Programa
Analista de dados Em Python
36 h
Na ciência de dados e no machine learning, a capacidade de descobrir padrões ocultos e agrupar pontos de dados semelhantes é uma habilidade importante. Os algoritmos de agrupamento são super importantes nesse processo.
O agrupamento é uma técnica fundamental de machine learning e ciência de dados que envolve juntar pontos de dados parecidos. É um método de aprendizado sem supervisão, ou seja, não precisa de dados rotulados para encontrar padrões.
O principal objetivo do agrupamento é:
Embora existam vários algoritmos de agrupamento (talvez você já tenha ouvido falar do K-means ou do agrupamento hierárquico), o DBSCAN oferece vantagens únicas. Como método baseado em densidade, o DBSCAN tem várias vantagens:
Neste artigo, vamos ver o que é o algoritmo DBSCAN, como ele funciona, como implementá-lo em Python e quando usá-lo nos seus projetos de ciência de dados.
DBSCAN, que significa Agrupamento Espacial Baseado em Densidade de Aplicações com Ruído, é um algoritmo de agrupamento bem poderoso que junta pontos que estão bem próximos uns dos outros no espaço de dados. Diferente de outros algoritmos de agrupamento, o DBSCAN não precisa que você diga antes quantos grupos quer, o que o torna bem útil para fazer análises exploratórias de dados.
O algoritmo funciona definindo os clusters como regiões densas separadas por regiões de menor densidade. Essa abordagem permite que o DBSCAN descubra clusters de formas arbitrárias e identifique outliers como ruído.
O DBSCAN gira em torno de três conceitos principais:
Imagem do autor
O diagrama acima mostra esses conceitos. Os pontos centrais (azuis) são o coração dos clusters, os pontos de borda (laranja) ficam na borda dos clusters e os pontos de ruído (vermelhos) ficam isolados.
O DBSCAN usa dois parâmetros principais:
Ao ajustar esses parâmetros, você pode controlar como o algoritmo define os clusters, permitindo que ele se adapte a diferentes tipos de conjuntos de dados e requisitos de agrupamento.
Na próxima seção, vamos ver como o algoritmo DBSCAN funciona, explorando seu processo passo a passo para identificar clusters nos dados.
O DBSCAN funciona examinando a vizinhança de cada ponto no conjunto de dados. O algoritmo segue um processo passo a passo para identificar agrupamentos com base na densidade dos pontos de dados. Vamos ver como o DBSCAN funciona:
Esse processo permite que o DBSCAN forme grupos de formas aleatórias e identifique valores atípicos de forma eficaz. A capacidade do algoritmo de encontrar agrupamentos sem precisar especificar o número de agrupamentos antes é um dos seus principais pontos fortes.
É importante notar que a escolha de ε e MinPts pode afetar bastante os resultados do agrupamento. Na próxima seção, vamos falar sobre como escolher esses parâmetros de forma eficaz e apresentar métodos como o gráfico de distância k para a seleção de parâmetros.
Para entender completamente como o DBSCAN forma clusters, é importante compreender dois conceitos-chave: acessibilidade de densidade e conectividade de densidade.
Um ponto q é alcançável em termos de densidade a partir de um ponto p se:
1. p é um ponto central (tem pelo menos MinPts dentro da distância ε)
2. Tem uma cadeia de pontos p = p1, ..., pn = q onde cada pi+1 é diretamente alcançável em densidade a partir de pi.
Em termos mais simples, você pode chegar a q a partir de p passando por pontos centrais, onde cada passo não é maior que ε.
Dois pontos p e q são densamente conectados se existe um ponto o tal que tanto p quanto q são densamente alcançáveis a partir de o.
A conectividade de densidade é a base para formar clusters no DBSCAN. Todos os pontos em um agrupamento estão conectados entre si por densidade, e se um ponto está conectado por densidade a qualquer ponto no agrupamento, ele também faz parte desse agrupamento.
A eficácia do DBSCAN depende muito da escolha dos seus dois parâmetros principais: ε (epsilon) e MinPts. Veja como selecionar esses parâmetros:
O parâmetro ε determina a distância máxima entre dois pontos para que eles sejam considerados vizinhos. Para escolher um ε adequado:
1. Use o conhecimento do domínio: Se você sabe qual distância é importante para o seu problema específico, use isso como ponto de partida.
