progetti di data science.
DBSCAN, acronimo di Density-Based Spatial Clustering of Applications with Noise, è un potente algoritmo di clustering che raggruppa i punti che sono addensati nello spazio dei dati. A differenza di altri algoritmi di clustering, DBSCAN non richiede di specificare in anticipo il numero di cluster, risultando particolarmente utile per l'analisi esplorativa dei dati.
L'algoritmo definisce i cluster come regioni dense separate da regioni a densità inferiore. Questo approccio consente a DBSCAN di scoprire cluster di forma arbitraria e identificare gli outlier come rumore.
DBSCAN ruota attorno a tre concetti chiave:
Immagine dell'autore
Il diagramma sopra illustra questi concetti. I punti core (blu) costituiscono il cuore dei cluster, i punti di bordo (arancione) sono ai margini dei cluster e i punti rumore (rosso) sono isolati.
DBSCAN utilizza due parametri principali:
Regolando questi parametri, puoi controllare come l'algoritmo definisce i cluster, consentendogli di adattarsi a diversi tipi di dataset ed esigenze di clustering.
Nella prossima sezione vedremo come funziona l'algoritmo DBSCAN, esplorando il suo processo passo dopo passo per identificare i cluster nei dati.
DBSCAN opera esaminando il vicinato di ciascun punto nel dataset. L'algoritmo segue un processo passo dopo passo per identificare i cluster in base alla densità dei punti dati. Vediamo come funziona DBSCAN:
Questo processo consente a DBSCAN di formare cluster di forme arbitrarie e identificare efficacemente gli outlier. La capacità dell'algoritmo di trovare cluster senza specificarne in anticipo il numero è uno dei suoi punti di forza.
È importante notare che la scelta di ε e MinPts può influenzare significativamente i risultati del clustering. Nella prossima sezione, vedremo come scegliere efficacemente questi parametri e introdurremo metodi come il grafico delle k-distanze per la selezione dei parametri.
Per comprendere appieno come DBSCAN forma i cluster, è importante conoscere due concetti chiave: raggiungibilità in densità e connettività in densità.
Un punto q è raggiungibile in densità da un punto p se:
1. p è un punto core (ha almeno MinPts entro la distanza ε)
2. Esiste una catena di punti p = p1, ..., pn = q dove ciascun pi+1 è direttamente raggiungibile in densità da pi.
In parole più semplici, puoi raggiungere q da p passando attraverso punti core, dove ogni passo non è più grande di ε.
Due punti p e q sono connessi in densità se esiste un punto o tale che sia p sia q siano raggiungibili in densità da o.
La connettività in densità è la base per la formazione dei cluster in DBSCAN. Tutti i punti in un cluster sono reciprocamente connessi in densità e, se un punto è connesso in densità a qualsiasi punto del cluster, appartiene anch'esso a quel cluster.
L'efficacia di DBSCAN dipende fortemente dalla scelta dei suoi due parametri principali: ε (epsilon) e MinPts. Ecco come affrontare la selezione di questi parametri:
Il parametro ε determina la distanza massima tra due punti affinché siano considerati vicini. Per scegliere un ε appropriato:
1. Usa la conoscenza del dominio: se hai un'idea di quale distanza sia significativa per il tuo problema specifico, usala come punto di partenza.
2. Grafico delle k-distanze: è un approccio più sistematico:
MinPts determina il numero minimo di punti richiesti per formare una regione densa. Ecco alcune linee guida:
1. Regola generale: un buon punto di partenza è impostare MinPts = 2 * num_features, dove num_features è il numero di dimensioni del tuo dataset.
2. Considerazione del rumore: se i tuoi dati presentano rumore o vuoi rilevare cluster più piccoli, potresti voler ridurre MinPts.
3. Dimensione del dataset: per dataset più grandi, potresti dover aumentare MinPts per evitare di creare troppi cluster piccoli.
Ricorda che la scelta dei parametri può influenzare significativamente i risultati. Spesso è utile sperimentare con valori diversi e valutare i cluster risultanti per trovare la soluzione migliore per il tuo dataset e problema specifico.
La scelta della metrica di distanza in DBSCAN può influenzare significativamente i risultati del clustering. Per impostazione predefinita, DBSCAN utilizza la distanza euclidea, che funziona bene per cluster compatti e sferici. Tuttavia, questo potrebbe non essere ideale per tutti i tipi di dati.
Puoi specificare metriche alternative, come:
Abbinare la metrica di distanza alla struttura dei tuoi dati garantisce che il clustering basato sulla densità rifletta una reale somiglianza.
In scikit-learn, il parametro metric ti consente di impostarlo in modo esplicito (ad es., metric='cosine'). Alcune metriche personalizzate potrebbero richiedere una matrice di distanza precomputata.
