Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenAan de slag
Installeer SHAP via PyPI of conda-forge:
pip install shapof
conda install -c conda-forge shapLaad de Telecom Customer Churn. De dataset ziet er schoon uit en de doelkolom is “Churn”.
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()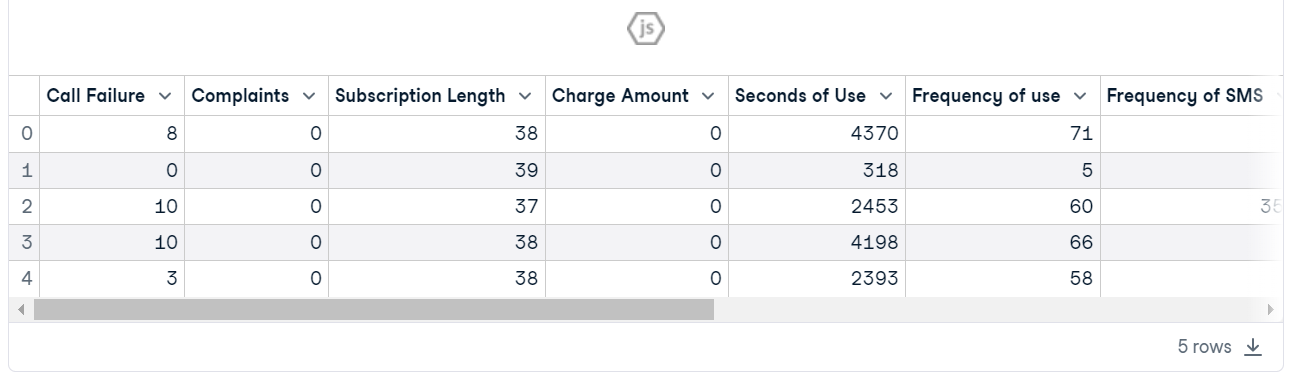
Modeltraining en evaluatie
- Maak X en y met behulp van de doelkolom en splits de dataset in train en test.
- Train een Random Forest Classifier op de trainingsset.
- Maak voorspellingen met de testset.
- Toon het classificatierapport.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Het model presteert beter voor label “0” dan voor “1” vanwege een onevenwichtige dataset. Al met al is het een acceptabel resultaat met 94% nauwkeurigheid.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Bekijk ook onze gids Classificatie in machine learning om meer te leren over classificatie in machine learning met Python-voorbeelden.
