Esegui e modifica il codice da questo tutorial online
Esegui codiceConfigurazione
Installa SHAP usando PyPI oppure conda-forge:
pip install shapoppure
conda install -c conda-forge shapCarica il dataset Telecom Customer Churn. Il dataset sembra pulito e la colonna target è “Churn”.
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()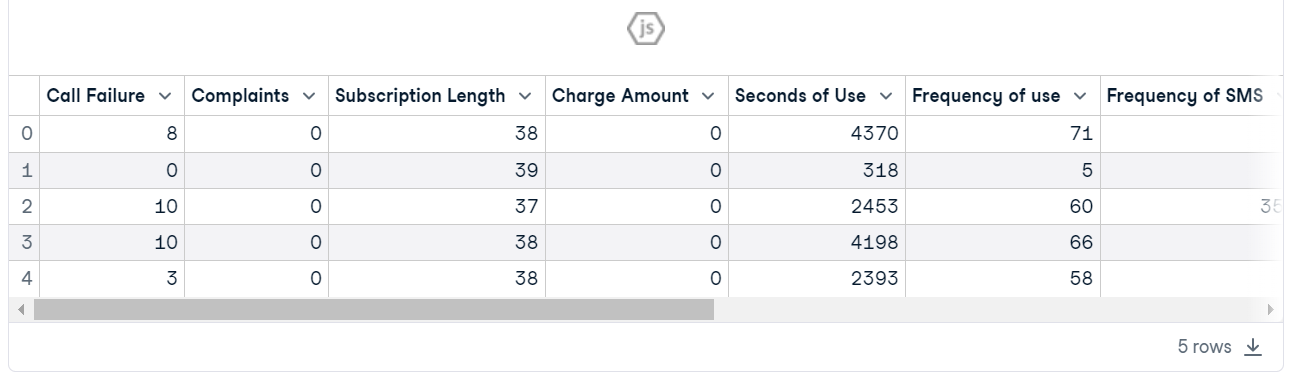
Addestramento e valutazione del modello
- Crea X e y usando la colonna target e dividi il dataset in train e test.
- Addestra un Random Forest Classifier sul set di training.
- Effettua le previsioni usando il set di test.
- Mostra il classification report.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Il modello ha mostrato prestazioni migliori per l’etichetta “0” rispetto a “1” a causa di un dataset sbilanciato. Nel complesso, è un risultato accettabile con un’accuratezza del 94%.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Dai un’occhiata alla nostra guida Classification in Machine Learning per imparare la classificazione nel machine learning con esempi in Python.
Configurare lo SHAP Explainer
Arriviamo ora alla parte dell’explainer del modello.
Per prima cosa creeremo un oggetto explainer fornendo un modello di classificazione random forest, quindi calcoleremo i valori SHAP usando il set di test.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Summary Plot
Mostra il summary_plot usando i valori SHAP e il set di test.
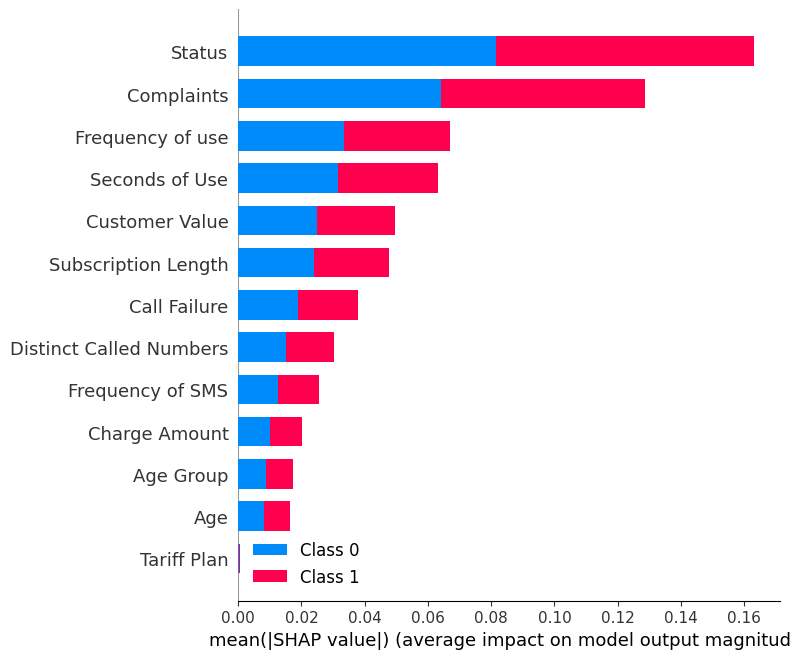
shap.summary_plot(shap_values, X_test)Il summary plot mostra l’importanza di ciascuna caratteristica nel modello. I risultati indicano che “Status”, “Complaints” e “Frequency of use” svolgono un ruolo chiave nel determinare i risultati.
