
Courses
Machine Learning for Time Series Data in Python
4 giờ
53.2K
Trước khi đi sâu vào các kỹ thuật kỹ thuật đặc trưng khác nhau, hãy cùng hiểu các loại đặc trưng hiện có.
Đúng như tên gọi, đặc trưng số biểu diễn dữ liệu bằng con số. Chúng là các biến định lượng liên tục. Ví dụ gồm chiều cao, tuổi và lương.
Một cột phân loại chỉ có thể chứa các giá trị rời rạc. Ví dụ, giới tính của một người là cột phân loại, vì nó chỉ có một vài loại giới tính. Tháng sinh là ví dụ khác vì giá trị phải nằm trong khoảng từ tháng Một đến tháng Mười hai.
Các biến phân loại được chia tiếp thành nhị phân và không nhị phân. Biến nhị phân có hai loại khả dĩ, trong khi đặc trưng không nhị phân có thể có nhiều loại.
Các cột văn bản chỉ chứa dữ liệu dạng chữ. Ví dụ gồm đánh giá sản phẩm hoặc cột mô tả sản phẩm trong bộ dữ liệu bán lẻ.
Mặt khác, đặc trưng chuỗi thời gian biểu diễn dữ liệu theo thời điểm, như doanh số theo tuần hoặc biến động giá cổ phiếu trong một năm.
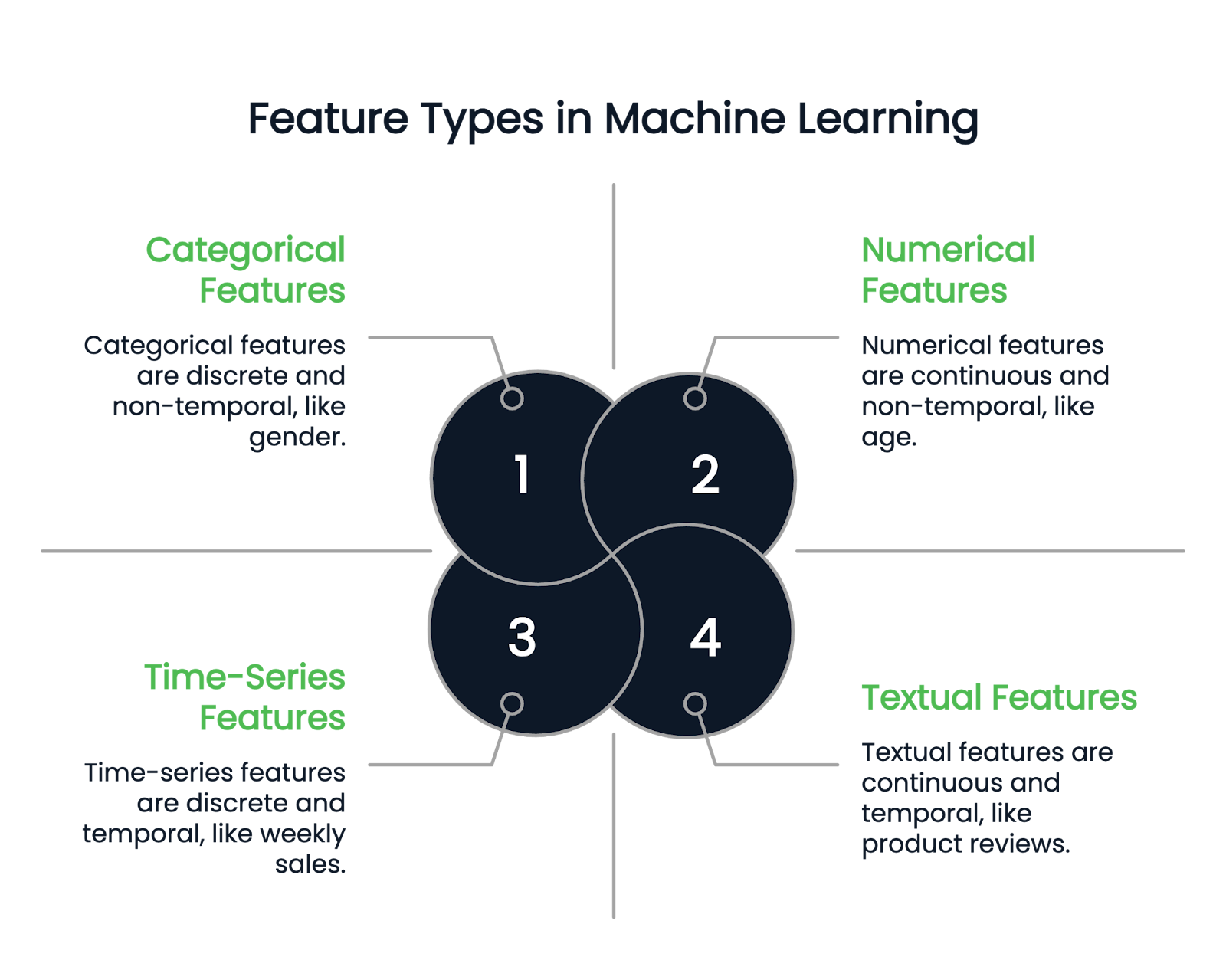
Hình do Tác giả cung cấp
Kỹ thuật đặc trưng cung cấp nhiều kỹ thuật mạnh mẽ để chuyển đổi các cột thô thành những đặc trưng phù hợp. Dưới đây, chúng ta bàn về một số kỹ thuật nổi bật.
Giá trị khuyết có thể làm sai lệch hiệu suất mô hình, nên xử lý đúng cách là rất quan trọng. Có hai cách tiếp cận chính:
Để có hướng dẫn chuyên sâu về xử lý dữ liệu thiếu, hãy đọc bài Hướng dẫn Kỹ thuật Xử lý Dữ liệu Thiếu hoặc khám phá khóa học Xử lý Dữ liệu Thiếu trong Python.
Ngoại lệ là những giá trị bất thường khác biệt đáng kể so với phần còn lại của các điểm dữ liệu. Ví dụ, nếu bạn có bộ dữ liệu lương với hầu hết quan sát nằm trong khoảng $90K đến $120K, thì mức $400K hoặc $10K là ngoại lệ.
Các mô hình machine learning không thể xử lý trực tiếp biến phân loại, nên cần chuyển chúng thành dạng số. Dưới đây là một số kỹ thuật mã hóa phổ biến.
Hãy xét một bộ dữ liệu với đặc trưng phân loại sau:
|
Name |
Gender |
|
John |
Male |
|
Rachel |
Female |
|
Emma |
Female |
Dùng one-hot encoding, chúng ta tạo các cột riêng cho mỗi hạng mục khả dĩ trong đặc trưng Gender:
|
Name |
Female |
Male |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Vì John là Male, cột "Male" nhận giá trị 1, trong khi cột "Female" là 0. Tương tự, Rachel và Emma là Female, nên cột "Female" là 1 và cột "Male" là 0.
Để xem hướng dẫn đầy đủ về one-hot encoding trong Python, hãy xem Hướng dẫn One-Hot Encoding.
Xét một bộ dữ liệu có cột Location chứa các giá trị phân loại:
|
Location |
Encoded value |
|
New York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
Mỗi địa điểm duy nhất được gán một giá trị số riêng. Tuy nhiên, vì California (2) không "nằm giữa" New York (1) và Texas (3) theo nghĩa nội tại, dùng label encoding cho dữ liệu không có thứ bậc có thể dẫn đến giả định sai. Trong những trường hợp như vậy, one-hot encoding thường được ưu tiên để tránh ngụ ý mối quan hệ số không chủ ý giữa các hạng mục.
Xét cột Education level với các hạng mục sau:
|
Education level |
Encoded value |
|
UG (Undergraduate) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Vì PhD thể hiện trình độ cao hơn PG, vốn lại cao hơn UG, nên các giá trị số được gán phản ánh thứ hạng này.
Xét một bộ dữ liệu trong đó Location là đặc trưng phân loại, và Target variable biểu diễn một kết quả số:
|
Location |
Target variable |
|
New York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Để mã hóa cột Location, chúng ta tính trung bình của Target variable cho mỗi hạng mục duy nhất:
|
Location |
Encoded value |
|
New York |
2 |
|
California |
2 |
|
Texas |
4.5 |
|
California |
2 |
|
Texas |
4.5 |
Nếu bạn đang tìm một hướng dẫn tổng quát hơn về xử lý dữ liệu phân loại, bài Hướng dẫn Xử lý Dữ liệu Phân loại này cung cấp thêm nhiều góc nhìn.
Chuẩn hóa thang đo đảm bảo các đặc trưng số nằm trong một khoảng tiêu chuẩn, tránh việc một số đặc trưng chi phối quá trình học do có giá trị lớn hơn.
Các mô hình machine learning dựa vào tính toán khoảng cách (ví dụ, hồi quy tuyến tính, k-láng giềng gần nhất, và mạng nơ-ron) có thể bị ảnh hưởng khi các đặc trưng có thang đo rất khác nhau.
Ví dụ, xét một bộ dữ liệu nhân viên với các đặc trưng sau:
Vì thu nhập có giá trị lớn hơn nhiều so với tuổi, một mô hình có thể gán tầm quan trọng cao hơn cho thu nhập chỉ vì thang đo, chứ không phải vì nó thực sự liên quan hơn.
Dưới đây là một số kỹ thuật phổ biến:
Giá trị đã chuẩn hóa = (điểm dữ liệu - min(cột)) / (max(cột) - min(cột))
Giá trị đã chuẩn hóa = (điểm dữ liệu - mean(cột)) / (std(cột))
Để so sánh chi tiết giữa chuẩn hóa và tiêu chuẩn hóa, hãy xem Hướng dẫn Chuẩn hóa vs. Tiêu chuẩn hóa.
Tạo các đặc trưng mới, có ý nghĩa từ dữ liệu hiện có giúp mô hình có thêm thông tin logic hơn.
Chẳng hạn, trong bộ dữ liệu dự đoán giá nhà, nếu bạn có riêng các cột length và breadth, bạn có thể suy ra đặc trưng mới: area = length * breath, có thể liên quan trực tiếp đến biến mục tiêu price. Đưa đặc trưng area này vào mô hình giúp đơn giản hóa việc khám phá các mẫu ẩn.
Chọn lọc đặc trưng chỉ giữ lại các đặc trưng liên quan bằng cách loại bỏ các cột không cần thiết. Tập trung vào dữ liệu nhiều thông tin nhất giúp tránh overfitting, giảm độ phức tạp tính toán và cải thiện hiệu suất mô hình. Một số kỹ thuật gồm:
Kỹ thuật đặc trưng được hiểu rõ nhất qua triển khai thực hành.
Bộ "dự đoán giá nhà" là một bộ dữ liệu thực tế lớn với 81 cột. Tôi chọn bộ này vì sự đa dạng đặc trưng của nó, giúp bạn hiểu thực tế hơn về các kỹ thuật kỹ thuật đặc trưng.
Bắt đầu:
Đoạn mã sau xác định các cột phân loại trong tập dữ liệu và thay thế giá trị khuyết của chúng bằng hạng mục xuất hiện nhiều nhất:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesTa xử lý giá trị khuyết dạng số bằng cách thay bằng trung bình hoặc trung vị. Trung bình phổ biến hơn cho dữ liệu phân phối thống kê, trong khi trung vị phù hợp khi cột có ngoại lệ. Vì vậy, ta sẽ kiểm tra ngoại lệ rồi quyết định phương pháp.
Để trực quan hóa ngoại lệ tiềm ẩn, ta có thể dùng boxplot, giúp nhận diện giá trị cực đoan. Dưới đây là triển khai Python để phát hiện ngoại lệ ở một số cột số được chọn:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Kết quả:
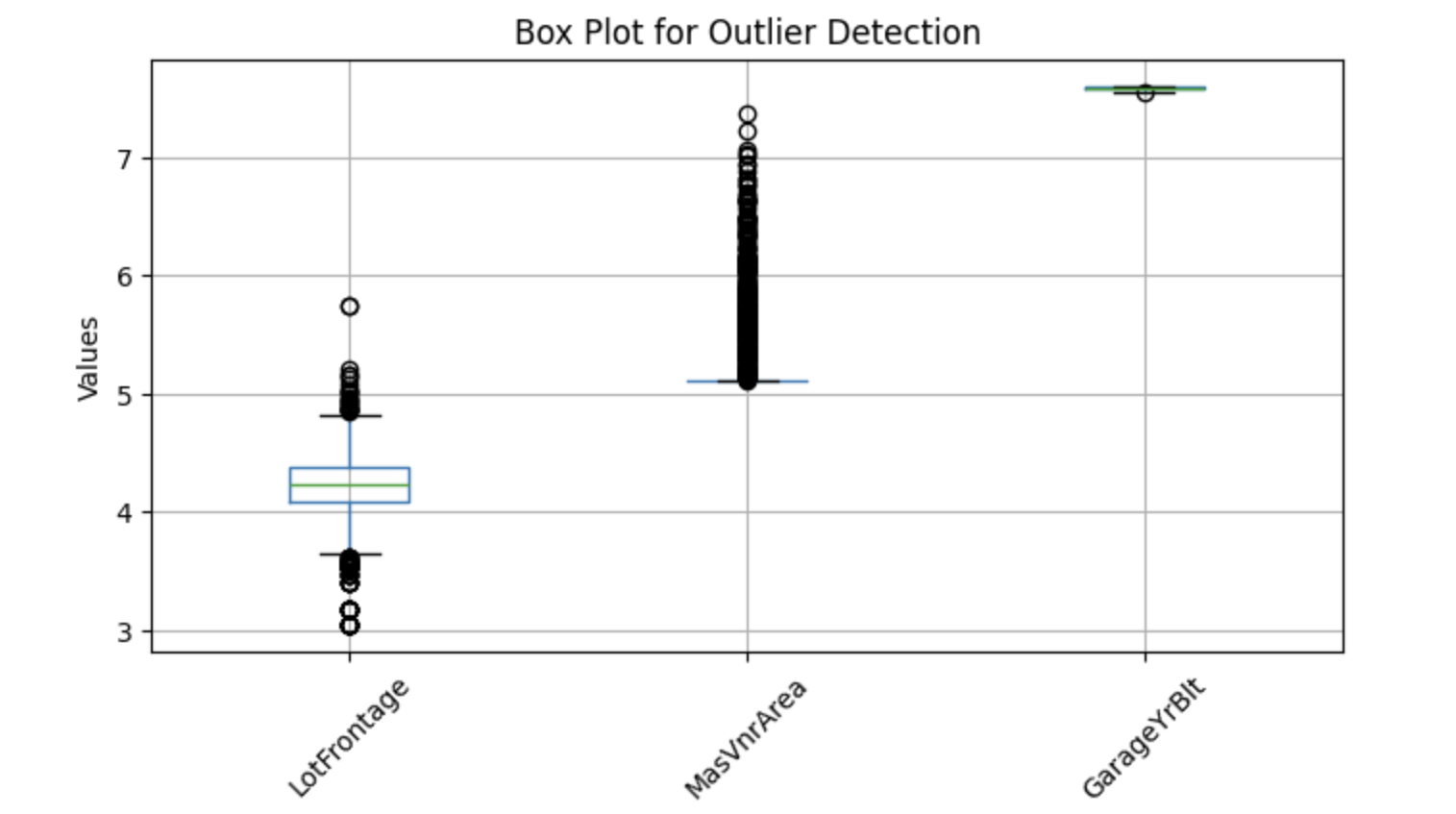
Các boxplot trên cho thấy những điểm nằm ngoài ria—đó gọi là ngoại lệ. Vì vậy, hãy thay giá trị khuyết bằng trung vị.
Mã thay thế giá trị null bằng trung vị:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianCác cột như YearBuilt, YearRemodAdd, GarageYrBlt và YrSold chứa năm (ví dụ: 2001, 1976) vốn không tác động trực tiếp đến biến mục tiêu. Dù các giá trị năm tuyệt đối này có thể không ảnh hưởng trực tiếp đến giá nhà, ta có thể rút ra thông tin hữu ích hơn bằng cách tính tuổi ngôi nhà hoặc thời điểm cải tạo tại thời gian bán.
Ví dụ, thay vì dùng YearBuilt, ta có thể tạo đặc trưng mới: House Age=YrSold−YearBuilt
Mã để tạo các đặc trưng mới này:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Trong machine learning, các đặc trưng số bị lệch (skew) có thể ảnh hưởng tiêu cực đến hiệu suất mô hình, đặc biệt với các mô hình giả định phân phối chuẩn (ví dụ, hồi quy tuyến tính). Để điều chỉnh, ta áp dụng biến đổi log.
Trước khi áp dụng biến đổi log, ta phải xác định các đặc trưng bị lệch. Tuy nhiên, loại trừ các cột chứa số 0 vì log của 0 là không xác định.
Dưới đây là triển khai bằng Python để xác định các cột bị lệch:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Kết quả:

Chúng ta sẽ dùng phân phối log-normal để chuyển năm cột bị lệch này thành phân phối Gaussian:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Chúng ta đã thảo luận một số kỹ thuật mã hóa; trong ví dụ này, ta sẽ áp dụng target encoding.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Trong đoạn mã trên, biến mục tiêu là SalePrice, nên chúng ta nhóm dữ liệu theo từng cột phân loại và tính trung bình SalePrice cho mỗi nhóm. Các giá trị trung bình này sau đó được gán cho các giá trị phân loại tương ứng trong cột đó.
Bộ dữ liệu của chúng ta giờ đã sẵn sàng cho machine learning!
Nếu bạn muốn củng cố hiểu biết về học có giám sát và cách các mô hình tận dụng đặc trưng được kỹ thuật hóa, khóa học Học có Giám sát với Scikit-Learn là một nguồn tài nguyên tuyệt vời.
Trong phần này, chúng ta sẽ điểm qua các thư viện Python và công cụ tự động được dùng nhiều nhất để triển khai kỹ thuật đặc trưng.
Pandas là framework Python được dùng nhiều nhất để xử lý dữ liệu có cấu trúc. Nó thực hiện nhiều bước kỹ thuật đặc trưng như biến đổi, tổng hợp dữ liệu và trích xuất đặc trưng. Pandas cũng giúp làm sạch và thao tác dữ liệu dễ dàng.
Nếu bạn mới bắt đầu với pandas, khóa học Xử lý Dữ liệu với pandas là điểm khởi đầu tuyệt vời.
Scikit-learn là thư viện machine learning mạnh mẽ với nhiều công cụ cho kỹ thuật đặc trưng. Nó có các phương thức như OneHotEncoder và LabelEncoder để chuyển biến phân loại sang số. Nó cũng cung cấp các phương pháp chuẩn hóa thang đo như StandardScaler và Minmaxscaler.
Feature-engine là thư viện Python mã nguồn mở cung cấp nhiều bộ biến đổi (transformer) để đơn giản hóa kỹ thuật đặc trưng. Các bộ biến đổi này chuyên biệt cho các tác vụ như bù dữ liệu thiếu, xử lý ngoại lệ, chọn lọc đặc trưng và rời rạc hóa. Hoàn toàn tương thích với scikit-learn, các bộ biến đổi này có thể được truyền làm tham số đầu vào cho tinh chỉnh siêu tham số.
fit(), thư viện cung cấp phương thức fit_transform() thực hiện đồng thời fit và transform trên dữ liệu đầu vào. Ngoài ra, các mô hình FeatureSelector và AutoFeatLight có sẵn cho chọn lọc và chuẩn hóa đặc trưng.Để triển khai kỹ thuật đặc trưng hiệu quả, hãy tập trung vào các thực hành tốt sau.
Hiểu ý nghĩa và tầm quan trọng của từng đặc trưng giúp bạn dễ dàng thực hiện các kỹ thuật như chọn lọc hoặc trích xuất đặc trưng hơn nhiều. Tôi khuyên bạn nghiên cứu dữ liệu và tri thức lĩnh vực liên quan để kỹ thuật đặc trưng hiệu quả.
Sử dụng các thư viện Python như Pandas và Matplotlib để thực hiện phân tích khám phá dữ liệu toàn diện, chẳng hạn như khám phá thông tin thống kê, trực quan hóa và tương quan để tìm mẫu và mối quan hệ tiềm năng trong dữ liệu.
Tạo đặc trưng tương tác bao gồm xác định mối quan hệ giữa các đặc trưng hiện có và suy ra đặc trưng mới. Ví dụ, trong dự đoán giá nhà, tính tuổi nhà bằng cách lấy năm hiện tại trừ năm xây dựng làm nổi bật xu hướng như giá nhà giảm theo thời gian.
Các mô hình machine learning khác nhau yêu cầu các bước kỹ thuật đặc trưng khác nhau. Ví dụ, các mô hình như hồi quy tuyến tính hay hồi quy bội, SVM và KNN thường hưởng lợi từ tiêu chuẩn hóa đặc trưng, nhưng kỹ thuật này không giúp ích cho các mô hình dựa trên cây.
Vì vậy, quyết định mô hình từ trước có thể giúp bạn xây dựng một pipeline kỹ thuật đặc trưng hiệu quả cho trường hợp sử dụng của mình.
Kỹ thuật đặc trưng là phần không thể thiếu trong xây dựng giải pháp machine learning, cho phép bạn tận dụng đặc trưng một cách hiệu quả nhất. Quá trình này được thực hiện bởi các nhà khoa học dữ liệu hoặc kỹ sư ML khi làm việc với bất kỳ tập dữ liệu nào. Nếu bạn là một chuyên gia dữ liệu hoặc đang hướng tới mục tiêu đó, nắm vững tất cả kỹ thuật được đề cập trong bài viết này sẽ giúp bạn thăng tiến sự nghiệp!
Để khám phá chi tiết hơn các kỹ thuật này, hãy xem các khóa học của DataCamp về kỹ thuật đặc trưng cho machine learning và kỹ thuật đặc trưng cho NLP. Cũng có một khóa học về kỹ thuật đặc trưng cho lập trình viên R.
Tìm hiểu thêm về machine learning với các khóa học này!
Courses
Courses
Courses