Vous souhaitez vous lancer dans l'IA générative ?
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeMise en place
Installez SHAP en utilisant PyPI ou conda-forge:
pip install shapou
conda install -c conda-forge shapCharger le taux d'attrition des clients des télécommunications. L'ensemble de données semble propre et la colonne cible est "Churn".
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()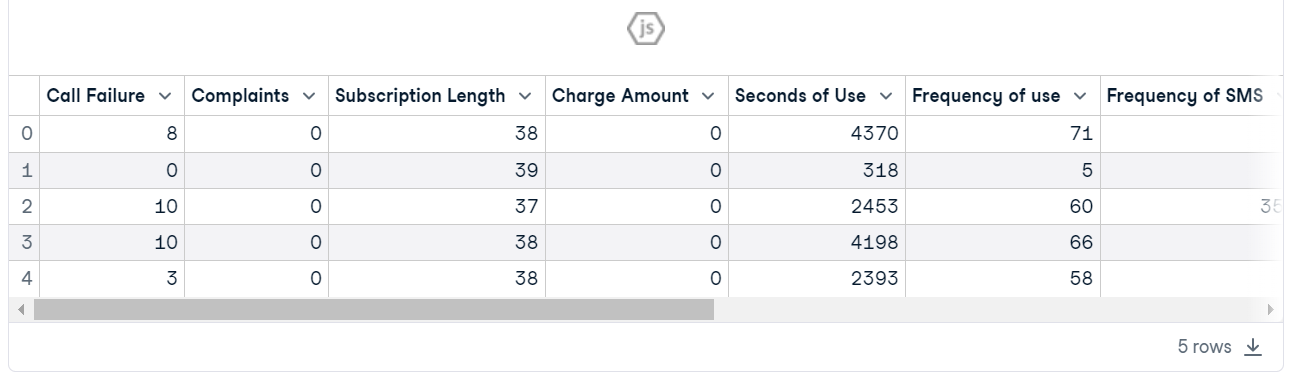
Formation et évaluation du modèle
- Créez X et y à l'aide d'une colonne cible et divisez l'ensemble de données en train et test.
- Entraînez le classificateur Random Forest sur l'ensemble d'apprentissage.
- Faites des prédictions à l'aide d'un ensemble de tests.
- Affichez le rapport de classification.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Le modèle s'est avéré plus performant pour l'étiquette "0" que pour l'étiquette "1" en raison d'un ensemble de données déséquilibré. Dans l'ensemble, il s'agit d'un résultat acceptable, avec une précision de 94 %.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Consultez notre guide Classification dans l'apprentissage automatique pour en savoir plus sur la classification dans l'apprentissage automatique avec des exemples Python.
Mise en place de SHAP Explainer
Voici maintenant l'explication du modèle.
Nous allons d'abord créer un objet explicatif en fournissant un modèle de classification par forêt aléatoire, puis calculer la valeur SHAP à l'aide d'un ensemble de tests.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Résumé de l'intrigue
Affichez le site summary_plot en utilisant les valeurs SHAP et le jeu d'essai.
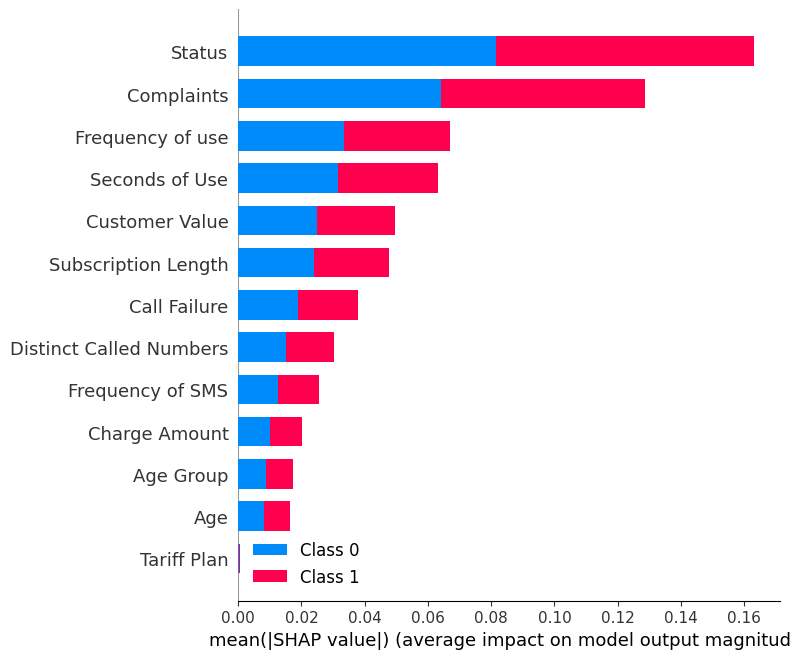
shap.summary_plot(shap_values, X_test)Le graphique récapitulatif montre l'importance de chaque caractéristique dans le modèle. Les résultats montrent que le "statut", les "plaintes" et la "fréquence d'utilisation" jouent un rôle majeur dans la détermination des résultats.
