
Kurs
Python ile Zaman Serisi Verileri için Machine Learning
4 sa
53.3K
Farklı özellik mühendisliği tekniklerine dalmadan önce, mevcut özellik türlerini anlayalım.
İsminden de anlaşılacağı gibi, sayısal özellikler veriyi sayılarla ifade eder. Sürekli nicel değişkenlerdir. Örnekler arasında boy, yaş ve maaş bulunur.
Kategorik bir sütun yalnızca ayrık özellikler içerebilir. Örneğin, bir kişinin cinsiyeti yalnızca birkaç cinsiyet türü olabileceğinden kategorik bir sütundur. Doğum ayı da başka bir örnektir çünkü değerler Ocak ile Aralık arasında olmalıdır.
Kategorik değişkenler ikili ve ikili olmayan olarak ikiye ayrılır. İkili değişkenlerin iki olası kategorisi vardır, ikili olmayan özellikler ise birden fazla kategoriye sahip olabilir.
Metinsel sütunlar yalnızca metin verisi içerir. Örneklere perakende veri kümesindeki ürün yorumları veya ürün açıklaması sütunları dahildir.
Öte yandan zaman serisi özellikleri, haftalık satışlar veya bir yıl içindeki hisse senedi fiyat dalgalanmaları gibi zamana bağlı verileri temsil eder.
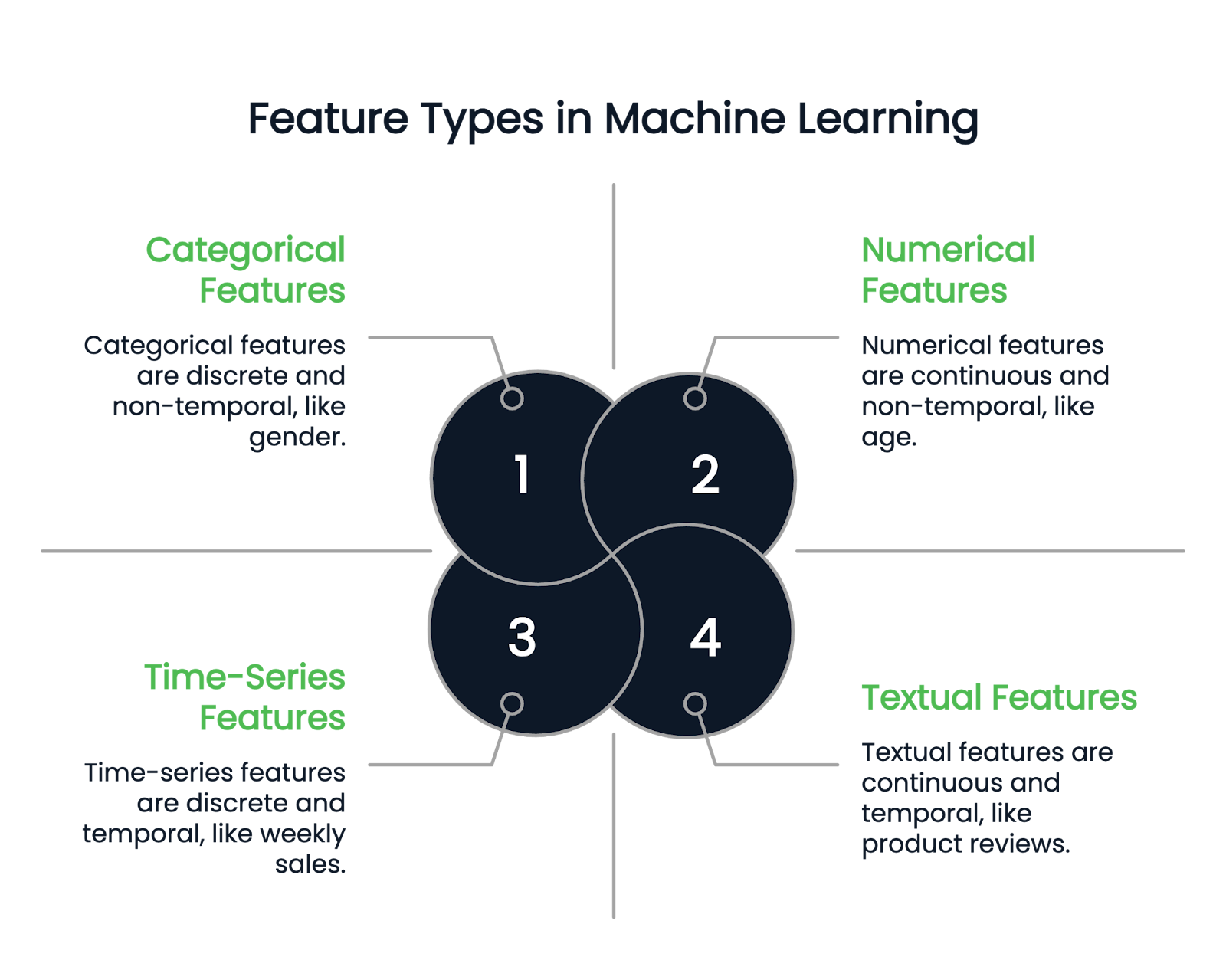
Görsel: Yazar
Özellik mühendisliği, ham sütunları istenen özelliklere dönüştürmek için çeşitli güçlü teknikler sunar. Burada öne çıkan bazılarını tartışıyoruz.