2. Gráfico de distância K: Essa é uma abordagem mais sistemática:
MinPts determina o número mínimo de pontos necessários para formar uma região densa. Aqui vão algumas dicas:
1. Regra geral: Um bom ponto de partida é definir MinPts = 2 * num_features, onde num_features é o número de dimensões no seu conjunto de dados.
2. Considerações sobre ruído: Se seus dados tiverem ruído ou você quiser detectar clusters menores, talvez seja uma boa ideia diminuir o MinPts.
3. Tamanho do conjunto de dados: Para conjuntos de dados maiores, talvez você precise aumentar o parâmetro ` MinPts ` para evitar a criação de muitos clusters pequenos.
Lembre-se de que a escolha dos parâmetros pode afetar bastante os resultados. Muitas vezes, é legal testar valores diferentes e ver os agrupamentos que saem pra achar o que funciona melhor pro seu conjunto de dados e problema.
A escolha da métrica de distância no DBSCAN pode afetar bastante os resultados do agrupamento. Por padrão, o DBSCAN usa a distância euclidiana, que funciona bem para clusters compactos e esféricos. Mas isso pode não ser ideal para todos os tipos de dados.
Você pode especificar métricas alternativas, como:
Combinar a métrica de distância com a estrutura dos seus dados garante que o agrupamento baseado em densidade reflita a semelhança real.
Em scikit-learn, o parâmetro metric permite definir isso explicitamente (por exemplo, metric='cosine'). Algumas métricas personalizadas podem precisar de uma matriz de distância pré-calculada.
Como o DBSCAN depende de valores de distância absolutos, características não escalonadas podem levar a resultados distorcidos. Variáveis com intervalos maiores vão dominar o cálculo da distância, mesmo que não sejam mais importantes. Isso pode impedir que o algoritmo identifique corretamente regiões densas nos dados.
Para evitar isso, é essencial dimensionar seus recursos para que eles contribuam igualmente. Abordagens comuns incluem:
Padronização: Centros com valor próximo de zero e variância unitária usando StandardScaler.
Escalonamento Mínimo-Máximo: Redimensiona os recursos para um intervalo fixo (normalmente [0, 1]) usando MinMaxScaler.
Escolha um método de dimensionamento que combine com a distribuição dos seus dados. Sem um pré-processamento adequado, o DBSCAN pode não conseguir detectar clusters significativos, mesmo que seus parâmetros epsilon e MinPts estejam bem ajustados.
Nesta seção, vamos ver como implementar o DBSCAN usando Python e a biblioteca scikit-learn. Vamos usar o conjunto de dados Make Moons para mostrar como funciona.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighborsEssas importações fornecem as ferramentas necessárias para manipulação de dados, visualização, criação de conjuntos de dados e implementação do algoritmo DBSCAN.
X, _ = make_moons(n_samples=200, noise=0.05, random_state=42)Esse código cria um conjunto de dados sintéticos usando a função ` make_moons ` do scikit-learn. Aqui vai uma breve descrição do conjunto de dados:
A função make_moons gera uma classificação binária classificação que lembra duas meias-luas entrelaçadas. No nosso caso:
n_samples=200)noise=0.05) para tornar o conjunto de dados mais realista.random_state=42 para a reprodutibilidadeEsse conjunto de dados é super útil pra mostrar como funciona o DBSCAN porque:
Vamos visualizar esse conjunto de dados para entender melhor sua estrutura:
# Visualize the dataset
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Moon-shaped Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Isso vai mostrar as duas formas de meia-lua entrelaçadas no nosso conjunto de dados, como mostrado abaixo.
