Track
Data Analyst in Python
36 hr
In data science and machine learning, the ability to uncover hidden patterns and group similar data points is an important skill. Clustering algorithms play a key role in this process.
Clustering is a fundamental machine learning and data science technique that involves grouping similar data points together. It's an unsupervised learning method, meaning it doesn't require labeled data to find patterns.
The primary goal of clustering is to:
While there are numerous clustering algorithms (you might have heard of K-means or hierarchical clustering), DBSCAN offers unique advantages. As a density-based method, DBSCAN has several strengths:
In this article, we'll look at what the DBSCAN algorithm is, how DBSCAN works, how to implement it in Python, and when to use it in your data science projects.
DBSCAN, which stands for Density-Based Spatial Clustering of Applications with Noise, is a powerful clustering algorithm that groups points that are closely packed together in data space. Unlike some other clustering algorithms, DBSCAN doesn't require you to specify the number of clusters beforehand, making it particularly useful for exploratory data analysis.
The algorithm works by defining clusters as dense regions separated by regions of lower density. This approach allows DBSCAN to discover clusters of arbitrary shape and identify outliers as noise.
DBSCAN revolves around three key concepts:
Image by author
The diagram above illustrates these concepts. Core points (blue) form the heart of clusters, border points (orange) are on the edge of clusters, and noise points (red) are isolated.
DBSCAN uses two main parameters:
By adjusting these parameters, you can control how the algorithm defines clusters, allowing it to adapt to different types of datasets and clustering requirements.
In the next section, we'll look at how the DBSCAN algorithm works, exploring its step-by-step process for identifying clusters in data.
DBSCAN operates by examining the neighborhood of each point in the dataset. The algorithm follows a step-by-step process to identify clusters based on the density of data points. Let's break down how DBSCAN works:
This process allows DBSCAN to form clusters of arbitrary shapes and identify outliers effectively. The algorithm's ability to find clusters without specifying the number of clusters beforehand is one of its key strengths.
It's important to note that the choice of ε and MinPts can significantly affect the clustering results. In the next section, we'll discuss how to choose these parameters effectively and introduce methods like the k-distance graph for parameter selection.
To fully grasp how DBSCAN forms clusters, it's important to understand two key concepts: density reachability and density connectivity.
A point q is density-reachable from a point p if:
1. p is a core point (has at least MinPts within ε distance)
2. There is a chain of points p = p1, ..., pn = q where each pi+1 is directly density-reachable from pi.
In simpler terms, you can reach q from p by stepping through core points, where each step is no larger than ε.
Two points p and q are density-connected if there exists a point o such that both p and q are density-reachable from o.
Density connectivity is the basis for forming clusters in DBSCAN. All points in a cluster are mutually density-connected, and if a point is density-connected to any point in the cluster, it also belongs to that cluster.
The effectiveness of DBSCAN heavily depends on the choice of its two main parameters: ε (epsilon) and MinPts. Here's how to approach selecting these parameters:
The ε parameter determines the maximum distance between two points for them to be considered neighbors. To choose an appropriate ε:
1. Use domain knowledge: If you have insight into what distance is meaningful for your specific problem, use that as a starting point.
2. K-distance graph: This is a more systematic approach:
MinPts determines the minimum number of points required to form a dense region. Here are some guidelines:
1. General rule: A good starting point is to set MinPts = 2 * num_features, where num_features is the number of dimensions in your dataset.
2. Noise consideration: If your data has noise or you want to detect smaller clusters, you might want to decrease MinPts.
3. Dataset size: For larger datasets, you might need to increase MinPts to avoid creating too many small clusters.
Remember, the choice of parameters can significantly affect the results. It's often beneficial to experiment with different values and evaluate the resulting clusters to find the best fit for your specific dataset and problem.
The choice of distance metric in DBSCAN can significantly impact clustering results. By default, DBSCAN uses Euclidean distance, which works well for compact, spherical clusters. However, this may not be ideal for all data types.