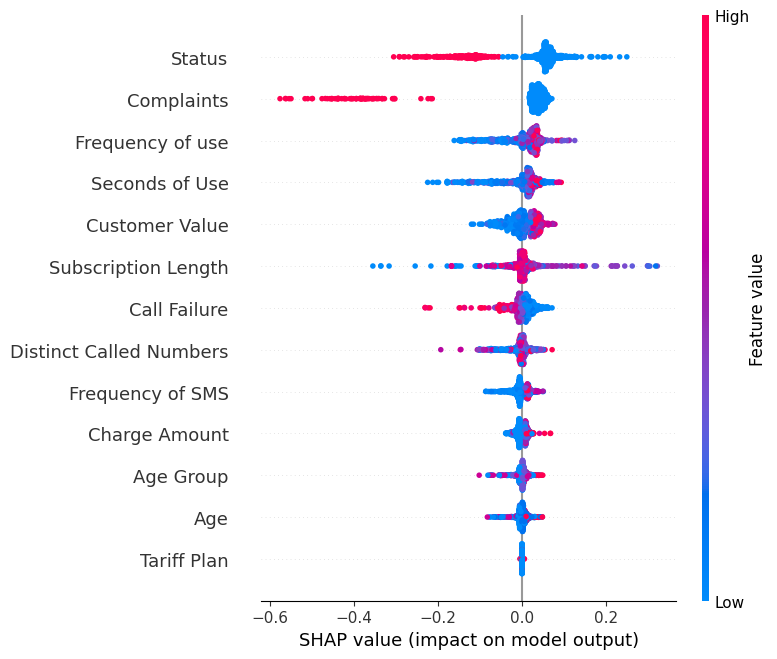
Mostra il summary_plot dell’etichetta “0”.
shap.summary_plot(shap_values[0], X_test)- L’asse Y indica i nomi delle caratteristiche in ordine di importanza dall’alto verso il basso.
- L’asse X rappresenta il valore SHAP, che indica l’entità del cambiamento nei log-odds.
- Il colore di ogni punto sul grafico rappresenta il valore della corrispondente caratteristica: rosso indica valori alti e blu valori bassi.
- Ogni punto rappresenta una riga di dati del dataset originale.
Se guardi la caratteristica “Complaints”, noterai che è per lo più alta con un valore SHAP negativo. Significa che conteggi più elevati di reclami tendono a influenzare negativamente l’output.
Nota: per l’etichetta “1” la visualizzazione sarà ribaltata.
Dependence Plot
Visualizza il dependence_plot tra le caratteristiche “Subscription Length” e “Age”.
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Un dependence plot è un tipo di scatter plot che mostra come le previsioni di un modello sono influenzate da una caratteristica specifica (Subscription Length). In media, le durate dell’abbonamento hanno un effetto per lo più positivo sul modello.
Force Plot
Esamineremo il primo campione nel set di test per determinare quali caratteristiche hanno contribuito al risultato "0". Per farlo, utilizzeremo un force plot e forniremo il valore atteso, il valore SHAP e il campione di test.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Si vede chiaramente che zero reclami e zero chiamate fallite hanno contribuito negativamente alla perdita di clienti.
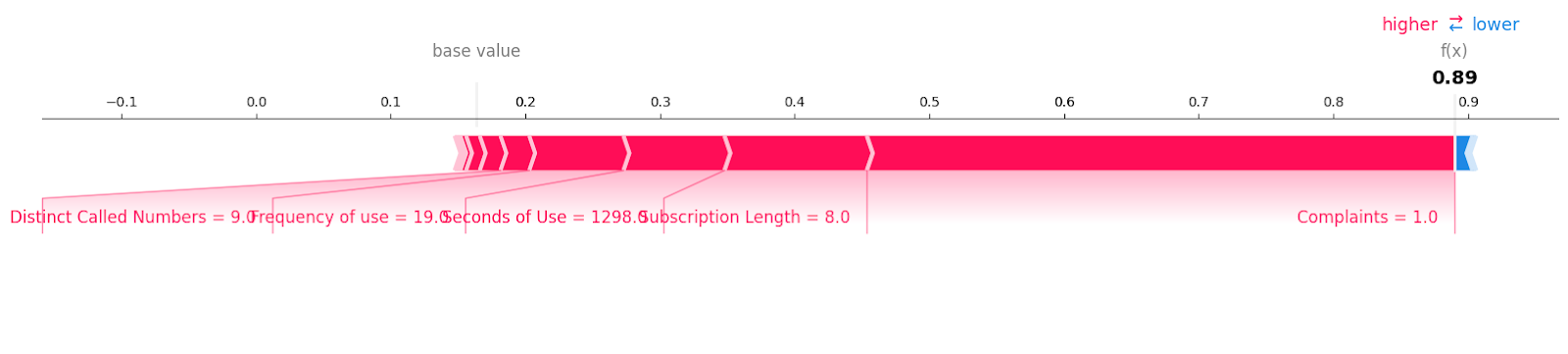
Diamo un’occhiata ai campioni di churn con etichetta “1”.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Puoi vedere tutte le caratteristiche con il relativo valore e la magnitudine che hanno contribuito alla perdita di clienti. Sembra che anche un solo reclamo non risolto possa costare caro a un’azienda di telecomunicazioni.
