Willst du mit generativer KI beginnen?
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenEinrichten
Installiere SHAP entweder über PyPI oder conda-forge:
pip install shapoder
conda install -c conda-forge shapLade die Telekommunikationskundenabwanderung. Der Datensatz sieht sauber aus, und die Zielspalte ist "Churn".
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()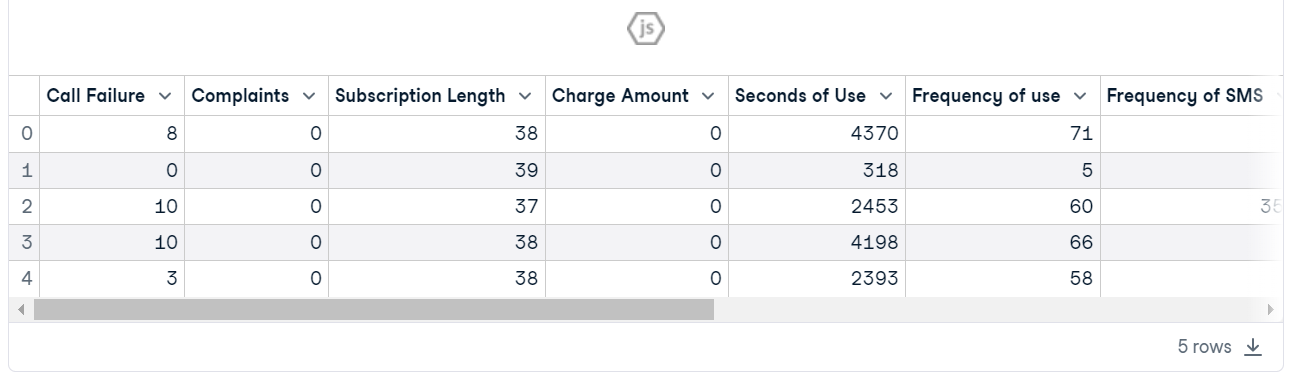
Modellschulung und Bewertung
- Erstelle X und y mithilfe einer Zielspalte und teile den Datensatz in Train und Test.
- Trainiere den Random Forest Classifier mit der Trainingsmenge.
- Mache Vorhersagen mit Hilfe einer Testgruppe.
- Klassifizierungsbericht anzeigen.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Das Modell hat aufgrund eines unausgewogenen Datensatzes eine bessere Leistung für das Label "0" als für das Label "1" gezeigt. Insgesamt ist es ein akzeptables Ergebnis mit 94% Genauigkeit.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945In unserem Leitfaden zur Klassifizierung im maschinellen Lernen erfährst du mehr über die Klassifizierung im maschinellen Lernen anhand von Python-Beispielen.
SHAP Explainer einrichten
Jetzt kommt der Teil mit dem Erklärungsmodell.
Wir erstellen zunächst ein Erklärungsobjekt, indem wir ein Random-Forest-Klassifizierungsmodell bereitstellen, und berechnen dann den SHAP-Wert anhand einer Testmenge.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Zusammenfassung des Plots
Zeige die summary_plot mit den SHAP-Werten und dem Testset an.
