Curso
Machine Learning para dados de séries temporais em Python
4 h
53.3K
Antes de mergulhar nas diferentes técnicas de engenharia de recursos, vamos primeiro entender os tipos de recursos disponíveis.
Como o nome sugere, os recursos numéricos representam dados em números. São variáveis quantitativas contínuas. Os exemplos incluem altura, idade e salário.
Uma coluna categórica pode conter apenas recursos discretos. Por exemplo, o gênero de uma pessoa é uma coluna categórica, pois só pode ter alguns tipos de gênero. O mês de nascimento é outro exemplo, pois os valores devem estar entre janeiro e dezembro.
As variáveis categóricas são ainda divididas em tipos binários e não binários. As variáveis binárias têm duas categorias possíveis, enquanto os recursos não binários podem ter várias categorias.
As colunas textuais contêm apenas dados de texto. Os exemplos incluem análises de produtos ou colunas de descrição de produtos em um conjunto de dados de varejo.
Por outro lado, os recursos de séries temporais representam dados oportunos, como vendas semanais ou flutuações de preços de ações ao longo de um ano.
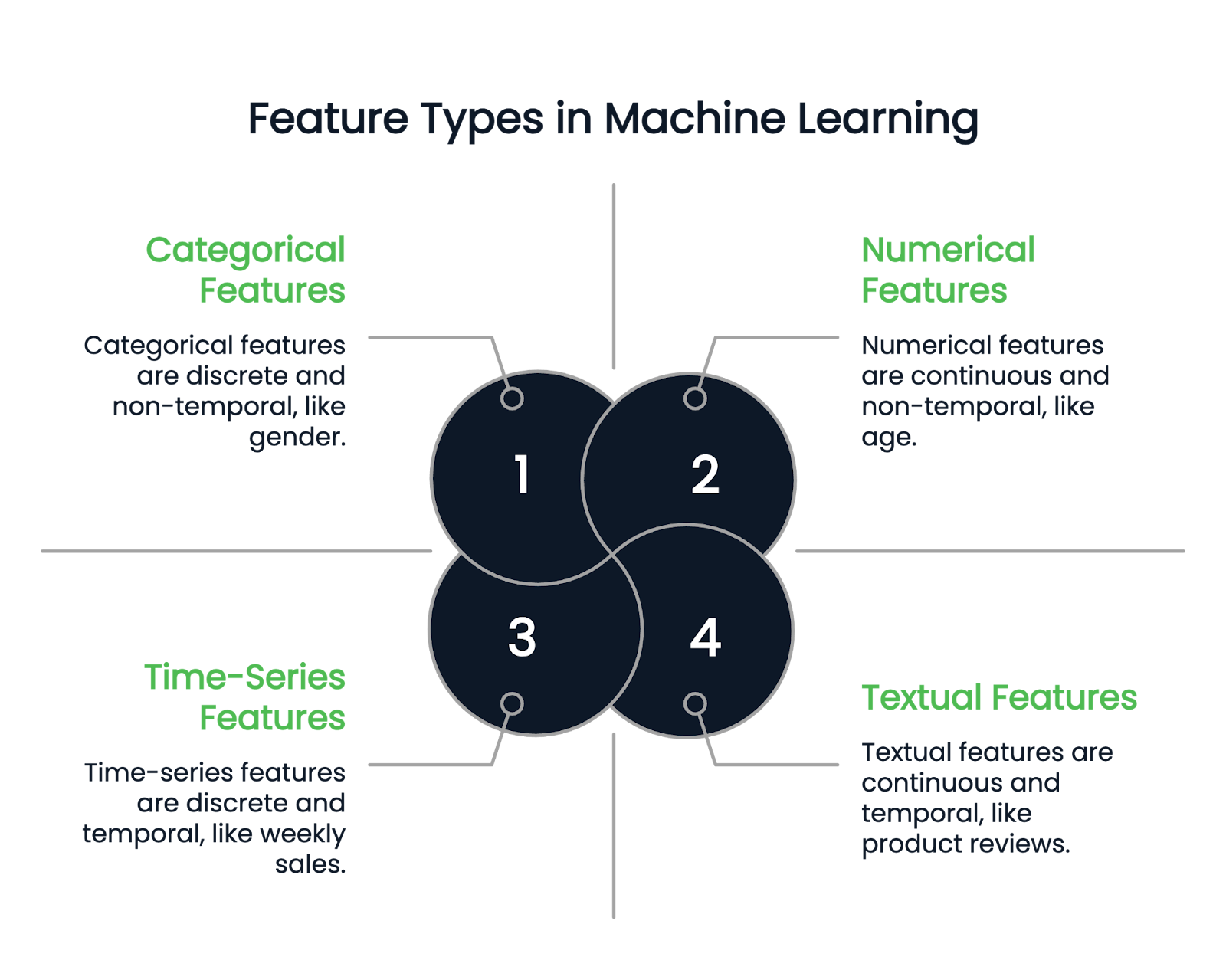
Imagem do autor
A engenharia de recursos oferece várias técnicas avançadas para converter colunas brutas em recursos desejáveis. Aqui, discutiremos alguns dos mais importantes.
