Você quer começar a usar a IA generativa?
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Execute e edite o código deste tutorial online
Executar códigoConfiguração
Instale o SHAP usando o PyPI ou o conda-forge:
pip install shapou
conda install -c conda-forge shapCarregar a rotatividade de clientes de telecomunicações. O conjunto de dados parece limpo, e a coluna de destino é "Churn".
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
Treinamento e avaliação de modelos
- Crie X e y usando uma coluna de destino e divida o conjunto de dados em treinamento e teste.
- Treine o classificador Random Forest no conjunto de treinamento.
- Faça previsões usando um conjunto de testes.
- Exibir relatório de classificação.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))O modelo apresentou melhor desempenho para o rótulo "0" do que para o rótulo "1" devido a um conjunto de dados desequilibrado. No geral, é um resultado aceitável com 94% de precisão.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Confira nosso guia de classificação em aprendizado de máquina para aprender sobre classificação em aprendizado de máquina com exemplos em Python.
Configuração do SHAP Explainer
Agora vem a parte da explicação do modelo.
Primeiro, criaremos um objeto de explicação fornecendo um modelo de classificação de floresta aleatória e, em seguida, calcularemos o valor SHAP usando um conjunto de testes.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Resumo do enredo
Exiba o site summary_plot usando os valores SHAP e o conjunto de testes.
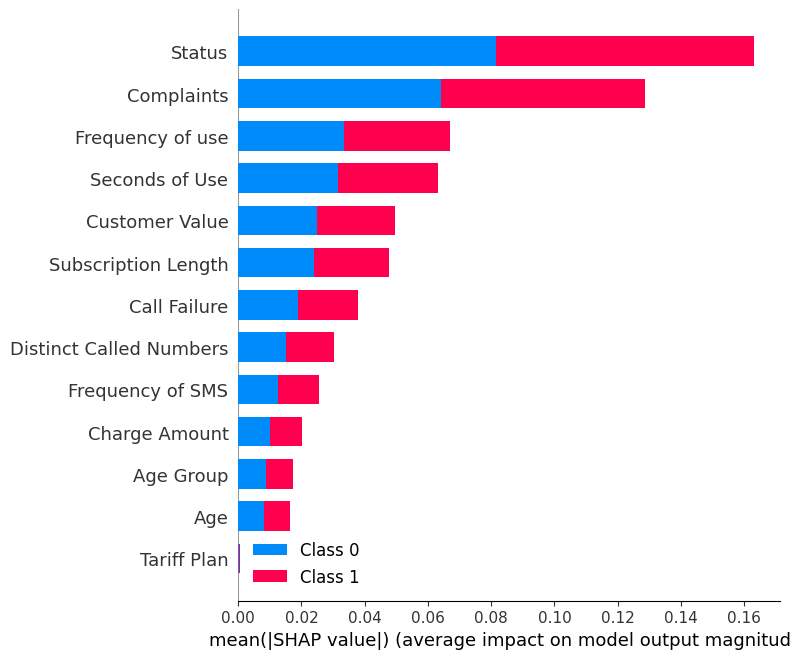
shap.summary_plot(shap_values, X_test)O gráfico de resumo mostra a importância de cada recurso no modelo. Os resultados mostram que "Status", "Reclamações" e "Frequência de uso" desempenham papéis importantes na determinação dos resultados.
Exiba o endereço summary_plot do rótulo "0".
shap.summary_plot(shap_values[0], X_test)- O eixo Y indica os nomes dos recursos em ordem de importância, de cima para baixo.
- O eixo X representa o valor SHAP, que indica o grau de alteração nas probabilidades de registro.
- A cor de cada ponto no gráfico representa o valor do recurso correspondente, com o vermelho indicando valores altos e o azul indicando valores baixos.
- Cada ponto representa uma linha de dados do conjunto de dados original.
Se você observar o recurso "Complaints" (Reclamações), verá que ele é, em sua maioria, alto, com um valor SHAP negativo. Isso significa que um número maior de reclamações tende a afetar negativamente o resultado.
Observação: para o rótulo "1", a visualização será invertida.