Usamos o método do gráfico de distância k para ajudar a escolher um valor epsilon apropriado:
plot_k_distance_graph que calcula a distância até o k-ésimo vizinho mais próximo para cada ponto.# Function to plot k-distance graph
def plot_k_distance_graph(X, k):
neigh = NearestNeighbors(n_neighbors=k)
neigh.fit(X)
distances, _ = neigh.kneighbors(X)
distances = np.sort(distances[:, k-1])
plt.figure(figsize=(10, 6))
plt.plot(distances)
plt.xlabel('Points')
plt.ylabel(f'{k}-th nearest neighbor distance')
plt.title('K-distance Graph')
plt.show()
# Plot k-distance graph
plot_k_distance_graph(X, k=5)Saída
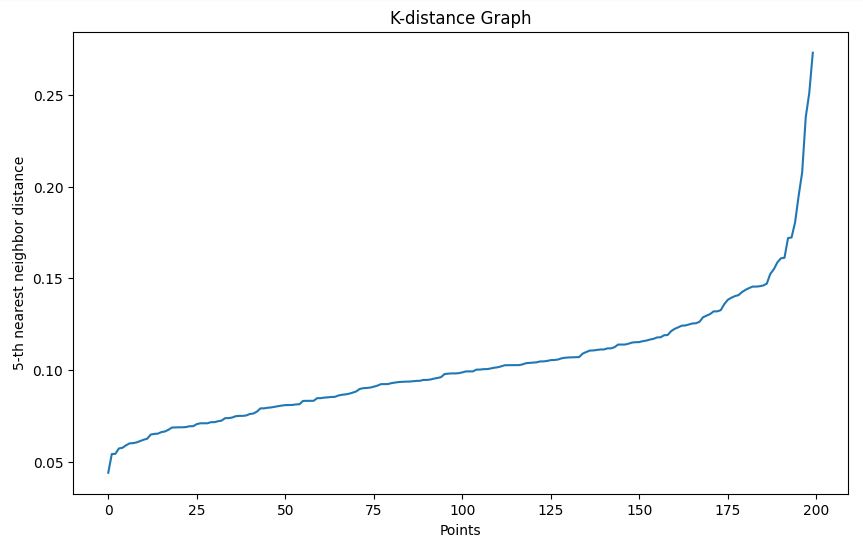
No nosso exemplo, com base no gráfico de distância k, escolhemos um epsilon de 0,15.
Usamos a implementação DBSCAN do scikit-learn:
epsilon=0.15 com base no nosso gráfico de distância k.min_samples=5 (2 * num_features, já que nossos dados são 2D).# Perform DBSCAN clustering
epsilon = 0.15 # Chosen based on k-distance graph
min_samples = 5 # 2 * num_features (2D data)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(X)Fazemos um gráfico de dispersão dos nossos pontos de dados, colorindo-os de acordo com os grupos que lhes foram atribuídos. Os pontos classificados como ruído geralmente têm uma cor diferente (muitas vezes preta).
# Visualize the results
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.colorbar(scatter)
plt.title('DBSCAN Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()Saída
Por fim, imprimimos o número de clusters encontrados e o número de pontos classificados como ruído. Isso nos dá um resumo rápido dos resultados do agrupamento.
# Print number of clusters and noise points
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0)
n_noise = list(clusters).count(-1)
print(f'Number of clusters: {n_clusters}')
print(f'Number of noise points: {n_noise}')Saída
Número de grupos: 2
Número de pontos de ruído: 5
Essa implementação oferece um fluxo de trabalho completo, desde a geração de dados até a interpretação dos resultados. É importante notar que, em cenários reais, você substituiria a geração de dados de amostra pelo carregamento e pré-processamento do seu conjunto de dados real.
Lembre-se, o segredo para um agrupamento DBSCAN bem-sucedido geralmente está na escolha certa dos parâmetros. Não hesite em experimentar diferentes valores de epsilon e min_samples para encontrar o mais adequado para o seu conjunto de dados específico.
Embora tanto o DBSCAN quanto o K-Means sejam algoritmos de agrupamento bem conhecidos, eles têm características diferentes que os tornam adequados para diferentes tipos de dados e casos de uso. Vamos comparar esses dois algoritmos para entender quando usar cada um deles.
|
Recurso |
DBSCAN |
K-Means |
|
Forma do cluster |
Consegue identificar grupos de formas aleatórias |
Supõe que os aglomerados são convexos e aproximadamente esféricos. |
|
Número de clusters |
Não precisa especificar o número de clusters antes. |
Precisa especificar o número de clusters (K) antes. |
|
Lidando com valores atípicos |
Identifica valores atípicos como pontos de ruído |
Força todos os pontos para um agrupamento, podendo distorcer as formas dos agrupamentos. |
|
Sensibilidade aos parâmetros |
Sensível aos parâmetros epsilon e MinPts |
Sensível às posições centróides iniciais e à escolha de K |
|
Densidade do cluster |
Pode encontrar grupos com densidades diferentes |
Costuma encontrar grupos com extensão espacial e densidade parecidas. |
|
Escalabilidade |
Menos eficiente para grandes conjuntos de dados, especialmente com dados de alta dimensão. |
Geralmente mais eficiente e se adapta melhor a grandes conjuntos de dados |
|
Como lidar com aglomerados não globulares |
Funciona bem em aglomerados não globulares |
Dificuldades com formas não esféricas |
|
Consistência dos resultados |
Produz resultados consistentes em todas as execuções |
Os resultados podem variar devido à inicialização aleatória dos centróides. |
Para mostrar essas diferenças, vamos usar os dois algoritmos no nosso conjunto de dados em forma de lua.
from sklearn.cluster import KMeans
# DBSCAN clustering
dbscan = DBSCAN(eps=0.15, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# K-Means clustering
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Visualize the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
ax1.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
ax1.set_title('DBSCAN Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax2.set_title('K-Means Clustering')
plt.show()
Esse código usa o DBSCAN e o K-Means no nosso conjunto de dados e mostra os resultados lado a lado.
