
Corso
Machine Learning for Time Series Data in Python
4 h
53.2K
Prima di addentrarci nelle diverse tecniche di feature engineering, capiamo innanzitutto i tipi di feature disponibili.
Come suggerisce il nome, le feature numeriche rappresentano i dati in numeri. Sono variabili quantitative continue. Esempi includono altezza, età e stipendio.
Una colonna categorica può contenere solo feature discrete. Per esempio, il genere di una persona è una colonna categorica, poiché può avere solo alcuni tipi di genere. Il mese di nascita è un altro esempio perché i valori devono rientrare tra gennaio e dicembre.
Le variabili categoriche sono ulteriormente suddivise in binarie e non binarie. Le variabili binarie hanno due possibili categorie, mentre le feature non binarie possono avere più categorie.
Le colonne testuali contengono solo dati di testo. Esempi includono recensioni di prodotti o colonne con descrizioni di prodotti in un dataset retail.
Le feature di serie temporali, invece, rappresentano dati nel tempo, come vendite settimanali o fluttuazioni dei prezzi azionari nel corso di un anno.
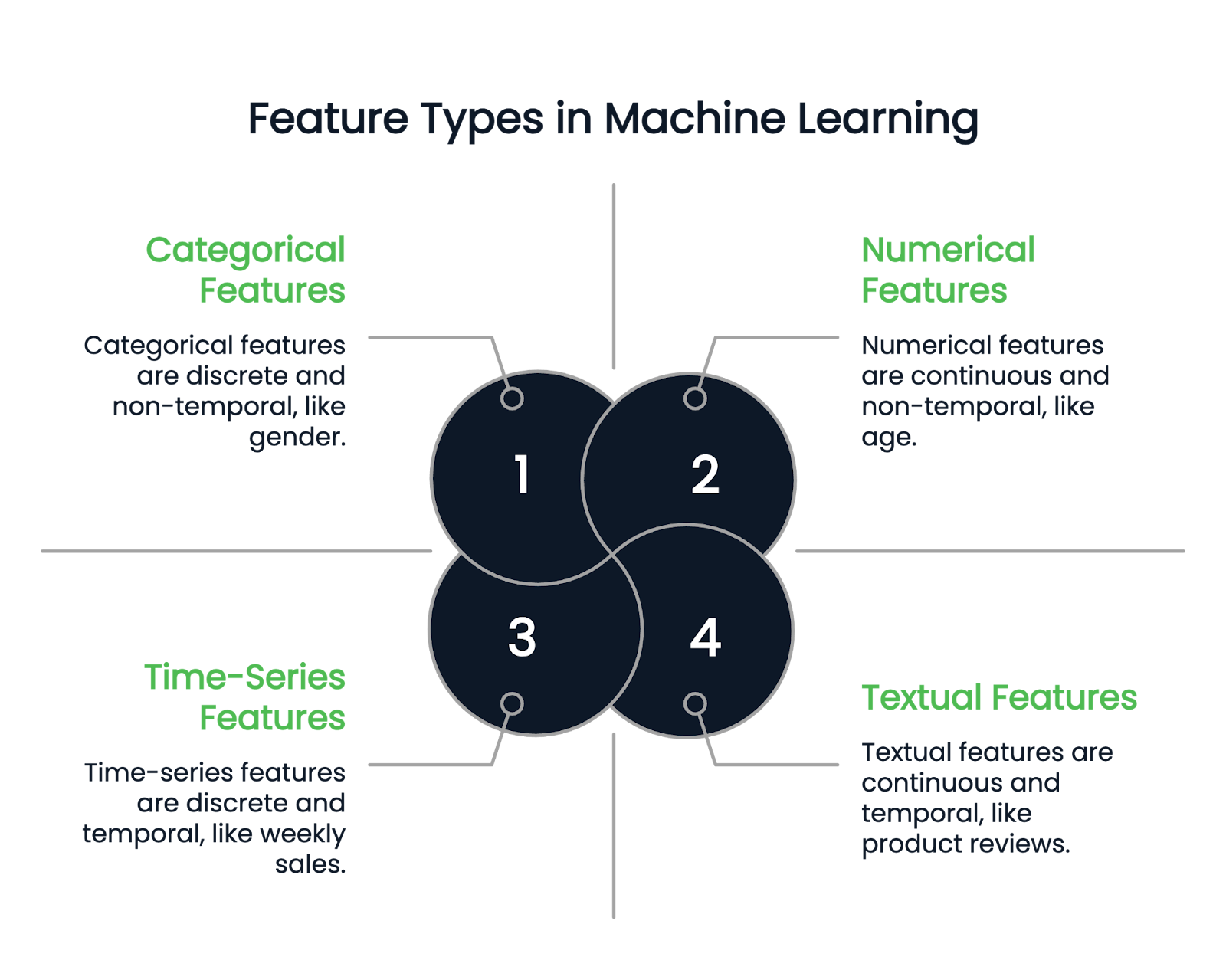
Immagine dell'autore
Il feature engineering offre varie tecniche potenti per convertire colonne grezze in feature desiderabili. Qui ne discutiamo alcune tra le più rilevanti.
I valori mancanti possono distorcere le prestazioni del modello, quindi gestirli correttamente è fondamentale. Esistono due approcci principali:
Per una guida approfondita sulla gestione dei dati mancanti, leggi questo tutorial sulle tecniche per gestire i valori mancanti o esplora questo corso Dealing with Missing Data in Python.
Gli outlier sono valori anomali significativamente diversi dal resto dei punti dati. Per esempio, se hai un dataset di stipendi con la maggior parte delle osservazioni tra 90.000 $ e 120.000 $, uno stipendio come 400.000 $ o 10.000 $ è un outlier.
I modelli di machine learning non possono elaborare direttamente variabili categoriche, quindi devono essere convertite in rappresentazioni numeriche. Di seguito discutiamo alcune tecniche di encoding popolari.
