Program
Veri Analisti Python'da
36 sa
Veri bilimi ve makine öğreniminde, gizli kalıpları ortaya çıkarma ve benzer veri noktalarını bir araya getirme becerisi önemli bir yetkinliktir. Kümeleme algoritmaları bu süreçte kilit rol oynar.
Kümeleme, benzer veri noktalarının bir araya getirilmesini içeren temel bir makine öğrenimi ve veri bilimi tekniğidir. Denetimsiz öğrenme yöntemidir; yani kalıpları bulmak için etiketli veriye ihtiyaç duymaz.
Kümelemenin başlıca hedefleri şunlardır:
Çok sayıda kümeleme algoritması varken (muhtemelen K-means veya hiyerarşik kümeleme duymuşsunuzdur), DBSCAN benzersiz avantajlar sunar. Yoğunluk temelli bir yöntem olarak DBSCAN’in çeşitli güçlü yönleri vardır:
Bu yazıda, DBSCAN algoritmasının ne olduğunu, nasıl çalıştığını, Python’da nasıl uygulanacağını ve veri bilimi projelerinizde ne zaman kullanılacağını inceleyeceğiz.
Gürültü ile Uygulamaların Yoğunluk Temelli Uzamsal Kümelemesi anlamına gelen DBSCAN, veri uzayında birbirine sıkı şekilde yakın olan noktaları gruplandıran güçlü bir kümeleme algoritmasıdır. Bazı diğer kümeleme algoritmalarının aksine, DBSCAN’dan önce küme sayısını belirtmeniz gerekmez; bu da onu özellikle keşif amaçlı veri analizi için kullanışlı kılar.
Algoritma, kümeleri düşük yoğunluklu bölgelerle ayrılmış yoğun bölgeler olarak tanımlayarak çalışır. Bu yaklaşım, DBSCAN’in keyfi şekillere sahip kümeleri keşfetmesine ve aykırı değerleri gürültü olarak tanımlamasına olanak tanır.
DBSCAN üç temel kavram etrafında döner:
Görsel: yazar
Yukarıdaki diyagram bu kavramları göstermektedir. Çekirdek noktalar (mavi) kümelerin kalbini oluşturur, sınır noktalar (turuncu) kümelerin kenarındadır ve gürültü noktaları (kırmızı) yalıtılmıştır.
DBSCAN iki ana parametre kullanır:
Bu parametreleri ayarlayarak algoritmanın kümeleri nasıl tanımladığını kontrol edebilir, farklı veri kümelerine ve kümeleme gereksinimlerine uyum sağlamasını sağlayabilirsiniz.
Bir sonraki bölümde, DBSCAN algoritmasının adım adım veri içinde kümeleri nasıl belirlediğini inceleyeceğiz.
DBSCAN, veri kümesindeki her noktanın komşuluğunu inceleyerek çalışır. Algoritma, veri noktalarının yoğunluğuna dayalı olarak kümeleri belirlemek için adım adım bir süreç izler. DBSCAN’in nasıl çalıştığını parçalayalım:
Bu süreç, DBSCAN’in keyfi şekillere sahip kümeler oluşturmasına ve aykırı değerleri etkili şekilde tanımlamasına olanak tanır. Küme sayısını önceden belirtme gereği olmaması, algoritmanın başlıca güçlü yönlerinden biridir.
ε ve MinPts seçiminin kümeleme sonuçlarını önemli ölçüde etkileyebileceğini not etmek gerekir. Bir sonraki bölümde bu parametreleri etkili biçimde nasıl seçeceğimizi ve k-mesafe grafiği gibi yöntemleri tanıtacağız.
DBSCAN’in kümeleri nasıl oluşturduğunu tam olarak kavramak için iki temel kavramı anlamak önemlidir: yoğunluk erişilebilirliği ve yoğunluk bağlantılılığı.
q noktası, şu koşullarda p noktasından yoğunlukça erişilebilir kabul edilir:
1. p bir çekirdek noktadır (ε uzaklığında en az MinPts vardır)
2. p = p1, ..., pn = q olacak şekilde, her pi+1 doğrudan pi.’den yoğunlukça erişilebilir bir noktadır.
