
Curso
Machine Learning para datos de series temporales en Python
4 h
53.2K
Antes de sumergirnos en las distintas técnicas de ingeniería de características, entendamos primero los tipos de características disponibles.
Como su nombre indica, las características numéricas representan los datos en números. Son variables cuantitativas continuas. Algunos ejemplos son la altura, la edad y el salario.
Una columna categórica sólo puede contener características discretas. Por ejemplo, el sexo de una persona es una columna categórica, ya que sólo puede tener unos pocos tipos de sexo. El mes de nacimiento es otro ejemplo, porque los valores deben estar comprendidos entre enero y diciembre.
Las variables categóricas se dividen a su vez en binarias y no binarias. Las variables binarias tienen dos categorías posibles, mientras que los rasgos no binarios pueden tener varias categorías.
Las columnas textuales sólo contienen datos de texto. Algunos ejemplos son las reseñas de productos o las columnas de descripción de productos en un conjunto de datos de venta al por menor.
Por otra parte, las características de series temporales representan datos puntuales, como las ventas semanales o las fluctuaciones del precio de las acciones a lo largo de un año.
Imagen del autor
La ingeniería de rasgos ofrece varias técnicas potentes para convertir columnas sin procesar en rasgos deseables. Aquí comentamos algunas de las más destacadas.
Los valores perdidos pueden distorsionar el rendimiento del modelo, por lo que manejarlos adecuadamente es crucial. Hay dos enfoques principales:
Para una guía en profundidad sobre el tratamiento de los datos que faltan, lee este Tutorial sobre Técnicas para Manejar los Datos que Faltan o explora este Curso de Tratamiento de los Datos que Faltan en Python.
Los valores atípicos son valores anormales significativamente diferentes del resto de los puntos de datos. Por ejemplo, si tienes un conjunto de datos salariales con la mayoría de las observaciones entre 90.000 y 120.000 $, una cifra salarial como 400.000 $ o 10.000 $ es un valor atípico.
Los modelos de aprendizaje automático no pueden procesar directamente variables categóricas, por lo que deben convertirse en representaciones numéricas. A continuación, analizamos algunas técnicas de codificación populares.
Considera un conjunto de datos con la siguiente característica categórica:
|
Nombre |
Género |
|
John |
Hombre |
|
Rachel |
Mujer |
|
Emma |
Mujer |
Utilizando la codificación de una sola vez, creamos columnas separadas para cada categoría posible en la función Gender:
|
Nombre |
Mujer |
Hombre |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Como Juan es Varón, la columna "Varón" recibe un 1, mientras que la columna "Mujer" sigue siendo 0. Asimismo, Raquel y Emma son Mujeres, por lo que la columna "Mujer" es 1 y la columna "Hombre" es 0.
Para un tutorial completo sobre la codificación en un solo paso en Python, consulta este Tutorial de codificación en un solo paso.
Considera un conjunto de datos con una columna Location que contiene valores categóricos:
|
Ubicación |
Valor codificado |
|
Nueva York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
A cada ubicación única se le asigna un valor numérico distinto. Sin embargo, dado que California (2) no está intrínsecamente "entre" Nueva York (1) y Texas (3), utilizar la codificación de etiquetas para datos no ordinales puede llevar a suposiciones engañosas del modelo. En estos casos, a menudo se prefiere la codificación de un solo punto para evitar implicar una relación numérica no intencionada entre las categorías.
Considera una columna Education level con las siguientes categorías:
|
Nivel de estudios |
Valor codificado |
|
UG (Licenciatura) |
1 |
|
PG (Postgrado) |
2 |
|
PhD |
3 |
Dado que un doctorado representa un nivel educativo superior al de un PG, que a su vez es superior al de un UG, los valores numéricos asignados reflejan esta clasificación.
Considera un conjunto de datos en el que Location es una característica categórica, y el Target variable representa algún resultado numérico:
|
Ubicación |
Variable objetivo |
|
Nueva York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Para codificar la columna Location, calculamos la media de Target variable para cada categoría única:
|
Ubicación |
Valor codificado |
|
Nueva York |
2 |
|
California |
2 |
|
Texas |
4.5 |
|
California |
2 |
|
Texas |
4.5 |
Si buscas una guía más amplia sobre el manejo de datos categóricos, este Tutorial de Manejo de Datos Categóricos te proporciona información adicional.
El escalado de rasgos garantiza que los rasgos numéricos se sitúen dentro de un rango normalizado, evitando que algunos rasgos dominen el proceso de aprendizaje debido a sus valores más grandes.
Los modelos de aprendizaje automático que se basan en cálculos de distancia (p. ej., regresión lineal, k-vecinos más próximos y redes neuronales) pueden verse afectados cuando las características tienen escalas muy diferentes.
Por ejemplo, considera un conjunto de datos de empleados con las siguientes características:
Como la renta tiene valores mucho mayores que la edad, un modelo podría asignar más importancia a la renta simplemente por su escala, no porque sea realmente más relevante.
He aquí algunas técnicas habituales:
Valor escalado =( punto dato - min(columna))/(max(columna) - min(columna))
Valor escalado =( punto de datos - media(columna))/(std(columna))
Para una comparación detallada de la normalización frente a la estandarización, consulta este Normalización frente a estandarización. Guía de normalización.
Crear características nuevas y significativas a partir de los datos existentes proporciona una visión más lógica del modelo.
Por ejemplo, en un conjunto de datos de predicción del precio de la vivienda, si tienes las columnas length y breadth por separado, puedes derivar una nueva característica: area = length * breath, que puede relacionarse directamente con la variable objetivo, price. Introducir esta característica area en el modelo simplifica el descubrimiento de patrones ocultos.
La selección de rasgos mantiene sólo los rasgos relevantes eliminando las columnas innecesarias. Centrarse en los datos más informativos ayuda a evitar el sobreajuste, reducir la complejidad computacional y mejorar el rendimiento del modelo. Aquí tienes algunas técnicas:
La ingeniería de características se comprende mejor mediante la aplicación práctica.
La "predicción del precio de la vivienda" es un enorme conjunto de datos del mundo real con 81 columnas. Lo he seleccionado por su gran variedad de funciones, que pueden ayudarte a comprender mejor las técnicas de ingeniería de funciones en la práctica.
Para empezar:
El código siguiente identifica las columnas categóricas del conjunto de datos y sustituye sus valores perdidos por la categoría más frecuente:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesTratamos los valores numéricos perdidos sustituyéndolos por la media o la mediana. La media es una opción más popular para datos distribuidos estadísticamente, mientras que la mediana funciona bien cuando la columna tiene valores atípicos. Por tanto, comprobaremos si hay valores atípicos y decidiremos el método.
Para visualizar posibles valores atípicos, podemos utilizar gráficos de caja, que ayudan a identificar los valores extremos. A continuación se muestra una implementación en Python para detectar valores atípicos en columnas numéricas seleccionadas:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Salida:
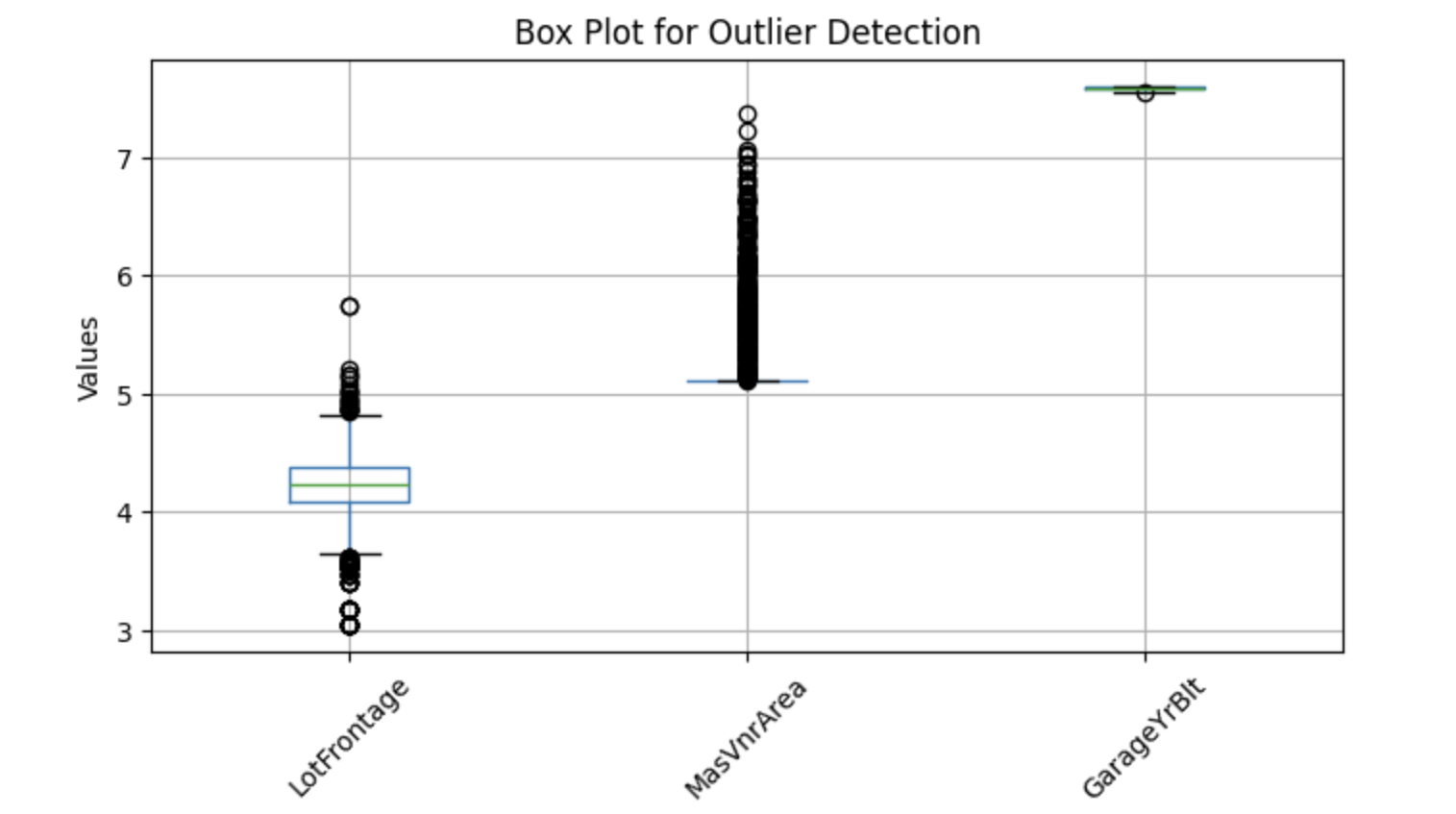
Los gráficos de caja anteriores muestran puntos fuera de los bigotes, que se denominan valores atípicos. Así pues, sustituyamos los valores perdidos por la mediana.
Código para sustituir los nulos por valores de la mediana:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianLas columnas como YearBuilt, YearRemodAdd, GarageYrBlt, y YrSold contienen años (por ejemplo, 2001, 1976) que no influyen directamente en la variable objetivo. Aunque estos valores absolutos por año no influyan directamente en el precio de la vivienda, podemos obtener información más útil calculando la antigüedad de la casa o la reforma en el momento de la venta.
Por ejemplo, en lugar de utilizar YearBuilt, podemos crear una nueva característica: House Age=YrSold-YearBuilt
Código para crear estas nuevas funciones:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]En el aprendizaje automático, las características numéricas sesgadas pueden influir negativamente en el rendimiento del modelo, especialmente en los modelos que asumen una distribución normal (por ejemplo, la regresión lineal). Para corregirlo, aplicamos la transformación logarítmica.
Antes de aplicar una transformación logarítmica, debemos identificar los rasgos sesgados. Sin embargo, excluimos las columnas que contienen ceros, ya que el logaritmo de cero es indefinido.
Aquí tienes una implementación en Python para identificar columnas sesgadas:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Salida:

Utilizaremos la distribución log-normal para convertir estas cinco columnas sesgadas enuna distribución gaussiana:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Anteriormente hemos hablado de varias técnicas de codificación; en este ejemplo, aplicaremos la codificación de objetivos.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)En el código anterior, la variable objetivo es SalePrice, así que agrupamos los datos por cada columna categórica y calculamos la media SalePrice de cada grupo. A continuación, estos valores medios se asignaron a los valores categóricos correspondientes de esa columna.
¡Nuestro conjunto de datos ya está listo para el aprendizaje automático!
Si quieres reforzar tu comprensión de los conceptos del aprendizaje supervisado y de cómo los modelos utilizan las características de ingeniería, este Curso de Aprendizaje Supervisado con Scikit-Learn es unrecurso excelente.
En esta sección, repasaremos las bibliotecas y herramientas de automatización de Python más utilizadas para implementar la ingeniería de funciones.
Pandas es el framework de Python más utilizado para manejar datos estructurados. Realiza muchos pasos de ingeniería de rasgos, como la transformación, la agregación de datos y la extracción de rasgos. Los pandas también facilitan la limpieza y manipulación de datos.
Si eres nuevo en pandas, este Curso de Manipulación de Datos con pandas es un buen punto de partida.
Scikit-learn es una potente biblioteca de aprendizaje automático con varias herramientas para la ingeniería de características. Contiene métodos como OneHotEncoder y LabelEncoder para convertir variables categóricas en numéricas. También ofrece métodos de escalado de rasgos como StandardScaler y Minmaxscaler.
Feature-engine es una biblioteca Python de código abierto que ofrece una variedad de transformadores para simplificar la ingeniería de características. Estos transformadores son herramientas especializadas para tareas específicas, como la imputación de datos perdidos, el tratamiento de valores atípicos, la selección de características y la discretización. Totalmente compatibles con scikit-learn, estos transformadores pueden pasarse como parámetros de entrada para el ajuste de hiperparámetros.
fit(), la biblioteca ofrece un método fit_transform() que realiza simultáneamente operaciones de ajuste y transformación en los datos de entrada. Además, los modelos FeatureSelector y AutoFeatLight están disponibles para la selección y el escalado de características.Para aplicar eficazmente la ingeniería de funciones, céntrate en estas prácticas recomendadas.
Comprender el significado y la importancia de cada rasgo te facilita mucho la realización de técnicas como la selección o extracción de rasgos. Te sugiero que investigues tus datos y los conocimientos de dominio relevantes para una ingeniería de características eficaz.
Utiliza bibliotecas de Python como Pandas y Matplotlib para realizar análisis exploratorios exhaustivos de datos,como explorar información estadística, visualizaciones y correlaciones para encontrar patrones y relaciones potenciales dentro de los datos.
Crear características de interacción implica identificar las relaciones entre las características existentes y derivar otras nuevas. Por ejemplo, en la predicción del precio de la vivienda, calcular la antigüedad de una casa restando el año en que se construyó del año actual pone de manifiesto tendencias, como la disminución del precio de la vivienda a medida que pasa el tiempo.
Diferentes modelos de aprendizaje automático requieren diferentes pasos de ingeniería de características. Por ejemplo, modelos como la regresión lineal o múltiple, SVM y KNN suelen beneficiarse de la normalización de características, pero esta técnica no ayuda a los modelos basados en árboles.
Por tanto, decidir tu modelo con antelación puede ayudarte a construir un proceso de ingeniería de características eficaz para tu caso de uso.
La ingeniería de características es una parte integral de la creación de soluciones de aprendizaje automático, que te permite aprovechar las características de la forma más eficaz. El proceso lo llevan a cabo los científicos de datos o ingenieros de ML cuando tratan con cualquier conjunto de datos. Si eres un profesional de los datos o aspiras a serlo, ¡dominar todas las técnicas mencionadas en este artículo te ayudará a avanzar en tu carrera!
Para explorar estas técnicas con más detalle, consultalos cursos de DataCampsobre ingeniería de características para el aprendizaje automático e ingeniería de características para la PNL. También hay un curso sobre ingeniería de funciones para programadores de R.
Aprende más sobre aprendizaje automático con estos cursos
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
DataCamp Team