Considera un dataset con la seguente feature categorica:
|
Nome |
Genere |
|
John |
Maschio |
|
Rachel |
Femmina |
|
Emma |
Femmina |
Usando il one-hot encoding, creiamo colonne separate per ogni categoria possibile nella feature Gender feature:
|
Nome |
Femmina |
Maschio |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Poiché John è Maschio, la colonna "Maschio" ottiene un 1, mentre la colonna "Femmina" resta 0. Allo stesso modo, Rachel ed Emma sono Femmina, quindi la colonna "Femmina" vale 1 e la colonna "Maschio" 0.
Per un tutorial completo sul one-hot encoding in Python, dai un'occhiata a questo One-Hot Encoding Tutorial.
Considera un dataset con una colonna Location contenente valori categorici:
|
Località |
Valore codificato |
|
New York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
A ogni località univoca viene assegnato un valore numerico distinto. Tuttavia, poiché California (2) non è intrinsecamente "tra" New York (1) e Texas (3), usare il label encoding per dati non ordinali può portare ad assunzioni fuorvianti del modello. In questi casi, il one-hot encoding è spesso preferito per evitare di implicare una relazione numerica indesiderata tra categorie.
Considera una colonna Education level con le seguenti categorie:
|
Livello di istruzione |
Valore codificato |
|
UG (Undergraduate) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Poiché un PhD rappresenta un livello di istruzione più alto di un PG, che a sua volta è più alto di UG, i valori numerici assegnati riflettono questa graduatoria.
Considera un dataset in cui Location è una feature categorica e la Target variable rappresenta un qualche esito numerico:
|
Località |
Variabile target |
|
New York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Per codificare la colonna Location, calcoliamo la media della Target variable per ogni categoria unica:
|
Località |
Valore codificato |
|
New York |
2 |
|
California |
2 |
|
Texas |
4,5 |
|
California |
2 |
|
Texas |
4,5 |
Se cerchi una guida più ampia sulla gestione dei dati categorici, questo tutorial sulla gestione dei dati categorici offre ulteriori approfondimenti.