SHAP Explainer instellen
Nu komt het deel van de modeluitlegger.
We maken eerst een explainer-object door een randomforest-classificatiemodel aan te leveren, en berekenen daarna de SHAP-waarde met behulp van de testset.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Summary-plot
Toon de summary_plot met SHAP-waarden en de testset.
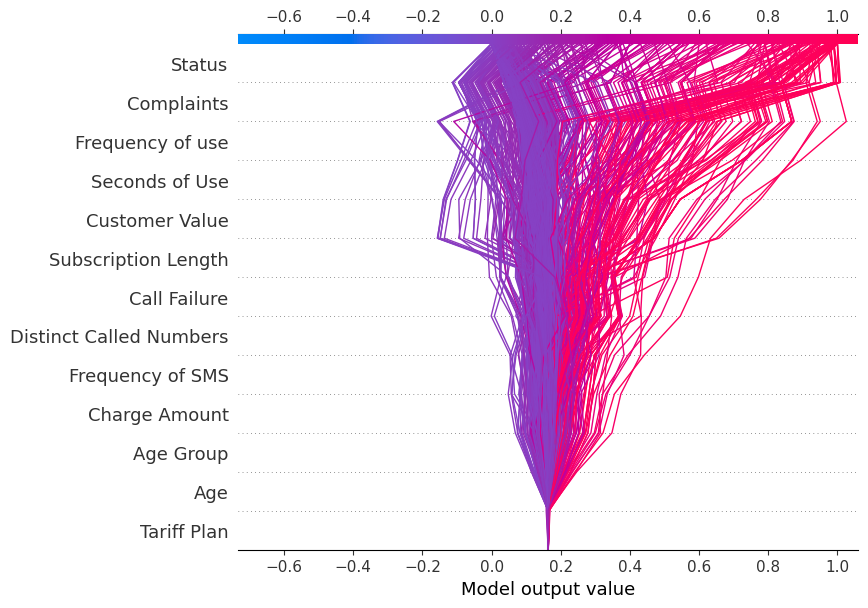
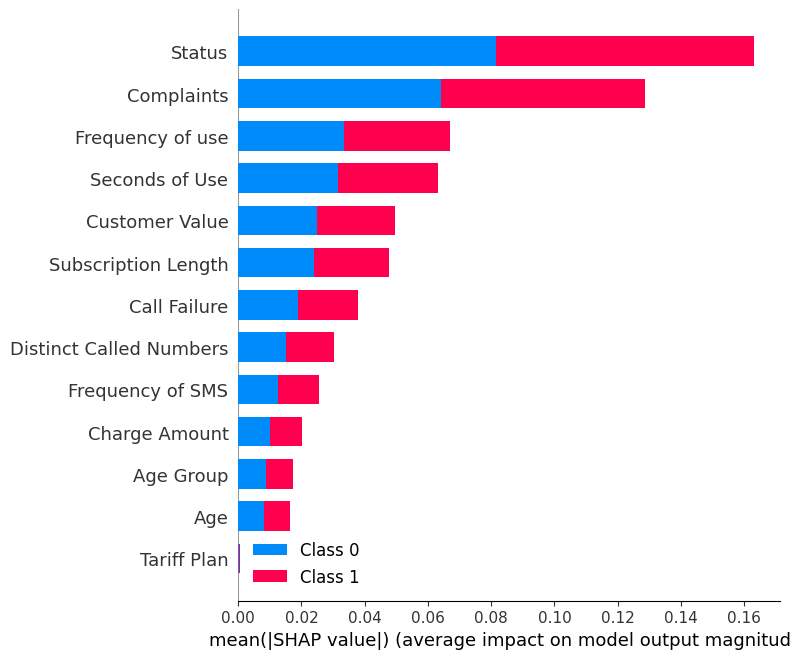
shap.summary_plot(shap_values, X_test)De summary-plot laat de feature-importance van elk kenmerk in het model zien. De resultaten tonen dat “Status”, “Complaints” en “Frequency of use” een grote rol spelen bij het bepalen van de uitkomsten.
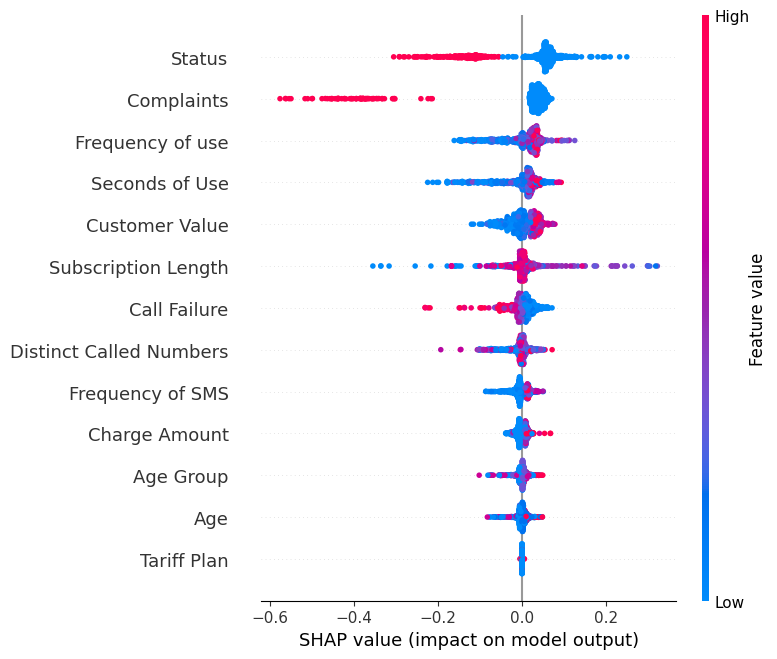
Toon de summary_plot van het label “0”.
shap.summary_plot(shap_values[0], X_test)- Y-as geeft de featurenamen aan in volgorde van belangrijkheid van boven naar beneden.