Daha basit anlatımla, ε’i aşmayan adımlarla çekirdek noktalar üzerinden ilerleyerek p’den q’ya ulaşabilirsiniz.
p ve q iki noktası, her ikisinden de yoğunlukça erişilebilir oldukları bir o noktası varsa yoğunluk bağlantılıdır.
Yoğunluk bağlantılılığı, DBSCAN’de küme oluşturmanın temelidir. Bir kümedeki tüm noktalar karşılıklı olarak yoğunluk bağlantılıdır ve bir nokta kümedeki herhangi bir noktaya yoğunluk bağlantılıysa o kümeye de aittir.
DBSCAN’in etkinliği büyük ölçüde iki ana parametresinin seçimine bağlıdır: ε (epsilon) ve MinPts. Bu parametreleri seçmeye şöyle yaklaşabilirsiniz:
ε parametresi, iki noktanın komşu sayılması için aralarındaki azami mesafeyi belirler. Uygun bir ε seçmek için:
1. Alan bilgisi kullanın: Belirli probleminiz için anlamlı mesafeye dair sezginiz varsa, bunu başlangıç noktası olarak kullanın.
2. K-mesafe grafiği: Daha sistematik bir yaklaşımdır:
MinPts, yoğun bir bölge oluşturmak için gereken asgari nokta sayısını belirler. İşte bazı yönergeler:
1. Genel kural: İyi bir başlangıç noktası, MinPts = 2 * num_features olarak ayarlamaktır; burada num_features, veri kümenizdeki boyut sayısıdır.
2. Gürültü dikkate alınması: Verinizde gürültü varsa veya daha küçük kümeleri tespit etmek istiyorsanız, MinPts’i düşürmek isteyebilirsiniz.
3. Veri kümesi boyutu: Daha büyük veri kümeleri için, çok fazla küçük küme oluşmasını önlemek üzere MinPts’i artırmanız gerekebilir.
Unutmayın, parametre seçimi sonuçları önemli ölçüde etkiler. Farklı değerlerle denemeler yapmak ve ortaya çıkan kümeleri değerlendirerek belirli veri kümeniz ve probleminiz için en uygun ayarı bulmak genellikle faydalıdır.
DBSCAN’de uzaklık metriği seçimi, kümeleme sonuçlarını önemli ölçüde etkileyebilir. Varsayılan olarak DBSCAN Öklid uzaklığını kullanır; bu, kompakt, küresel kümeler için iyi çalışır. Ancak tüm veri tipleri için ideal olmayabilir.
Şu alternatif metrikleri belirtebilirsiniz:
Uzaklık metriğini verinizin yapısına uydurmak, yoğunluk temelli kümelemenin gerçek benzerliği yansıtmasını sağlar.
scikit-learn’de, metric parametresi bunu açıkça ayarlamanıza olanak tanır (ör., metric='cosine'). Bazı özel metrikler, önceden hesaplanmış bir mesafe matrisi gerektirebilir.
DBSCAN mutlak mesafe değerlerine dayandığından, ölçeklenmemiş özellikler çarpık sonuçlara yol açabilir. Daha geniş aralıklara sahip değişkenler, daha önemli olmasalar bile mesafe hesabına hükmeder. Bu, algoritmanın verideki yoğun bölgeleri doğru tanımlamasını engelleyebilir.
Bunu önlemek için, özelliklerinizi eşit katkı verecek şekilde ölçeklemek şarttır. Yaygın yaklaşımlar şunlardır:
Standardizasyon: StandardScaler kullanarak özellikleri sıfır etrafında birim varyansla merkezler.
Min-Maks Ölçekleme: MinMaxScaler kullanarak özellikleri sabit bir aralığa (genellikle [0, 1]) yeniden ölçeklendirir.
Özelliklerinizin dağılımına uyan bir ölçekleme yöntemi seçin. Uygun ön işleme olmadan, epsilon ve MinPts iyi ayarlanmış olsa bile DBSCAN anlamlı kümeleri tespit edemeyebilir.