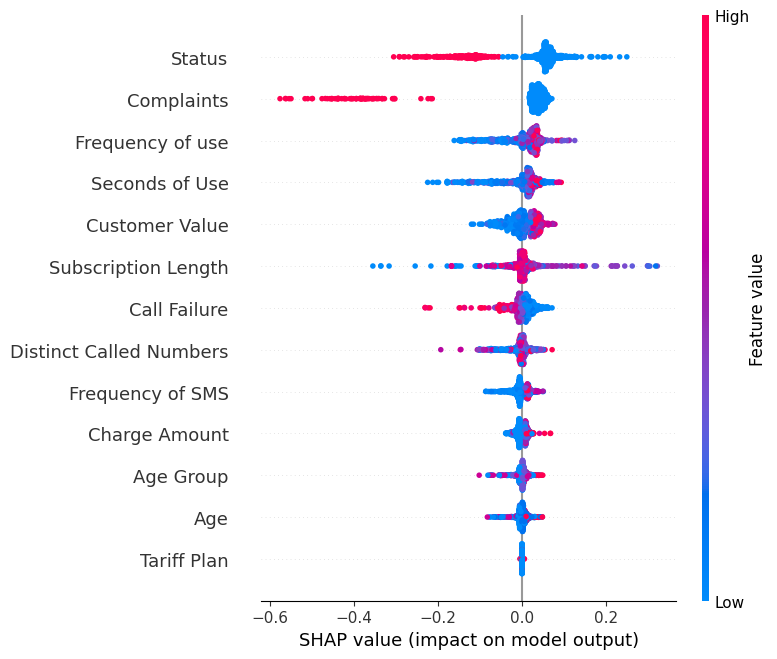
Gráfico de dependência
Visualize o dependence_plot entre o recurso "Subscription Length" (duração da assinatura) e "Age" (idade).
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Um gráfico de dependência é um tipo de gráfico de dispersão que mostra como as previsões de um modelo são afetadas por um recurso específico (comprimento da assinatura). Em média, a duração das assinaturas tem um efeito positivo no modelo.
Gráfico de força
Examinaremos a primeira amostra do conjunto de testes para determinar quais recursos contribuíram para o resultado "0". Para isso, utilizaremos um gráfico de força e forneceremos o valor esperado, o valor SHAP e a amostra de teste.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Podemos ver claramente que zero reclamações e zero falhas nas chamadas contribuíram negativamente para a perda de clientes.
Vejamos as amostras de rotatividade de clientes com o rótulo "1".
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Você pode ver todos os recursos com o valor e a magnitude que contribuíram para a perda de clientes. Parece que até mesmo uma reclamação não resolvida pode custar caro para uma empresa de telecomunicações.
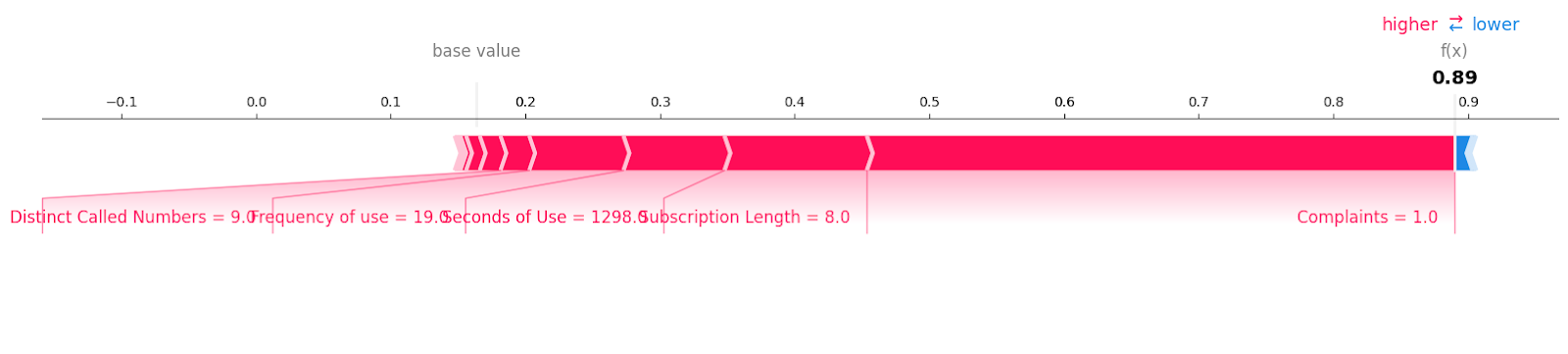
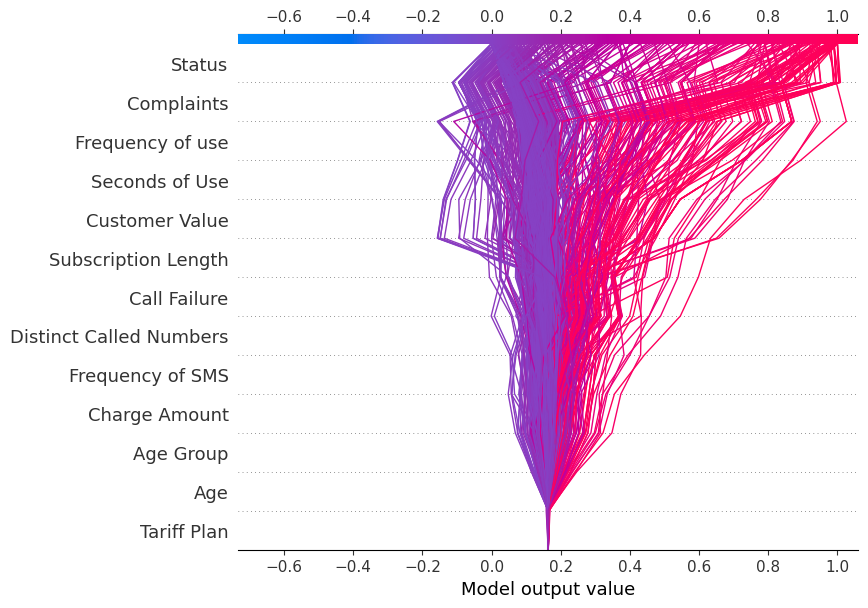
Gráfico de decisão
Agora, exibiremos o site decision_plot. Ele descreve visualmente as decisões do modelo mapeando os valores SHAP cumulativos para cada previsão.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Cada linha traçada no gráfico de decisão mostra a intensidade com que os recursos individuais contribuíram para uma única previsão de modelo, explicando assim quais valores de recursos impulsionaram a previsão.
Observação: O gráfico de decisão do rótulo de destino "1" está inclinado para "1".
Exibir o gráfico de decisão para o rótulo de destino "0"
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)O gráfico de decisão está inclinado para "0".

Aplicação de valores SHAP
Além da capacidade de interpretação e explicação do aprendizado de máquina, o valor SHAP pode ser usado para:
- Depuração de modelos. Ao examinar os valores de SHAP, podemos identificar quaisquer distorções ou discrepâncias nos dados que possam estar fazendo com que o modelo cometa erros.
- Importância do recurso. A identificação e a remoção de recursos de baixo impacto podem criar um modelo mais otimizado.
- Explicações de ancoragem. Podemos usar os valores de SHAP para explicar previsões individuais, destacando os recursos essenciais que causaram essa previsão. Ele pode ajudar os usuários a entender e confiar nas decisões de um modelo.
- Resumos de modelos. Ele pode fornecer um resumo global de um modelo na forma de um gráfico de resumo do valor SHAP. Ele fornece uma visão geral dos recursos mais importantes em todo o conjunto de dados.
- Detecção de vieses. A análise de valor do SHAP ajuda a identificar se determinados recursos afetam desproporcionalmente grupos específicos. Ele permite a detecção e a redução da discriminação no modelo.
- Auditoria de imparcialidade. Ele pode ser usado para avaliar a imparcialidade e as implicações éticas de um modelo.
- Aprovação regulatória. Os valores do SHAP podem ajudar a obter aprovação regulatória, explicando as decisões do modelo.
Conclusão
Exploramos os valores SHAP e como podemos usá-los para oferecer interpretabilidade aos modelos de aprendizado de máquina. Embora seja essencial ter um modelo preciso, as empresas precisam ir além da precisão e se concentrar na interpretabilidade e na transparência para ganhar a confiança dos usuários e dos órgãos reguladores.
A capacidade de explicar por que um modelo fez uma previsão específica ajuda a depurar possíveis vieses, identificar problemas de dados e justificar as decisões do modelo.
Se você é novo no aprendizado de máquina e quer se preparar para o trabalho, considere fazer o curso de Cientista de Aprendizado de Máquina com Python. Este programa ajudará você a dominar as habilidades necessárias em Python para se tornar um cientista de aprendizado de máquina e conseguir um emprego.