- X-as stelt de SHAP-waarde voor, die de mate van verandering in log odds aangeeft.
- De kleur van elk punt in de grafiek geeft de waarde van de corresponderende feature weer, waarbij rood hoge waarden en blauw lage waarden aangeeft.
- Elk punt vertegenwoordigt een rij data uit de oorspronkelijke dataset.
Als je naar de feature “Complaints" kijkt, zie je dat die meestal hoog is met een negatieve SHAP-waarde. Dat betekent dat hogere aantallen klachten de output negatief beïnvloeden.
Let op: voor label “1” wordt de visualisatie gespiegeld.
Dependence-plot
Visualiseer de dependence_plot tussen de features “Subscription Length” en “Age”.
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Een dependence-plot is een soort spreidingsdiagram dat laat zien hoe de voorspellingen van een model worden beïnvloed door een specifieke feature (Subscription Length). Gemiddeld genomen heeft de abonnementsduur een overwegend positief effect op het model.
Force-plot
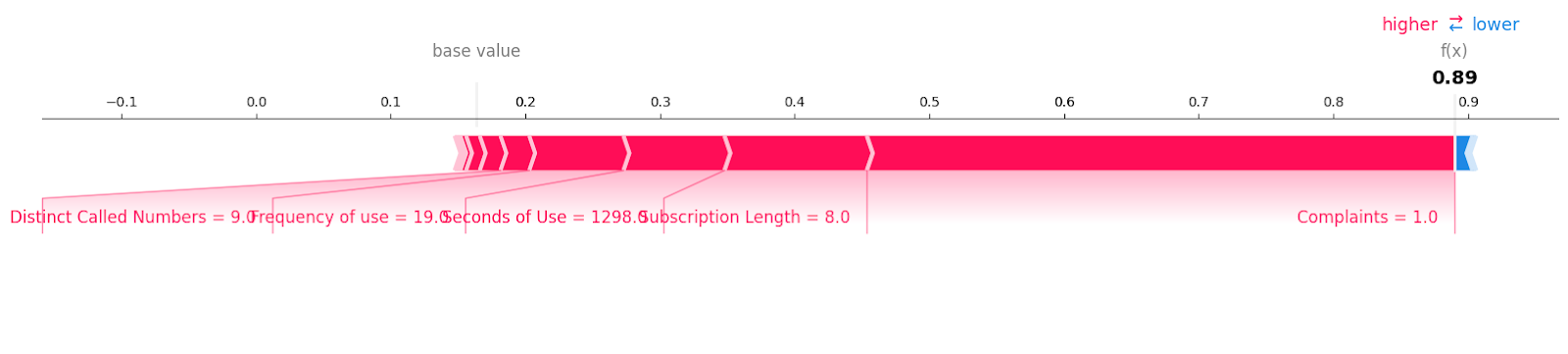
We bekijken de eerste sample in de testset om te bepalen welke features hebben bijgedragen aan het resultaat “0”. Hiervoor gebruiken we een force-plot en geven we de expected value, de SHAP-waarde en de testsample mee.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)We zien duidelijk dat nul klachten en nul storingen bijdroegen aan een negatief effect op klantverlies.
Laten we nu kijken naar churn-samples met label “1”.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Je ziet alle features met hun waarde en grootte die hebben bijgedragen aan klantverlies. Het lijkt erop dat zelfs één onopgeloste klacht een telecombedrijf kan kosten.
Decision-plot
We tonen nu de
decision_plot. