
Kursus
Machine Learning for Time Series Data in Python
4 Hr
53.2K
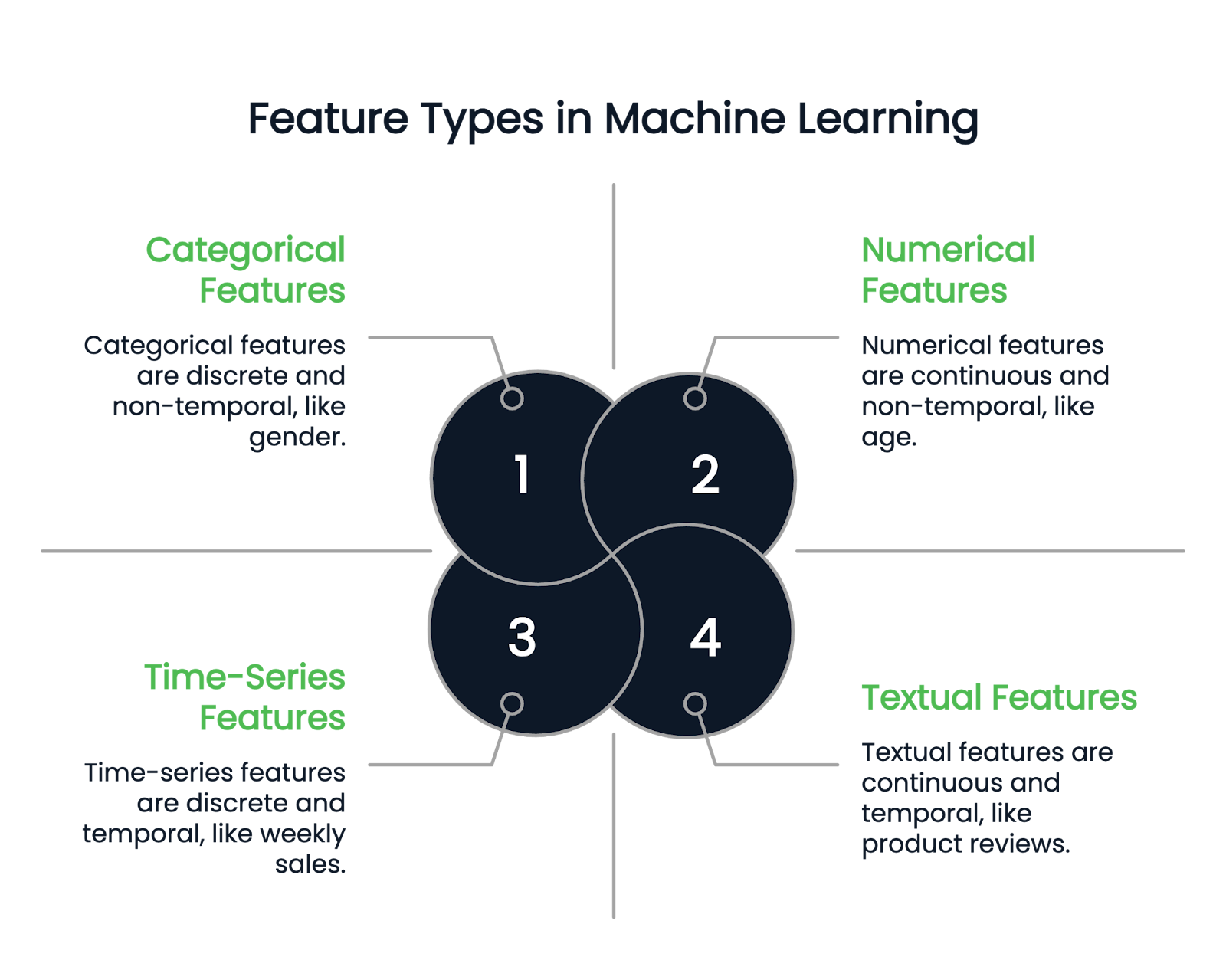
Sebelum membahas berbagai teknik feature engineering, mari pahami dulu jenis-jenis fitur yang ada.
Seperti namanya, fitur numerik merepresentasikan data dalam angka. Mereka adalah variabel kuantitatif kontinu. Contoh: tinggi badan, usia, dan gaji.
Kolom kategorikal hanya dapat berisi fitur diskret. Misalnya, jenis kelamin seseorang adalah kolom kategorikal, karena hanya dapat memiliki beberapa tipe gender. Bulan lahir juga contoh lain karena nilainya harus antara Januari dan Desember.
Variabel kategorikal selanjutnya dibagi menjadi biner dan non-biner. Variabel biner memiliki dua kemungkinan kategori, sedangkan fitur non-biner dapat memiliki banyak kategori.
Kolom tekstual hanya berisi data teks. Contohnya termasuk ulasan produk atau kolom deskripsi produk dalam dataset ritel.
Di sisi lain, fitur deret waktu merepresentasikan data berkala, seperti penjualan mingguan atau fluktuasi harga saham selama satu tahun.
Gambar oleh Penulis
Feature engineering menawarkan berbagai teknik kuat untuk mengonversi kolom mentah menjadi fitur yang diinginkan. Berikut ini beberapa yang menonjol.
Nilai hilang dapat mendistorsi performa model, jadi penting untuk menanganinya dengan benar. Ada dua pendekatan utama:
Untuk panduan mendalam tentang penanganan data hilang, baca this Techniques to Handle Missing Data Tutorial atau jelajahi this Dealing with Missing Data in Python Course.
Outlier adalah nilai abnormal yang sangat berbeda dari titik data lainnya. Misalnya, jika Anda memiliki dataset gaji dengan sebagian besar observasi antara $90K dan $120k, angka gaji seperti $400K atau $10K adalah outlier.
Model machine learning tidak dapat memproses variabel kategorikal secara langsung, sehingga harus diubah menjadi representasi numerik. Di bawah ini, kita bahas beberapa teknik encoding populer.
Pertimbangkan dataset dengan fitur kategorikal berikut:
|
Nama |
Gender |
|
John |
Male |
|
Rachel |
Female |
|
Emma |
Female |
Dengan one-hot encoding, kita membuat kolom terpisah untuk setiap kategori yang mungkin dalam fitur Gender:
|
Nama |
Female |
Male |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Karena John adalah Male, kolom "Male" mendapat 1, sementara kolom "Female" tetap 0. Demikian pula, Rachel dan Emma adalah Female, sehingga kolom "Female" bernilai 1 dan kolom "Male" bernilai 0.
Untuk tutorial lengkap tentang one-hot encoding di Python, lihat this One-Hot Encoding Tutorial.
Pertimbangkan dataset dengan kolom Location yang berisi nilai kategorikal:
|
Location |
Encoded value |
|
New York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
Setiap lokasi unik diberikan nilai numerik yang berbeda. Namun, karena California (2) tidak secara inheren "di antara" New York (1) dan Texas (3), penggunaan label encoding untuk data non-ordinal dapat menimbulkan asumsi model yang menyesatkan. Dalam kasus seperti itu, one-hot encoding sering lebih disukai untuk menghindari implikasi hubungan numerik yang tidak diinginkan antar kategori.
Pertimbangkan kolom Education level dengan kategori berikut:
|
Education level |
Encoded value |
|
UG (Undergraduate) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Karena PhD merepresentasikan tingkat pendidikan yang lebih tinggi daripada PG, yang pada gilirannya lebih tinggi daripada UG, nilai numerik yang diberikan mencerminkan peringkat ini.
Pertimbangkan dataset di mana Location adalah fitur kategorikal, dan Target variable merepresentasikan suatu hasil numerik:
|
Location |
Target variable |
|
New York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Untuk meng-encode kolom Location, kita menghitung mean Target variable untuk setiap kategori unik:
|
Location |
Encoded value |
|
New York |
2 |
|
California |
2 |
|
Texas |
4.5 |
|
California |
2 |
|
Texas |
4.5 |
Jika Anda mencari panduan yang lebih luas tentang penanganan data kategorikal, this Categorical Data Handling Tutorial memberikan wawasan tambahan.
