Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãThiết lập
Cài đặt SHAP bằng PyPI hoặc conda-forge:
pip install shaphoặc
conda install -c conda-forge shapTải Telecom Customer Churn. Tập dữ liệu trông khá sạch và cột đích là “Churn”.
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()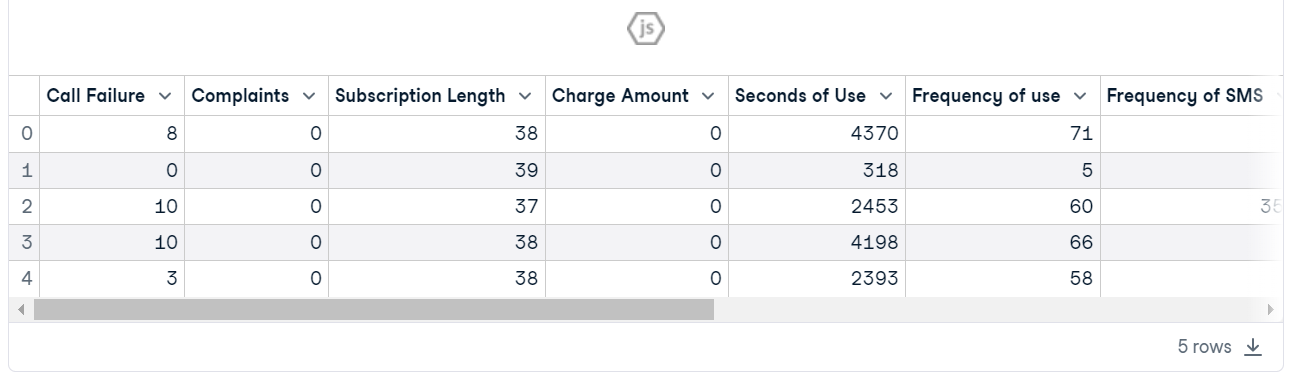
Huấn luyện và đánh giá mô hình
- Tạo X và y sử dụng cột đích và chia tập dữ liệu thành train và test.
- Huấn luyện Random Forest Classifier trên tập huấn luyện.
- Thực hiện dự đoán bằng tập kiểm tra.
- Hiển thị báo cáo phân loại.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Mô hình thể hiện tốt hơn với nhãn “0” so với “1” do tập dữ liệu mất cân bằng. Nhìn chung, đây là kết quả chấp nhận được với độ chính xác 94%.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Xem hướng dẫn Phân loại trong Học máy để tìm hiểu về phân loại trong học máy với các ví dụ Python.
Thiết lập SHAP Explainer
Bây giờ đến phần giải thích mô hình.
Trước tiên, chúng ta sẽ tạo một đối tượng explainer bằng cách cung cấp mô hình phân loại rừng ngẫu nhiên, sau đó tính giá trị SHAP bằng tập kiểm tra.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Biểu đồ tổng quan (Summary Plot)
Hiển thị summary_plot sử dụng giá trị SHAP và tập kiểm tra.
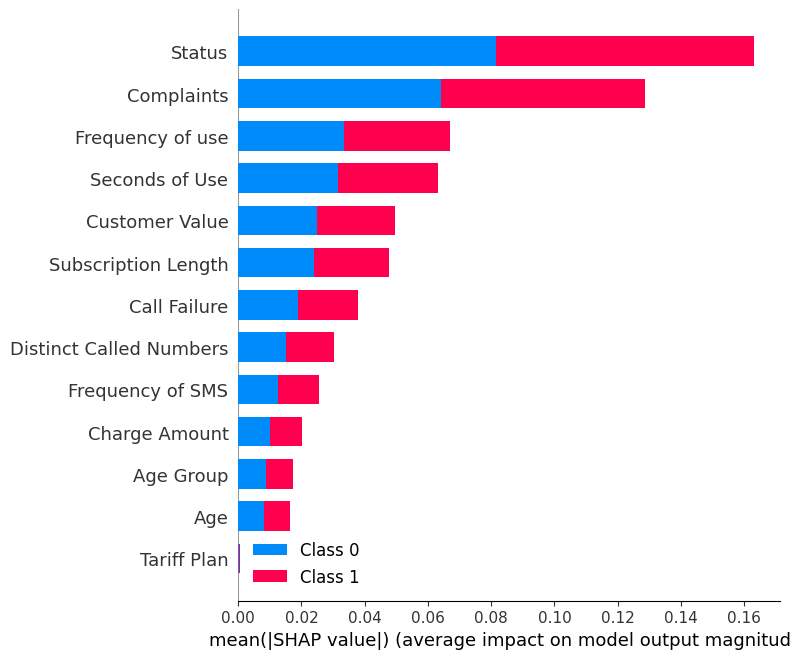
shap.summary_plot(shap_values, X_test)Biểu đồ tổng quan cho thấy tầm quan trọng của từng đặc trưng trong mô hình. Kết quả cho thấy “Status”, “Complaints” và “Frequency of use” đóng vai trò chính trong việc quyết định kết quả.