Os valores ausentes podem distorcer o desempenho do modelo, portanto, é fundamental lidar com eles adequadamente. Há duas abordagens principais:
Para obter um guia detalhado sobre como lidar com dados ausentes, leia este tutorial Técnicas para lidar com dados ausentes ou explore este curso Lidando com dados ausentes em Python.
Os outliers são valores anormais significativamente diferentes do restante dos pontos de dados. Por exemplo, se você tiver um conjunto de dados de salário com a maioria das observações entre US$ 90 mil e US$ 120 mil, um número de salário como US$ 400 mil ou US$ 10 mil é um valor atípico.
Os modelos de machine learning não podem processar diretamente variáveis categóricas, portanto, elas devem ser convertidas em representações numéricas. A seguir, discutiremos algumas técnicas populares de codificação.
Considere um conjunto de dados com o seguinte recurso categórico:
|
Nome |
Gênero |
|
John |
Masculino |
|
Rachel |
Feminino |
|
Emma |
Feminino |
Usando a codificação one-hot, criamos colunas separadas para cada categoria possível no recurso Gender:
|
Nome |
Feminino |
Masculino |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Como John é do sexo masculino, a coluna "Male" recebe um 1, enquanto a coluna "Female" permanece 0. Da mesma forma, Rachel e Emma são do sexo feminino, portanto a coluna "Female" é 1 e a coluna "Male" é 0.
Para obter um tutorial completo sobre codificação one-hot em Python, confira este Tutorial de codificação one-hot.
Considere um conjunto de dados com uma coluna Location contendo valores categóricos:
|
Localização |
Valor codificado |
|
Nova York |
1 |
|
Califórnia |
2 |
|
Texas |
3 |
|
Califórnia |
2 |
|
Texas |
3 |
Cada local exclusivo é atribuído a um valor numérico distinto. No entanto, como a Califórnia (2) não está inerentemente "entre" Nova York (1) e Texas (3), o uso da codificação de rótulos para dados não ordinais pode levar a suposições de modelo enganosas. Nesses casos, a codificação de um único ponto é geralmente preferida para evitar a implicação de uma relação numérica não intencional entre as categorias.
Considere uma coluna Education level com as seguintes categorias:
|
Nível de escolaridade |
Valor codificado |
|
UG (Graduação) |
1 |
|
PG (Pós-graduação) |
2 |
|
PhD |
3 |
Como o PhD representa um nível mais alto de educação do que o PG, que, por sua vez, é mais alto do que o UG, os valores numéricos atribuídos refletem essa classificação.
Considere um conjunto de dados em que Location é um recurso categórico e o Target variable representa algum resultado numérico:
|
Localização |
Variável-alvo |
|
Nova York |
2 |
|
Califórnia |
3 |
|
Texas |
5 |
|
Califórnia |
1 |
|
Texas |
4 |
Para codificar a coluna Location, calculamos a média do Target variable para cada categoria exclusiva:
|
Localização |
Valor codificado |
|
Nova York |
2 |
|
Califórnia |
2 |
|
Texas |
4.5 |
|
Califórnia |
2 |
|
Texas |
4.5 |
Se você estiver procurando um guia mais amplo sobre como lidar com dados categóricos, este Tutorial de manipulação de dados categóricos fornece insights adicionais.