Saída
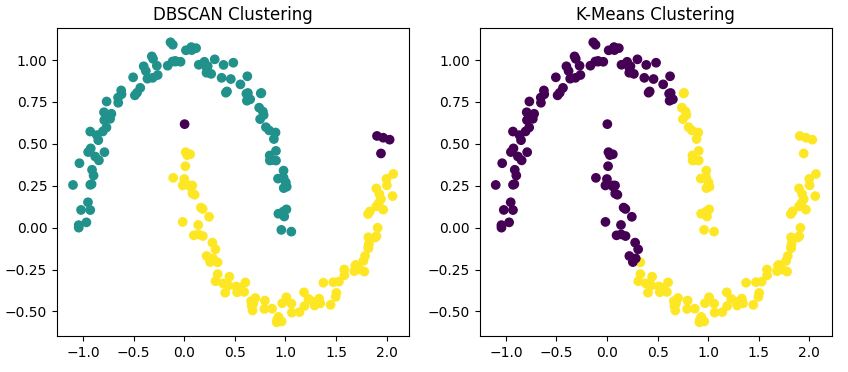
Você vai perceber que
Agora que vimos como o DBSCAN funciona e comparamos com o K-Means, vamos ver quando o DBSCAN é a escolha certa para nossas necessidades de agrupamento. As propriedades únicas do DBSCAN fazem com que ele seja especialmente bom para certos tipos de dados e áreas de problemas.
Com base na nossa comparação anterior, o DBSCAN realmente se destaca quando lida com formas de agrupamentos não globulares. Se seus dados formam padrões aleatórios, como as meias-luas que vimos antes, o DBSCAN provavelmente vai funcionar melhor do que os algoritmos tradicionais, como o K-Means.
Por exemplo, na análise geográfica, formações naturais como sistemas fluviais ou expansão urbana geralmente têm formas irregulares que o DBSCAN consegue identificar direitinho.
Uma das principais vantagens do DBSCAN é a capacidade de determinar automaticamente o número de clusters. Isso é super útil na análise exploratória de dados, onde você pode não ter conhecimento prévio sobre a estrutura subjacente dos seus dados.
Pense num problema de segmentação de mercado: você pode não saber de antemão quantos grupos distintos de clientes existem. O DBSCAN pode ajudar a descobrir esses segmentos sem que você precise adivinhar o número de clusters.
A maneira como o DBSCAN lida com pontos ruidosos o torna resistente a valores atípicos. Isso é super importante em muitos conjuntos de dados do mundo real, onde erros de medição ou anomalias são comuns.
Por exemplo, em sistemas de detecção de anomalias para segurança de rede, o DBSCAN consegue separar bem os padrões normais de tráfego de rede das possíveis ameaças à segurança.
Ao contrário do K-Means, que assume clusters de densidade semelhante, o DBSCAN consegue identificar clusters de densidades diferentes. Isso é super útil quando alguns grupos nos seus dados estão mais compactados do que outros.
Um exemplo poderia ser a análise da distribuição das galáxias na astronomia, onde diferentes regiões do espaço têm densidades variadas de objetos celestes.
Agora que já sabemos quando usar o DBSCAN, vamos ver quais são os pontos fracos dele e dar uma olhada rápida em duas alternativas: OPTICS e HDBSCAN.
Embora o DBSCAN seja poderoso, é importante estar ciente de suas limitações:
Para melhorar o agrupamento, use técnicas de redução de dimensionalidade como PCA, t-SNE ou UMAP antes de usar o DBSCAN. Isso reduz o ruído e melhora a capacidade do algoritmo de detectar regiões densas.
Uma alternativa útil ao DBSCAN é o OPTICS (Ordering Points To Identify the Clustering Structure). Ele resolve a limitação do DBSCAN de usar um valor epsilon fixo, ajustando dinamicamente os limites de vizinhança.