Il feature scaling assicura che le feature numeriche rientrino in un intervallo standardizzato, evitando che alcune feature dominino il processo di apprendimento a causa dei loro valori più grandi.
I modelli di machine learning che si basano su calcoli di distanza (ad esempio, regressione lineare, k-nearest neighbors e reti neurali) possono essere influenzati quando le feature hanno scale molto diverse.
Per esempio, considera un dataset di dipendenti con le seguenti feature:
Poiché il reddito ha valori molto più grandi dell'età, un modello potrebbe attribuire maggiore importanza al reddito semplicemente per via della scala, non perché sia effettivamente più rilevante.
Ecco alcune tecniche comuni:
Valore scalato =( datapoint - min(colonna))/(max(colonna) - min(colonna))
Valore scalato =( datapoint - mean(colonna))/(std(colonna))
Per un confronto dettagliato tra normalizzazione e standardizzazione, dai un'occhiata a questa guida Normalization vs. Standardization.
Creare nuove feature significative a partire dai dati esistenti offre insight più logici per il modello.
Per esempio, in un dataset di previsione dei prezzi delle case, se hai le colonne length e breadth separatamente, puoi derivare una nuova feature: area = length * breath, che può essere direttamente correlata alla variabile target, price. Fornire questa feature area al modello semplifica la scoperta di pattern nascosti.
La selezione delle feature mantiene solo le feature rilevanti rimuovendo le colonne non necessarie. Concentrarsi sui dati più informativi aiuta a prevenire l'overfitting, ridurre la complessità computazionale e migliorare le prestazioni del modello. Ecco alcune tecniche:
Il feature engineering si comprende al meglio tramite l'implementazione pratica.
Il dataset "house price prediction" è grande e reale, con 81 colonne. L'ho selezionato per l'ampia gamma di feature, che può aiutarti a comprendere meglio le tecniche di feature engineering in pratica.
Per iniziare:
Il seguente codice identifica le colonne categoriche nel dataset e sostituisce i loro valori mancanti con la categoria più frequente:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesGestiamo i valori mancanti numerici sostituendoli con media o mediana. La media è un'opzione più comune per dati distribuiti statisticamente, mentre la mediana funziona bene quando la colonna ha outlier. Quindi, controlleremo la presenza di outlier e decideremo il metodo.
Per visualizzare potenziali outlier, possiamo usare i box plot, che aiutano a identificare i valori estremi. Di seguito un'implementazione Python per rilevare outlier in alcune colonne numeriche selezionate:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Output:
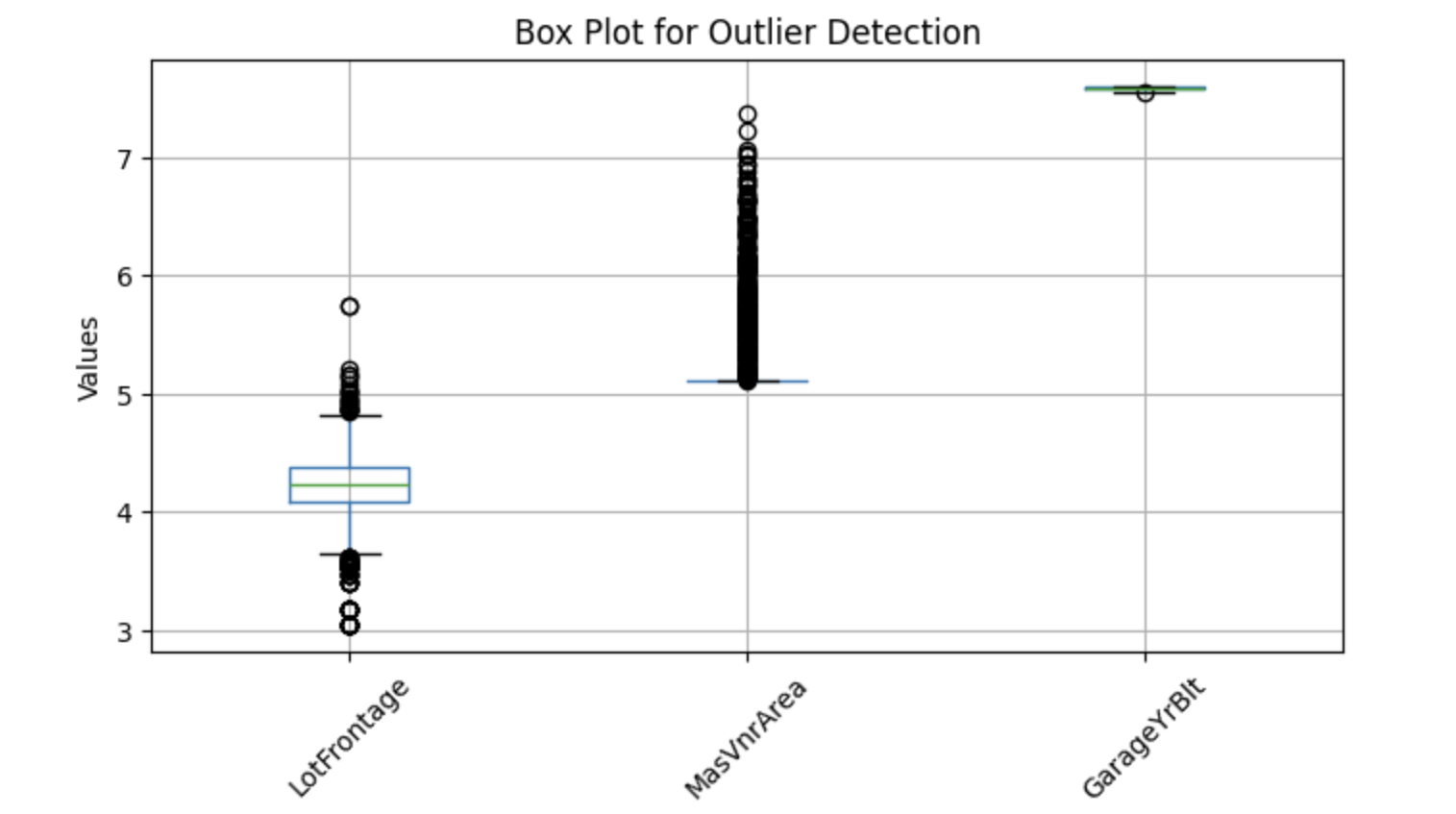
I boxplot sopra mostrano punti fuori dai baffi: questi sono chiamati outlier. Quindi, sostituiamo i valori mancanti con la mediana.
Codice per sostituire i null con valori mediani:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianColonne come YearBuilt, YearRemodAdd, GarageYrBlt e YrSold contengono anni (ad es., 2001, 1976) che non influenzano direttamente la variabile target. Sebbene questi valori assoluti degli anni possano non impattare direttamente i prezzi delle case, possiamo ricavare insight più utili calcolando quanti anni ha la casa o la ristrutturazione al momento della vendita.
Per esempio, invece di usare YearBuilt, possiamo creare una nuova feature: House Age=YrSold−YearBuilt
Codice per creare queste nuove feature:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Nel machine learning, feature numeriche asimmetriche possono influire negativamente sulle prestazioni del modello, specialmente per modelli che assumono una distribuzione normale (ad es., regressione lineare). Per correggere questo aspetto, applichiamo la trasformazione logaritmica.
Prima di applicare una trasformazione logaritmica, dobbiamo identificare le feature asimmetriche. Tuttavia, escludiamo le colonne contenenti zeri poiché il logaritmo di zero non è definito.