Decision Plot
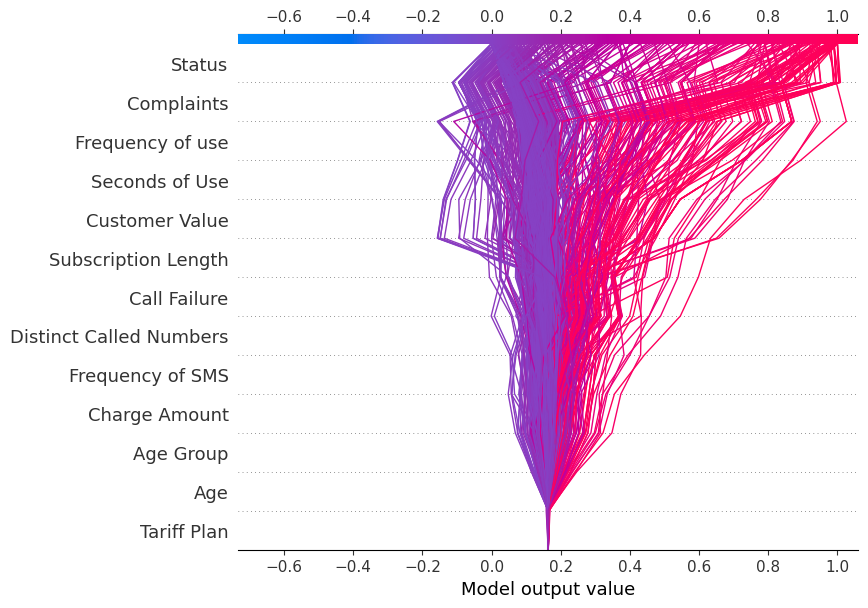
Ora mostreremo il decision_plot. Rappresenta visivamente le decisioni del modello mappando i valori SHAP cumulativi per ciascuna previsione.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Ogni linea tracciata nel decision plot mostra quanto fortemente le singole caratteristiche hanno contribuito a una singola previsione del modello, spiegando quindi quali valori delle caratteristiche hanno spinto la previsione.
Nota: il decision plot per l’etichetta target “1” è inclinato verso “1”.
Mostra il decision plot per l’etichetta target “0”
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Per il decision plot l’inclinazione è verso “0”.

Applicazioni dei valori SHAP
Oltre all’interpretabilità e alla spiegabilità dei modelli di machine learning, i valori SHAP possono essere usati per:
- Debug del modello. Esaminando i valori SHAP, possiamo individuare eventuali bias o outlier nei dati che potrebbero indurre il modello a commettere errori.
- Importanza delle caratteristiche. Identificare e rimuovere caratteristiche a basso impatto può portare a un modello più ottimizzato.
- Spiegazioni ancorate. Possiamo usare i valori SHAP per spiegare singole previsioni evidenziando le caratteristiche essenziali che le hanno determinate. Può aiutare gli utenti a capire e fidarsi delle decisioni di un modello.
- Riepiloghi del modello. Può fornire un riepilogo globale del modello sotto forma di summary plot dei valori SHAP, offrendo una panoramica delle caratteristiche più importanti sull’intero dataset.
- Rilevazione dei bias. L’analisi dei valori SHAP aiuta a capire se alcune caratteristiche influenzano in modo sproporzionato particolari gruppi. Consente di individuare e ridurre le discriminazioni nel modello.
- Audit di fairness. Può essere utilizzato per valutare la correttezza e le implicazioni etiche di un modello.
- Approvazione regolatoria. I valori SHAP possono aiutare a ottenere l’approvazione normativa spiegando le decisioni del modello.
Conclusione
Abbiamo esplorato i valori SHAP e come possiamo usarli per fornire interpretabilità ai modelli di machine learning. Sebbene avere un modello accurato sia essenziale, le aziende devono andare oltre l’accuratezza e concentrarsi su interpretabilità e trasparenza per guadagnare la fiducia di utenti e regolatori.
Saper spiegare perché un modello ha fatto una certa previsione aiuta a fare debug di potenziali bias, individuare problemi nei dati e giustificare le decisioni del modello.
Se sei alle prime armi con il machine learning e vuoi essere pronto per il lavoro, valuta il career track Machine Learning Scientist with Python. Questo programma ti aiuterà a padroneggiare le competenze Python necessarie per diventare un machine learning scientist e trovare lavoro.


