
Kurs
Maschinelles Lernen für Zeitreihendaten in Python
4 Std.
53.3K
Bevor wir uns mit den verschiedenen Feature-Engineering-Techniken beschäftigen, sollten wir zunächst die verschiedenen Arten von Features verstehen.
Wie der Name schon sagt, stellen numerische Merkmale Daten in Zahlen dar. Sie sind kontinuierliche quantitative Variablen. Beispiele sind Größe, Alter und Gehalt.
Eine kategoriale Spalte kann nur diskrete Merkmale enthalten. Das Geschlecht einer Person ist zum Beispiel eine kategorische Spalte, da es nur einige Geschlechtstypen geben kann. Der Geburtsmonat ist ein weiteres Beispiel, denn die Werte müssen zwischen Januar und Dezember liegen.
Kategoriale Variablen werden weiter in binäre und nicht-binäre Typen unterteilt. Binäre Variablen haben zwei mögliche Kategorien, während nicht-binäre Merkmale mehrere Kategorien haben können.
Textuelle Spalten enthalten nur Textdaten. Beispiele sind Produktbewertungen oder Spalten mit Produktbeschreibungen in einem Einzelhandelsdatensatz.
Zeitreihenmerkmale hingegen stellen zeitnahe Daten dar, z. B. wöchentliche Umsätze oder Aktienkursschwankungen über ein Jahr hinweg.
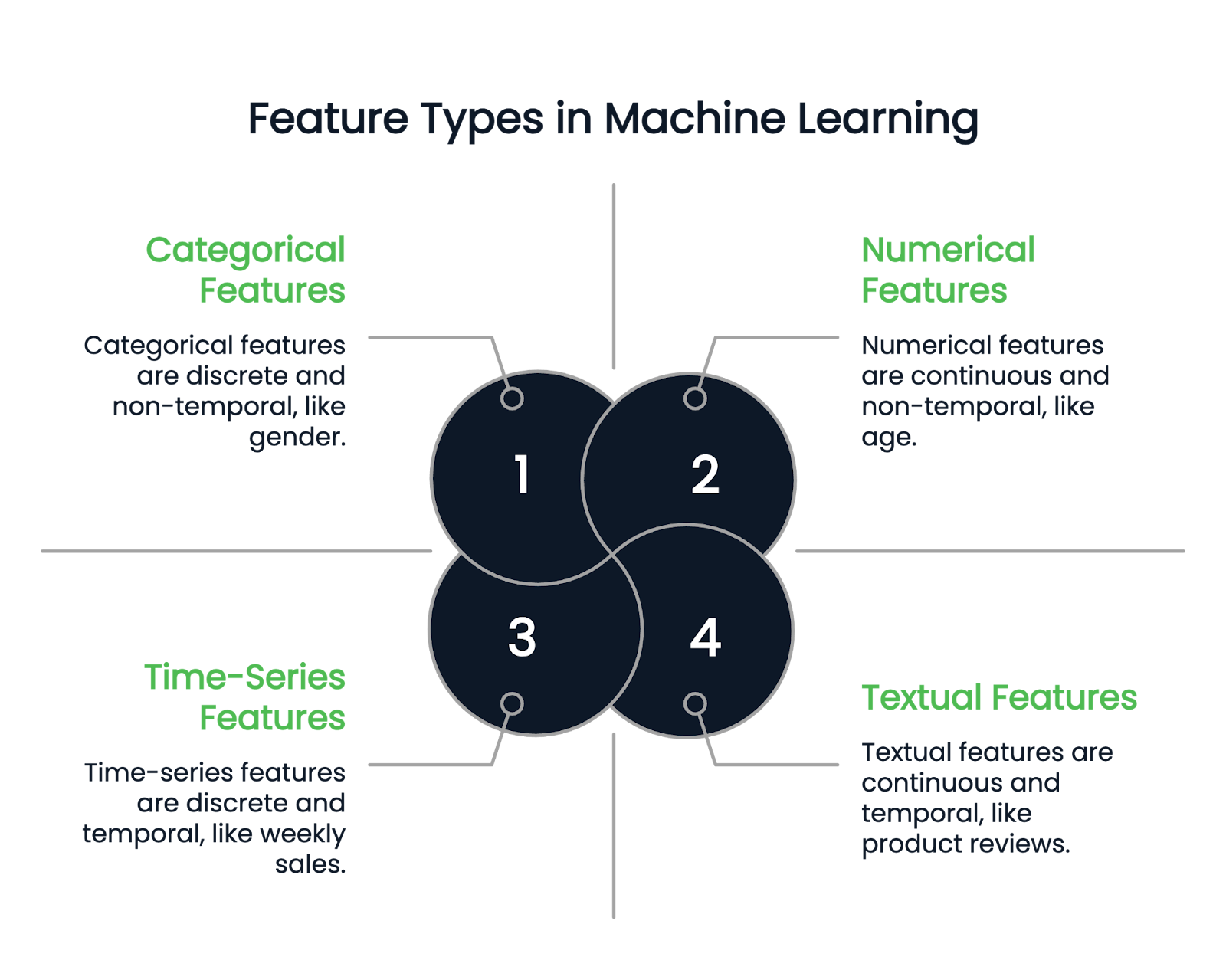
Bild vom Autor
Das Feature-Engineering bietet verschiedene leistungsstarke Techniken zur Umwandlung von Rohspalten in erwünschte Merkmale. Hier besprechen wir einige prominente Beispiele.
Fehlende Werte können die Leistung des Modells beeinträchtigen, daher ist der richtige Umgang mit ihnen entscheidend. Es gibt zwei Hauptansätze:
Eine ausführliche Anleitung zum Umgang mit fehlenden Daten findest du in diesem Tutorial über Techniken zum Umgang mit fehlenden Daten oder in diesem Kurs über den Umgang mit fehlenden Daten in Python.
Ausreißer sind anormale Werte, die sich deutlich vom Rest der Datenpunkte unterscheiden. Wenn du zum Beispiel einen Gehaltsdatensatz hast, bei dem die meisten Beobachtungen zwischen 90 und 120 Tausend Dollar liegen, ist eine Gehaltszahl wie 400 Tausend Dollar oder 10 Tausend Dollar ein Ausreißer.
Modelle des maschinellen Lernens können kategoriale Variablen nicht direkt verarbeiten, daher müssen sie in numerische Darstellungen umgewandelt werden. Im Folgenden werden einige beliebte Kodierungstechniken vorgestellt.
Betrachte einen Datensatz mit dem folgenden kategorialen Merkmal:
|
Name |
Geschlecht |
|
John |
Männlich |
|
Rachel |
Weiblich |
|
Emma |
Weiblich |
Mit der One-Hot-Codierung erstellen wir separate Spalten für jede mögliche Kategorie in dem Merkmal Gender:
|
Name |
Weiblich |
Männlich |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Da John männlich ist, bekommt die Spalte "Männlich" ein 1, während die Spalte "Weiblich" 0 bleibt. Ebenso sind Rachel und Emma weiblich, also steht in der Spalte "Weiblich" 1 und in der Spalte "Männlich" 0.
Ein komplettes Tutorial zur One-Hot-Kodierung in Python findest du in diesem Tutorial zur One-Hot-Kodierung.
Betrachte einen Datensatz mit einer Spalte Location, die kategoriale Werte enthält:
|
Standort |
Kodierter Wert |
|
New York |
1 |
|
Kalifornien |
2 |
|
Texas |
3 |
|
Kalifornien |
2 |
|
Texas |
3 |
Jedem eindeutigen Standort wird ein eindeutiger numerischer Wert zugewiesen. Da Kalifornien (2) jedoch nicht von Natur aus "zwischen" New York (1) und Texas (3) liegt, kann die Verwendung der Label-Kodierung für nicht-ordinale Daten zu irreführenden Modellannahmen führen. In solchen Fällen wird oft eine Ein-Punkt-Kodierung bevorzugt, um zu vermeiden, dass eine unbeabsichtigte numerische Beziehung zwischen den Kategorien hergestellt wird.
Betrachte eine Education level Spalte mit den folgenden Kategorien:
|
Bildungsniveau |
Kodierter Wert |
|
UG (Undergraduate) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Da ein PhD ein höheres Bildungsniveau darstellt als ein PG, das wiederum höher ist als ein UG, spiegeln die zugewiesenen Zahlenwerte diese Rangfolge wider.
Betrachte einen Datensatz, bei dem Location ein kategoriales Merkmal ist und Target variable ein numerisches Ergebnis darstellt:
|
Standort |
Zielvariable |
|
New York |
2 |
|
Kalifornien |
3 |
|
Texas |
5 |
|
Kalifornien |
1 |
|
Texas |
4 |
Um die Spalte Location zu kodieren, berechnen wir den Mittelwert der Target variable für jede einzelne Kategorie:
|
Standort |
Kodierter Wert |
|
New York |
2 |
|
Kalifornien |
2 |
|
Texas |
4.5 |
|
Kalifornien |
2 |
|
Texas |
4.5 |
Wenn du nach einem umfassenderen Leitfaden für den Umgang mit kategorischen Daten suchst, findest du in diesem Tutorial zum Umgang mit kategorischen Daten weitere Informationen.
Die Skalierung von Merkmalen stellt sicher, dass numerische Merkmale innerhalb eines standardisierten Bereichs liegen und verhindert, dass einige Merkmale aufgrund ihrer größeren Werte den Lernprozess dominieren.
Modelle des maschinellen Lernens, die auf abstandsbasierten Berechnungen beruhen (z. B. lineare Regression, k-nearest neighbors und neuronale Netze), können beeinträchtigt werden, wenn die Merkmale sehr unterschiedliche Größenordnungen haben.
Nehmen wir zum Beispiel einen Arbeitnehmerdatensatz mit den folgenden Merkmalen:
Da das Einkommen viel größere Werte als das Alter hat, könnte ein Modell dem Einkommen allein aufgrund seiner Größe mehr Bedeutung beimessen, nicht weil es tatsächlich relevanter ist.
Hier sind einige gängige Techniken:
Skalierter Wert =( Datenpunkt - min(Spalte))/(max(Spalte) - min(Spalte))
Skalierter Wert =( Datenpunkt - Mittelwert(Spalte))/(std(Spalte))
Einen detaillierten Vergleich zwischen Normalisierung und Standardisierung findest du hier: Normalisierung vs. Standardisierung. Standardisierungsleitfaden.
Das Erstellen neuer, aussagekräftiger Merkmale aus bestehenden Daten bietet logischere Einblicke in das Modell.
Wenn du zum Beispiel in einem Datensatz zur Hauspreisvorhersage die Spalten length und breadth getrennt hast, kannst du ein neues Merkmal ableiten: area = length * breath price , das sich direkt auf die Zielvariable beziehen kann. Die Eingabe dieses area Merkmals in das Modell vereinfacht die Entdeckung versteckter Muster.
Bei der Merkmalsauswahl werden nur relevante Merkmale berücksichtigt, indem unnötige Spalten entfernt werden. Die Konzentration auf die informativsten Daten hilft dabei, eine Überanpassung zu vermeiden, den Rechenaufwand zu verringern und die Modellleistung zu verbessern. Hier sind einige Techniken:
Feature Engineering lässt sich am besten durch praktische Umsetzung verstehen.
Die "Hauspreisvorhersage" ist ein riesiger, realistischer Datensatz mit 81 Spalten. Ich habe es wegen seiner vielfältigen Funktionen ausgewählt, die dir helfen können, die Techniken des Feature Engineering in der Praxis besser zu verstehen.
Die ersten Schritte:
Der folgende Code identifiziert kategoriale Spalten im Datensatz und ersetzt ihre fehlenden Werte durch die häufigste Kategorie:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesFehlende numerische Werte werden durch den Mittelwert oder den Median ersetzt. Der Mittelwert ist eine beliebte Option für statistisch verteilte Daten, während der Median gut funktioniert, wenn die Spalte Ausreißer enthält. Wir werden also nach Ausreißern suchen und uns für eine Methode entscheiden.
Um potenzielle Ausreißer zu visualisieren, können wir Boxplots verwenden, die helfen, Extremwerte zu identifizieren. Im Folgenden findest du eine Python-Implementierung zur Erkennung von Ausreißern in ausgewählten numerischen Spalten:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Ausgabe:
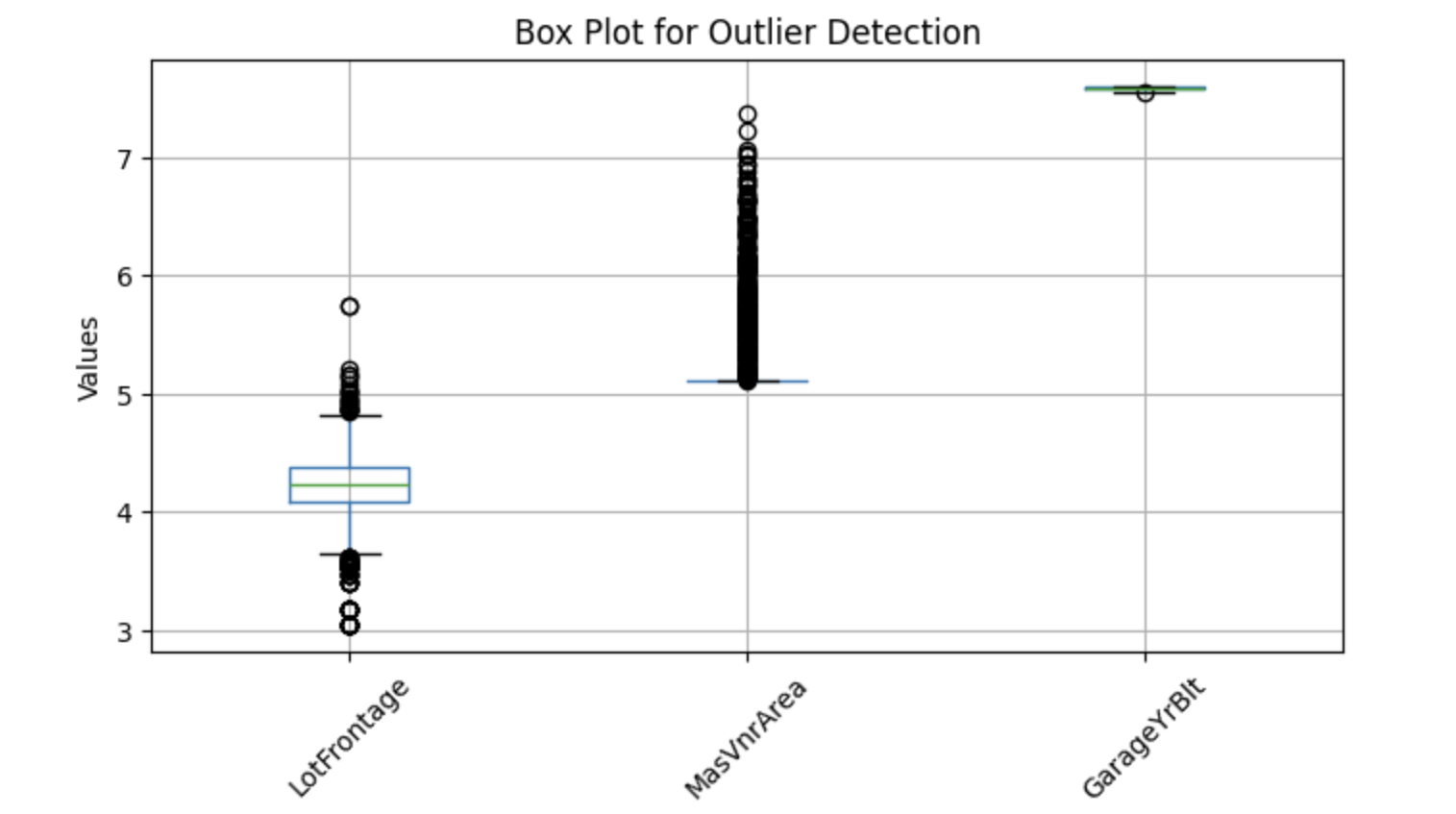
Die obigen Boxplots zeigen Punkte, die außerhalb der Whisker liegen - diese werden als Ausreißer bezeichnet. Ersetzen wir also fehlende Werte durch den Median.
Code, um Nullen durch Medianwerte zu ersetzen:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianSpalten wie YearBuilt, YearRemodAdd, GarageYrBlt und YrSold enthalten Jahre (z. B. 2001, 1976), die keinen direkten Einfluss auf die Zielvariable haben. Diese absoluten Jahreswerte haben zwar keinen direkten Einfluss auf die Hauspreise, aber wir können mehr nützliche Erkenntnisse gewinnen, wenn wir berechnen, wie alt das Haus oder die Renovierung zum Zeitpunkt des Verkaufs ist.
Anstatt YearBuilt zu verwenden, können wir zum Beispiel ein neues Merkmal erstellen: House Age=YrSold-YearBuilt
Code, um diese neuen Funktionen zu erstellen:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Beim maschinellen Lernen können sich schiefe numerische Merkmale negativ auf die Modellleistung auswirken, vor allem bei Modellen, die von einer Normalverteilung ausgehen (z. B. bei der linearen Regression). Um dies zu korrigieren, wenden wir eine Log-Transformation an.
Bevor wir eine Log-Transformation anwenden, müssen wir schiefe Merkmale identifizieren. Wir schließen jedoch Spalten mit Nullen aus, da der Logarithmus von Null undefiniert ist.
Hier ist eine Implementierung in Python, um schiefe Spalten zu erkennen:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Ausgabe:

Wir werden die Lognormalverteilung verwenden, um diese fünf schiefen Spalten in eine Gaußverteilungumzuwandeln:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Wir haben bereits verschiedene Kodierungstechniken besprochen; in diesem Beispiel werden wir die Zielkodierung anwenden.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Im obigen Code ist die Zielvariable SalePrice, also haben wir die Daten nach jeder kategorialen Spalte gruppiert und den Mittelwert SalePrice für jede Gruppe berechnet. Diese Mittelwerte wurden dann den entsprechenden kategorialen Werten in dieser Spalte zugeordnet.
Unser Datensatz ist jetzt bereit für maschinelles Lernen!
Wenn du dein Verständnis von Konzepten des überwachten Lernens vertiefen möchtest und wissen willst, wie Modelle konstruierte Merkmale nutzen, ist dieser Kurs zum überwachten Lernen mit Scikit-Learn einehervorragende Ressource.
In diesem Abschnitt stellen wir dir die am häufigsten verwendeten Python-Bibliotheken und Automatisierungstools für das Feature Engineering vor.
Pandas ist das am häufigsten verwendete Python-Framework zur Verarbeitung strukturierter Daten. Es führt viele Schritte der Merkmalstechnik durch, wie z. B. Transformation, Datenaggregation und Merkmalsextraktion. Pandas machen auch die Datenbereinigung und -manipulation einfach.
Wenn du Pandas noch nicht kennst, ist dieser Kurs zur Datenbearbeitung mit Pandas ein guter Startpunkt.
Scikit-learn ist eine leistungsstarke Bibliothek für maschinelles Lernen mit verschiedenen Werkzeugen für das Feature Engineering. Sie enthält Methoden wie OneHotEncoder und LabelEncoder, um kategorische in numerische Variablen umzuwandeln. Es bietet auch Methoden zur Skalierung von Merkmalen wie StandardScaler und Minmaxscaler.
Feature-engine ist eine offeneurce Python-Bibliothek, die eine Vielzahl von Transformatoren zur Vereinfachung des Feature-Engineering bietet. Diese Transformatoren sind spezialisierte Werkzeuge für bestimmte Aufgaben, z. B. für die Imputation fehlender Daten, die Behandlung von Ausreißern, die Auswahl von Merkmalen und die Diskretisierung. Diese Transformatoren sind vollständig mit scikit-learn kompatibel und können als Eingabeparameter für das Tuning der Hyperparameter übergeben werden.
fit() eine fit_transform() Methode, die gleichzeitig Anpassungs- und Transformationsoperationen an den Eingabedaten durchführt. Außerdem sind FeatureSelector und AutoFeatLight für die Auswahl und Skalierung von Merkmalen verfügbar.Um Feature Engineering effektiv umzusetzen, solltest du dich an diesen Best Practices orientieren.
Wenn du die Bedeutung und Wichtigkeit jedes Merkmals verstehst, kannst du Techniken wie die Merkmalsauswahl oder -extraktion viel einfacher durchführen. Ich schlage vor, du recherchierst deine Daten und das relevante Fachwissen für ein effektives Feature Engineering.
Nutze Python-Bibliotheken wie Pandas und Matplotlib, um umfassende explorative Datenanalysen durchzuführen,z. B. statistische Informationen, Visualisierungen und Korrelationen, um Muster und potenzielle Beziehungen in den Daten zu finden.
Bei der Erstellung von Interaktionsmerkmalen geht es darum, Beziehungen zwischen bestehenden Merkmalen zu erkennen und neue Merkmale abzuleiten. Bei der Vorhersage von Hauspreisen zum Beispiel zeigt die Berechnung des Alters eines Hauses durch Subtraktion des Baujahrs vom aktuellen Jahr Trends auf, wie z. B. sinkende Hauspreise im Laufe der Zeit.
Verschiedene Machine-Learning-Modelle erfordern unterschiedliche Schritte der Merkmalstechnik. Zum Beispiel profitieren Modelle wie lineare oder multiple Regression, SVM und KNN oft von der Standardisierung der Merkmale, aber diese Technik hilft baumbasierten Modellen nicht.
Wenn du dich also schon im Voraus für dein Modell entscheidest, kannst du eine effektive Feature-Engineering-Pipeline für deinen Anwendungsfall aufbauen.
Das Feature-Engineering ist ein wesentlicher Bestandteil der Entwicklung von Machine-Learning-Lösungen und ermöglicht es dir, Features auf die effizienteste Weise zu nutzen. Dieser Prozess wird von Datenwissenschaftlern oder ML-Ingenieuren durchgeführt, wenn sie mit einem beliebigen Datensatz arbeiten. Wenn du ein Datenexperte bist oder einer werden willst, wird dir das Beherrschen aller in diesem Artikel genannten Techniken helfen, deine Karriere voranzutreiben!
Wenn du diese Techniken genauer kennenlernen möchtest, schau dir die DataCamp-Kurseüber Feature Engineering für maschinelles Lernen und Feature Engineering für NLPan. Es gibt auch einen Kurs über Feature Engineering für R-Programmierer.
Lerne mehr über maschinelles Lernen mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team