Bu bölümde, Python ve scikit-learn kütüphanesini kullanarak DBSCAN’in nasıl uygulanacağını göreceğiz. Süreci göstermek için Make Moons veri kümesini kullanacağız.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsBu içe aktarmalar, veri işleme, görselleştirme, veri kümesi oluşturma ve DBSCAN algoritmasını uygulama için gerekli araçları sağlar.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)Bu kod, scikit-learn’ün make_moons fonksiyonunu kullanarak sentetik bir veri kümesi oluşturur. Veri kümesine ilişkin kısa bir açıklama:
make_moons fonksiyonu, birbirine geçen iki yarım ayı andıran ikili bir sınıflandırma veri kümesi üretir. Bizim örneğimizde:
n_samples=200)noise=0.05)random_state=42 ayarlıyoruzBu veri kümesi, DBSCAN’i göstermek için özellikle kullanışlıdır çünkü:
Yapısını daha iyi anlamak için bu veri kümesini görselleştirelim:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Bu, veri kümemizde birbirine geçen iki yarım ay şeklini aşağıda gösterildiği gibi gösterecektir
Uygun bir epsilon değeri seçmeye yardımcı olması için k-mesafe grafiği yöntemini kullanıyoruz:
plot_k_distance_graph fonksiyonunu tanımlıyoruz.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Çıktı
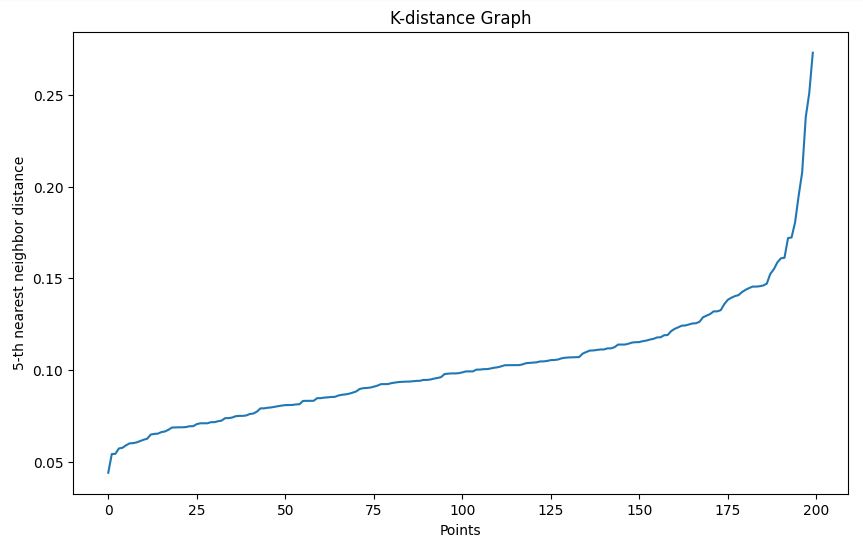
Örneğimizde, k-mesafe grafiğine dayanarak 0,15 epsilon seçiyoruz.
scikit-learn’ün DBSCAN uygulamasını kullanıyoruz:
epsilon=0.15 ayarlıyoruz.min_samples=5 (2 * num_features, verimiz 2B) ayarlıyoruz.# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)Veri noktalarımızın saçılım grafiğini oluşturuyor, atandıkları kümelere göre renklendiriyoruz. Gürültü olarak sınıflanan noktalar genellikle farklı (çoğunlukla siyah) renkle gösterilir.
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Çıktı
Son olarak, bulunan küme sayısını ve gürültü olarak sınıflanan nokta sayısını yazdırıyoruz. Bu, kümeleme sonuçlarının hızlı bir özetini verir.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Çıktı
Küme sayısı: 2
Gürültü noktası sayısı: 5
Bu uygulama, veri oluşturmadan sonuçların yorumlanmasına kadar eksiksiz bir iş akışı sunar. Gerçek dünyadaki senaryolarda, örnek veri oluşturma yerine kendi veri kümenizi yükleyip ön işleme tabi tutacağınızı belirtmek önemlidir.