O escalonamento de recursos garante que os recursos numéricos estejam dentro de um intervalo padronizado, evitando que alguns recursos dominem o processo de aprendizado devido a seus valores maiores.
Os modelos de machine learning que dependem de cálculos baseados em distância (por exemplo, regressão linear, k-nearest neighbors e redes neurais) podem ser afetados quando os recursos têm escalas muito diferentes.
Por exemplo, considere um conjunto de dados de funcionários com os seguintes recursos:
Como a renda tem valores muito maiores do que a idade, um modelo pode atribuir mais importância à renda simplesmente por causa de sua escala, e não porque ela seja realmente mais relevante.
Aqui estão algumas técnicas comuns:
Valor escalonado =( ponto de dados - min(coluna))/(max(coluna) - min(coluna))
Valor escalonado =( ponto de dados - média(coluna))/(std(coluna))
Para obter uma comparação detalhada entre normalização e padronização, consulte o site Normalização vs. padronização. Guia de padronização.
A criação de recursos novos e significativos a partir de dados existentes fornece insights mais lógicos sobre o modelo.
Por exemplo, em um conjunto de dados de previsão de preços de imóveis, se você tiver as colunas length e breadth separadamente, poderá derivar um novo recurso: area = length * breath, que pode se relacionar diretamente com a variável de destino, price. A inserção desse recurso area no modelo simplifica a descoberta de padrões ocultos.
A seleção de recursos mantém apenas os recursos relevantes, removendo colunas desnecessárias. O foco nos dados mais informativos ajuda a evitar o excesso de ajuste, reduz a complexidade computacional e melhora o desempenho do modelo. Aqui estão algumas técnicas:
A engenharia de recursos é melhor compreendida por meio da implementação prática.
A "previsão de preços de imóveis" é um enorme conjunto de dados do mundo real com 81 colunas. Eu o selecionei por sua variedade de recursos, que podem ajudar você a entender melhor as técnicas de engenharia de recursos na prática.