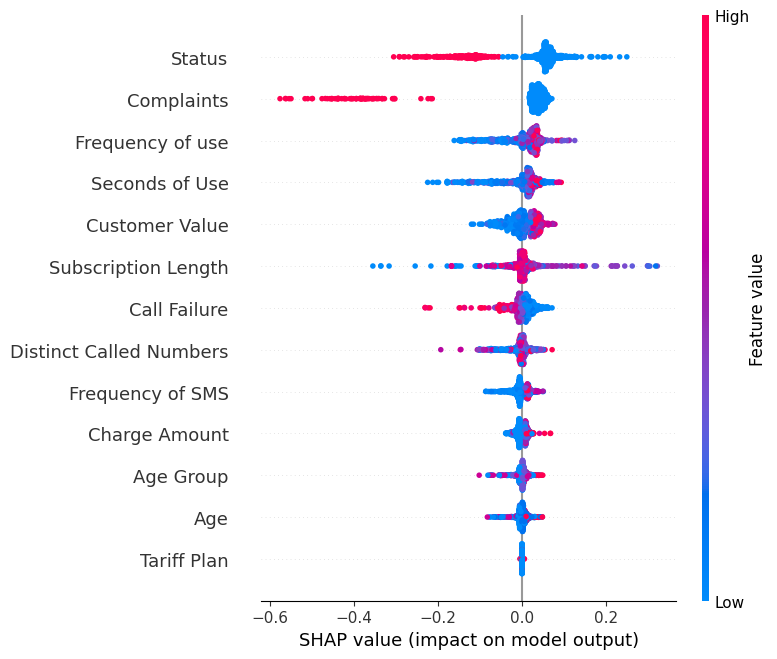
Hiển thị summary_plot của nhãn “0”.
shap.summary_plot(shap_values[0], X_test)- Trục Y hiển thị tên các đặc trưng theo thứ tự tầm quan trọng từ trên xuống.
- Trục X biểu diễn giá trị SHAP, cho biết mức độ thay đổi trong log-odds.
- Màu sắc của mỗi điểm trên biểu đồ biểu thị giá trị của đặc trưng tương ứng, đỏ là giá trị cao và xanh là giá trị thấp.
- Mỗi điểm đại diện cho một dòng dữ liệu từ tập dữ liệu gốc.
Nếu bạn nhìn vào đặc trưng “Complaints”, bạn sẽ thấy phần lớn có giá trị cao cùng giá trị SHAP âm. Điều này nghĩa là số lượng khiếu nại cao hơn có xu hướng ảnh hưởng tiêu cực đến đầu ra.
Lưu ý: với nhãn “1” trực quan hóa sẽ đảo chiều.
Biểu đồ phụ thuộc (Dependence Plot)
Trực quan hóa dependence_plot giữa đặc trưng “Subscription Length” và “Age”.
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Biểu đồ phụ thuộc là dạng biểu đồ phân tán thể hiện dự đoán của mô hình bị ảnh hưởng bởi một đặc trưng cụ thể (Subscription Length) như thế nào. Trung bình, thời hạn thuê bao có tác động chủ yếu là tích cực lên mô hình.