You can specify alternative metrics, such as:
Matching the distance metric to your data's structure ensures that density-based clustering reflects real similarity.
In scikit-learn, the metric parameter lets you set this explicitly (e.g., metric='cosine'). Some custom metrics may require a precomputed distance matrix.
Because DBSCAN relies on absolute distance values, unscaled features can lead to distorted results. Variables with larger ranges will dominate the distance calculation, even if they aren’t more important. This can prevent the algorithm from correctly identifying dense regions in the data.
To avoid this, it’s essential to scale your features so they contribute equally. Common approaches include:
Standardization: Centers features around zero with unit variance using StandardScaler.
Min-Max Scaling: Rescales features to a fixed range (usually [0, 1]) using MinMaxScaler.
Choose a scaling method that matches your data's distribution. Without proper preprocessing, DBSCAN may fail to detect meaningful clusters—even if your epsilon and MinPts are well-tuned.
In this section, we'll look at the implementation of DBSCAN using Python and the scikit-learn library. We'll use the Make Moons dataset to demonstrate the process.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsThese imports provide the necessary tools for data manipulation, visualization, dataset creation, and implementing the DBSCAN algorithm.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)This code creates a synthetic dataset using the make_moons function from scikit-learn. Here's a brief description of the dataset:
The make_moons function generates a binary classification dataset that resembles two interleaving half moons. In our case:
n_samples=200)noise=0.05) to make the dataset more realisticrandom_state=42 for reproducibilityThis dataset is particularly useful for demonstrating DBSCAN because:
Let's visualize this dataset to better understand its structure:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()This will show you the two interleaving half-moon shapes in our dataset as shown below
We use the k-distance graph method to help choose an appropriate epsilon value:
plot_k_distance_graph that calculates the distance to the k-th nearest neighbor for each point.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Output
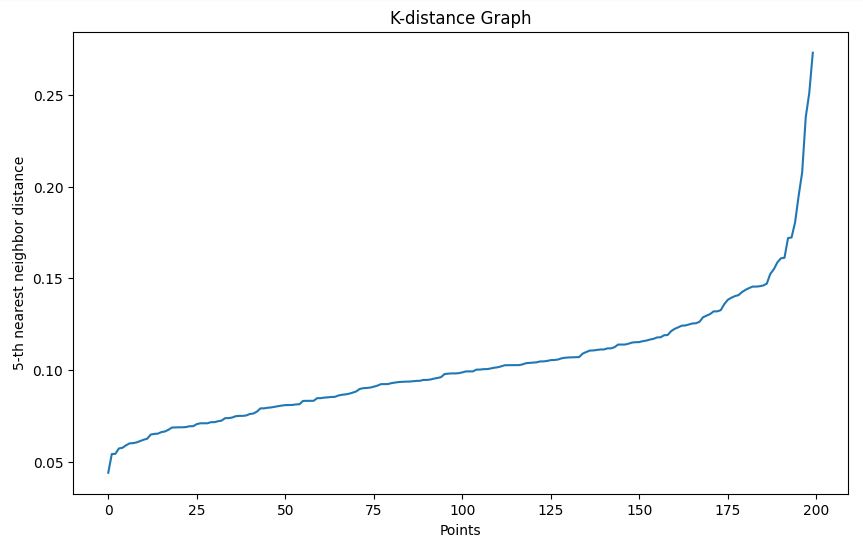
In our example, based on the k-distance graph, we choose an epsilon of 0.15.
We use scikit-learn's DBSCAN implementation:
epsilon=0.15 based on our k-distance graph.min_samples=5 (2 * num_features, as our data is 2D).# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)We create a scatter plot of our data points, coloring them according to their assigned clusters. Points classified as noise are typically colored differently (often black).
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Output
Finally, we print out the number of clusters found and the number of points classified as noise. This gives us a quick summary of the clustering results.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Output
Number of clusters: 2
Number of noise points: 5
This implementation provides a complete workflow from data generation to results interpretation. It's important to note that in real-world scenarios, you would replace the sample data generation with loading and preprocessing your actual dataset.