Ecco un'implementazione in Python per identificare le colonne asimmetriche:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Output:

Useremo la distribuzione lognormale per convertire queste cinque colonne asimmetriche in una distribuzione gaussiana:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Abbiamo precedentemente discusso diverse tecniche di encoding; in questo esempio, applicheremo il target encoding.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Nel codice sopra, la variabile target è SalePrice, quindi abbiamo raggruppato i dati per ciascuna colonna categorica e calcolato la media di SalePrice per ogni gruppo. Questi valori medi sono stati quindi assegnati ai corrispondenti valori categorici in quella colonna.
Il nostro dataset è ora pronto per il machine learning!
Se vuoi rafforzare la comprensione dei concetti di apprendimento supervisionato e di come i modelli utilizzino le feature ingegnerizzate, questo corso Supervised Learning with Scikit-Learn è un'eccellente risorsa.
In questa sezione, passeremo in rassegna le librerie Python e gli strumenti di automazione più usati per implementare il feature engineering.
Pandas è il framework Python più usato per la gestione di dati strutturati. Esegue molte fasi di feature engineering, come trasformazione, aggregazione dei dati ed estrazione di feature. Pandas rende anche semplice la pulizia e la manipolazione dei dati.
Se sei alle prime armi con pandas, questo corso Data Manipulation with pandas è un ottimo punto di partenza.
Scikit-learn è una potente libreria di machine learning con vari strumenti per il feature engineering. Contiene metodi come OneHotEncoder e LabelEncoder per convertire variabili categoriche in numeriche. Offre anche metodi di feature scaling come StandardScaler e Minmaxscaler.
Feature-engine è una libreria Python open-source che offre una varietà di transformer per semplificare il feature engineering. Questi transformer sono strumenti specializzati per compiti specifici, come imputazione dei dati mancanti, gestione degli outlier, selezione delle feature e discretizzazione. Pienamente compatibili con scikit-learn, questi transformer possono essere passati come parametri di input per l'ottimizzazione degli iperparametri.
fit(), la libreria offre un metodo fit_transform() che esegue simultaneamente le operazioni di fit e transform sui dati in input. Inoltre, sono disponibili i modelli FeatureSelector e AutoFeatLight per selezione e scaling delle feature.Per implementare efficacemente il feature engineering, concentrati su queste best practice.
Capire il significato e la rilevanza di ogni feature rende molto più semplice eseguire tecniche come selezione o estrazione di feature. Ti suggerisco di fare ricerca sui tuoi dati e sulla conoscenza del dominio per un feature engineering efficace.
Utilizza librerie Python come Pandas e Matplotlib per condurre una analisi esplorativa dei dati completa, ad esempio esplorando informazioni statistiche, visualizzazioni e correlazioni per trovare pattern e potenziali relazioni nei dati.
Creare feature di interazione implica identificare relazioni tra feature esistenti e derivarne di nuove. Per esempio, nella previsione dei prezzi delle case, calcolare l'età di una casa sottraendo l'anno di costruzione dall'anno corrente mette in evidenza tendenze, come la diminuzione del prezzo con il passare del tempo.
Diversi modelli di machine learning richiedono diversi passaggi di feature engineering. Per esempio, modelli come regressione lineare o multipla, SVM e KNN beneficiano spesso della standardizzazione delle feature, ma questa tecnica non aiuta i modelli basati su alberi.
Quindi, decidere in anticipo il tuo modello può aiutarti a costruire una pipeline di feature engineering efficace per il tuo caso d'uso.
Il feature engineering è una parte integrante della costruzione di soluzioni di machine learning, che ti consente di sfruttare le feature nel modo più efficiente. Il processo è svolto da data scientist o ML engineer quando lavorano con qualsiasi dataset. Se sei un professionista dei dati o aspiri a diventarlo, padroneggiare tutte le tecniche menzionate in questo articolo ti aiuterà a far progredire la tua carriera!
Per esplorare queste tecniche più in dettaglio, dai un'occhiata ai corsi di DataCamp su feature engineering per il machine learning e feature engineering per l'NLP. C'è anche un corso su feature engineering per programmatori R.
Scopri di più sul machine learning con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