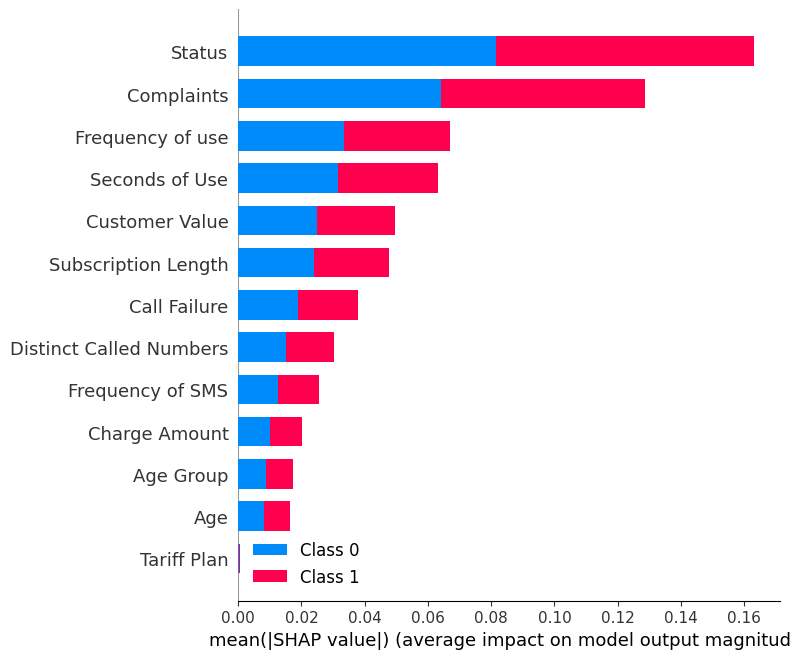
shap.summary_plot(shap_values, X_test)Die zusammenfassende Darstellung zeigt die Bedeutung jedes Merkmals im Modell. Die Ergebnisse zeigen, dass "Status", "Beschwerden" und "Häufigkeit der Nutzung" eine wichtige Rolle bei der Ermittlung der Ergebnisse spielen.
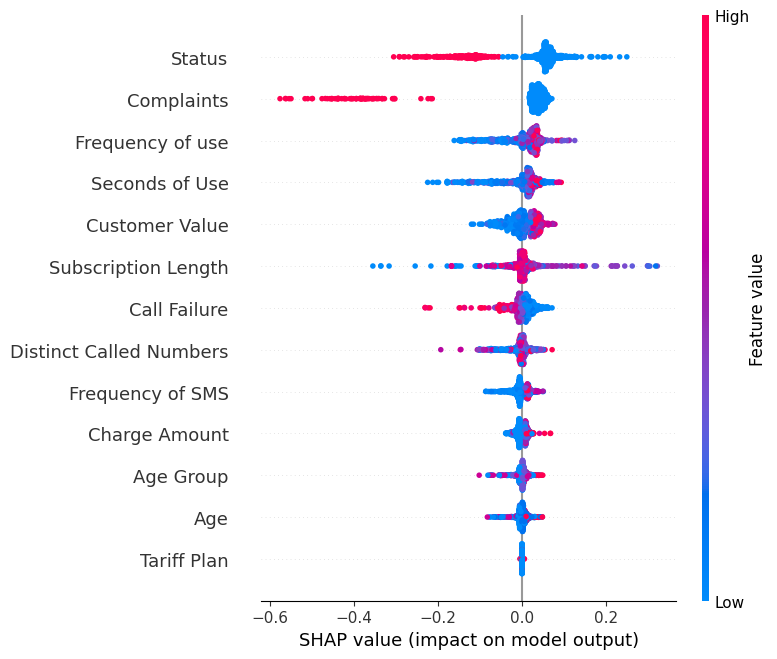
Zeige die summary_plot des Labels "0" an.
shap.summary_plot(shap_values[0], X_test)- Die Y-Achse zeigt die Namen der Merkmale in der Reihenfolge ihrer Bedeutung von oben nach unten an.
- Die X-Achse stellt den SHAP-Wert dar, der den Grad der Veränderung der logarithmischen Quoten angibt.
- Die Farbe jedes Punktes auf dem Diagramm steht für den Wert des entsprechenden Merkmals, wobei Rot für hohe und Blau für niedrige Werte steht.
- Jeder Punkt steht für eine Datenzeile aus dem Originaldatensatz.
Wenn du dir das Merkmal "Beschwerden" ansiehst, wirst du sehen, dass es meist hoch ist und einen negativen SHAP-Wert hat. Das bedeutet, dass sich eine höhere Anzahl von Beschwerden eher negativ auf die Leistung auswirkt.
Hinweis: Bei der Bezeichnung "1" wird die Visualisierung gespiegelt.
Abhängigkeitsdiagramm
Visualisiere die dependence_plot zwischen dem Merkmal "Abonnementlänge" und "Alter".