Biểu đồ lực (Force Plot)
Chúng ta sẽ xem xét mẫu đầu tiên trong tập kiểm tra để xác định những đặc trưng nào góp phần dẫn đến kết quả "0". Để làm điều này, chúng ta sẽ sử dụng biểu đồ lực và cung cấp giá trị kỳ vọng, giá trị SHAP và mẫu kiểm tra.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Chúng ta có thể thấy rõ rằng số khiếu nại bằng 0 và số lần gọi thất bại bằng 0 đã góp phần làm giảm khả năng mất khách hàng.
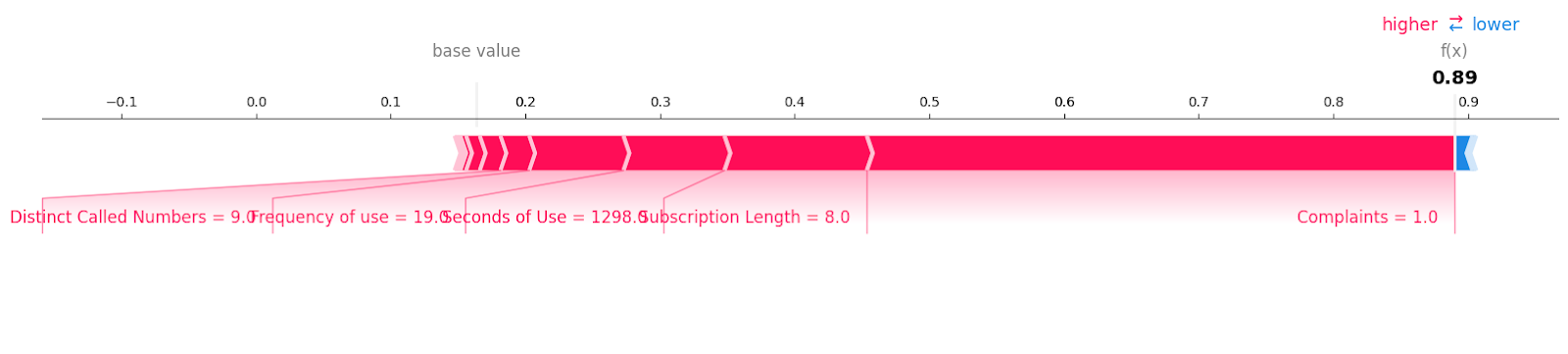
Hãy xem các mẫu rời bỏ khách hàng với nhãn “1”.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Bạn có thể thấy tất cả các đặc trưng với giá trị và độ lớn đã góp phần vào việc mất khách hàng. Có vẻ như chỉ một khiếu nại chưa được giải quyết cũng có thể khiến công ty viễn thông tổn thất.
Biểu đồ quyết định (Decision Plot)
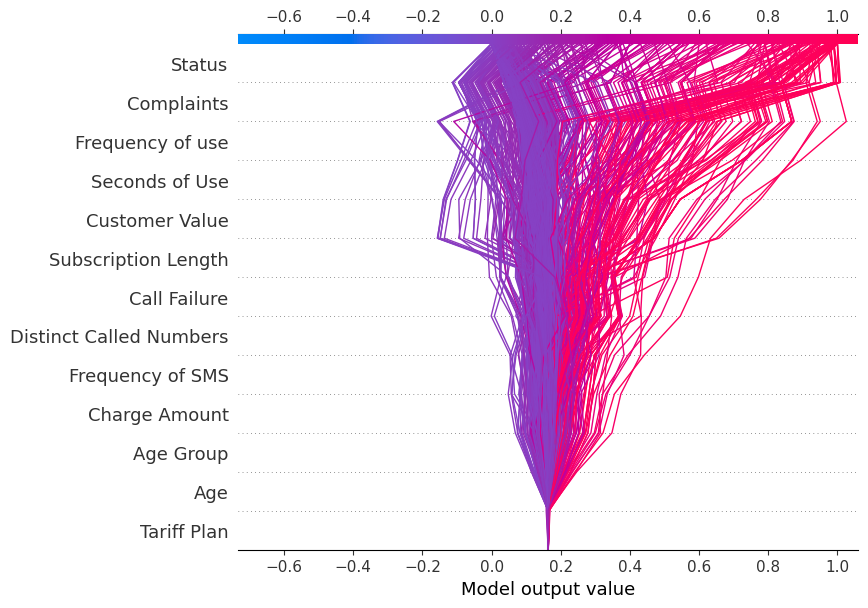
Bây giờ chúng ta sẽ hiển thị decision_plot. Nó mô tả trực quan các quyết định của mô hình bằng cách ánh xạ các giá trị SHAP tích lũy cho mỗi dự đoán.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Mỗi đường vẽ trên biểu đồ quyết định cho thấy các đặc trưng riêng lẻ đã đóng góp mạnh mẽ như thế nào vào một dự đoán cụ thể của mô hình, qua đó giải thích những giá trị đặc trưng nào đã đẩy dự đoán theo hướng đó.