Poiché DBSCAN si basa su valori di distanza assoluti, feature non scalate possono portare a risultati distorti. Le variabili con range più ampi domineranno il calcolo della distanza, anche se non sono più importanti. Questo può impedire all'algoritmo di identificare correttamente le regioni dense nei dati.
Per evitarlo, è essenziale scalare le feature in modo che contribuiscano in egual misura. Approcci comuni includono:
Standardizzazione: centra le feature attorno allo zero con varianza unitaria usando StandardScaler.
Min-Max Scaling: riscalare le feature a un intervallo fisso (di solito [0, 1]) usando MinMaxScaler.
Scegli un metodo di scalatura che si adatti alla distribuzione dei tuoi dati. Senza un preprocessing adeguato, DBSCAN potrebbe non rilevare cluster significativi, anche se epsilon e MinPts sono ben calibrati.
In questa sezione vedremo l'implementazione di DBSCAN usando Python e la libreria scikit-learn. Useremo il dataset Make Moons per illustrare il processo.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsQueste importazioni forniscono gli strumenti necessari per la manipolazione dei dati, la visualizzazione, la creazione del dataset e l'implementazione dell'algoritmo DBSCAN.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)Questo codice crea un dataset sintetico usando la funzione make_moons di scikit-learn. Ecco una breve descrizione del dataset:
La funzione make_moons genera un dataset di classificazione binaria che ricorda due mezze lune intersecanti. Nel nostro caso:
n_samples=200)noise=0.05) per rendere il dataset più realisticorandom_state=42 per la riproducibilitàQuesto dataset è particolarmente utile per dimostrare DBSCAN perché:
Visualizziamo questo dataset per comprenderne meglio la struttura:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Questo mostrerà le due mezze lune intersecanti nel nostro dataset come sotto
Usiamo il metodo del grafico delle k-distanze per aiutare a scegliere un valore di epsilon appropriato:
plot_k_distance_graph che calcola la distanza dal k-esimo vicino più prossimo per ciascun punto.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Output
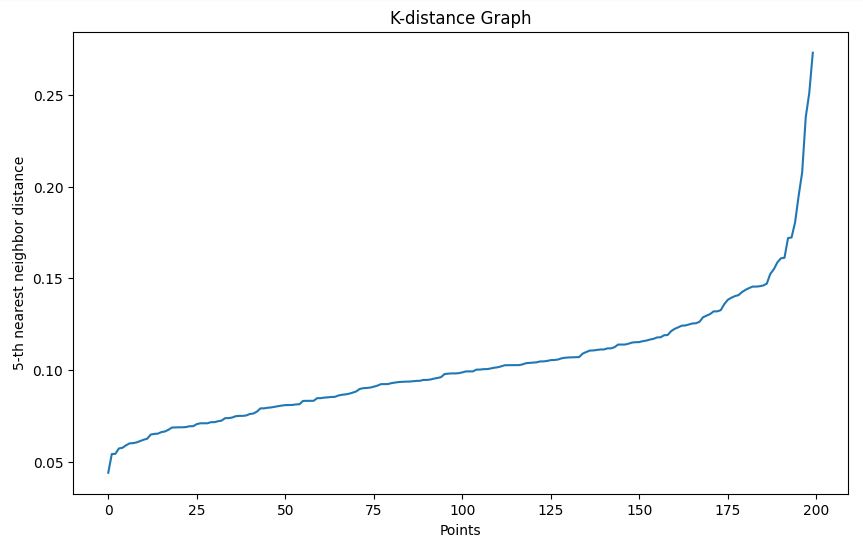
Nel nostro esempio, in base al grafico delle k-distanze, scegliamo un epsilon di 0,15.
Usiamo l'implementazione di DBSCAN di scikit-learn:
epsilon=0.15 in base al nostro grafico delle k-distanze.min_samples=5 (2 * num_features, poiché i nostri dati sono 2D).# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)Creiamo uno scatter plot dei nostri punti dati, colorandoli in base ai cluster assegnati. I punti classificati come rumore sono in genere colorati in modo diverso (spesso nero).
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Output
Infine, stampiamo il numero di cluster trovati e il numero di punti classificati come rumore. Questo ci fornisce un riepilogo rapido dei risultati del clustering.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Output
Number of clusters: 2
Number of noise points: 5
Questa implementazione fornisce un workflow completo dalla generazione dei dati all'interpretazione dei risultati. È importante notare che, in scenari reali, sostituiresti la generazione di dati di esempio con il caricamento e il preprocessing del tuo dataset effettivo.
Ricorda, la chiave per un clustering DBSCAN di successo spesso risiede in una selezione appropriata dei parametri. Non esitare a sperimentare diversi valori di epsilon e min_samples per trovare la soluzione migliore per il tuo dataset specifico.
