
Cursus
Machine Learning for Time Series Data in Python
4 Hr
53.2K
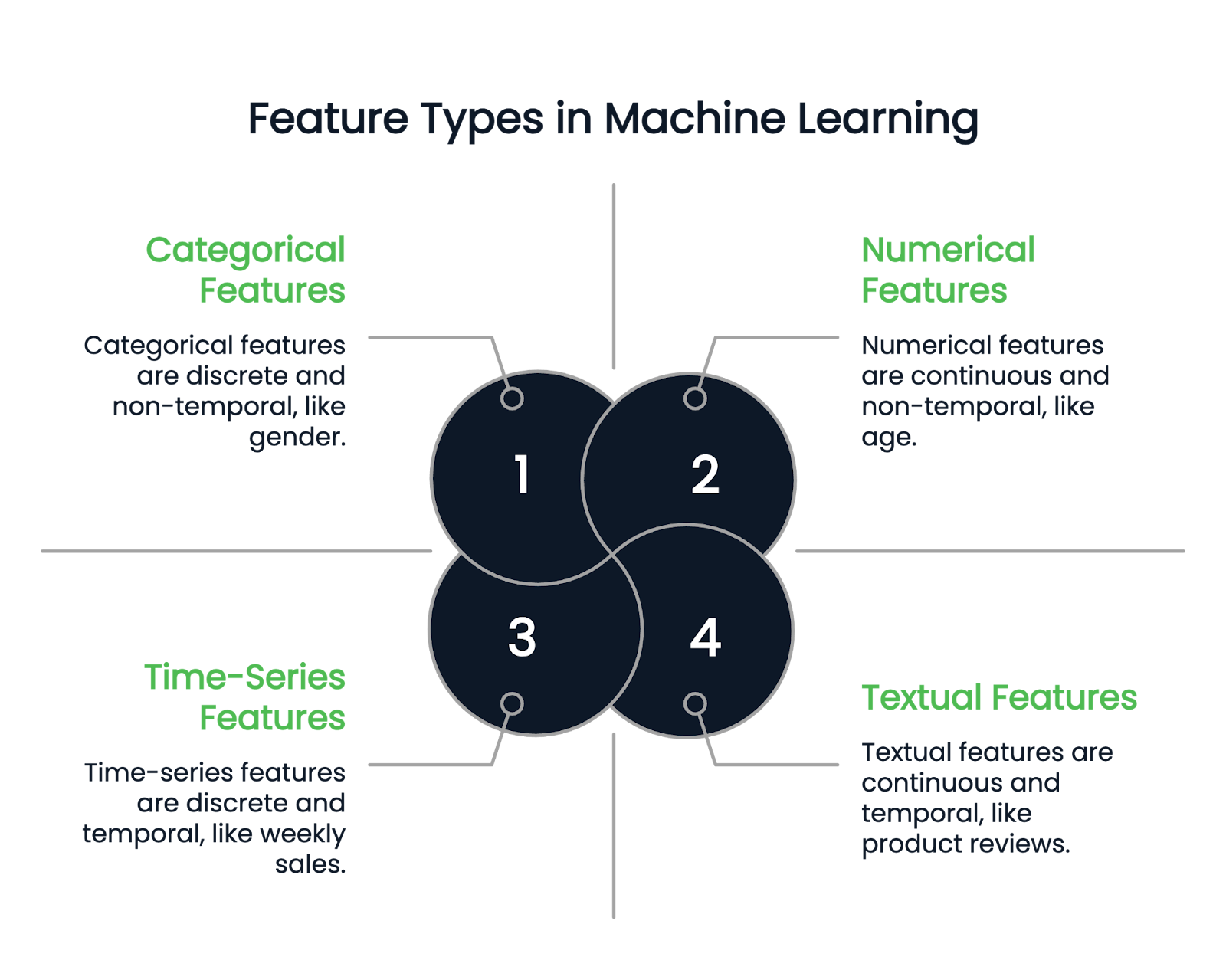
Voordat we in verschillende feature-engineeringtechnieken duiken, kijken we eerst naar de soorten features die er zijn.
Zoals de naam al aangeeft, representeren numerieke features data in getallen. Het zijn continue kwantitatieve variabelen. Voorbeelden zijn lengte, leeftijd en salaris.
Een categorische kolom kan alleen discrete waarden bevatten. Zo is iemands gender een categorische kolom, omdat deze maar een paar gendertypen kan hebben. Geboortemaand is een ander voorbeeld, omdat de waarden tussen januari en december moeten vallen.
Categorische variabelen worden verder onderverdeeld in binaire en niet-binaire typen. Binaire variabelen hebben twee mogelijke categorieën, terwijl niet-binaire features meerdere categorieën kunnen hebben.
Tekstkolommen bevatten alleen tekstdata. Voorbeelden zijn productreviews of productbeschrijvingskolommen in een retaildataset.
Tijdreeksfeatures daarentegen representeren tijdsgebonden data, zoals wekelijkse verkopen of schommelingen in aandelenkoersen gedurende een jaar.
Afbeelding door auteur
Feature engineering biedt diverse krachtige technieken om ruwe kolommen om te zetten in bruikbare features. Hier bespreken we enkele belangrijke.
Missende waarden kunnen de modelprestaties verstoren, dus het is cruciaal om er goed mee om te gaan. Er zijn twee hoofdbenaderingen:
Voor een diepgaande gids over het omgaan met missende data, lees deze tutorial Technieken om met missende data om te gaan of bekijk deze cursus Dealing with Missing Data in Python.
Outliers zijn abnormale waarden die significant afwijken van de rest van de datapunten. Als je bijvoorbeeld een salarisdataset hebt met de meeste observaties tussen $90K en $120K, dan is een salaris als $400K of $10K een outlier.
Machine-learningmodellen kunnen categorische variabelen niet direct verwerken, dus ze moeten worden omgezet in numerieke representaties. Hieronder bespreken we enkele populaire encoderingstechnieken.
Neem een dataset met de volgende categorische feature:
|
Naam |
Gender |
|
John |
Male |
|
Rachel |
Female |
|
Emma |
Female |
Met one-hot encoding maken we aparte kolommen voor elke mogelijke categorie in de Gender-feature:
|
Naam |
Female |
Male |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
Omdat John Male is, krijgt de kolom "Male" een 1, terwijl de kolom "Female" 0 blijft. Evenzo zijn Rachel en Emma Female, dus is de kolom "Female" 1 en de kolom "Male" 0.
Voor een volledige tutorial over one-hot encoding in Python, bekijk deze One-Hot Encoding Tutorial.
Neem een dataset met een Location-kolom met categorische waarden:
|
Location |
Geëncodeerde waarde |
|
New York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
Elke unieke locatie krijgt een afzonderlijke numerieke waarde. Maar omdat California (2) niet inherent "tussen" New York (1) en Texas (3) ligt, kan label encoding voor niet-ordinale data leiden tot misleidende aannames in het model. In zulke gevallen heeft one-hot encoding vaak de voorkeur om te voorkomen dat er onbedoeld een numerieke relatie tussen categorieën wordt gesuggereerd.
Neem een kolom Education level met de volgende categorieën:
|
Education level |
Geëncodeerde waarde |
|
UG (Undergraduate) |
1 |
|
PG (Postgraduate) |
2 |
|
PhD |
3 |
Omdat een PhD een hoger opleidingsniveau vertegenwoordigt dan een PG, dat op zijn beurt hoger is dan UG, weerspiegelen de toegewezen numerieke waarden deze rangorde.
Neem een dataset waarin Location een categorische feature is en de Target variable een numerieke uitkomst voorstelt:
|
Location |
Targetvariabele |
|
New York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Om de kolom Location te encoderen, berekenen we het gemiddelde van de Target variable voor elke unieke categorie:
|
Location |
Geëncodeerde waarde |
|
New York |
2 |
|
California |
2 |
|
Texas |
4,5 |
|
California |
2 |
|
Texas |
4,5 |
Als je op zoek bent naar een bredere gids over het omgaan met categorische data, biedt deze tutorial over het verwerken van categorische data extra inzichten.
Features schalen zorgt ervoor dat numerieke features binnen een gestandaardiseerd bereik vallen, zodat sommige features het leerproces niet domineren door hun grotere waarden.
Machine-learningmodellen die vertrouwen op afstandsberekeningen (bijv. lineaire regressie, k-nearest neighbors en neurale netwerken) kunnen worden beïnvloed wanneer features sterk verschillende schalen hebben.
Neem bijvoorbeeld een medewerkersdataset met de volgende features:
Omdat inkomenswaarden veel groter zijn dan leeftijd, kan een model meer belang toekennen aan inkomen puur vanwege de schaal, niet omdat het daadwerkelijk relevanter is.
Enkele gangbare technieken:
Geschaalde waarde =( datapunt - min(kolom))/(max(kolom) - min(kolom))
Geschaalde waarde =( datapunt - mean(kolom))/(std(kolom))
Voor een gedetailleerde vergelijking tussen normalisatie en standaardisatie, bekijk deze gids Normalization vs. Standardization.
Nieuwe, betekenisvolle features creëren uit bestaande data geeft het model meer logische inzichten.
In een dataset voor het voorspellen van huizenprijzen kun je bijvoorbeeld, als je de kolommen length en breadth apart hebt, een nieuwe feature afleiden: area = length * breath, die mogelijk direct verband houdt met de targetvariabele, price. Door deze feature area aan het model te voeren, wordt het eenvoudiger om verborgen patronen te ontdekken.
Featureselectie behoudt alleen relevante features door overbodige kolommen te verwijderen. Door te focussen op de meest informatieve data, help je overfitting voorkomen, verlaag je de computationele complexiteit en verbeter je de modelprestaties. Enkele technieken:
Feature engineering begrijp je het best door het hands-on te implementeren.
De dataset "house price prediction" is een grote, realistische dataset met 81 kolommen. Ik heb deze gekozen vanwege het diverse scala aan features, waardoor je feature-engineeringtechnieken in de praktijk beter kunt begrijpen.
Aan de slag:
De volgende code identificeert categorische kolommen in de dataset en vervangt hun missende waarden door de meest voorkomende categorie:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesWe gaan numerieke missende waarden afhandelen door ze te vervangen door het gemiddelde of de mediaan. Het gemiddelde is populairder voor statistisch verdeelde data, terwijl de mediaan goed werkt wanneer de kolom outliers bevat. We controleren dus op outliers en bepalen de methode.
Om mogelijke outliers te visualiseren, kunnen we boxplots gebruiken, die extreme waarden helpen identificeren. Hieronder staat een Python-implementatie voor het detecteren van outliers in geselecteerde numerieke kolommen:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Output:
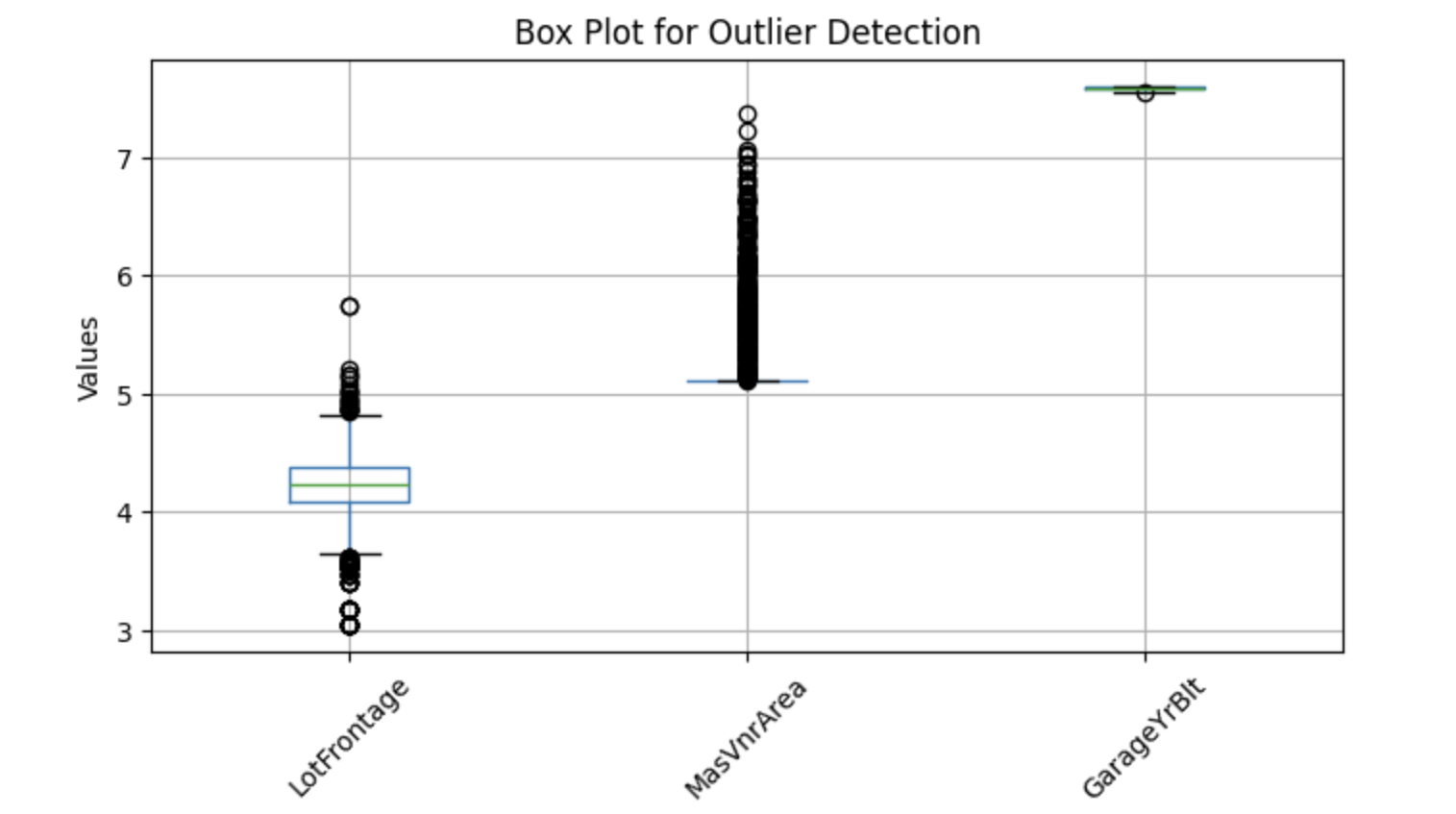
De bovenstaande boxplots tonen punten buiten de snorharen—dit zijn outliers. Laten we missende waarden dus vervangen door de mediaan.
Code om nullen te vervangen door mediaanwaarden:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianKolommen zoals YearBuilt, YearRemodAdd, GarageYrBlt en YrSold bevatten jaartallen (bijv. 2001, 1976) die niet direct invloed hebben op de targetvariabele. Hoewel deze absolute jaartallen misschien niet direct de huizenprijs beïnvloeden, kunnen we nuttigere inzichten afleiden door te berekenen hoe oud het huis of de renovatie is op het moment van verkoop.
In plaats van YearBuilt te gebruiken, kunnen we bijvoorbeeld een nieuwe feature maken: House Age=YrSold−YearBuilt
Code om deze nieuwe features te maken:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]In machine learning kunnen scheve numerieke features de modelprestaties negatief beïnvloeden, vooral bij modellen die een normale verdeling veronderstellen (bijv. lineaire regressie). Om dit te corrigeren passen we een logtransformatie toe.
Voordat we een logtransformatie toepassen, moeten we scheve features identificeren. We sluiten echter kolommen met nullen uit, aangezien de logaritme van nul ongedefinieerd is.
Hier is een implementatie in Python om scheve kolommen te identificeren:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Output:

We gebruiken log-normale distributie om deze vijf scheve kolommen om te zetten naar een Gaussiaanse verdeling:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])We hebben eerder verschillende encoderingstechnieken besproken; in dit voorbeeld passen we target encoding toe.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)In de bovenstaande code is de targetvariabele SalePrice, dus groepeerden we de data per categorische kolom en berekenden we de gemiddelde SalePrice voor elke groep. Deze gemiddelde waarden zijn vervolgens toegewezen aan de overeenkomstige categorische waarden in die kolom.
Onze dataset is nu klaar voor machine learning!
Als je je begrip van supervised learning-concepten en hoe modellen gebruikmaken van ontworpen features wilt verdiepen, is deze cursus Supervised Learning with Scikit-Learn een excellente bron.
In deze sectie bespreken we de meest gebruikte Python-libraries en automatiseringstools om feature engineering te implementeren.
Pandas is het meest gebruikte Python-framework voor het werken met gestructureerde data. Het voert veel feature-engineeringstappen uit, zoals transformatie, data-aggregatie en feature-extractie. Met Pandas is data opschonen en manipuleren ook eenvoudig.
Als je nieuw bent met pandas, is deze cursus Data Manipulation with pandas een uitstekend startpunt.
Scikit-learn is een krachtige machine-learninglibrary met diverse tools voor feature engineering. Het bevat methoden zoals OneHotEncoder en LabelEncoder om categorisch naar numeriek om te zetten. Het biedt ook featureschaalmethoden zoals StandardScaler en Minmaxscaler.
Feature-engine is een open-source Python-library met verschillende transformers om feature engineering te vereenvoudigen. Deze transformers zijn gespecialiseerde tools voor specifieke taken, zoals imputatie van missende data, omgaan met outliers, featureselectie en discretisatie. Volledig compatibel met scikit-learn, kunnen deze transformers worden doorgegeven als inputparameters voor hyperparameter-tuning.
fit() biedt de library bijvoorbeeld een fit_transform()-methode die gelijktijdig fit- en transform-bewerkingen op de inputdata uitvoert. Bovendien zijn FeatureSelector en AutoFeatLight-modellen beschikbaar voor featureselectie en -schaling.Om feature engineering effectief te implementeren, focus je op deze best practices.
Als je de betekenis en het belang van elke feature begrijpt, wordt het veel makkelijker om technieken als featureselectie of -extractie uit te voeren. Ik raad je aan je data en relevante domeinkennis te onderzoeken voor effectieve feature engineering.
Gebruik Python-libraries zoals Pandas en Matplotlib om uitgebreide exploratory data analysis uit te voeren, zoals het verkennen van statistische informatie, visualisaties en correlaties om patronen en mogelijke relaties in de data te vinden.
Interactiefeatures creëren houdt in dat je relaties tussen bestaande features identificeert en daar nieuwe uit afleidt. In de voorspelling van huizenprijzen kun je bijvoorbeeld de leeftijd van een huis berekenen door het bouwjaar van het huidige jaar af te trekken; dit laat trends zien, zoals dalende huizenprijzen naarmate de tijd verstrijkt.
Verschillende machine-learningmodellen vereisen verschillende stappen in feature engineering. Modellen zoals lineaire of multiple regressie, SVM en KNN profiteren vaak van featurestandaardisatie, maar deze techniek helpt niet bij boomgebaseerde modellen.
Door je model van tevoren te kiezen, kun je een effectieve feature-engineeringpipeline opzetten voor jouw usecase.
Feature engineering is een integraal onderdeel van het bouwen van machine-learningoplossingen, waarmee je features zo efficiënt mogelijk benut. Het proces wordt uitgevoerd door data scientists of ML-engineers bij elke dataset. Als je data professional bent of dat wilt worden, helpt het beheersen van alle technieken in dit artikel je carrière vooruit!
Wil je deze technieken uitgebreider verkennen, bekijk dan de DataCamp-cursussen over feature engineering voor machine learning en feature engineering voor NLP. Er is ook een cursus over feature engineering voor R-programmeurs.
Leer meer over machine learning met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