Remember, the key to successful DBSCAN clustering often lies in appropriate parameter selection. Don't hesitate to experiment with different epsilon and min_samples values to find the best fit for your specific dataset.
While both DBSCAN and K-Means are popular clustering algorithms, they have distinct characteristics that make them suitable for different types of data and use cases. Let's compare these two algorithms to understand when to use each one.
|
Feature |
DBSCAN |
K-Means |
|
Cluster Shape |
Can identify clusters of arbitrary shapes |
Assumes clusters are convex and roughly spherical |
|
Number of Clusters |
Does not require specifying the number of clusters beforehand |
Requires specifying the number of clusters (K) in advance |
|
Handling Outliers |
Identifies outliers as noise points |
Forces every point into a cluster, potentially distorting cluster shapes |
|
Sensitivity to Parameters |
Sensitive to epsilon and MinPts parameters |
Sensitive to initial centroid positions and the choice of K |
|
Cluster Density |
Can find clusters of varying densities |
Tends to find clusters of similar spatial extent and density |
|
Scalability |
Less efficient for large datasets, especially with high-dimensional data |
Generally more efficient and scales better to large datasets |
|
Handling of Non-Globular Clusters |
Performs well on non-globular clusters |
Struggles with non-globular shapes |
|
Consistency of Results |
Produces consistent results across runs |
Results can vary due to random initialization of centroids |
To illustrate these differences, let's apply both algorithms to our moon-shaped dataset
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
This code applies both DBSCAN and K-Means to our dataset and visualizes the results side by side.
Output
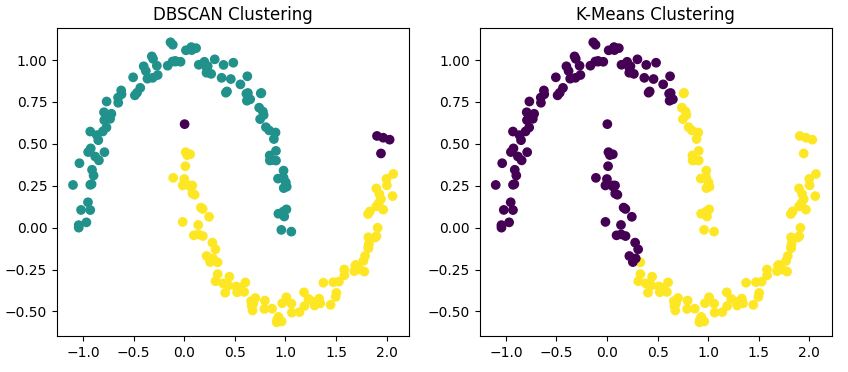
You'll notice that
Now that we've seen how DBSCAN works and compared it to K-Means, let’s see when DBSCAN is the right choice for our clustering needs. The unique properties of DBSCAN make it particularly well-suited for certain types of data and problem domains.
Building on our previous comparison, DBSCAN truly shines when dealing with non-globular cluster shapes. If your data forms arbitrary patterns like the half-moons we explored earlier, DBSCAN is likely to outperform traditional algorithms like K-Means.
For example, in geographical analysis, natural formations like river systems or urban sprawl often form irregular shapes that DBSCAN can effectively identify.
One of DBSCAN's key advantages is its ability to determine the number of clusters automatically. This is particularly useful in exploratory data analysis where you might not have prior knowledge about the underlying structure of your data.
Consider a market segmentation problem: you might not know in advance how many distinct customer groups exist. DBSCAN can help uncover these segments without requiring you to guess the number of clusters.
DBSCAN's approach to handling noise points makes it robust to outliers. This is crucial in many real-world datasets where measurement errors or anomalies are common.
For instance, in anomaly detection systems for network security, DBSCAN can effectively separate normal network traffic patterns from potential security threats.
Unlike K-Means, which assume clusters of similar density, DBSCAN can identify clusters of varying densities. This is particularly useful in scenarios where some groups in your data are more tightly packed than others.
