Bu eğitimdeki kodu çevrimiçi olarak çalıştırın ve düzenleyin
Kodu çalıştırKurulum
SHAP'i PyPI veya conda-forge kullanarak yükleyin:
pip install shapveya
conda install -c conda-forge shapTelecom Customer Churn verisini yükleyin. Veri kümesi temiz görünüyor ve hedef sütun “Churn”.
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()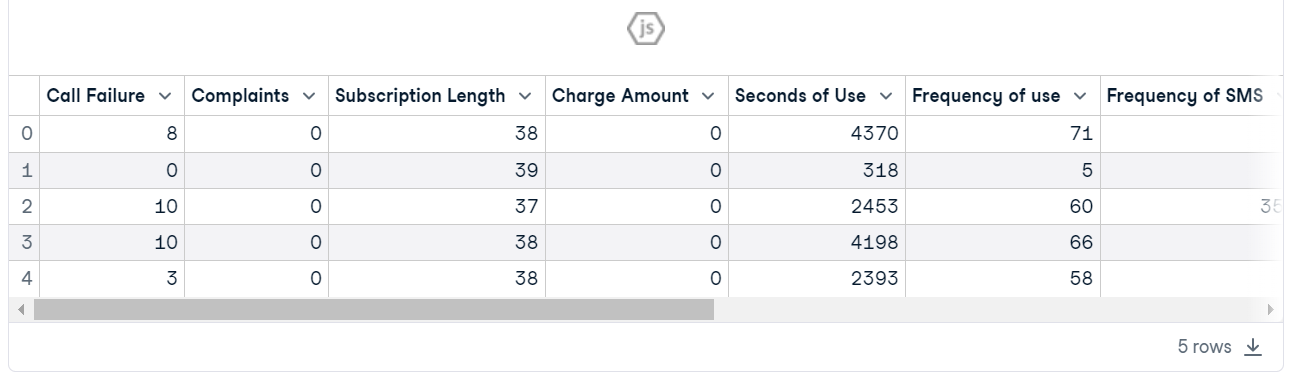
Model Eğitimi ve Değerlendirme
- Hedef sütunu kullanarak X ve y oluşturun ve veri kümesini eğitim ve test olarak ayırın.
- Eğitim setinde Random Forest Classifier eğitin.
- Test setini kullanarak tahmin yapın.
- Sınıflandırma raporunu görüntüleyin.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Model, dengesiz veri kümesi nedeniyle “0” etiketi için “1” etiketinden daha iyi performans gösterdi. Genel olarak, yüzde 94 doğrulukla kabul edilebilir bir sonuçtur.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Python örnekleriyle makine öğreniminde sınıflandırmayı öğrenmek için Makine Öğreniminde Sınıflandırma rehberimize göz atın.
SHAP Açıklayıcısını Kurma
Şimdi model açıklayıcı kısmına geliyoruz.
Önce bir rastgele orman sınıflandırma modeli sağlayarak bir açıklayıcı nesnesi oluşturacağız, ardından test setini kullanarak SHAP değerini hesaplayacağız.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Özet Grafiği
SHAP değerlerini ve test setini kullanarak summary_plot'u görüntüleyin.