Feature scaling memastikan fitur numerik berada dalam rentang yang terstandarisasi, mencegah beberapa fitur mendominasi proses pembelajaran karena nilainya lebih besar.
Model machine learning yang bergantung pada perhitungan berbasis jarak (misalnya, linear regression, k-nearest neighbors, dan neural network) dapat terpengaruh ketika fitur memiliki skala yang sangat berbeda.
Sebagai contoh, pertimbangkan dataset karyawan dengan fitur berikut:
Karena pendapatan memiliki nilai yang jauh lebih besar daripada usia, sebuah model mungkin memberi bobot lebih pada pendapatan hanya karena skalanya, bukan karena memang lebih relevan.
Berikut beberapa teknik umum:
Scaled value =( datapoint - min(column))/(max(column) - min(column))
Scaled value =( datapoint - mean(column))/(std(column))
Untuk perbandingan mendetail antara normalisasi vs. standarisasi, lihat this Normalization vs. Standardization Guide.
Membuat fitur baru yang bermakna dari data yang ada memberikan wawasan yang lebih logis bagi model.
Misalnya, dalam dataset prediksi harga rumah, jika Anda memiliki kolom length dan breadth secara terpisah, Anda dapat menurunkan fitur baru: area = length * breath, yang mungkin berhubungan langsung dengan variabel target, price. Memberikan fitur area ini ke model mempermudah penemuan pola tersembunyi.
Seleksi fitur hanya mempertahankan fitur yang relevan dengan menghapus kolom yang tidak perlu. Memfokuskan pada data yang paling informatif membantu mencegah overfitting, mengurangi kompleksitas komputasi, dan meningkatkan performa model. Berikut beberapa teknik:
Feature engineering paling mudah dipahami melalui implementasi langsung.
“Prediksi harga rumah” adalah dataset dunia nyata besar dengan 81 kolom. Saya memilihnya karena beragamnya fitur, yang dapat membantu Anda lebih memahami teknik feature engineering secara praktis.
Mulai:
Kode berikut mengidentifikasi kolom kategorikal dalam dataset dan mengganti nilai hilangnya dengan kategori yang paling sering muncul:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesKita menangani nilai hilang numerik dengan menggantinya menggunakan mean atau median. Mean lebih populer untuk data yang terdistribusi secara statistik, sementara median bekerja baik ketika kolom memiliki outlier. Jadi, kita akan memeriksa outlier dan memutuskan metodenya.
Untuk memvisualisasikan potensi outlier, kita dapat menggunakan box plot, yang membantu mengidentifikasi nilai ekstrem. Di bawah ini adalah implementasi Python untuk mendeteksi outlier pada kolom numerik terpilih:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Keluaran:
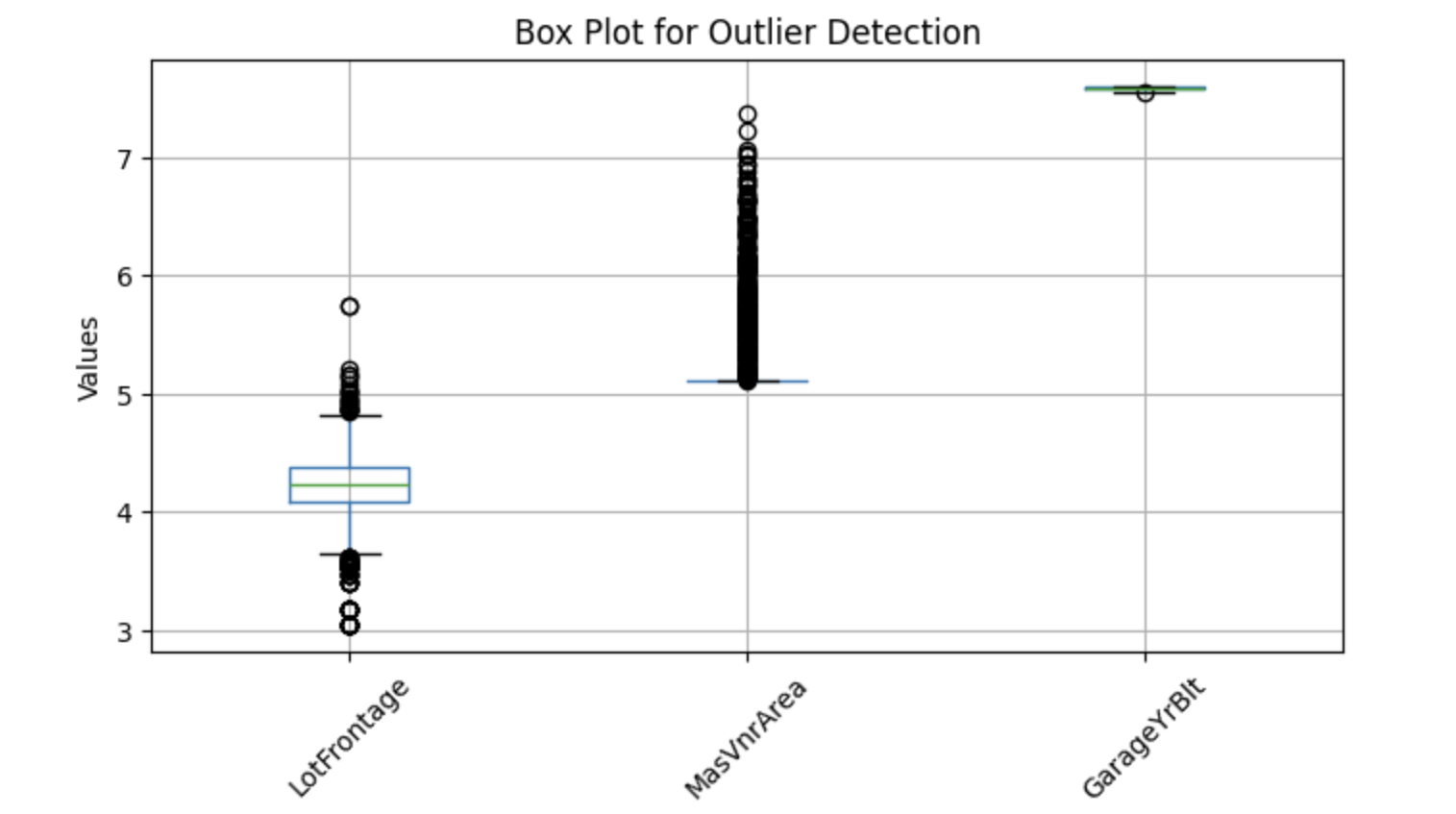
Boxplot di atas menunjukkan titik di luar whisker—ini disebut outlier. Jadi, mari kita ganti nilai hilang dengan median.
Kode untuk mengganti nilai null dengan median:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianKolom seperti YearBuilt, YearRemodAdd, GarageYrBlt, dan YrSold berisi tahun (misalnya, 2001, 1976) yang tidak secara langsung memengaruhi variabel target. Meskipun nilai tahun absolut ini mungkin tidak berdampak langsung pada harga rumah, kita dapat menurunkan wawasan yang lebih berguna dengan menghitung seberapa tua rumah atau renovasinya pada saat penjualan.
Sebagai contoh, alih-alih menggunakan YearBuilt, kita dapat membuat fitur baru: House Age=YrSold−YearBuilt
Kode untuk membuat fitur-fitur baru ini:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Dalam machine learning, fitur numerik yang skewed dapat berdampak negatif pada performa model, terutama untuk model yang mengasumsikan distribusi normal (misalnya, linear regression). Untuk memperbaikinya, kita menerapkan transformasi log.
Sebelum menerapkan transformasi log, kita harus mengidentifikasi fitur yang skewed. Namun, kita mengecualikan kolom yang berisi nol karena logaritma dari nol tidak terdefinisi.
Berikut implementasi di Python untuk mengidentifikasi kolom yang skewed:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Keluaran:

Kita akan menggunakan distribusi log-normal untuk mengonversi lima kolom yang skewed ini menjadi distribusi Gaussian:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Kita sebelumnya telah membahas beberapa teknik encoding; pada contoh ini, kita akan menerapkan target encoding.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Pada kode di atas, variabel target adalah SalePrice, sehingga kami mengelompokkan data berdasarkan setiap kolom kategorikal dan menghitung mean SalePrice untuk tiap grup. Nilai mean ini kemudian diberikan ke nilai kategorikal yang sesuai pada kolom tersebut.
Dataset kita sekarang siap untuk machine learning!
Jika Anda ingin memperkuat pemahaman tentang konsep supervised learning dan bagaimana model memanfaatkan fitur yang direkayasa, this Supervised Learning with Scikit-Learn Course adalah sumber yang sangat baik.
Pada bagian ini, kita akan membahas pustaka Python dan alat otomatisasi yang paling sering digunakan untuk mengimplementasikan feature engineering.
Pandas adalah kerangka kerja Python yang paling sering digunakan untuk menangani data terstruktur. Ia melakukan banyak langkah feature engineering, seperti transformasi, agregasi data, dan ekstraksi fitur. Pandas juga memudahkan pembersihan dan manipulasi data.
Jika Anda baru mengenal pandas, this Data Manipulation with pandas Course adalah titik awal yang bagus.
Scikit-learn adalah pustaka machine learning yang kuat dengan berbagai alat untuk feature engineering. Ia memiliki metode seperti OneHotEncoder dan LabelEncoder untuk mengonversi variabel kategorikal menjadi numerik. Ia juga menawarkan metode feature scaling seperti StandardScaler dan Minmaxscaler.
Feature-engine adalah pustaka Python sumber terbuka yang menawarkan berbagai transformer untuk menyederhanakan feature engineering. Transformer ini adalah alat khusus untuk tugas tertentu, seperti imputasi data hilang, penanganan outlier, seleksi fitur, dan diskretisasi. Sepenuhnya kompatibel dengan scikit-learn, transformer ini dapat diteruskan sebagai parameter input untuk penalaan hiperparameter.
fit(), pustaka ini menawarkan metode fit_transform() yang secara bersamaan melakukan operasi fit dan transform pada data input. Selain itu, model FeatureSelector dan AutoFeatLight tersedia untuk seleksi fitur dan scaling.Agar efektif mengimplementasikan feature engineering, fokuslah pada praktik terbaik berikut.
Memahami makna dan signifikansi setiap fitur membuat Anda jauh lebih mudah melakukan teknik seperti seleksi atau ekstraksi fitur. Saya menyarankan Anda meneliti data dan pengetahuan domain yang relevan untuk feature engineering yang efektif.
Manfaatkan pustaka Python seperti Pandas dan Matplotlib untuk melakukan exploratory data analysis secara komprehensif, seperti mengeksplorasi informasi statistik, visualisasi, dan korelasi untuk menemukan pola serta potensi hubungan dalam data.
Membuat fitur interaksi melibatkan identifikasi hubungan antar fitur yang ada dan menurunkan fitur baru. Misalnya, dalam prediksi harga rumah, menghitung usia rumah dengan mengurangkan tahun dibangun dari tahun saat ini menyoroti tren, seperti harga rumah yang menurun seiring waktu.
Model machine learning yang berbeda memerlukan langkah feature engineering yang berbeda. Misalnya, model seperti regresi linear atau multipel, SVM, dan KNN sering mendapat manfaat dari standarisasi fitur, tetapi teknik ini tidak membantu model berbasis pohon.
Jadi, memutuskan model Anda terlebih dahulu dapat membantu Anda membangun pipeline feature engineering yang efektif untuk kasus penggunaan Anda.
Feature engineering adalah bagian integral dari pembangunan solusi machine learning, memungkinkan Anda memanfaatkan fitur seefisien mungkin. Proses ini dilakukan oleh data scientist atau ML engineer saat menangani dataset apa pun. Jika Anda seorang profesional data atau bercita-cita menjadi salah satunya, menguasai semua teknik yang disebutkan dalam artikel ini akan membantu memajukan karier Anda!
Untuk mengeksplorasi teknik-teknik ini lebih detail, lihat kursus DataCamp tentang feature engineering untuk machine learning dan feature engineering untuk NLP. Ada juga kursus tentang feature engineering untuk programmer R.
Pelajari lebih lanjut tentang machine learning dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
