Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeMenyiapkan Lingkungan
Instal SHAP menggunakan PyPI atau conda-forge:
pip install shapatau
conda install -c conda-forge shapMuat Telecom Customer Churn. Dataset terlihat bersih, dan kolom target adalah “Churn.”
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()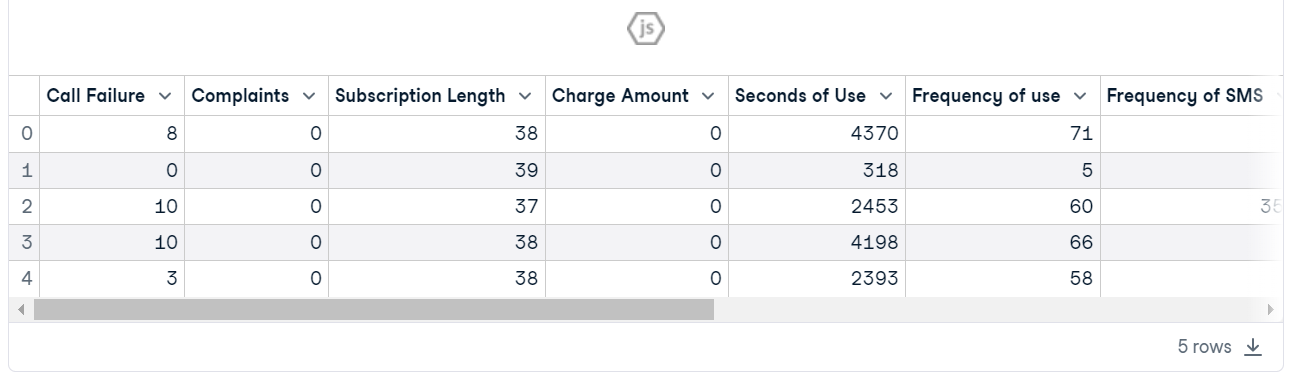
Pelatihan dan Evaluasi Model
- Buat X dan y menggunakan kolom target dan bagi dataset menjadi train dan test.
- Latih Random Forest Classifier pada data latih.
- Lakukan prediksi menggunakan data uji.
- Tampilkan classification report.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Model menunjukkan kinerja yang lebih baik untuk label “0” dibanding “1” karena dataset tidak seimbang. Secara keseluruhan, hasilnya dapat diterima dengan akurasi 94%.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Lihat panduan Klasifikasi dalam Machine Learning kami untuk mempelajari klasifikasi dalam machine learning dengan contoh Python.
Menyiapkan SHAP Explainer
Sekarang masuk ke bagian penjelas model.
Kita akan terlebih dahulu membuat objek explainer dengan memberikan model klasifikasi random forest, lalu menghitung nilai SHAP menggunakan data uji.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Summary Plot
Tampilkan summary_plot menggunakan nilai SHAP dan data uji.
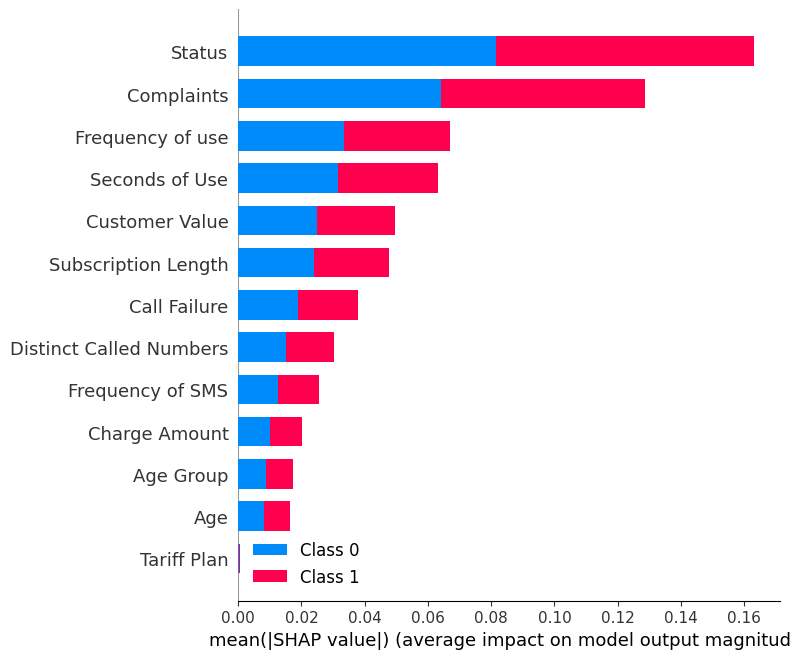
shap.summary_plot(shap_values, X_test)Summary plot menampilkan feature importance dari setiap fitur dalam model. Hasilnya menunjukkan bahwa “Status,” “Complaints,” dan “Frequency of use” berperan besar dalam menentukan hasil.