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Ein Abhängigkeitsdiagramm ist eine Art Streudiagramm, das zeigt, wie die Vorhersagen eines Modells von einem bestimmten Merkmal (Abonnementlänge) beeinflusst werden. Im Durchschnitt wirken sich die Abonnementlängen meist positiv auf das Modell aus.
Kraftplot
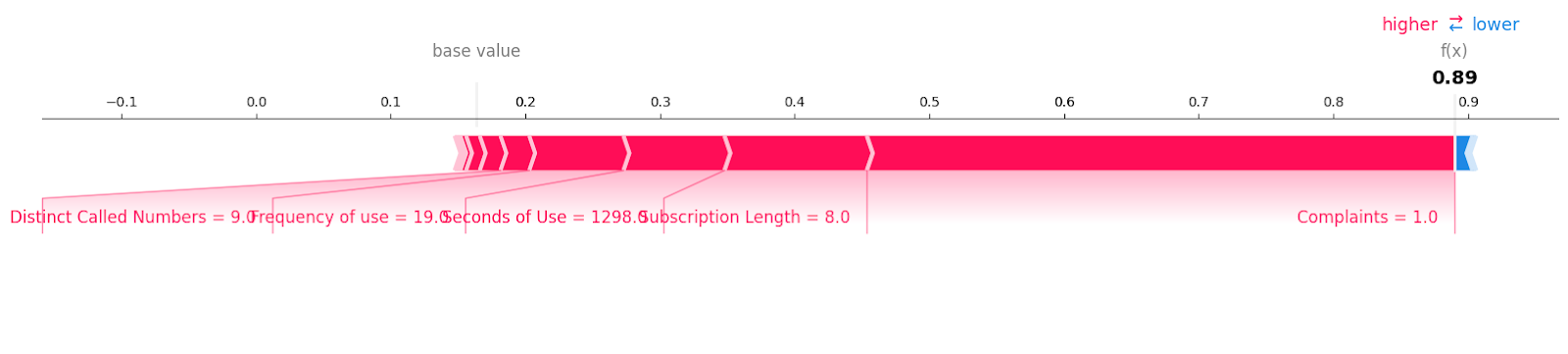
Wir untersuchen die erste Probe in der Testgruppe, um festzustellen, welche Merkmale zu dem Ergebnis "0" beigetragen haben. Dazu verwenden wir ein Kraftdiagramm und geben den erwarteten Wert, den SHAP-Wert und die Testprobe an.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Wir können deutlich sehen, dass null Beschwerden und null Anrufausfälle zu einem negativen Kundenverlust beigetragen haben.
Betrachten wir die Kundenabwanderungsmuster mit dem Label "1".
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Du kannst alle Funktionen mit dem Wert und dem Ausmaß sehen, die zu einem Kundenverlust beigetragen haben. Es scheint, dass schon eine einzige ungelöste Beschwerde ein Telekommunikationsunternehmen kosten kann.
Entscheidung Plot
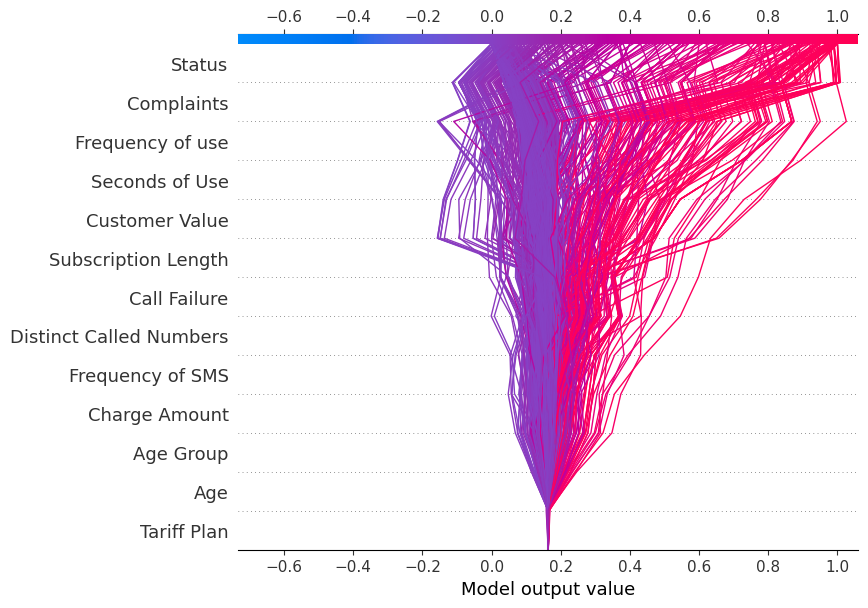
Wir werden nun die decision_plot anzeigen. Sie stellt die Modellentscheidungen visuell dar, indem sie die kumulativen SHAP-Werte für jede Vorhersage abbildet.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Jede gezeichnete Linie auf dem Entscheidungsdiagramm zeigt, wie stark die einzelnen Merkmale zu einer einzelnen Modellvorhersage beigetragen haben, und erklärt so, welche Merkmalswerte die Vorhersage beeinflusst haben.