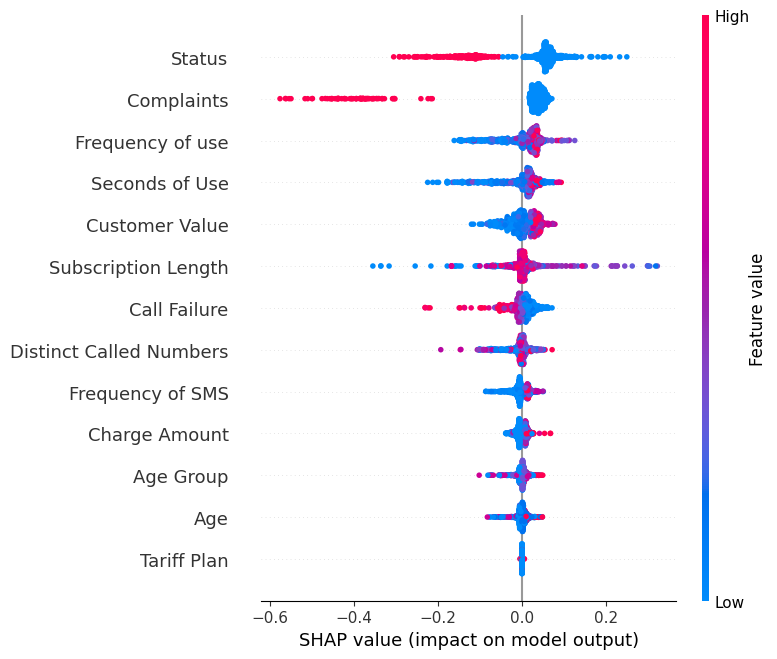
Affichez le site summary_plot de l'étiquette "0".
shap.summary_plot(shap_values[0], X_test)- L'axe des ordonnées indique les noms des caractéristiques par ordre d'importance, de haut en bas.
- L'axe X représente la valeur SHAP, qui indique le degré de changement dans le logarithme des cotes.
- La couleur de chaque point du graphique représente la valeur de l'élément correspondant, le rouge indiquant les valeurs élevées et le bleu les valeurs faibles.
- Chaque point représente une ligne de données de l'ensemble de données original.
Si vous examinez la caractéristique "Plaintes", vous verrez qu'elle est principalement élevée avec une valeur SHAP négative. Cela signifie qu'un nombre élevé de plaintes a tendance à avoir un effet négatif sur la production.
Remarque: pour l'étiquette "1", la visualisation sera inversée.
Graphique de dépendance
Visualisez le site dependence_plot entre la caractéristique "Durée de l'abonnement" et "Âge".
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Un diagramme de dépendance est un type de diagramme de dispersion qui montre comment les prédictions d'un modèle sont affectées par une caractéristique spécifique (Longueur d'abonnement). En moyenne, les durées d'abonnement ont un effet positif sur le modèle.
Tracé des forces
Nous examinerons le premier échantillon de l'ensemble de tests afin de déterminer les caractéristiques qui ont contribué au résultat "0". Pour ce faire, nous utiliserons un diagramme de force et fournirons la valeur attendue, la valeur SHAP et l'échantillon d'essai.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Nous pouvons clairement voir que l'absence de plaintes et d'échecs d'appels a contribué à une perte négative de clients.
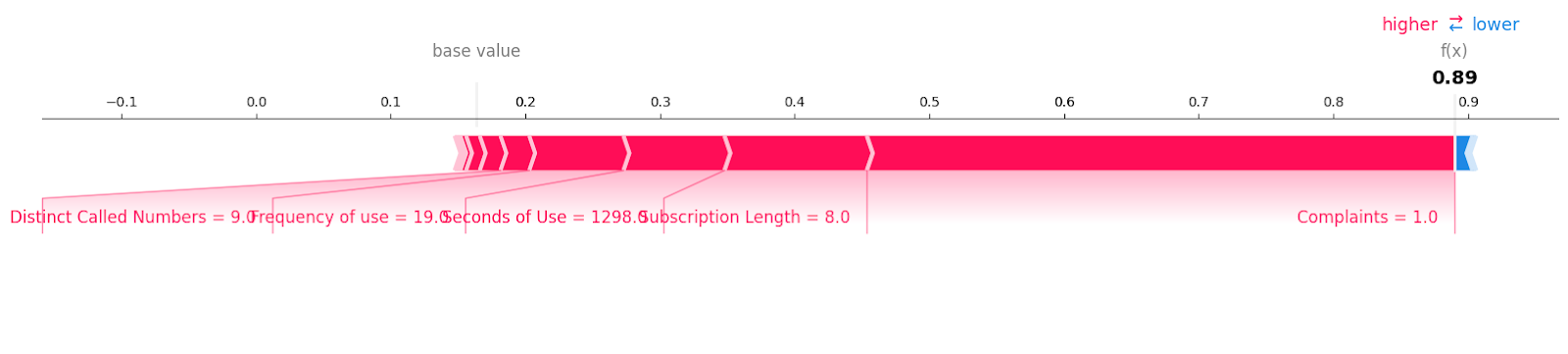
Examinons les échantillons de désabonnement avec l'étiquette "1".