Unutmayın, başarılı DBSCAN kümelemesinin anahtarı çoğunlukla uygun parametre seçimidir. Belirli veri kümeniz için en iyi uyumu bulmak amacıyla farklı epsilon ve min_samples değerleriyle denemekten çekinmeyin.
DBSCAN ve K-Means her ikisi de popüler kümeleme algoritmaları olsa da, farklı özelliklere sahiptir ve farklı veri türleri ve kullanım durumları için uygundur. Her birini ne zaman kullanmanız gerektiğini anlamak için bu iki algoritmayı karşılaştıralım.
|
Özellik |
DBSCAN |
K-Means |
|
Küme Şekli |
Keyfi şekillerde kümeleri tanımlayabilir |
Kümelerin dışbükey ve kabaca küresel olduğunu varsayar |
|
Küme Sayısı |
Küme sayısını önceden belirtmeyi gerektirmez |
Küme sayısının (K) önceden belirtilmesini gerektirir |
|
Aykırı Değerleri Ele Alma |
Aykırı değerleri gürültü noktaları olarak tanımlar |
Her noktayı bir kümeye zorlar; bu da küme şekillerini bozabilir |
|
Parametrelere Duyarlılık |
Epsilon ve MinPts parametrelerine duyarlıdır |
Başlangıç merkezlerine ve K seçimine duyarlıdır |
|
Küme Yoğunluğu |
Farklı yoğunluklardaki kümeleri bulabilir |
Benzer uzamsal kapsam ve yoğunlukta kümeler bulma eğilimindedir |
|
Ölçeklenebilirlik |
Özellikle yüksek boyutlu büyük veri kümeleri için daha az verimlidir |
Genellikle daha verimlidir ve büyük veri kümelerine daha iyi ölçeklenir |
|
Küresel Olmayan Kümeleri Ele Alma |
Küresel olmayan kümelerde iyi performans gösterir |
Küresel olmayan şekillerde zorlanır |
|
Sonuçların Tutarlılığı |
Çalıştırmalar arasında tutarlı sonuçlar üretir |
Merkezlerin rastgele başlatılmasından dolayı sonuçlar değişebilir |
Bu farklılıkları göstermek için her iki algoritmayı da yarım ay biçimli veri kümemize uygulayalım
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
Bu kod, hem DBSCAN’i hem de K-Means’i veri kümemize uygular ve sonuçları yan yana görselleştirir.
Çıktı
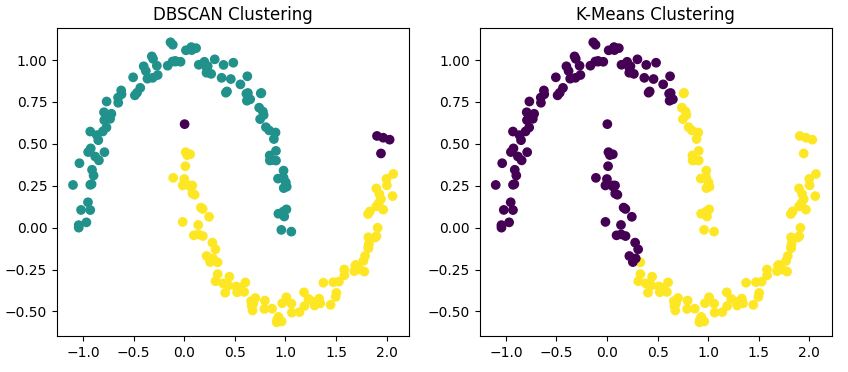
Şunları fark edeceksiniz
Artık DBSCAN’in nasıl çalıştığını gördüğümüze ve K-Means ile karşılaştırdığımıza göre, kümeleme ihtiyaçlarımız için DBSCAN’in hangi durumlarda doğru tercih olduğuna bakalım. DBSCAN’in benzersiz özellikleri onu belirli veri türleri ve problem alanları için özellikle uygun kılar.