Hinweis: Das Entscheidungsdiagramm für die Zielmarke "1" ist in Richtung "1" geneigt.
Zeige den Entscheidungsplot für die Zielbeschriftung "0" an
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Denn das Entscheidungsdiagramm ist gegen "0" geneigt.

Anwendung der SHAP-Werte
Abgesehen von der Interpretierbarkeit und Erklärbarkeit des maschinellen Lernens kann der SHAP-Wert für Folgendes verwendet werden:
- Modell-Debugging. Durch die Untersuchung der SHAP-Werte können wir alle Verzerrungen oder Ausreißer in den Daten erkennen, die das Modell zu Fehlern verleiten könnten.
- Bedeutung der Funktion. Durch die Identifizierung und Entfernung von Merkmalen mit geringer Auswirkung kann ein optimiertes Modell erstellt werden.
- Erklärungen zur Verankerung. Wir können SHAP-Werte nutzen, um einzelne Vorhersagen zu erklären, indem wir die wesentlichen Merkmale hervorheben, die diese Vorhersage verursacht haben. Sie kann den Nutzern helfen, die Entscheidungen eines Modells zu verstehen und ihnen zu vertrauen.
- Modellzusammenfassungen. Es kann eine globale Zusammenfassung eines Modells in Form einer SHAP-Wert-Zusammenfassung liefern. Sie gibt einen Überblick über die wichtigsten Merkmale des gesamten Datensatzes.
- Vorurteile aufdecken. Die SHAP-Wertanalyse hilft dabei, festzustellen, ob bestimmte Merkmale bestimmte Gruppen unverhältnismäßig stark betreffen. Sie ermöglicht die Erkennung und Reduzierung von Diskriminierung im Modell.
- Fairness-Prüfung. Sie kann genutzt werden, um die Fairness und die ethischen Implikationen eines Modells zu bewerten.
- Regulatorische Zulassung. Die SHAP-Werte können helfen, die Genehmigung der Behörden zu erhalten, indem sie die Entscheidungen des Modells erklären.
Fazit
Wir haben die SHAP-Werte untersucht und wie wir sie nutzen können, um Modelle für maschinelles Lernen interpretierbar zu machen. Ein genaues Modell ist zwar wichtig, aber die Unternehmen müssen über die Genauigkeit hinausgehen und sich auf die Interpretierbarkeit und Transparenz konzentrieren, um das Vertrauen der Nutzer und der Regulierungsbehörden zu gewinnen.
Wenn du in der Lage bist zu erklären, warum ein Modell eine bestimmte Vorhersage getroffen hat, kannst du mögliche Verzerrungen beseitigen, Datenprobleme erkennen und die Entscheidungen des Modells rechtfertigen.
Wenn du neu im Bereich des maschinellen Lernens bist und dich für den Job fit machen willst, solltest du den Berufswunsch Machine Learning Scientist with Python in Betracht ziehen. Dieses Programm hilft dir dabei, die notwendigen Python-Kenntnisse zu erlangen, um ein/e Wissenschaftler/in für maschinelles Lernen zu werden und einen Job zu bekommen.