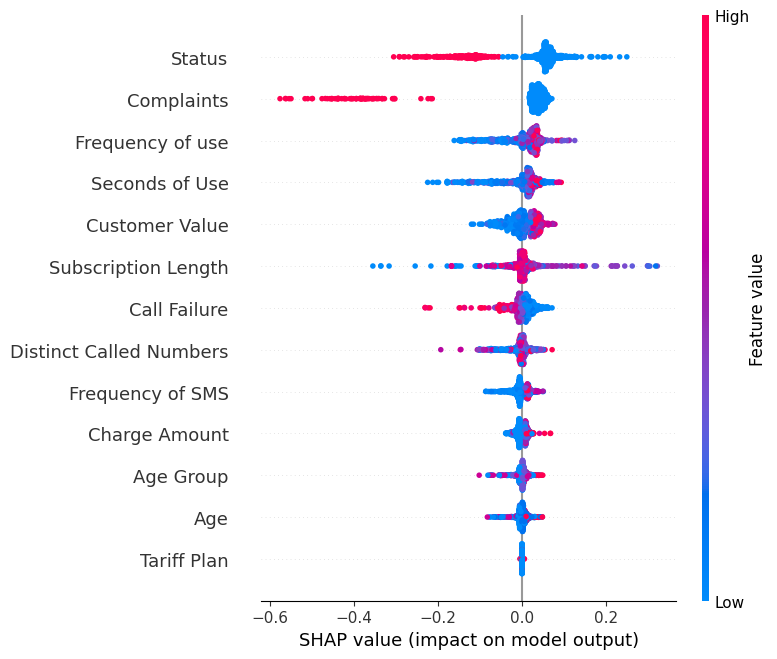
Tampilkan summary_plot untuk label “0”.
shap.summary_plot(shap_values[0], X_test)- Sumbu-Y menunjukkan nama fitur dalam urutan kepentingan dari atas ke bawah.
- Sumbu-X merepresentasikan nilai SHAP, yang menunjukkan derajat perubahan pada log odds.
- Warna setiap titik pada grafik merepresentasikan nilai fitur terkait, dengan merah menandakan nilai tinggi dan biru menandakan nilai rendah.
- Setiap titik merepresentasikan satu baris data dari dataset asli.
Jika Anda melihat fitur “Complaints", Anda akan melihat bahwa nilainya sebagian besar tinggi dengan nilai SHAP negatif. Artinya, jumlah keluhan yang lebih tinggi cenderung berdampak negatif pada keluaran.
Catatan: untuk label “1” visualisasinya akan terbalik.
Dependence Plot
Visualisasikan dependence_plot antara fitur “Subscription Length” dan “Age.”
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Dependence plot adalah jenis scatter plot yang menampilkan bagaimana prediksi model dipengaruhi oleh fitur tertentu (Subscription Length). Secara rata-rata, lama berlangganan memiliki efek yang sebagian besar positif pada model.
Force Plot
Kita akan meninjau sampel pertama di data uji untuk menentukan fitur mana yang berkontribusi pada hasil "0". Untuk itu, kita akan menggunakan force plot dan menyertakan expected value, nilai SHAP, dan sampel uji.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Kita dapat melihat dengan jelas bahwa nol keluhan dan nol kegagalan panggilan berkontribusi negatif terhadap kehilangan pelanggan.
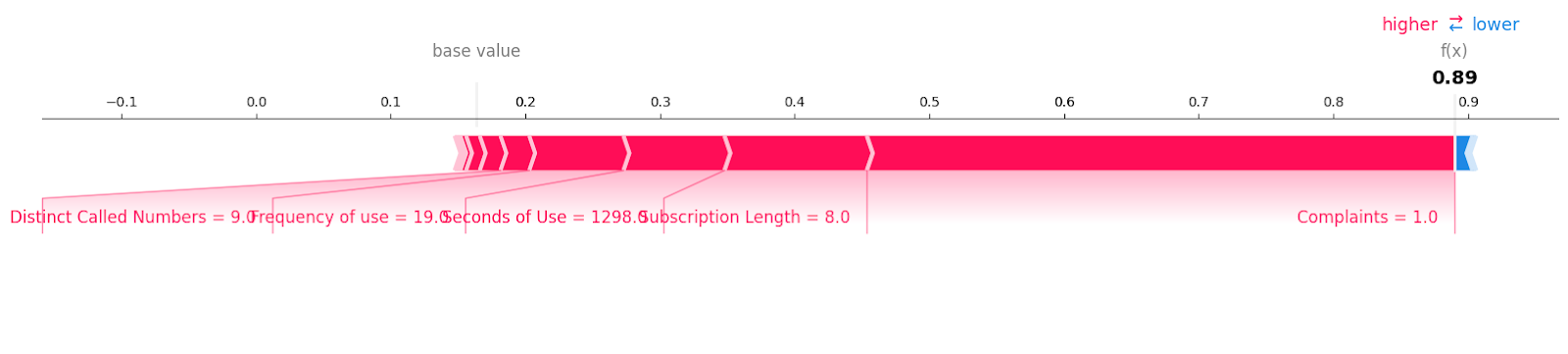
Mari melihat sampel churn pelanggan dengan label “1”.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Anda dapat melihat semua fitur beserta nilai dan magnitudonya yang berkontribusi pada kehilangan pelanggan. Tampaknya bahkan satu keluhan yang tidak terselesaikan dapat merugikan perusahaan telekomunikasi.
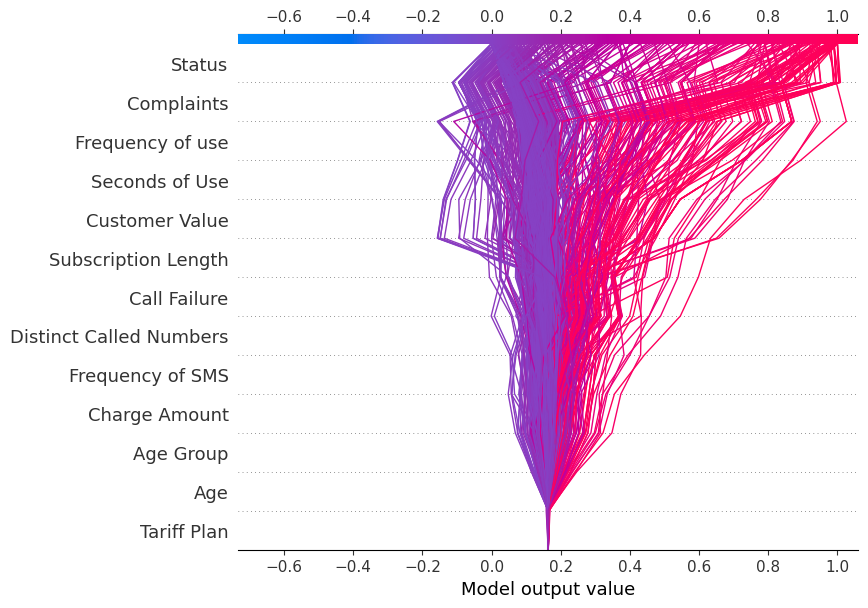
Decision Plot
Sekarang kita akan menampilkan decision_plot. Plot ini secara visual menggambarkan keputusan model dengan memetakan nilai SHAP kumulatif untuk setiap prediksi.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Setiap garis pada decision plot menunjukkan seberapa kuat fitur-fitur individual berkontribusi pada satu prediksi model, sehingga menjelaskan nilai fitur mana yang mendorong prediksi.
Catatan: Decision plot untuk label target “1” condong ke arah “1”.
Tampilkan decision plot untuk label target “0”
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Untuk decision plot ini condong ke arah “0”.

Penerapan Nilai SHAP
Selain interpretabilitas dan keterjelasan machine learning, nilai SHAP dapat digunakan untuk:
- Debugging model. Dengan memeriksa nilai SHAP, kita dapat mengidentifikasi bias atau outlier dalam data yang mungkin menyebabkan model membuat kesalahan.
- Kepentingan fitur. Mengidentifikasi dan menghapus fitur berdampak rendah dapat menghasilkan model yang lebih optimal.
- Penjelasan terjangkar. Kita dapat menggunakan nilai SHAP untuk menjelaskan prediksi individual dengan menyoroti fitur-fitur penting yang menyebabkan prediksi tersebut. Ini dapat membantu pengguna memahami dan memercayai keputusan model.
- Ringkasan model. Dapat memberikan ringkasan global model dalam bentuk summary plot nilai SHAP. Ini memberikan gambaran fitur paling penting di seluruh dataset.
- Mendeteksi bias. Analisis nilai SHAP membantu mengidentifikasi apakah fitur tertentu secara tidak proporsional memengaruhi kelompok tertentu. Ini memungkinkan deteksi dan pengurangan diskriminasi dalam model.
- Audit keadilan. Dapat digunakan untuk menilai keadilan dan implikasi etis model.
- Persetujuan regulatori. Nilai SHAP dapat membantu memperoleh persetujuan regulator dengan menjelaskan keputusan model.
Kesimpulan
Kita telah menelaah nilai SHAP dan bagaimana kita dapat menggunakannya untuk memberikan interpretabilitas bagi model machine learning. Meskipun memiliki model yang akurat itu penting, perusahaan perlu melampaui akurasi dan berfokus pada interpretabilitas serta transparansi untuk mendapatkan kepercayaan pengguna dan regulator.
Kemampuan menjelaskan mengapa model membuat prediksi tertentu membantu melakukan debug potensi bias, mengidentifikasi masalah data, dan membenarkan keputusan model.
Jika Anda baru dalam machine learning dan ingin siap kerja, pertimbangkan untuk mengambil jalur karier Machine Learning Scientist with Python. Program ini akan membantu Anda menguasai keterampilan Python yang diperlukan untuk menjadi ilmuwan machine learning dan mendapatkan pekerjaan.