O OPTICS é mais eficaz em conjuntos de dados com clusters de diferentes densidades e pode revelar estruturas de clusters que o DBSCAN pode deixar passar. O Scikit-learn inclui o OPTICS no seu módulo de agrupamento e usa a mesma interface que o DBSCAN.
O HDBSCAN (Hierarchical DBSCAN) é uma versão mais moderna do DBSCAN que cria uma hierarquia de clusters com base em diferentes níveis de densidade. Isso elimina a necessidade de escolher manualmente o epsilon e, muitas vezes, dá resultados melhores com menos ajustes de parâmetros.
O HDBSCAN costuma ter um desempenho melhor do que o DBSCAN básico em conjuntos de dados reais, ruidosos ou desequilibrados. Está disponível como um pacote Python independente (hdbscan) e se integra bem com scikit-learn.
O DBSCAN tem aplicações em vários domínios.
Nos sistemas de informação geográfica (SIG), o DBSCAN consegue identificar áreas de muita atividade ou interesse. Por exemplo, um estudo chamado “Descobrindo a mobilidade humana urbana a partir de dados GPS de táxis em grande escala” mostra como o DBSCAN consegue detectar pontos de interesse urbanos a partir de dados de GPS de táxis.
Esse aplicativo mostra como o DBSCAN consegue identificar áreas com muita atividade em dados espaciais, o que é super importante para o planejamento urbano e a gestão do transporte.
O DBSCAN pode juntar pixels em objetos diferentes para tarefas como reconhecimento de objetos em imagens. Um estudo chamado “Segmentação de tumor cerebral a partir de imagem de ressonância magnética – Análise de agrupamento K-means e DBSCAN” mostra como o DBSCAN é eficiente na análise de imagens médicas.
Os pesquisadores usaram o DBSCAN para segmentar com precisão tumores cerebrais em exames de ressonância magnética, mostrando seu potencial no diagnóstico assistido por computador e em imagens médicas.
Na detecção de fraudes ou no monitoramento da saúde do sistema, o DBSCAN pode isolar padrões incomuns. Um estudo chamado “Detecção eficiente de outliers incrementais baseada em densidade e cluster em fluxos de dados” mostra como usar um algoritmo DBSCAN modificado para detectar anomalias em tempo real.
Os pesquisadores usaram uma versão melhorada do DBSCAN para achar dados fora do normal em fluxos de dados, o que pode ser útil para detectar fraudes e monitorar a saúde do sistema.
Esse estudo mostra como o DBSCAN pode ser adaptado para identificar padrões incomuns em fluxos de dados contínuos, uma capacidade essencial para sistemas de detecção de fraudes em tempo real.
O DBSCAN pode juntar usuários com gostos parecidos, ajudando a gerar recomendações mais precisas. Por exemplo, um estudo chamado “Sistema de recomendação de serviços baseado em múltiplas nuvens usando o algoritmo DBSCAN” mostra como o DBSCAN pode melhorar a filtragem colaborativa em sistemas de recomendação. Os pesquisadores usaram o DBSCAN como parte de uma abordagem de agrupamento para classificar os usuários com base em suas preferências e avaliações de filmes, o que melhorou a precisão das recomendações de filmes.
Essa abordagem mostra como o DBSCAN pode melhorar as recomendações personalizadas em áreas como serviços de streaming de entretenimento.
O DBSCAN é uma ferramenta poderosa no kit de ferramentas do cientista de dados, especialmente útil quando se lida com conjuntos de dados complexos e ruidosos, onde o número de clusters é desconhecido. Mas, como qualquer algoritmo, não é uma solução que serve para todos.
O segredo para um agrupamento bem-sucedido está em entender seus dados, os pontos fortes e as limitações dos diferentes algoritmos e escolher a ferramenta certa para o trabalho. Em muitos casos, experimentar várias abordagens de agrupamento, incluindo DBSCAN e K-Means, e comparar seus resultados pode fornecer informações valiosas sobre a estrutura dos seus dados.
Com prática e experiência, você vai desenvolver uma intuição para saber quando o DBSCAN provavelmente revelará os padrões ocultos em seus dados.
Você pode saber mais sobre as várias tecnologias e métodos que falamos neste post no DataCamp com os seguintes recursos:
Cursos mais populares do DataCamp
Programa
Curso
Curso
blog
Moez Ali
15 min
blog
Kurtis Pykes
7 min
Tutorial
Kevin Babitz
Tutorial
Eugenia Anello
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan


