Leerpad
Data-analist in Python
36 Hr
In data science en machine learning is het vermogen om verborgen patronen te ontdekken en vergelijkbare datapunten te groeperen een belangrijke vaardigheid. Clusteringalgoritmen spelen hierbij een sleutelrol.
Clustering is een fundamentele techniek in machine learning en data science waarbij vergelijkbare datapunten worden gegroepeerd. Het is een vorm van unsupervised learning, wat betekent dat er geen gelabelde data nodig is om patronen te vinden.
Het primaire doel van clustering is om:
Hoewel er talloze clusteringalgoritmen zijn (je hebt misschien gehoord van K-means of hiërarchische clustering), biedt DBSCAN unieke voordelen. Als dichtheidsgebaseerde methode heeft DBSCAN verschillende sterke punten:
In dit artikel bekijken we wat het DBSCAN-algoritme is, hoe DBSCAN werkt, hoe je het in Python implementeert en wanneer je het gebruikt in je data science-projecten.
DBSCAN, wat staat voor Density-Based Spatial Clustering of Applications with Noise, is een krachtig clusteringalgoritme dat punten groepeert die dicht bij elkaar liggen in de dataspace. In tegenstelling tot sommige andere clusteringalgoritmen hoef je bij DBSCAN het aantal clusters niet van tevoren op te geven, wat het bijzonder nuttig maakt voor verkennende data-analyse.
Het algoritme definieert clusters als dichte regio's die gescheiden zijn door gebieden met lagere dichtheid. Deze aanpak stelt DBSCAN in staat clusters met willekeurige vormen te ontdekken en uitschieters als ruis te identificeren.
DBSCAN draait om drie kernbegrippen:
Afbeelding door de auteur
Het diagram hierboven illustreert deze concepten. Kernpunten (blauw) vormen de kern van clusters, randpunten (oranje) zitten aan de rand van clusters en ruispunten (rood) staan op zichzelf.
DBSCAN gebruikt twee hoofdparameters:
Door deze parameters aan te passen, kun je sturen hoe het algoritme clusters definieert, zodat het zich kan aanpassen aan verschillende soorten datasets en clusteringeisen.
In de volgende sectie bekijken we hoe het DBSCAN-algoritme werkt en lopen we stap voor stap door het proces om clusters in data te identificeren.
DBSCAN werkt door de buurt van elk punt in de dataset te onderzoeken. Het algoritme volgt een stapsgewijs proces om clusters te identificeren op basis van de dichtheid van datapunten. Zo werkt DBSCAN:
Dit proces stelt DBSCAN in staat om clusters met willekeurige vormen te vormen en uitschieters effectief te identificeren. Het vermogen om clusters te vinden zonder het aantal clusters vooraf te specificeren is een van de belangrijkste sterke punten.
Het is belangrijk om te weten dat de keuze van ε en MinPts de clusteringresultaten sterk kan beïnvloeden. In de volgende sectie bespreken we hoe je deze parameters effectief kiest en introduceren we methoden zoals de k-afstandsgrafiek voor parameterselectie.
Om volledig te begrijpen hoe DBSCAN clusters vormt, is het belangrijk om twee kernconcepten te kennen: dichtheidsbereikbaarheid en dichtheidsconnectiviteit.
Een punt q is dichtheids-bereikbaar vanaf een punt p als:
1. p een kernpunt is (heeft minstens MinPts binnen ε afstand)
2. Er een keten van punten is p = p1, ..., pn = q waarbij elk pi+1 direct dichtheids-bereikbaar is vanaf pi.
Simpeler gezegd: je kunt q bereiken vanaf p door via kernpunten te stappen, waarbij elke stap niet groter is dan ε.
Twee punten p en q zijn dichtheids-verbonden als er een punt o bestaat zodanig dat zowel p als q dichtheids-bereikbaar zijn vanaf o.
Dichtheidsconnectiviteit is de basis voor het vormen van clusters in DBSCAN. Alle punten in een cluster zijn onderling dichtheids-verbonden, en als een punt dichtheids-verbonden is met een willekeurig punt in het cluster, behoort het ook tot dat cluster.
De effectiviteit van DBSCAN hangt sterk af van de keuze van de twee hoofdparameters: ε (epsilon) en MinPts. Zo pak je de selectie van deze parameters aan:
De ε-parameter bepaalt de maximale afstand tussen twee punten om ze als buren te beschouwen. Om een geschikte ε te kiezen:
1. Gebruik domeinkennis: Als je inzicht hebt in welke afstand betekenisvol is voor jouw specifieke probleem, gebruik dat als startpunt.
2. K-afstandsgrafiek: Dit is een meer systematische aanpak:
MinPts bepaalt het minimumaantal punten dat nodig is om een dichte regio te vormen. Richtlijnen:
1. Algemene vuistregel: Een goed startpunt is MinPts = 2 * num_features, waarbij num_features het aantal dimensies in je dataset is.
2. Ruisoverweging: Als je data ruis bevat of je kleinere clusters wilt detecteren, kun je MinPts verlagen.
3. Datasetgrootte: Voor grotere datasets moet je mogelijk MinPts verhogen om te voorkomen dat er te veel kleine clusters ontstaan.
Onthoud dat de keuze van parameters de resultaten sterk kan beïnvloeden. Het is vaak zinvol om met verschillende waarden te experimenteren en de resulterende clusters te evalueren om de beste fit voor jouw dataset en probleem te vinden.
De keuze van de afstandsmaat in DBSCAN kan de clusteringresultaten aanzienlijk beïnvloeden. Standaard gebruikt DBSCAN Euclidische afstand, wat goed werkt voor compacte, bolvormige clusters. Dit is echter niet voor alle datatypes ideaal.
Je kunt alternatieve maten opgeven, zoals:
Door de afstandsmaat af te stemmen op de structuur van je data zorg je ervoor dat dichtheidsgebaseerde clustering echte gelijkenis weerspiegelt.
In scikit-learn kun je dit expliciet instellen met de parameter metric (bijv. metric='cosine'). Voor sommige aangepaste maten is een vooraf berekende afstandsmatrix nodig.
Omdat DBSCAN op absolute afstandswaarden vertrouwt, kunnen ongeschaalde features tot vertekende resultaten leiden. Variabelen met grotere bereiken domineren de afstandsberekening, ook als ze niet belangrijker zijn. Dit kan voorkomen dat het algoritme dichte regio's in de data correct identificeert.
Om dit te voorkomen is het essentieel je features te schalen zodat ze gelijk bijdragen. Veelgebruikte aanpakken zijn:
Standaardisering: Centreert features rond nul met variantie 1 met StandardScaler.
Min-max-scaling: Schaal features naar een vast bereik (meestal [0, 1]) met MinMaxScaler.
Kies een schaalmethode die past bij de verdeling van je data. Zonder goede preprocessing kan DBSCAN geen betekenisvolle clusters detecteren—zelfs als je epsilon en MinPts goed zijn afgesteld.
In deze sectie bekijken we de implementatie van DBSCAN met Python en de scikit-learn-bibliotheek. We gebruiken de Make Moons-dataset om het proces te demonstreren.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsDeze imports bieden de benodigde tools voor datamanipulatie, visualisatie, het maken van een dataset en het implementeren van het DBSCAN-algoritme.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)Deze code creëert een synthetische dataset met de make_moons-functie uit scikit-learn. Hier is een korte beschrijving van de dataset:
De make_moons-functie genereert een binaire classificatiedataset die lijkt op twee in elkaar grijpende halve manen. In ons geval:
n_samples=200)noise=0.05) om de dataset realistischer te makenrandom_state=42 voor reproduceerbaarheidDeze dataset is bijzonder geschikt om DBSCAN te demonstreren omdat:
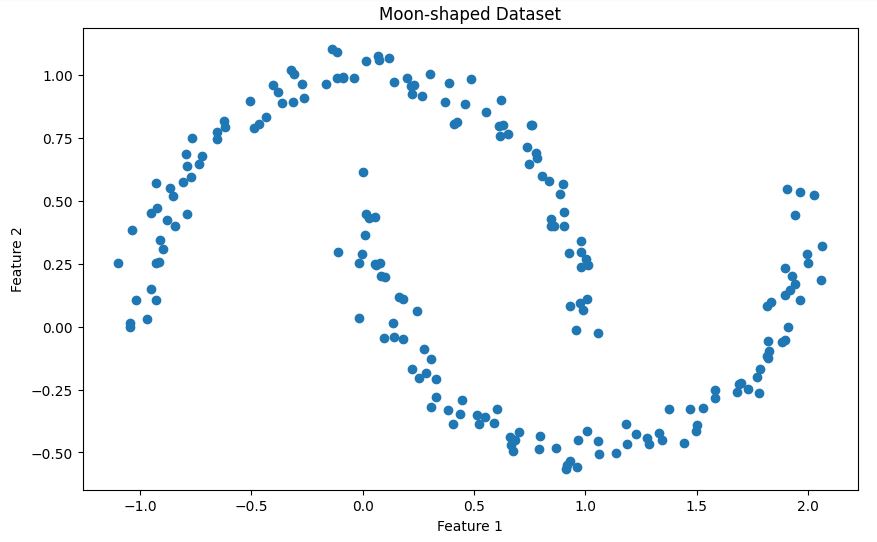
Laten we deze dataset visualiseren om de structuur beter te begrijpen:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Dit laat je de twee in elkaar grijpende halve manen in onze dataset zien, zoals hieronder weergegeven
We gebruiken de k-afstandsgrafiek om een geschikte epsilonwaarde te kiezen:
plot_k_distance_graph die voor elk punt de afstand tot de k-de naaste buur berekent.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Output
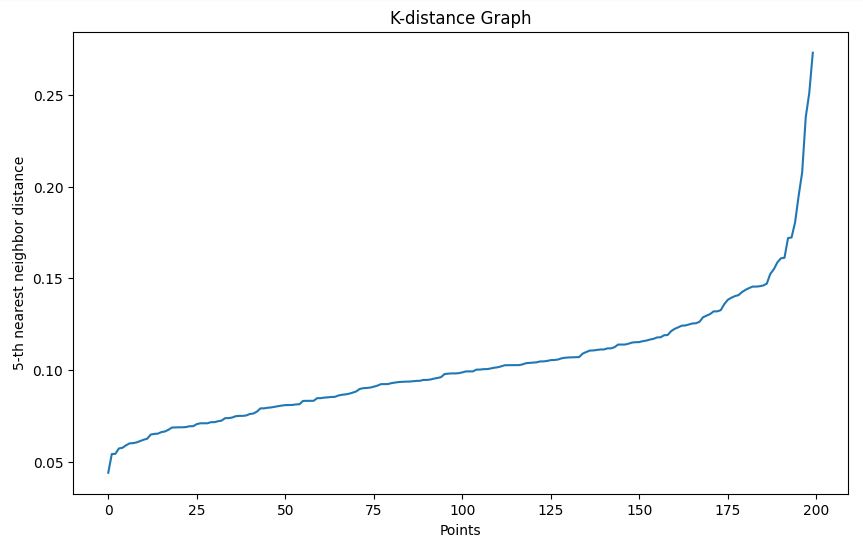
In ons voorbeeld kiezen we op basis van de k-afstandsgrafiek een epsilon van 0,15.
We gebruiken de DBSCAN-implementatie van scikit-learn:
epsilon=0.15 in op basis van onze k-afstandsgrafiek.min_samples=5 in (2 * num_features, omdat onze data 2D is).# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)We maken een scatterplot van onze datapunten en kleuren ze volgens hun toegewezen clusters. Punten die als ruis zijn geclassificeerd, krijgen doorgaans een andere kleur (vaak zwart).
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Output
Tot slot printen we het aantal gevonden clusters en het aantal punten dat als ruis is geclassificeerd. Dit geeft snel een samenvatting van de clusteringresultaten.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Output
Aantal clusters: 2
Aantal ruispunten: 5
Deze implementatie biedt een complete workflow van datageneratie tot het interpreteren van de resultaten. In echte situaties vervang je de gegenereerde voorbeelddata door het laden en preprocessen van je eigen dataset.
Onthoud dat succesvolle DBSCAN-clustering vaak draait om de juiste parameterkeuze. Experimenteer gerust met verschillende epsilon- en min_samples-waarden om de beste fit voor jouw dataset te vinden.
Hoewel DBSCAN en K-Means beide populaire clusteringalgoritmen zijn, hebben ze verschillende kenmerken die ze geschikt maken voor uiteenlopende data en use-cases. Laten we deze twee algoritmen vergelijken om te begrijpen wanneer je welke gebruikt.
|
Kenmerk |
DBSCAN |
K-Means |
|
Clustervorm |
Kan clusters van willekeurige vormen identificeren |
Gaat uit van convexe, grofweg bolvormige clusters |
|
Aantal clusters |
Vereist niet dat het aantal clusters vooraf wordt opgegeven |
Vereist dat het aantal clusters (K) vooraf wordt gespecificeerd |
|
Omgaan met uitschieters |
Identificeert uitschieters als ruispunten |
Dwingt elk punt in een cluster, wat de clustervormen kan vertekenen |
|
Gevoeligheid voor parameters |
Gevoelig voor de parameters epsilon en MinPts |
Gevoelig voor initiële centroidposities en de keuze van K |
|
Clusterdichtheid |
Kan clusters met uiteenlopende dichtheden vinden |
Vindt eerder clusters met vergelijkbare omvang en dichtheid |
|
Schaalbaarheid |
Minder efficiënt voor zeer grote datasets, vooral bij hoge dimensionaliteit |
Over het algemeen efficiënter en schaalbaarder naar grote datasets |
|
Omgaan met niet-globulaire clusters |
Presteert goed op niet-globulaire clusters |
Heeft moeite met niet-globulaire vormen |
|
Consistentie van resultaten |
Levert consistente resultaten over runs heen |
Resultaten kunnen variëren door willekeurige initialisatie van centroiden |
Om deze verschillen te illustreren passen we beide algoritmen toe op onze maanvormige dataset
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
Deze code past zowel DBSCAN als K-Means toe op onze dataset en visualiseert de resultaten naast elkaar.
Output
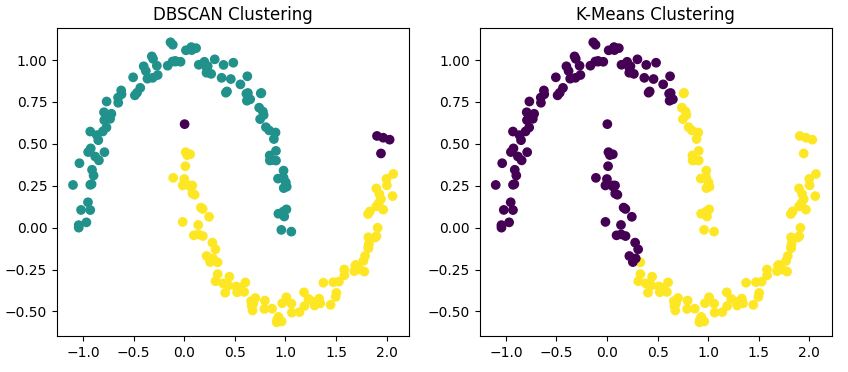
Je zult merken dat
Nu we hebben gezien hoe DBSCAN werkt en hoe het zich verhoudt tot K-Means, kijken we wanneer DBSCAN de juiste keuze is voor je clusteringbehoeften. De unieke eigenschappen van DBSCAN maken het bijzonder geschikt voor bepaalde soorten data en probleemdomeinen.
Aansluitend op onze eerdere vergelijking blinkt DBSCAN echt uit bij niet-globulaire clustervormen. Als je data willekeurige patronen vormt, zoals de halve manen die we hebben bekeken, zal DBSCAN waarschijnlijk beter presteren dan traditionele algoritmen zoals K-Means.
In geografische analyses vormen natuurlijke patronen zoals riviersystemen of stedelijke uitwaaiering vaak onregelmatige vormen die DBSCAN effectief kan identificeren.
Een van de belangrijkste voordelen van DBSCAN is dat het het aantal clusters automatisch kan bepalen. Dit is vooral handig bij verkennende data-analyse, waar je mogelijk geen voorkennis hebt over de onderliggende structuur van je data.
Neem marktsegmentatie: je weet vooraf misschien niet hoeveel verschillende klantgroepen er zijn. DBSCAN kan deze segmenten blootleggen zonder dat je het aantal clusters hoeft te raden.
DBSCAN's aanpak voor ruispunten maakt het robuust tegen uitschieters. Dit is cruciaal in veel real-world datasets waarin meetfouten of anomalieën vaak voorkomen.
Bijvoorbeeld in anomaliedetectie voor netwerkbeveiliging kan DBSCAN normale netwerkverkeerspatronen effectief scheiden van mogelijke bedreigingen.
In tegenstelling tot K-Means, dat uitgaat van clusters met vergelijkbare dichtheid, kan DBSCAN clusters met verschillende dichtheden identificeren. Dit is vooral nuttig wanneer sommige groepen in je data dichter op elkaar zitten dan andere.
Een voorbeeld is het analyseren van sterrenstelseldistributies in de astronomie, waar verschillende regio's in de ruimte uiteenlopende dichtheden aan hemelobjecten hebben.
Nu we weten wanneer je DBSCAN gebruikt, kijken we naar de zwakke punten en kort naar twee alternatieven: OPTICS en HDBSCAN.
Hoewel DBSCAN krachtig is, is het belangrijk om je bewust te zijn van de beperkingen:
Voor betere clustering kun je techniek(en) voor dimensionaliteitsreductie toepassen, zoals PCA, t-SNE of UMAP voordat je DBSCAN gebruikt. Dit vermindert ruis en verbetert het vermogen van het algoritme om dichte regio's te detecteren.
Een nuttig alternatief voor DBSCAN is OPTICS (Ordering Points To Identify the Clustering Structure). Het pakt de beperking van DBSCAN aan om een vaste epsilonwaarde te gebruiken door de buurtdrempels dynamisch aan te passen.
OPTICS is effectiever op datasets met clusters van verschillende dichtheden en kan clusterstructuren onthullen die DBSCAN kan missen. Scikit-learn bevat OPTICS in zijn clusteringmodule en gebruikt dezelfde interface als DBSCAN.
HDBSCAN (Hierarchische DBSCAN) is een moderne uitbreiding van DBSCAN die een hiërarchie van clusters opbouwt op basis van variërende dichtheidsniveaus. Het haalt de noodzaak weg om epsilon handmatig te kiezen en levert vaak betere resultaten met minder afstemming.
HDBSCAN presteert vaak beter dan de standaard DBSCAN op realistische, rumoerige of onevenwichtige datasets. Het is beschikbaar als een losstaande Python-package (hdbscan) en integreert goed met scikit-learn.
DBSCAN vindt toepassingen in diverse domeinen.
In geografische informatiesystemen (GIS) kan DBSCAN gebieden met hoge activiteit of interesse identificeren. Zo laat een studie met de titel ‘Uncovering urban human mobility from large scale taxi GPS data’ zien hoe DBSCAN stedelijke hotspots kan detecteren uit taxi-GPS-data.
Deze toepassing toont het vermogen van DBSCAN om dichte activiteitsregio's in ruimtelijke data te identificeren, cruciaal voor stedelijke planning en verkeersmanagement.
DBSCAN kan pixels groeperen tot afzonderlijke objecten voor taken zoals objectherkenning in afbeeldingen. Een studie met de titel 'Segmentation of Brain Tumour from MRI Image – Analysis of K-means and DBSCAN Clustering' toont de effectiviteit van DBSCAN in medische beeldanalyse.
De onderzoekers gebruikten DBSCAN om hersentumoren in MRI-scans nauwkeurig te segmenteren, wat de potentie laat zien voor computerondersteunde diagnose en medische beeldvorming.
Bij fraudedetectie of monitoring van systeemgezondheid kan DBSCAN ongebruikelijke patronen isoleren. Een studie met de titel 'Efficient density and cluster-based incremental outlier detection in data streams' toont de toepassing van een aangepaste DBSCAN-variant voor realtime anomaliedetectie.
De onderzoekers pasten een incrementele versie van DBSCAN toe om uitschieters in streamingdata te detecteren, met potentiële toepassingen in fraudedetectie en monitoring van systeemgezondheid.
Deze studie laat zien hoe DBSCAN kan worden aangepast om ongebruikelijke patronen in continue datastromen te identificeren, een cruciale eigenschap voor realtime fraudedetectiesystemen.
DBSCAN kan gebruikers met vergelijkbare voorkeuren groeperen en zo nauwkeurigere aanbevelingen helpen genereren. Zo toont een studie met de titel "Multi-Cloud Based Service Recommendation System Using DBSCAN Algorithm" de toepassing van DBSCAN bij het verbeteren van collaborative filtering voor aanbevelingssystemen. De onderzoekers gebruikten DBSCAN als onderdeel van een clusteringaanpak om gebruikers te groeperen op basis van hun filmvoorkeuren en -beoordelingen, wat de nauwkeurigheid van filmaanbevelingen verbeterde.
Deze aanpak laat zien hoe DBSCAN gepersonaliseerde aanbevelingen kan versterken in domeinen zoals streamingdiensten.
DBSCAN is een krachtig hulpmiddel in de toolkit van de data scientist, vooral waardevol bij complexe, rumoerige datasets waarbij het aantal clusters onbekend is. Maar zoals elk algoritme is het geen one-size-fits-all-oplossing.
Succesvolle clustering draait om het begrijpen van je data, de sterke en zwakke punten van verschillende algoritmen en het kiezen van het juiste gereedschap voor de klus. In veel gevallen levert het uitproberen van meerdere clusteringbenaderingen, waaronder DBSCAN en K-Means, en het vergelijken van de resultaten waardevolle inzichten op in de structuur van je data.
Met oefening en ervaring ontwikkel je een intuïtie voor wanneer DBSCAN de verborgen patronen in je data zal onthullen.
Je kunt meer leren over de verschillende technologieën en methoden die we in deze post hebben behandeld op DataCamp met de volgende resources:
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
