
Cours
Machine Learning for Time Series Data in Python
4 h
53.3K
Avant d'aborder les différentes techniques d'ingénierie des fonctionnalités, commençons par comprendre les types de fonctionnalités disponibles.
Comme leur nom l'indique, les caractéristiques numériques représentent les données sous forme de nombres. Il s'agit de variables quantitatives continues. Les exemples incluent la taille, l'âge et le salaire.
Une colonne catégorielle ne peut contenir que des caractéristiques discrètes. Par exemple, le sexe d'une personne est une colonne catégorielle, car il ne peut y avoir que quelques types de sexe. Le mois de naissance est un autre exemple, car les valeurs doivent être comprises entre janvier et décembre.
Les variables catégorielles sont elles-mêmes divisées en types binaires et non binaires. Les variables binaires ont deux catégories possibles, tandis que les caractéristiques non binaires peuvent avoir plusieurs catégories.
Les colonnes textuelles contiennent uniquement des données textuelles. Il peut s'agir, par exemple, d'avis sur des produits ou de colonnes de description de produits dans un ensemble de données sur le commerce de détail.
D'autre part, les caractéristiques des séries temporelles représentent des données ponctuelles, telles que les ventes hebdomadaires ou les fluctuations du cours des actions sur une année.
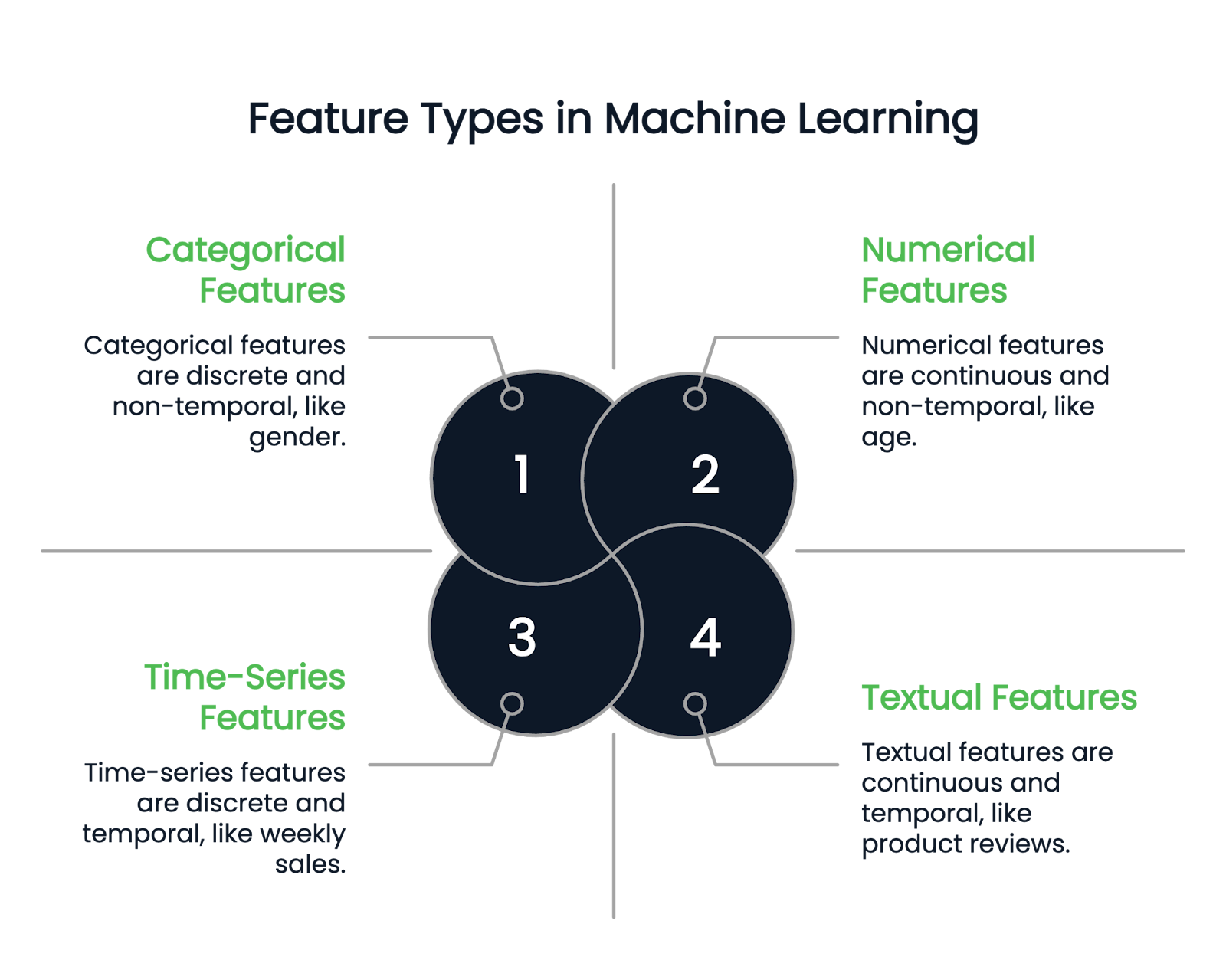
Image par l'auteur
L'ingénierie des caractéristiques offre diverses techniques puissantes pour convertir les colonnes brutes en caractéristiques souhaitables. Nous en présentons ici quelques-uns.
Les valeurs manquantes peuvent fausser les performances du modèle, c'est pourquoi il est essentiel de les traiter correctement. Il existe deux approches principales :
Pour un guide approfondi sur le traitement des données manquantes, lisez ce tutoriel Techniques pour traiter les données manquantes ou explorez ce cours Traiter les données manquantes en Python.
Les valeurs aberrantes sont des valeurs anormales significativement différentes du reste des points de données. Par exemple, si vous disposez d'un ensemble de données sur les salaires dont la plupart des observations se situent entre 90 000 et 120 000 dollars, un salaire de 400 000 ou 10 000 dollars est une valeur aberrante.
Les modèles d'apprentissage automatique ne peuvent pas traiter directement les variables catégorielles, qui doivent donc être converties en représentations numériques. Nous examinons ci-dessous quelques techniques d'encodage courantes.
Considérez un ensemble de données avec la caractéristique catégorielle suivante :
|
Nom |
Genre |
|
John |
Homme |
|
Rachel |
Femme |
|
Emma |
Femme |
En utilisant l'encodage à une touche, nous créons des colonnes distinctes pour chaque catégorie possible dans la caractéristique Gender :
|
Nom |
Femme |
Homme |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Comme Jean est un homme, la colonne "Homme" reçoit une adresse 1, tandis que la colonne "Femme" reste 0. De même, Rachel et Emma étant des femmes, la colonne "Femme" est 1 et la colonne "Homme" est 0.
Pour un tutoriel complet sur l'encodage one-hot en Python, consultez ce tutoriel sur l'encodage one-hot.
Considérons un ensemble de données avec une colonne Location contenant des valeurs catégorielles :
|
Localisation |
Valeur codée |
|
New York (en anglais) |
1 |
|
Californie |
2 |
|
Texas |
3 |
|
Californie |
2 |
|
Texas |
3 |
Chaque emplacement unique se voit attribuer une valeur numérique distincte. Cependant, comme la Californie (2) n'est pas intrinsèquement "entre" New York (1) et le Texas (3), l'utilisation du codage des étiquettes pour des données non ordinales peut conduire à des hypothèses de modèle trompeuses. Dans ce cas, il est souvent préférable d'opter pour un codage à un seul point afin d'éviter d'impliquer une relation numérique involontaire entre les catégories.
Considérez une colonne Education level avec les catégories suivantes :
|
Niveau d'éducation |
Valeur codée |
|
UG (premier cycle) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Étant donné qu'un doctorat représente un niveau d'éducation plus élevé qu'un diplôme d'études supérieures, qui est lui-même plus élevé qu'un diplôme d'études supérieures, les valeurs numériques attribuées reflètent ce classement.
Considérez un ensemble de données dans lequel Location est une caractéristique catégorielle et Target variable représente un résultat numérique :
|
Localisation |
Variable cible |
|
New York (en anglais) |
2 |
|
Californie |
3 |
|
Texas |
5 |
|
Californie |
1 |
|
Texas |
4 |
Pour coder la colonne Location, nous calculons la moyenne de Target variable pour chaque catégorie unique :
|
Localisation |
Valeur codée |
|
New York (en anglais) |
2 |
|
Californie |
2 |
|
Texas |
4.5 |
|
Californie |
2 |
|
Texas |
4.5 |
Si vous recherchez un guide plus complet sur le traitement des données catégorielles, ce tutoriel sur le traitement des données catégorielles vous apportera des informations supplémentaires.
La mise à l'échelle des caractéristiques garantit que les caractéristiques numériques se situent dans une fourchette normalisée, ce qui empêche certaines caractéristiques de dominer le processus d'apprentissage en raison de leurs valeurs plus importantes.
Les modèles d'apprentissage automatique qui reposent sur des calculs basés sur la distance (par exemple, la régression linéaire, les voisins les plus proches et les réseaux neuronaux) peuvent être affectés lorsque les caractéristiques ont des échelles très différentes.
Prenons l'exemple d'un ensemble de données relatives à un employé, avec les caractéristiques suivantes :
Étant donné que le revenu a des valeurs beaucoup plus importantes que l'âge, un modèle pourrait accorder plus d'importance au revenu simplement en raison de son échelle, et non parce qu'il est réellement plus pertinent.
Voici quelques techniques courantes :
Valeur mise à l'échelle =( point de données - min(colonne))/(max(colonne) - min(colonne))
Valeur mise à l'échelle =( point de données - moyenne(colonne))/(std(colonne))
Pour une comparaison détaillée de la normalisation et de la standardisation, consultez le site Normalization vs. Guide de normalisation.
La création de nouvelles caractéristiques significatives à partir de données existantes permet d'obtenir des informations plus logiques sur le modèle.
Par exemple, dans un ensemble de données de prévision du prix des logements, si vous disposez séparément des colonnes length et breadth, vous pouvez dériver une nouvelle caractéristique : area = length * breath qui peut être directement liée à la variable cible, price. La saisie de cette caractéristique area dans le modèle simplifie la découverte de modèles cachés.
La sélection des caractéristiques ne conserve que les caractéristiques pertinentes en supprimant les colonnes inutiles. Le fait de se concentrer sur les données les plus informatives permet d'éviter l'ajustement excessif, de réduire la complexité des calculs et d'améliorer les performances du modèle. Voici quelques techniques :
La meilleure façon de comprendre l'ingénierie des fonctionnalités est de la mettre en pratique.
La "prédiction du prix des maisons" est un énorme ensemble de données réelles comportant 81 colonnes. Je l'ai sélectionné pour la diversité de ses caractéristiques, qui peuvent vous aider à mieux comprendre les techniques d'ingénierie des caractéristiques dans la pratique.
Pour commencer :
Le code suivant identifie les colonnes catégorielles de l'ensemble de données et remplace leurs valeurs manquantes par la catégorie la plus fréquente :
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesNous traitons les valeurs manquantes numériques en les remplaçant par la moyenne ou la médiane. La moyenne est une option plus populaire pour les données statistiquement distribuées, tandis que la médiane fonctionne bien lorsque la colonne présente des valeurs aberrantes. Nous allons donc vérifier s'il y a des valeurs aberrantes et décider de la méthode.
Pour visualiser les valeurs aberrantes potentielles, nous pouvons utiliser des diagrammes en boîte, qui permettent d'identifier les valeurs extrêmes. Vous trouverez ci-dessous une implémentation Python permettant de détecter les valeurs aberrantes dans des colonnes numériques sélectionnées :
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Sortie :
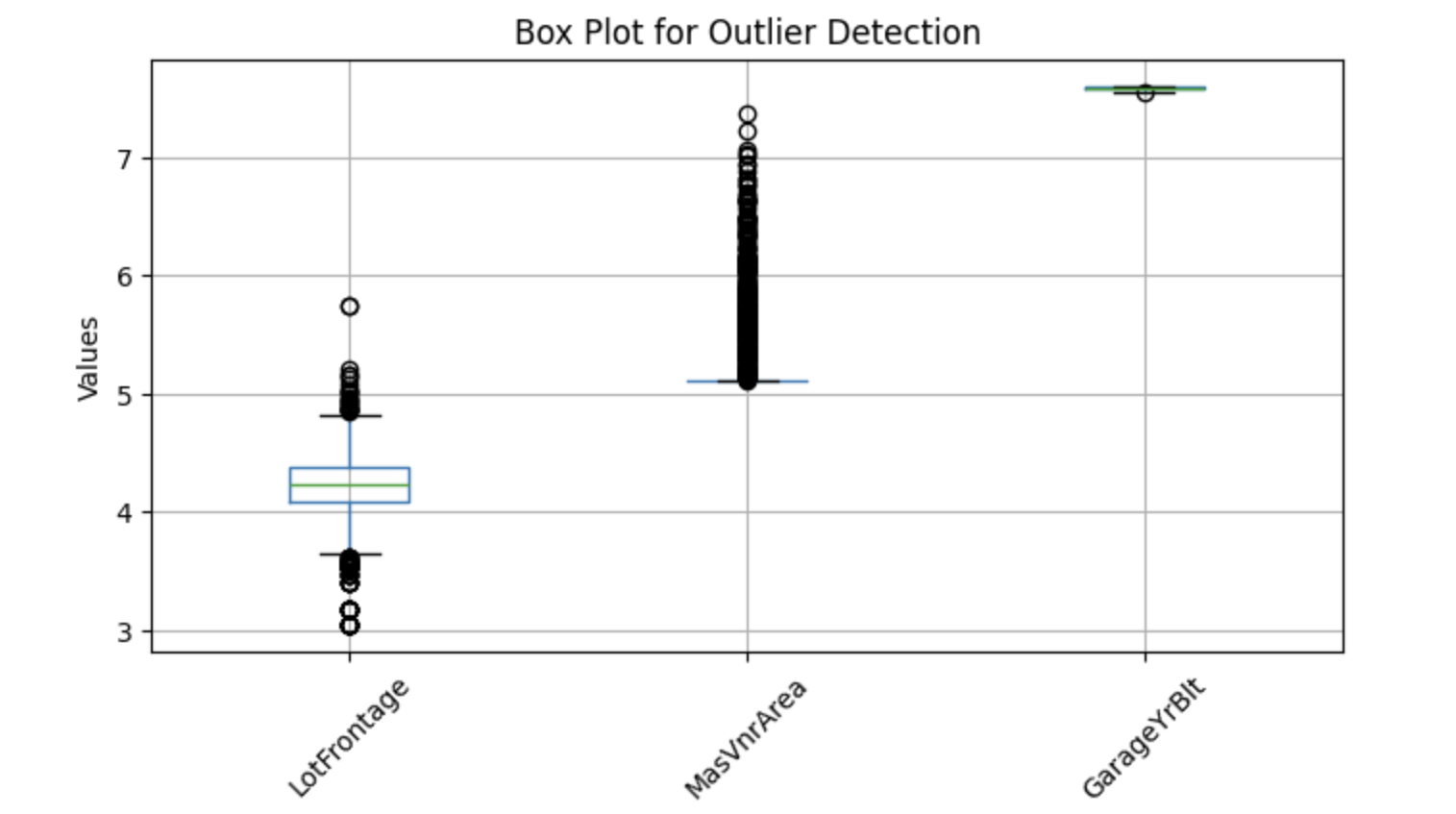
Les diagrammes en boîte ci-dessus présentent des points en dehors des moustaches : ce sont les valeurs aberrantes. Remplaçons donc les valeurs manquantes par la médiane.
Code pour remplacer les valeurs nulles par des valeurs médianes :
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianLes colonnes telles que YearBuilt, YearRemodAdd, GarageYrBlt, et YrSold contiennent des années (par exemple, 2001, 1976) qui n'influencent pas directement la variable cible. Bien que ces valeurs absolues n'aient pas d'incidence directe sur le prix des maisons, nous pouvons obtenir des informations plus utiles en calculant l'âge de la maison ou de la rénovation au moment de la vente.
Par exemple, au lieu d'utiliser YearBuilt, nous pouvons créer une nouvelle caractéristique : House Age=YrSold-YearBuilt
pour créer ces nouvelles fonctionnalités :
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Dans l'apprentissage automatique, les caractéristiques numériques asymétriques peuvent avoir un impact négatif sur les performances du modèle, en particulier pour les modèles qui supposent une distribution normale (par exemple, la régression linéaire). Pour corriger ce problème, nous appliquons une transformation logarithmique.
Avant d'appliquer une transformation logarithmique, nous devons identifier les caractéristiques asymétriques. Cependant, nous excluons les colonnes contenant des zéros car le logarithme de zéro n'est pas défini.
Voici une implémentation en Python pour identifier les colonnes asymétriques :
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Sortie :

Nous utiliserons la distribution log-normale pour convertir ces cinq colonnes asymétriques enune distribution gaussienne:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Nous avons abordé précédemment plusieurs techniques d'encodage ; dans cet exemple, nous appliquerons l'encodage cible.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Dans le code ci-dessus, la variable cible est SalePrice, nous avons donc regroupé les données par colonne catégorielle et calculé la moyenne SalePrice pour chaque groupe. Ces valeurs moyennes ont ensuite été attribuées aux valeurs catégorielles correspondantes dans cette colonne.
Notre ensemble de données est maintenant prêt pour l'apprentissage automatique !
Si vous souhaitez renforcer votre compréhension des concepts de l'apprentissage supervisé et de la manière dont les modèles utilisent les caractéristiques techniques, ce cours sur l'apprentissage supervisé avec Scikit-Learn est uneexcellente ressource.
Dans cette section, nous allons passer en revue les bibliothèques Python et les outils d'automatisation les plus utilisés pour mettre en œuvre l'ingénierie des fonctionnalités.
Pandas est le framework Python le plus utilisé pour traiter les données structurées. Il effectue de nombreuses étapes d'ingénierie des caractéristiques, telles que la transformation, l'agrégation des données et l'extraction des caractéristiques. Les Pandas facilitent également le nettoyage et la manipulation des données.
Si vous êtes novice en matière de pandas, ce cours sur la manipulation des données avec pandas est un excellent point de départ.
Scikit-learn est une puissante bibliothèque d'apprentissage automatique dotée de divers outils pour l'ingénierie des caractéristiques. Il contient des méthodes telles que OneHotEncoder et LabelEncoder pour convertir les variables catégorielles en variables numériques. Il propose également des méthodes de mise à l'échelle des caractéristiques telles que StandardScaler et Minmaxscaler.
Feature-engine est une bibliothèque Python ouverte-source offrant une variété de transformateurs pour simplifier l'ingénierie des fonctionnalités. Ces transformateurs sont des outils spécialisés pour des tâches spécifiques, telles que l'imputation des données manquantes, le traitement des valeurs aberrantes, la sélection des caractéristiques et la discrétisation. Entièrement compatibles avec scikit-learn, ces transformateurs peuvent être transmis comme paramètres d'entrée pour l'ajustement des hyperparamètres.
fit(), la bibliothèque propose une méthode fit_transform() qui effectue simultanément des opérations d'ajustement et de transformation sur les données d'entrée. En outre, les modèles FeatureSelector et AutoFeatLight sont disponibles pour la sélection et la mise à l'échelle des caractéristiques.Pour mettre en œuvre efficacement l'ingénierie des fonctionnalités, concentrez-vous sur les meilleures pratiques suivantes.
En comprenant la signification et l'importance de chaque caractéristique, il vous sera beaucoup plus facile d'utiliser des techniques telles que la sélection ou l'extraction de caractéristiques. Je vous suggère de faire des recherches sur vos données et sur les connaissances pertinentes du domaine pour une ingénierie des fonctionnalités efficace.
Utilisez les bibliothèques Python telles que Pandas et Matplotlib pour effectuer une analyse exploratoire complète des données,comme l'exploration des informations statistiques, des visualisations et des corrélations pour trouver des modèles et des relations potentielles au sein des données.
La création de caractéristiques d'interaction implique d'identifier les relations entre les caractéristiques existantes et d'en dériver de nouvelles. Par exemple, dans le cadre de la prédiction du prix des maisons, le calcul de l'âge d'une maison en soustrayant l'année de sa construction de l'année en cours permet de mettre en évidence des tendances, telles que la baisse du prix des maisons au fil du temps.
Différents modèles d'apprentissage automatique nécessitent différentes étapes d'ingénierie des caractéristiques. Par exemple, les modèles tels que la régression linéaire ou multiple, les SVM et les KNN bénéficient souvent de la normalisation des caractéristiques, mais cette technique n'aide pas les modèles basés sur les arbres.
Ainsi, le fait de décider à l'avance de votre modèle peut vous aider à construire un pipeline d'ingénierie fonctionnelle efficace pour votre cas d'utilisation.
L'ingénierie des fonctionnalités fait partie intégrante de l'élaboration de solutions d'apprentissage automatique, vous permettant d'exploiter les fonctionnalités de la manière la plus efficace possible. Ce processus est mis en œuvre par les scientifiques des données ou les ingénieurs ML lorsqu'ils traitent un ensemble de données. Si vous êtes un professionnel des données ou si vous souhaitez le devenir, la maîtrise de toutes les techniques mentionnées dans cet article vous aidera à faire progresser votre carrière !
Pour explorer ces techniques plus en détail, consultez lescours DataCampsur l'ingénierie des fonctionnalités pour l'apprentissage automatique et l'ingénierie des fonctionnalités pour le NLP. Il existe également un cours sur l'ingénierie des fonctionnalités pour les programmeurs R.
Apprenez-en plus sur l'apprentissage automatique grâce à ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Mark Pedigo
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
Tutoriel
Moez Ali