Eksik değerler model performansını bozabilir; bu nedenle doğru şekilde ele alınmaları kritiktir. Başlıca iki yaklaşım vardır:
Eksik verileri ele alma üzerine ayrıntılı bir rehber için şu Eksik Verileri Ele Alma Teknikleri Eğitimini okuyun veya şu Python’da Eksik Verilerle Başa Çıkma Kursunu inceleyin.
Aykırı değerler, diğer veri noktalarından önemli ölçüde farklı anormal değerlerdir. Örneğin, gözlemlerin çoğu 90.000 $ ile 120.000 $ arasında olan bir maaş veri kümesinde, 400.000 $ veya 10.000 $ gibi maaşlar aykırı değerdir.
Makine öğrenimi modelleri kategorik değişkenleri doğrudan işleyemez; bu nedenle bunların sayısal temsillere dönüştürülmesi gerekir. Aşağıda bazı popüler kodlama tekniklerini tartışıyoruz.
Aşağıdaki kategorik özelliğe sahip bir veri kümesini düşünün:
|
Ad |
Cinsiyet |
|
John |
Erkek |
|
Rachel |
Kadın |
|
Emma |
Kadın |
One-hot kodlama kullanarak, Cinsiyet özelliğindeki her olası kategori için ayrı sütunlar oluştururuz:
|
Ad |
Kadın |
Erkek |
|
John |
0 |
1 |
|
Richale |
1 |
0 |
|
Emma |
1 |
0 |
John Erkek olduğundan, "Erkek" sütunu 1 olurken "Kadın" sütunu 0 kalır. Benzer şekilde, Rachel ve Emma Kadın olduğundan "Kadın" sütunu 1, "Erkek" sütunu 0 olur.
Python’da one-hot kodlamaya dair eksiksiz bir eğitim için şu One-Hot Kodlama Eğitimine göz atın.
Konum sütununda kategorik değerler içeren bir veri kümesini düşünün:
|
Konum |
Kodlanmış değer |
|
New York |
1 |
|
California |
2 |
|
Texas |
3 |
|
California |
2 |
|
Texas |
3 |
Her benzersiz konuma farklı bir sayısal değer atanır. Ancak California (2) doğası gereği New York (1) ile Texas (3) arasında değildir; bu nedenle dereceli olmayan verilerde etiket kodlama kullanmak, modelde yanıltıcı varsayımlara yol açabilir. Bu gibi durumlarda, kategoriler arasında istenmeyen sayısal ilişkiler ima edilmesini önlemek için sıklıkla one-hot kodlama tercih edilir.
Aşağıdaki kategorilere sahip bir Eğitim seviyesi sütununu düşünün:
|
Eğitim seviyesi |
Kodlanmış değer |
|
UG (Lisans) |
1 |
|
PG (Yüksek Lisans) |
2 |
|
Doktora |
3 |
Doktora, PG’den; PG ise UG’den daha yüksek bir eğitim seviyesini temsil ettiğinden, atanan sayısal değerler bu sıralamayı yansıtır.
Konumun kategorik bir özellik ve Hedef değişkenin bazı sayısal çıktıyı temsil ettiği bir veri kümesini düşünün:
|
Konum |
Hedef değişken |
|
New York |
2 |
|
California |
3 |
|
Texas |
5 |
|
California |
1 |
|
Texas |
4 |
Konum sütununu kodlamak için, her benzersiz kategori için Hedef değişkenin ortalamasını hesaplarız:
|
Konum |
Kodlanmış değer |
|
New York |
2 |
|
California |
2 |
|
Texas |
4,5 |
|
California |
2 |
|
Texas |
4,5 |
Kategorik verileri ele almaya dair daha kapsamlı bir rehber arıyorsanız, şu Kategorik Veri İşleme Eğitimi ek içgörüler sunar.
Özellik ölçekleme, sayısal özelliklerin standart bir aralıkta yer almasını sağlar; böylece bazı özelliklerin daha büyük değerleri nedeniyle öğrenme sürecine hakim olmasını engeller.
Mesafe tabanlı hesaplamalara dayanan makine öğrenimi modelleri (ör. doğrusal regresyon, en yakın k-komşu ve sinir ağları), özellikler çok farklı ölçeklere sahip olduğunda etkilenebilir.
Örneğin, aşağıdaki özelliklere sahip bir çalışan veri kümesini düşünün:
Gelir, yaştan çok daha büyük değerlere sahip olduğundan, bir model ölçekten dolayı gelire daha fazla önem atayabilir; bu da gerçekte daha alakalı olduğu anlamına gelmez.
Bazı yaygın teknikler şunlardır:
Ölçeklenmiş değer =( veri_noktası - min(sütun))/(max(sütun) - min(sütun))
Ölçeklenmiş değer =( veri_noktası - ortalama(sütun))/(std(sütun))
Normalizasyon ve standardizasyonun ayrıntılı karşılaştırması için şu Normalizasyon vs. Standardizasyon Rehberine bakın.
Mevcut verilerden yeni ve anlamlı özellikler oluşturmak, modele daha mantıklı içgörüler sağlar.
Örneğin, bir konut fiyatı tahmini veri kümesinde length ve breadth sütunları ayrı ayrı varsa, yeni bir özellik türetebilirsiniz: area = length * breath; bu, hedef değişken olan price ile doğrudan ilişkili olabilir. Bu area özelliğini modele girmek, gizli kalıpları keşfetmeyi kolaylaştırır.
Özellik seçimi, gereksiz sütunları kaldırarak yalnızca ilgili özellikleri tutar. En bilgilendirici verilere odaklanmak, aşırı uyumu önlemeye, hesaplama karmaşıklığını azaltmaya ve model performansını iyileştirmeye yardımcı olur. Bazı teknikler şunlardır:
Özellik mühendisliğini en iyi, uygulamalı olarak gerçekleştirerek anlayabilirsiniz.
“Konut fiyatı tahmini”, 81 sütunlu, büyük ve gerçek dünyadan bir veri kümesidir. Çeşitli özellik aralığı sayesinde, özellik mühendisliği tekniklerini pratikte daha iyi anlamanıza yardımcı olması için bunu seçtim.
Başlarken:
Aşağıdaki kod, veri kümesindeki kategorik sütunları belirler ve eksik değerlerini en sık görülen kategoriyle değiştirir:
import pandas as pd
# Load dataset (replace 'your_file.csv' with the actual file name)
df = pd.read_csv('your_file.csv')
# Select categorical columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Replace missing values with the most frequent category (mode)
for col in categorical_cols:
mode = df[col].mode()[0] # Get the most common value
df[col].fillna(mode, inplace=True) # Fill missing valuesSayısal eksik değerleri ortalama veya medyan ile değiştirerek ele alıyoruz. İstatistiksel olarak dağılmış veriler için ortalama daha popüler bir seçenektir; sütunda aykırı değerler olduğunda medyan iyi çalışır. Bu nedenle, aykırı değerlere bakıp yönteme karar vereceğiz.
Olası aykırı değerleri görselleştirmek için, uç değerleri belirlemeye yardımcı olan kutu grafikleri kullanabiliriz. Aşağıda, seçili sayısal sütunlarda aykırı değerleri tespit etmek için bir Python uygulaması yer alır:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
features = ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
# Plot box plots
df[features]=np.log(df[features])
df[features].boxplot(figsize=(8, 4))
plt.title('Box Plot for Outlier Detection')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.show()Çıktı:
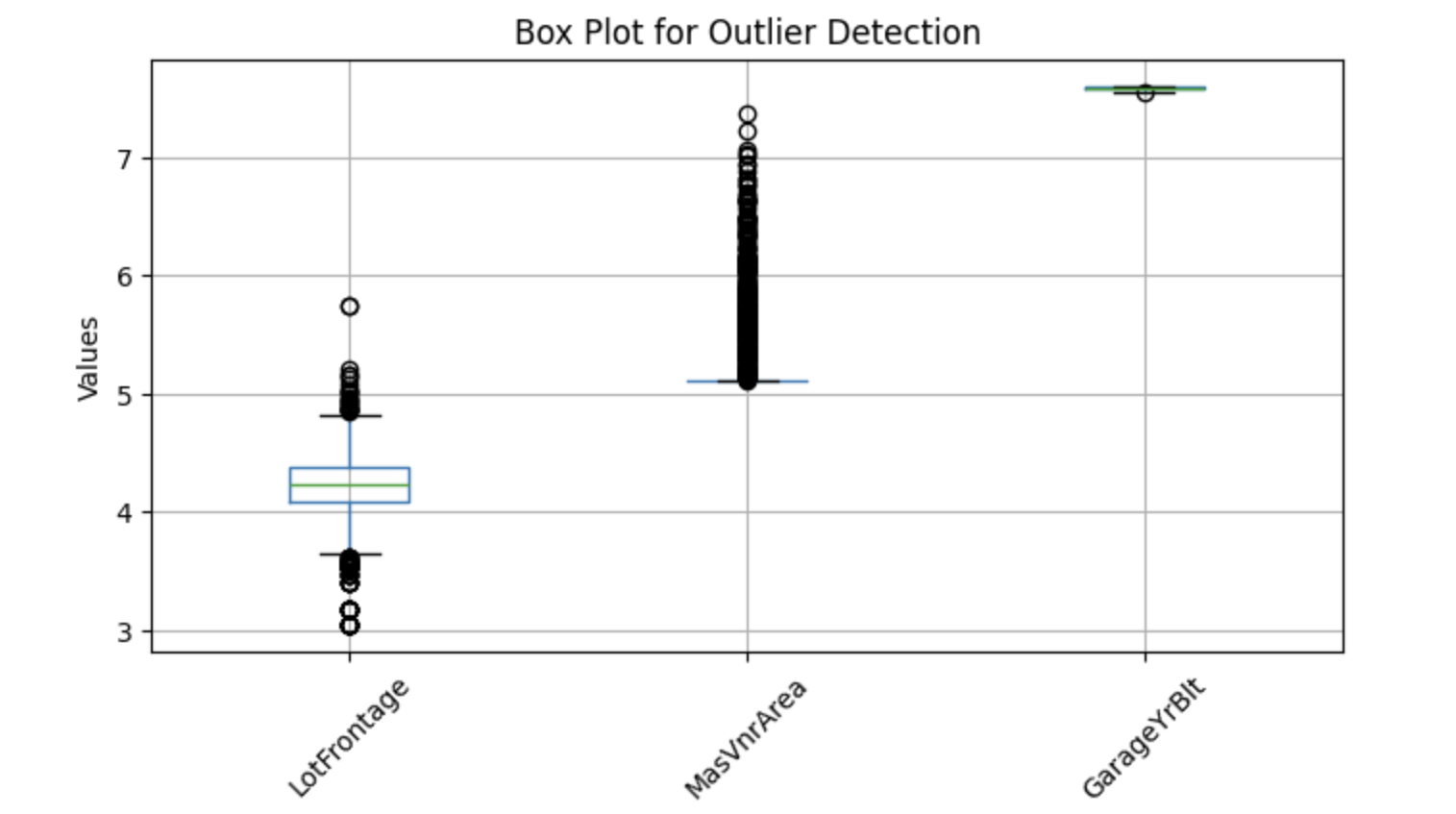
Yukarıdaki kutu grafikleri, bıyıkların dışındaki noktaları gösteriyor—bunlara aykırı değer denir. O halde, eksik değerleri medyan ile değiştirelim.
Boş değerleri medyanla değiştirme kodu:
import pandas as pd
# Select numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
for col in numerical_columns:
median = df[col].median()
df[col].fillna(median, inplace=True) # Replace nulls with medianYearBuilt, YearRemodAdd, GarageYrBlt ve YrSold gibi sütunlar (ör. 2001, 1976) yılı içerir ve hedef değişkeni doğrudan etkilemez. Bu mutlak yıl değerleri doğrudan konut fiyatlarını etkilemeyebilir; ancak satış anındaki evin veya tadilatın ne kadar eski olduğunu hesaplayarak daha faydalı içgörüler elde edebiliriz.
Örneğin, YearBuilt yerine şu yeni özelliği oluşturabiliriz: House Age=YrSold−YearBuilt
Bu yeni özellikleri oluşturma kodu:
# Get columns that contain 'Yr' or 'Year'
year_columns = [feature for feature in numerical_columns if 'Yr' in feature or 'Year' in feature]
# Convert year values into age-related features
for col in year_columns:
df[col] = df['YrSold'] - df[col]Makine öğreniminde, çarpık dağılıma sahip sayısal özellikler, özellikle normal dağılım varsayan modellerde (ör. doğrusal regresyon) model performansını olumsuz etkileyebilir. Bunu düzeltmek için log dönüşümü uygularız.
Log dönüşümü uygulamadan önce, çarpık özellikleri belirlemeliyiz. Ancak sıfır içeren sütunları hariç tutarız; çünkü sıfırın logaritması tanımsızdır.
Çarpık sütunları belirlemek için Python ile bir uygulama:
import pandas as pd
# Get numerical columns
numerical_columns = df.select_dtypes(include=['number']).columns
# Identify columns containing zeros
numerical_0s = df.loc[:, (df == 0).any()].select_dtypes(include=['number']).columns
# Remove columns that contain zeros from consideration
numerical_columns = numerical_columns.difference(numerical_0s)
# Calculate skewness for the remaining numerical columns
skewness = df[numerical_columns].skew()
# Set threshold for skewness (e.g., absolute value > 1 indicates high skewness)
skewed_columns = skewness[abs(skewness) > 1]
# Display skewed columns
print("Skewed Columns:")
print(skewed_columns)Çıktı:

Bu beş çarpık sütunu log-normal dağılım kullanarak Gaussian dağılıma dönüştüreceğiz:
import numpy as np
# The list of highly skewed features identified earlier
skew_features = ['LotFrontage', 'LotArea', '1stFlrSF', 'GrLivArea', 'SalePrice']
# Apply log transformation to each skewed feature
for col in skew_features:
df[col] = np.log(df[col])Önceden birkaç kodlama tekniğini tartıştık; bu örnekte hedef kodlama uygulayacağız.
# Select categorical variables
categorical_columns = df.select_dtypes(include=['object', 'category']).columns
# Apply target encoding
for col in categorical_columns:
# Compute mean SalePrice for each category
labels_ordered = df.groupby([col])['SalePrice'].mean().sort_values().index
# Assign numerical values based on target variable mean
labels_ordered = {x: i for i, x in enumerate(labels_ordered, 0)}
# Map encoded values back to the dataframe
df[col] = df[col].map(labels_ordered)Yukarıdaki kodda hedef değişken SalePrice olduğundan, verileri her kategorik sütuna göre grupladık ve her grup için ortalama SalePrice’ı hesapladık. Bu ortalama değerler daha sonra ilgili kategorik değerlere atandı.
Artık veri kümemiz makine öğrenimi için hazır!
Denetimli öğrenme kavramlarını ve modellerin tasarlanmış özellikleri nasıl kullandığını pekiştirmek istiyorsanız, şu Scikit-Learn ile Denetimli Öğrenme Kursu mükemmel bir kaynaktır.
Bu bölümde, özellik mühendisliğini uygulamak için en sık kullanılan Python kütüphaneleri ve otomasyon araçlarını ele alacağız.
Pandas, yapılandırılmış verileri işlemek için en çok kullanılan Python çatısıdır. Dönüştürme, veri toplulaştırma ve özellik çıkarımı gibi birçok özellik mühendisliği adımını gerçekleştirir. Pandas, veri temizleme ve manipülasyonunu da kolaylaştırır.
Pandas’a yeni başlıyorsanız, şu pandas ile Veri Manipülasyonu Kursu harika bir başlangıç noktasıdır.
Scikit-learn, özellik mühendisliği için çeşitli araçlara sahip güçlü bir makine öğrenimi kütüphanesidir. Kategorikleri sayısal değişkenlere dönüştürmek için OneHotEncoder ve LabelEncoder gibi yöntemler içerir. Ayrıca StandardScaler ve Minmaxscaler gibi özellik ölçekleme yöntemleri sunar.
Feature-engine, özellik mühendisliğini basitleştirmek için çeşitli dönüştürücüler sunan açık kaynak bir Python kütüphanesidir. Bu dönüştürücüler; eksik veri ataması, aykırı değer işleme, özellik seçimi ve ayrıklaştırma gibi belirli görevler için özelleşmiş araçlardır. Scikit-learn ile tamamen uyumludur ve bu dönüştürücüler hiperparametre ayarı için girdi parametresi olarak geçirilebilir.
fit() yerine, girdi verisi üzerinde aynı anda fit ve transform işlemlerini gerçekleştiren bir fit_transform() yöntemi sunar. Ayrıca, özellik seçimi ve ölçekleme için FeatureSelector ve AutoFeatLight modelleri mevcuttur.Özellik mühendisliğini etkili bir şekilde uygulamak için şu en iyi uygulamalara odaklanın.
Her bir özelliğin anlamını ve önemini anlamak, özellik seçimi veya çıkarımı gibi teknikleri uygulamayı çok daha kolay hale getirir. Etkili özellik mühendisliği için verinizi ve ilgili alan bilgisini araştırmanızı öneririm.
Pandas ve Matplotlib gibi Python kütüphanelerini kullanarak kapsamlı keşifsel veri analizi gerçekleştirin; ististatistiksel bilgiler, görselleştirmeler ve korelasyonları keşfederek verideki kalıpları ve olası ilişkileri bulun.
Etkileşim özellikleri oluşturmak, mevcut özellikler arasındaki ilişkileri belirlemeyi ve yenilerini türetmeyi içerir. Örneğin, konut fiyatı tahmininde, inşa yılından mevcut yılı çıkararak evin yaşını hesaplamak; zaman geçtikçe konut fiyatlarının düşmesi gibi eğilimleri vurgular.
Farklı makine öğrenimi modelleri, farklı özellik mühendisliği adımları gerektirir. Örneğin, doğrusal veya çoklu regresyon, SVM ve KNN gibi modeller genellikle özellik standardizasyonundan fayda sağlar; ancak bu teknik ağaç tabanlı modellere yardımcı olmaz.
Bu nedenle, modelinize önceden karar vermek, kullanım durumunuz için etkili bir özellik mühendisliği hattı kurmanıza yardımcı olabilir.
Özellik mühendisliği, özelliklerden en verimli şekilde yararlanmanızı sağlayarak makine öğrenimi çözümleri oluşturmanın ayrılmaz bir parçasıdır. Bu süreç, herhangi bir veri kümesiyle çalışırken veri bilimciler veya ML mühendisleri tarafından yürütülür. Bir veri profesyoneliyseniz ya da olmayı hedefliyorsanız, bu yazıda bahsedilen tüm tekniklerde ustalaşmak kariyerinizi ilerletmenize yardımcı olacaktır!
Bu teknikleri daha ayrıntılı keşfetmek için, DataCamp’in makine öğrenimi için özellik mühendisliği ve NLP için özellik mühendisliği kurslarına göz atın. Ayrıca R programcıları için özellik mühendisliği kursu da mevcut.
Bu kurslarla makine öğrenimi hakkında daha fazla bilgi edinin!
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