Önceki karşılaştırmamız üzerine, DBSCAN küresel olmayan küme şekilleriyle uğraşırken gerçekten parlıyor. Veriniz, daha önce incelediğimiz yarım aylar gibi keyfi kalıplar oluşturuyorsa, DBSCAN büyük olasılıkla K-Means gibi geleneksel algoritmalardan daha iyi performans gösterecektir.
Örneğin coğrafi analizde, nehir sistemleri veya kentsel yayılma gibi doğal oluşumlar sıklıkla DBSCAN’in etkili biçimde tanımlayabildiği düzensiz şekiller oluşturur.
DBSCAN’in önemli avantajlarından biri, küme sayısını otomatik olarak belirleyebilmesidir. Bu, verinizin altında yatan yapıya dair ön bilginizin olmadığı keşif amaçlı veri analizinde özellikle faydalıdır.
Bir pazar segmentasyonu problemini düşünün: Kaç farklı müşteri grubunun var olduğunu önceden bilmiyor olabilirsiniz. DBSCAN, küme sayısını tahmin etmenize gerek kalmadan bu segmentleri ortaya çıkarmaya yardımcı olabilir.
DBSCAN’in gürültü noktalarını ele alma yaklaşımı, onu aykırı değerlere karşı dayanıklı kılar. Bu, ölçüm hataları veya anormalliklerin yaygın olduğu birçok gerçek dünya veri kümesinde kritik önemdedir.
Örneğin, ağ güvenliği için anomali tespit sistemlerinde DBSCAN, normal ağ trafiği kalıplarını olası güvenlik tehditlerinden etkili şekilde ayırabilir.
Kümelerin benzer yoğunlukta olduğunu varsayan K-Means’in aksine DBSCAN, değişen yoğunluklardaki kümeleri tanımlayabilir. Bu, verinizdeki bazı grupların diğerlerine göre daha sıkı paketlendiği durumlarda özellikle faydalıdır.
Örneğin astronomide galaksi dağılımlarını analiz ederken, uzayın farklı bölgelerinde gök cisimlerinin yoğunlukları değişkenlik gösterebilir.
DBSCAN’i ne zaman kullanacağımızı öğrendiğimize göre, şimdi de zayıf yönlerine bakalım ve OPTICS ile HDBSCAN gibi iki alternatife kısaca değinelim.
DBSCAN güçlü olmakla birlikte, şu sınırlamaların farkında olmak önemlidir:
Kümelemeyi iyileştirmek için, DBSCAN’den önce PCA, t-SNE veya UMAP gibi boyut indirgeme tekniklerini uygulayın. Bu, gürültüyü azaltır ve algoritmanın yoğun bölgeleri tespit etme kabiliyetini artırır.
DBSCAN’e yararlı bir alternatif, Kümeleme Yapısını Belirlemek İçin Noktaların Sıralanması (OPTICS)’tır. Sabit bir epsilon değeri kullanma sınırlamasını, komşuluk eşiklerini dinamik olarak ayarlayarak ele alır.
OPTICS, farklı yoğunluklara sahip kümelerin bulunduğu veri kümelerinde daha etkilidir ve DBSCAN’in kaçırabileceği küme yapılarını ortaya çıkarabilir. Scikit-learn, kümeleme modülünde OPTICS’i içerir ve DBSCAN ile aynı arayüzü kullanır.
HDBSCAN (Hiyerarşik DBSCAN), değişen yoğunluk seviyelerine göre bir küme hiyerarşisi oluşturan DBSCAN’in modern bir uzantısıdır. Epsilon’u elle seçme ihtiyacını ortadan kaldırır ve sıklıkla daha az parametre ayarıyla daha iyi sonuçlar verir.
HDBSCAN, gerçek dünya, gürültülü veya dengesiz veri kümelerinde klasik DBSCAN’den genellikle daha iyi performans gösterir. Bağımsız bir Python paketi (hdbscan) olarak mevcuttur ve scikit-learn ile iyi entegre olur.
DBSCAN, çeşitli alanlarda uygulama bulur.