Lưu ý: Biểu đồ quyết định của nhãn đích “1” nghiêng về phía “1”.
Hiển thị biểu đồ quyết định cho nhãn đích “0”
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Đối với biểu đồ quyết định này, nó nghiêng về phía “0”.

Ứng dụng của giá trị SHAP
Ngoài khả năng diễn giải và giải thích trong học máy, giá trị SHAP còn có thể được dùng cho:
- Gỡ lỗi mô hình. Bằng cách xem xét giá trị SHAP, chúng ta có thể xác định bất kỳ thiên lệch hoặc ngoại lệ nào trong dữ liệu có thể khiến mô hình mắc lỗi.
- Tầm quan trọng đặc trưng. Xác định và loại bỏ các đặc trưng có tác động thấp có thể tạo ra mô hình tối ưu hơn.
- Giải thích theo điểm tựa. Chúng ta có thể dùng giá trị SHAP để giải thích các dự đoán cá nhân bằng cách làm nổi bật những đặc trưng then chốt dẫn đến dự đoán đó. Điều này giúp người dùng hiểu và tin tưởng các quyết định của mô hình.
- Tóm tắt mô hình. Có thể cung cấp bản tóm tắt tổng quát của mô hình dưới dạng biểu đồ tổng quan giá trị SHAP, cho cái nhìn tổng thể về các đặc trưng quan trọng nhất trên toàn bộ tập dữ liệu.
- Phát hiện thiên lệch. Phân tích giá trị SHAP giúp xác định liệu một số đặc trưng có ảnh hưởng không tương xứng đến các nhóm cụ thể hay không. Nó cho phép phát hiện và giảm thiểu sự phân biệt trong mô hình.
- Kiểm toán công bằng. Có thể dùng để đánh giá mức độ công bằng và các hàm ý đạo đức của mô hình.
- Phê duyệt theo quy định. Giá trị SHAP có thể giúp đạt được sự chấp thuận của cơ quan quản lý bằng cách giải thích các quyết định của mô hình.
Kết luận
Chúng ta đã khám phá giá trị SHAP và cách sử dụng chúng để mang lại khả năng diễn giải cho các mô hình học máy. Mặc dù độ chính xác là quan trọng, các công ty cần vượt ra ngoài độ chính xác và tập trung vào khả năng diễn giải và minh bạch để giành được niềm tin của người dùng và cơ quan quản lý.
Khả năng giải thích vì sao mô hình đưa ra một dự đoán cụ thể giúp gỡ lỗi các thiên lệch tiềm ẩn, xác định vấn đề dữ liệu và biện minh cho các quyết định của mô hình.
Nếu bạn mới bắt đầu với học máy và muốn sẵn sàng cho công việc, hãy cân nhắc theo học lộ trình nghề nghiệp Machine Learning Scientist with Python. Chương trình này sẽ giúp bạn nắm vững các kỹ năng Python cần thiết để trở thành một nhà khoa học học máy và tìm được việc làm.