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Vous pouvez voir toutes les caractéristiques avec la valeur et l'ampleur qui ont contribué à une perte de clients. Il semble qu'une seule plainte non résolue puisse coûter cher à une entreprise de télécommunications.
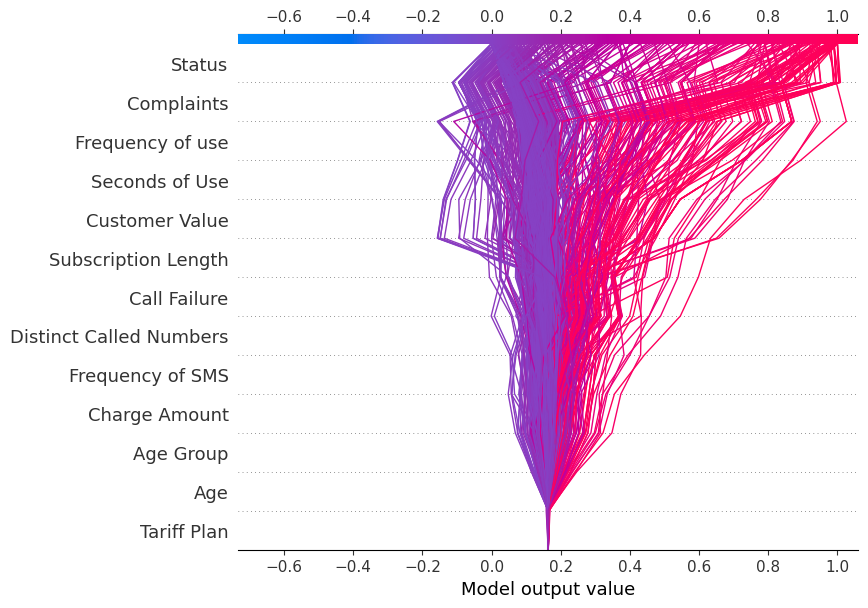
Graphique de décision
Nous allons maintenant afficher le site decision_plot. Il représente visuellement les décisions du modèle en cartographiant les valeurs SHAP cumulées pour chaque prédiction.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Chaque ligne tracée sur le diagramme de décision indique l'importance de la contribution des caractéristiques individuelles à la prédiction d'un modèle unique, expliquant ainsi quelles valeurs de caractéristiques ont poussé à la prédiction.
Note: Le diagramme de décision de l'étiquette cible "1" est incliné vers "1".
Affichez le diagramme de décision pour l'étiquette cible "0".
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Car le diagramme de décision est incliné vers "0".

Application des valeurs SHAP
Outre l'interprétabilité et l'explicabilité de l'apprentissage automatique, la valeur SHAP peut être utilisée pour :
- Débogage du modèle. En examinant les valeurs SHAP, nous pouvons identifier les biais ou les valeurs aberrantes dans les données qui peuvent entraîner des erreurs dans le modèle.
- Importance de la fonctionnalité. L'identification et la suppression des éléments à faible impact permettent de créer un modèle plus optimisé.
- Explications sur l'ancrage. Nous pouvons utiliser les valeurs SHAP pour expliquer les prédictions individuelles en mettant en évidence les caractéristiques essentielles à l'origine de cette prédiction. Elle peut aider les utilisateurs à comprendre les décisions d'un modèle et à s'y fier.
- Résumés des modèles. Il peut fournir un résumé global d'un modèle sous la forme d'un graphique récapitulatif des valeurs SHAP. Il donne un aperçu des caractéristiques les plus importantes de l'ensemble des données.
- Détecter les biais. L'analyse de la valeur du SHAP permet d'identifier si certaines caractéristiques affectent de manière disproportionnée des groupes particuliers. Il permet de détecter et de réduire la discrimination dans le modèle.
- L'audit d'équité. Il peut être utilisé pour évaluer l'équité et les implications éthiques d'un modèle.
- Approbation réglementaire. Les valeurs SHAP peuvent aider à obtenir l'approbation réglementaire en expliquant les décisions du modèle.
Conclusion
Nous avons étudié les valeurs SHAP et la manière dont nous pouvons les utiliser pour fournir une interprétabilité aux modèles d'apprentissage automatique. S'il est essentiel de disposer d'un modèle précis, les entreprises doivent aller au-delà de la précision et se concentrer sur l'interprétabilité et la transparence pour gagner la confiance des utilisateurs et des régulateurs.
Pouvoir expliquer pourquoi un modèle a fait une prédiction particulière permet de débusquer les biais potentiels, d'identifier les problèmes de données et de justifier les décisions du modèle.
Si vous êtes novice en matière d'apprentissage automatique et que vous cherchez à vous préparer à un emploi, envisagez de suivre le parcours de carrière Machine Learning Scientist with Python (Scientifique en apprentissage automatique avec Python). Ce programme vous aidera à maîtriser les compétences Python nécessaires pour devenir un scientifique spécialisé dans l'apprentissage automatique et décrocher un emploi.