Coğrafi bilgi sistemlerinde (GIS) DBSCAN, yüksek etkinlik veya ilgi alanlarını belirleyebilir. Örneğin, ‘Uncovering urban human mobility from large scale taxi GPS data’ başlıklı bir çalışma, DBSCAN’in taksi GPS verilerinden kentsel sıcak noktaları nasıl tespit edebildiğini gösterir.
Bu uygulama, DBSCAN’in mekansal verilerde yoğun etkinlik bölgelerini belirleme yeteneğini sergiler; bu da kentsel planlama ve ulaşım yönetimi için kritiktir.
DBSCAN, nesne tanıma gibi görevler için pikselleri ayrı nesnelere gruplayabilir. 'Segmentation of Brain Tumour from MRI Image – Analysis of K-means and DBSCAN Clustering' başlıklı bir çalışma, DBSCAN’in tıbbi görüntü analizindeki etkinliğini göstermektedir.
Araştırmacılar, MRI taramalarında beyin tümörlerini doğru şekilde bölütlemek için DBSCAN’i kullanmış; bu da bilgisayar destekli tanı ve tıbbi görüntülemedeki potansiyelini ortaya koymuştur.
Dolandırıcılık tespiti veya sistem sağlık izleme gibi alanlarda DBSCAN, alışılmadık kalıpları izole edebilir. 'Efficient density and cluster-based incremental outlier detection in data streams' başlıklı çalışma, gerçek zamanlı anomali tespiti için değiştirilmiş bir DBSCAN algoritmasının uygulanmasını göstermektedir.
Araştırmacılar, akış verilerinde aykırı değerleri tespit etmek için DBSCAN’in artımlı bir sürümünü uygulamış; bu da dolandırıcılık tespiti ve sistem sağlık izleme için potansiyel uygulamalara sahiptir.
Bu çalışma, DBSCAN’in sürekli veri akışlarında alışılmadık kalıpları belirlemek üzere nasıl uyarlanabileceğini; bunun da gerçek zamanlı dolandırıcılık tespit sistemleri için kritik bir yetenek olduğunu ortaya koyar.
DBSCAN, benzer tercihlere sahip kullanıcıları gruplayarak daha doğru öneriler üretmeye yardımcı olabilir. Örneğin, "Multi-Cloud Based Service Recommendation System Using DBSCAN Algorithm" başlıklı çalışma, öneri sistemlerinde işbirlikçi filtrelemeyi iyileştirmede DBSCAN’in uygulanışını göstermektedir. Araştırmacılar, kullanıcıları film tercihleri ve puanlarına göre gruplamak için DBSCAN’i bir kümeleme yaklaşımının parçası olarak kullanmış ve film önerilerinin doğruluğunu artırmıştır.
Bu yaklaşım, DBSCAN’in eğlence yayın servisleri gibi alanlarda kişiselleştirilmiş önerileri nasıl güçlendirebileceğini gösterir.
DBSCAN, veri bilimcisinin araç setinde güçlü bir araçtır; özellikle küme sayısının bilinmediği, karmaşık ve gürültülü veri kümeleriyle uğraşırken değerlidir. Ancak her algoritma gibi, her duruma uyan tek çözüm değildir.
Başarılı kümelemenin anahtarı, verinizi, farklı algoritmaların güçlü ve zayıf yönlerini anlamakta ve işe uygun doğru aracı seçmektedir. Çoğu durumda, DBSCAN ve K-Means de dahil olmak üzere birden fazla kümeleme yaklaşımını denemek ve sonuçlarını karşılaştırmak, verinizin yapısına dair değerli içgörüler sağlayabilir.
Pratik ve deneyimle, DBSCAN’in verinizdeki gizli kalıpları ne zaman ortaya çıkarabileceğine dair bir sezgi geliştireceksiniz.
Bu yazıda ele aldığımız çeşitli teknoloji ve yöntemler hakkında daha fazla bilgiyi DataCamp’te şu kaynaklarda bulabilirsiniz:
En Popüler DataCamp Kursları
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