Como começar:
O código a seguir identifica colunas categóricas no conjunto de dados e substitui seus valores ausentes pela categoria mais frequente:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesLidamos com valores numéricos ausentes substituindo-os pela média ou mediana. A média é uma opção mais popular para dados distribuídos estatisticamente, enquanto a mediana funciona bem quando a coluna tem valores discrepantes. Portanto, verificaremos se há valores discrepantes e decidiremos sobre o método.
Para visualizar possíveis outliers, podemos usar gráficos de caixa, que ajudam a identificar valores extremos. Abaixo você encontra uma implementação em Python para detectar outliers em colunas numéricas selecionadas:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Saída:
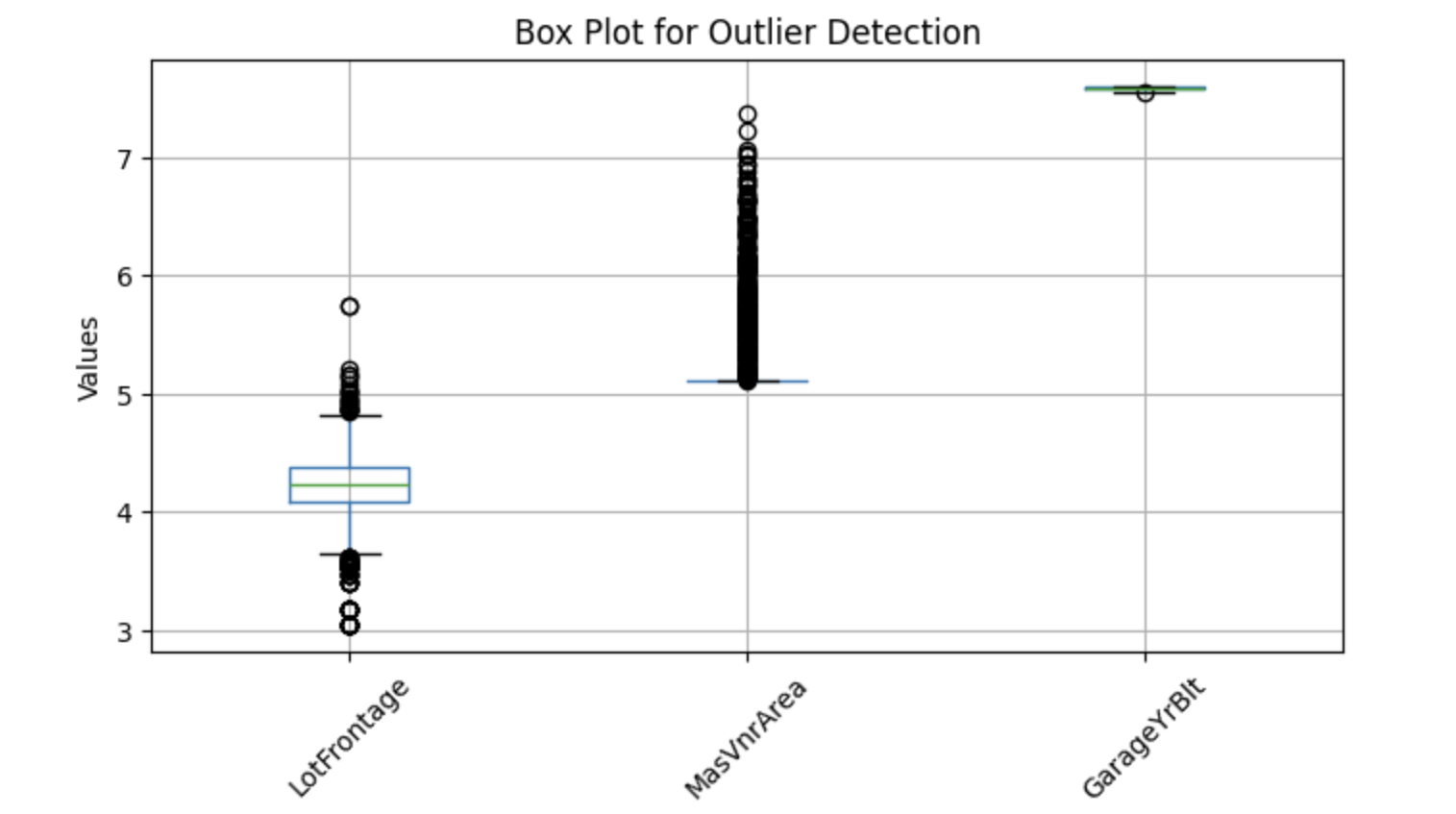
Os boxplots acima mostram pontos fora dos bigodes - esses são chamados de outliers. Portanto, vamos substituir os valores ausentes pela mediana.
Código para substituir nulos por valores medianos:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianColunas como YearBuilt, YearRemodAdd, GarageYrBlt e YrSold contêm anos (por exemplo, 2001, 1976) que não influenciam diretamente a variável de destino. Embora esses valores absolutos de ano possam não afetar diretamente os preços dos imóveis, podemos obter insights mais úteis calculando a idade da casa ou da reforma no momento da venda.
Por exemplo, em vez de usar YearBuilt, podemos criar um novo recurso: House Age=YrSold-YearBuilt
Código para criar esses novos recursos:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]No machine learning, os recursos numéricos distorcidos podem afetar negativamente o desempenho do modelo, especialmente para modelos que assumem uma distribuição normal (por exemplo, regressão linear). Para corrigir isso, aplicamos a transformação de log.
Antes de aplicar uma transformação de log, devemos identificar os recursos distorcidos. No entanto, excluímos as colunas que contêm zeros, pois o logaritmo de zero é indefinido.