An example could be analyzing galaxy distributions in astronomy, where different regions of space have varying densities of celestial objects.
Now that we learned about when to use DBSCAN, let's look at its weaknesses and take a short look at two alternatives, OPTICS and HDBSCAN.
While DBSCAN is powerful, it's important to be aware of its limitations:
To improve clustering, apply dimensionality reduction techniques like PCA, t-SNE, or UMAP before using DBSCAN. This reduces noise and improves the algorithm’s ability to detect dense regions.
A useful alternative to DBSCAN is OPTICS (Ordering Points To Identify the Clustering Structure). It addresses DBSCAN’s limitation of using a fixed epsilon value by dynamically adjusting neighborhood thresholds.
OPTICS is more effective on datasets with clusters of different densities and can reveal cluster structures that DBSCAN may miss. Scikit-learn includes OPTICS in its clustering module, and it uses the same interface as DBSCAN.
HDBSCAN (Hierarchical DBSCAN) is a modern extension of DBSCAN that builds a hierarchy of clusters based on varying density levels. It removes the need to manually choose epsilon and often provides better results with less parameter tuning.
HDBSCAN tends to outperform vanilla DBSCAN on real-world, noisy, or unbalanced datasets. It’s available as a standalone Python package (hdbscan) and integrates well with scikit-learn.
DBSCAN finds applications across various domains.
In geographic information systems (GIS), DBSCAN can identify areas of high activity or interest. For instance, a study titled ‘Uncovering urban human mobility from large scale taxi GPS data’ demonstrates how DBSCAN can detect urban hotspots from taxi GPS data.
This application showcases DBSCAN's ability to identify dense activity regions in spatial data, which is crucial for urban planning and transportation management.
DBSCAN can group pixels into distinct objects for tasks like object recognition in images. A study titled 'Segmentation of Brain Tumour from MRI Image – Analysis of K-means and DBSCAN Clustering' demonstrates DBSCAN's effectiveness in medical image analysis.
The researchers used DBSCAN to accurately segment brain tumors in MRI scans, showcasing its potential in computer-aided diagnosis and medical imaging.
In fraud detection or system health monitoring, DBSCAN can isolate unusual patterns. A study titled 'Efficient density and cluster-based incremental outlier detection in data streams' demonstrates the application of a modified DBSCAN algorithm for real-time anomaly detection.
The researchers applied an incremental version of DBSCAN to detect outliers in streaming data, which has potential applications in fraud detection and system health monitoring.
This study showcases how DBSCAN can be adapted for identifying unusual patterns in continuous data streams, a crucial capability for real-time fraud detection systems.
DBSCAN can group users with similar preferences, helping to generate more accurate recommendations. For example, a study titled "Multi-Cloud Based Service Recommendation System Using DBSCAN Algorithm" demonstrates the application of DBSCAN in improving collaborative filtering for recommendation systems. The researchers used DBSCAN as part of a clustering approach to group users based on their movie preferences and ratings, which improved the accuracy of movie recommendations.
This approach showcases how DBSCAN can enhance personalized recommendations in domains such as entertainment streaming services.
DBSCAN is a powerful tool in the data scientist's toolkit, particularly valuable when dealing with complex, noisy datasets where the number of clusters is unknown. However, like any algorithm, it's not a one-size-fits-all solution.
The key to successful clustering lies in understanding your data, the strengths and limitations of different algorithms, and choosing the right tool for the job. In many cases, trying multiple clustering approaches, including DBSCAN and K-Means, and comparing their results can provide valuable insights into your data's structure.
With practice and experience, you'll develop an intuition for when DBSCAN is likely to unveil the hidden patterns in your data.
You can learn more about the various technologies and methods we’ve covered in this post on DataCamp with the following resources:
Top DataCamp Courses
Track
Course
Course
blog
Moez Ali
15 min
Tutorial
Sayak Paul
Tutorial
Vidhi Chugh
Tutorial
Kevin Babitz
Tutorial
Zoumana Keita
Tutorial
Austin Chia