Sebbene DBSCAN e K-Means siano entrambi algoritmi di clustering popolari, hanno caratteristiche distinte che li rendono adatti a diversi tipi di dati e casi d'uso. Confrontiamoli per capire quando usare l'uno o l'altro.
|
Caratteristica |
DBSCAN |
K-Means |
|
Forma dei cluster |
Può identificare cluster di forme arbitrarie |
Presuppone cluster convessi e approssimativamente sferici |
|
Numero di cluster |
Non richiede di specificare in anticipo il numero di cluster |
Richiede di specificare in anticipo il numero di cluster (K) |
|
Gestione degli outlier |
Identifica gli outlier come punti rumore |
Forza ogni punto in un cluster, potenzialmente distorcendo le forme dei cluster |
|
Sensibilità ai parametri |
Sensibile ai parametri epsilon e MinPts |
Sensibile alle posizioni iniziali dei centroidi e alla scelta di K |
|
Densità dei cluster |
Può trovare cluster con densità variabili |
Tende a trovare cluster con estensione spaziale e densità simili |
|
Scalabilità |
Meno efficiente per dataset di grandi dimensioni, specialmente con dati ad alta dimensionalità |
Generalmente più efficiente e scala meglio su grandi dataset |
|
Gestione di cluster non globulari |
Si comporta bene su cluster non globulari |
Fa fatica con forme non globulari |
|
Coerenza dei risultati |
Produce risultati coerenti tra le esecuzioni |
I risultati possono variare a causa dell'inizializzazione casuale dei centroidi |
Per illustrare queste differenze, applichiamo entrambi gli algoritmi al nostro dataset a forma di luna
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
Questo codice applica sia DBSCAN sia K-Means al nostro dataset e visualizza i risultati affiancati.
Output
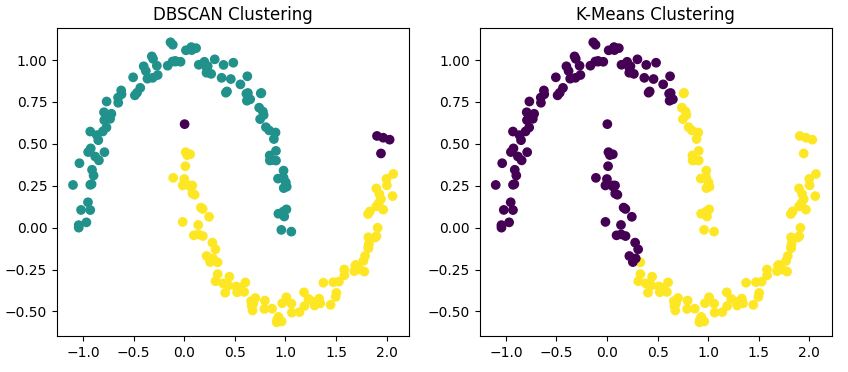
Noterai che
Ora che abbiamo visto come funziona DBSCAN e lo abbiamo confrontato con K-Means, vediamo quando DBSCAN è la scelta giusta per le nostre esigenze di clustering. Le proprietà uniche di DBSCAN lo rendono particolarmente adatto a determinati tipi di dati e domini applicativi.
Riprendendo il nostro confronto precedente, DBSCAN dà il meglio con forme di cluster non globulari. Se i tuoi dati formano pattern arbitrari come le mezze lune viste in precedenza, DBSCAN probabilmente supererà algoritmi tradizionali come K-Means.
Ad esempio, nelle analisi geografiche, conformazioni naturali come i sistemi fluviali o l'espansione urbana spesso formano forme irregolari che DBSCAN può identificare efficacemente.
Uno dei principali vantaggi di DBSCAN è la capacità di determinare automaticamente il numero di cluster. Questo è particolarmente utile nell'analisi esplorativa dei dati, quando potresti non avere conoscenza pregressa della struttura sottostante dei tuoi dati.
Considera un problema di segmentazione del mercato: potresti non sapere in anticipo quanti gruppi di clienti distinti esistono. DBSCAN può aiutare a scoprire questi segmenti senza richiederti di indovinare il numero di cluster.
L'approccio di DBSCAN alla gestione dei punti rumore lo rende robusto agli outlier. Questo è fondamentale in molti dataset reali, in cui errori di misurazione o anomalie sono comuni.
Per esempio, nei sistemi di rilevamento delle anomalie per la sicurezza di rete, DBSCAN può separare efficacemente i pattern di traffico normali dalle potenziali minacce alla sicurezza.
A differenza di K-Means, che presuppone cluster di densità simile, DBSCAN può identificare cluster con densità variabili. Ciò è particolarmente utile in scenari in cui alcuni gruppi nei tuoi dati sono più fitti di altri.
Un esempio potrebbe essere l'analisi della distribuzione delle galassie in astronomia, dove diverse regioni dello spazio hanno densità variabili di oggetti celesti.
Dopo aver visto quando usare DBSCAN, vediamo i suoi punti deboli e diamo uno sguardo a due alternative, OPTICS e HDBSCAN.
Sebbene DBSCAN sia potente, è importante essere consapevoli delle sue limitazioni:
Per migliorare il clustering, applica tecniche di riduzione della dimensionalità come PCA, t-SNE o UMAP prima di usare DBSCAN. Questo riduce il rumore e migliora la capacità dell'algoritmo di rilevare regioni dense.
Un'alternativa utile a DBSCAN è OPTICS (Ordering Points To Identify the Clustering Structure). Affronta la limitazione di DBSCAN di usare un valore di epsilon fisso regolando dinamicamente le soglie di vicinato.
OPTICS è più efficace su dataset con cluster di densità diversa e può rivelare strutture di cluster che DBSCAN potrebbe non cogliere. Scikit-learn include OPTICS nel suo modulo di clustering e utilizza la stessa interfaccia di DBSCAN.
HDBSCAN (Hierarchical DBSCAN) è un'estensione moderna di DBSCAN che costruisce una gerarchia di cluster basata su livelli di densità variabili. Elimina la necessità di scegliere manualmente epsilon e spesso fornisce risultati migliori con meno messa a punto dei parametri.
HDBSCAN tende a superare il DBSCAN classico su dataset reali, rumorosi o sbilanciati. È disponibile come pacchetto Python standalone (hdbscan) e si integra bene con scikit-learn.
DBSCAN trova applicazioni in vari domini.
Nei sistemi informativi geografici (GIS), DBSCAN può identificare aree di alta attività o interesse. Per esempio, uno studio intitolato ‘Uncovering urban human mobility from large scale taxi GPS data’ mostra come DBSCAN possa rilevare hotspot urbani dai dati GPS dei taxi.
Questa applicazione dimostra la capacità di DBSCAN di identificare regioni di attività densa nei dati spaziali, cruciale per la pianificazione urbana e la gestione dei trasporti.
DBSCAN può raggruppare i pixel in oggetti distinti per attività come il riconoscimento di oggetti nelle immagini. Uno studio intitolato "Segmentation of Brain Tumour from MRI Image – Analysis of K-means and DBSCAN Clustering" dimostra l'efficacia di DBSCAN nell'analisi di immagini mediche.
I ricercatori hanno utilizzato DBSCAN per segmentare accuratamente i tumori cerebrali nelle scansioni MRI, mostrando il suo potenziale nella diagnosi assistita dal computer e nell'imaging medico.
Nel rilevamento delle frodi o nel monitoraggio dello stato di salute dei sistemi, DBSCAN può isolare pattern insoliti. Uno studio intitolato "Efficient density and cluster-based incremental outlier detection in data streams" dimostra l'applicazione di una versione modificata dell'algoritmo DBSCAN per il rilevamento in tempo reale delle anomalie.
I ricercatori hanno applicato una versione incrementale di DBSCAN per rilevare outlier in dati in streaming, con potenziali applicazioni nel rilevamento delle frodi e nel monitoraggio dello stato dei sistemi.
Questo studio mostra come DBSCAN possa essere adattato per identificare pattern insoliti in flussi di dati continui, una capacità cruciale per i sistemi di rilevamento frodi in tempo reale.
DBSCAN può raggruppare utenti con preferenze simili, aiutando a generare raccomandazioni più accurate. Per esempio, uno studio intitolato "Multi-Cloud Based Service Recommendation System Using DBSCAN Algorithm" dimostra l'applicazione di DBSCAN nel migliorare il collaborative filtering per i sistemi di raccomandazione. I ricercatori hanno usato DBSCAN come parte di un approccio di clustering per raggruppare gli utenti in base alle preferenze e valutazioni dei film, migliorando l'accuratezza delle raccomandazioni.
Questo approccio mostra come DBSCAN possa migliorare le raccomandazioni personalizzate in ambiti come i servizi di streaming di intrattenimento.
DBSCAN è uno strumento potente nel kit del data scientist, particolarmente prezioso quando si lavora con dataset complessi e rumorosi in cui il numero di cluster è sconosciuto. Tuttavia, come ogni algoritmo, non è una soluzione universale.
La chiave per un clustering di successo sta nel comprendere i tuoi dati, i punti di forza e le limitazioni dei diversi algoritmi e scegliere lo strumento giusto per il lavoro. In molti casi, provare più approcci di clustering, tra cui DBSCAN e K-Means, e confrontarne i risultati può fornire preziose intuizioni sulla struttura dei tuoi dati.
Con la pratica e l'esperienza, svilupperai un'intuizione su quando DBSCAN può svelare i pattern nascosti nei tuoi dati.
Puoi approfondire le varie tecnologie e i metodi trattati in questo post su DataCamp con le seguenti risorse:
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