Aqui está uma implementação em Python para que você identifique colunas distorcidas:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Saída:

Usaremos a distribuição log-normal para converter essas cinco colunas distorcidas emuma distribuição gaussiana:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Discutimos anteriormente várias técnicas de codificação; neste exemplo, aplicaremos a codificação de destino.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)No código acima, a variável de destino é SalePrice, portanto, agrupamos os dados por cada coluna categórica e calculamos a média SalePrice para cada grupo. Esses valores médios foram então atribuídos aos valores categóricos correspondentes nessa coluna.
Agora, nosso conjunto de dados está pronto para o machine learning!
Se você quiser aumentar sua compreensão dos conceitos de aprendizagem supervisionada e de como os modelos utilizam recursos projetados, este curso de aprendizagem supervisionada com Scikit-Learn é umexcelente recurso.
Nesta seção, examinaremos as bibliotecas Python e as ferramentas de automação mais usadas para implementar a engenharia de recursos.
O Pandas é a estrutura Python mais usada para lidar com dados estruturados. Ele executa várias etapas de engenharia de recursos, como transformação, agregação de dados e extração de recursos. O Pandas também facilita a limpeza e a manipulação de dados.
Se você ainda não conhece o pandas, este curso Manipulação de dados com pandas é um ótimo ponto de partida.
O Scikit-learn é uma biblioteca avançada de machine learning com várias ferramentas para engenharia de recursos. Ele contém métodos como OneHotEncoder e LabelEncoder para converter variáveis categóricas em numéricas. Ele também oferece métodos de dimensionamento de recursos, como StandardScaler e Minmaxscaler.
Feature-engine é uma biblioteca Python de código aberto que oferece uma variedade de transformadores para simplificar a engenharia de recursos. Esses transformadores são ferramentas especializadas para tarefas específicas, como imputação de dados ausentes, tratamento de outlier, seleção de recursos e discretização. Totalmente compatíveis com o scikit-learn, esses transformadores podem ser passados como parâmetros de entrada para ajuste de hiperparâmetros.
fit(), a biblioteca oferece um método fit_transform() que executa simultaneamente operações de ajuste e transformação nos dados de entrada. Além disso, os modelos FeatureSelector e AutoFeatLight estão disponíveis para seleção e dimensionamento de recursos.Para implementar com eficácia a engenharia de recursos, concentre-se nestas práticas recomendadas.
Compreender o significado e a importância de cada recurso torna muito mais fácil para você executar técnicas como seleção ou extração de recursos. Sugiro que você pesquise seus dados e o conhecimento de domínio relevante para uma engenharia de recursos eficaz.
Utilize as bibliotecas Python, como Pandas e Matplotlib, para realizar análises exploratórias de dados abrangentes,como explorar informações estatísticas, visualizações e correlações para encontrar padrões e possíveis relações nos dados.
A criação de recursos de interação envolve a identificação de relações entre os recursos existentes e a derivação de novos recursos. Por exemplo, na previsão de preços de imóveis, o cálculo da idade de um imóvel subtraindo o ano em que foi construído do ano atual destaca tendências, como a diminuição dos preços dos imóveis com o passar do tempo.
Diferentes modelos de machine learning exigem diferentes etapas de engenharia de recursos. Por exemplo, modelos como regressão linear ou múltipla, SVM e KNN geralmente se beneficiam da padronização de recursos, mas essa técnica não ajuda os modelos baseados em árvores.
Portanto, decidir o modelo com antecedência pode ajudar você a criar um pipeline de engenharia de recursos eficaz para o seu caso de uso.
A engenharia de recursos é parte integrante da criação de soluções de machine learning, permitindo que você aproveite os recursos da maneira mais eficiente. O processo é realizado por cientistas de dados ou engenheiros de ML ao lidar com qualquer conjunto de dados. Se você é um profissional de dados ou pretende se tornar um, dominar todas as técnicas mencionadas neste artigo o ajudará a avançar em sua carreira!
Para explorar essas técnicas em mais detalhes, confira oscursos do DataCampsobre engenharia de recursos para machine learning e engenharia de recursos para NLP. Há também um curso sobre engenharia de recursos para programadores de R.
Aprenda mais sobre machine learning com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Abid Ali Awan
Tutorial
Oluseye Jeremiah