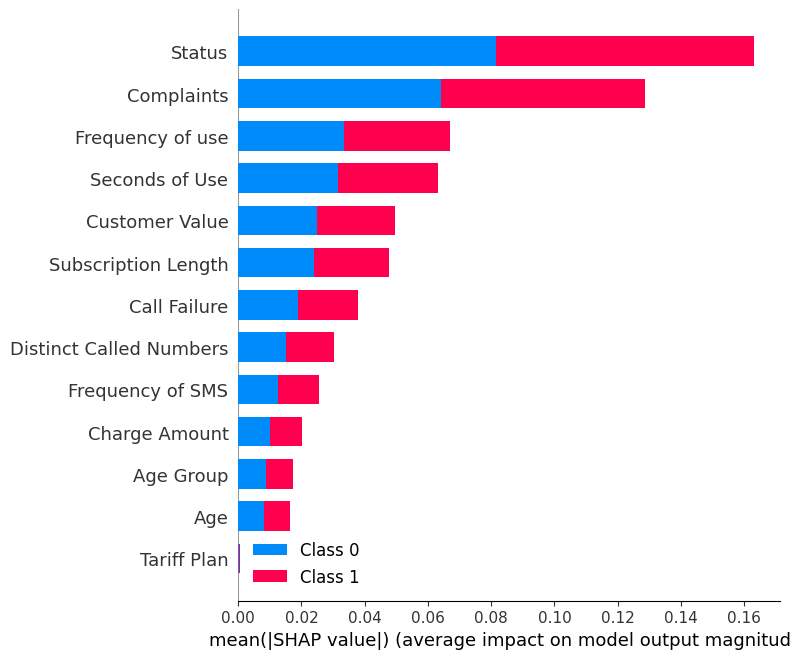
shap.summary_plot(shap_values, X_test)Özet grafiği, modeldeki her bir özelliğin önemini gösterir. Sonuçlar “Status”, “Complaints” ve “Frequency of use” özelliklerinin sonuçların belirlenmesinde başlıca rol oynadığını gösteriyor.
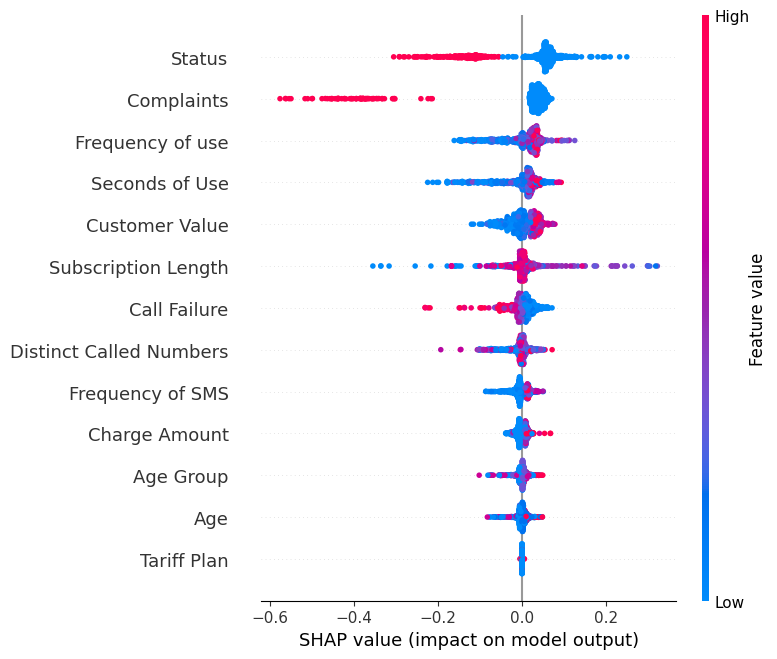
“0” etiketi için summary_plot'u görüntüleyin.
shap.summary_plot(shap_values[0], X_test)- Y ekseni, özellik adlarını önem sırasına göre yukarıdan aşağıya gösterir.
- X ekseni, log olasılıklardaki değişim derecesini gösteren SHAP değerini temsil eder.
- Grafikteki her bir noktanın rengi, karşılık gelen özelliğin değerini temsil eder; kırmızı yüksek değerleri, mavi düşük değerleri gösterir.
- Her bir nokta, orijinal veri kümesindeki bir veri satırını temsil eder.
“Complaints” özelliğine bakarsanız, çoğunlukla negatif SHAP değeriyle yüksek olduğunu görürsünüz. Bu da daha yüksek şikayet sayılarının çıktıyı olumsuz etkileme eğiliminde olduğunu gösterir.
Not: “1” etiketi için görselleştirme tersine çevrilecektir.
Bağımlılık Grafiği
“Subscription Length” ve “Age” özellikleri arasındaki dependence_plot'u görselleştirin.
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Bağımlılık grafiği, modelin tahminlerinin belirli bir özelliğe (Subscription Length) göre nasıl etkilendiğini gösteren bir dağılım grafiği türüdür. Ortalama olarak, abonelik sürelerinin model üzerinde çoğunlukla olumlu bir etkisi vardır.
Kuvvet Grafiği
Test setindeki ilk örneği inceleyerek hangi özelliklerin "0" sonucuna katkıda bulunduğunu belirleyeceğiz. Bunu yapmak için bir kuvvet grafiği kullanacak ve beklenen değeri, SHAP değerini ve test örneğini sağlayacağız.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Sıfır şikayet ve sıfır çağrı hatasının müşteri kaybının olmamasına olumsuz yönde katkıda bulunduğunu açıkça görebiliyoruz.
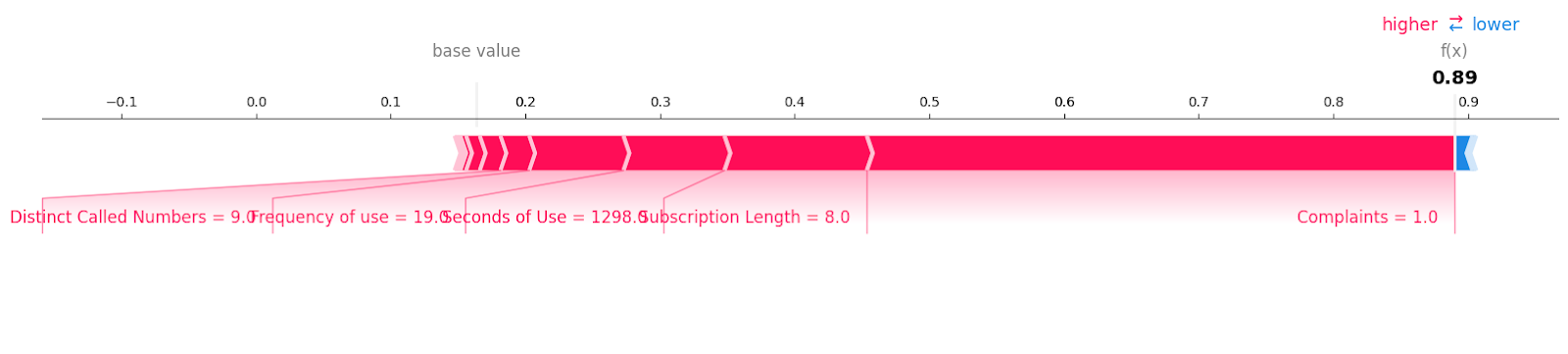
Şimdi “1” etiketli müşteri kaybı örneklerine bakalım.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Müşteri kaybına katkıda bulunan tüm özellikleri, değerleri ve büyüklükleriyle birlikte görebilirsiniz. Görünüşe göre tek bir çözülmemiş şikayet bile bir telekom şirketine müşteri kaybettirebilir.
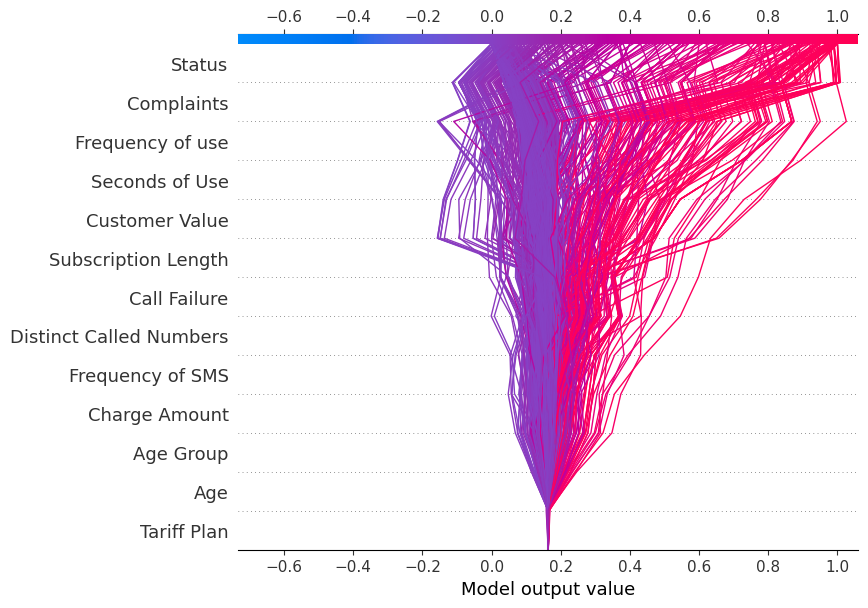
Karar Grafiği
Şimdi decision_plot'u görüntüleyeceğiz. Bu grafik, her tahmin için kümülatif SHAP değerlerini eşleyerek model kararlarını görsel olarak gösterir.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Karar grafiğindeki her çizgi, tek bir model tahminine bireysel özelliklerin ne kadar güçlü katkıda bulunduğunu gösterir; böylece hangi özellik değerlerinin tahmini ittiğini açıklar.
Not: Hedef etiket “1” için karar grafiği “1” yönüne eğimlidir.
Hedef etiket “0” için karar grafiğini görüntüleyin
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Bu karar grafiği ise “0” yönüne eğimlidir.

SHAP Değerlerinin Uygulamaları
Makine öğreniminde yorumlanabilirlik ve açıklanabilirliğin yanı sıra, SHAP değeri şu amaçlarla da kullanılabilir:
- Model hata ayıklama. SHAP değerlerini inceleyerek, modelin hata yapmasına neden olabilecek veri önyargılarını veya aykırı değerleri belirleyebiliriz.
- Özellik önemi. Düşük etkili özelliklerin belirlenip kaldırılması daha optimize bir model oluşturabilir.
- Öngörü açıklamaları. SHAP değerlerini, belirli bir tahmine neden olan temel özellikleri vurgulayarak tekil tahminleri açıklamak için kullanabiliriz. Bu, kullanıcıların bir modelin kararlarını anlamasına ve güvenmesine yardımcı olabilir.
- Model özetleri. SHAP değeri özet grafiği biçiminde bir modelin küresel özetini sağlayabilir. Tüm veri kümesi genelinde en önemli özelliklere genel bir bakış sunar.
- Önyargı tespiti. SHAP değeri analizi, belirli özelliklerin bazı grupları orantısız biçimde etkileyip etkilemediğini belirlemeye yardımcı olur. Modeldeki ayrımcılığın tespit edilmesini ve azaltılmasını sağlar.
- Adalet denetimi. Bir modelin adilliğini ve etik etkilerini değerlendirmek için kullanılabilir.
- Düzenleyici onay. SHAP değerleri, modelin kararlarını açıklayarak düzenleyici onay alınmasına yardımcı olabilir.
Sonuç
SHAP değerlerini ve bunları makine öğrenimi modellerine yorumlanabilirlik kazandırmak için nasıl kullanabileceğimizi inceledik. Doğru bir modele sahip olmak önemli olmakla birlikte, şirketlerin kullanıcıların ve düzenleyicilerin güvenini kazanmak için doğruluğun ötesine geçip yorumlanabilirlik ve şeffaflığa odaklanması gerekir.
Bir modelin neden belirli bir tahmini yaptığını açıklayabilmek, olası önyargıların hata ayıklanmasına, veri sorunlarının belirlenmesine ve modelin kararlarının gerekçelendirilmesine yardımcı olur.
Makine öğrenimine yeni başlıyorsanız ve işe hazır hale gelmek istiyorsanız, Machine Learning Scientist with Python kariyer yolunu değerlendirin. Bu program, makine öğrenimi bilim insanı olmak ve iş bulmak için gerekli Python becerilerinde ustalaşmanıza yardımcı olacaktır.

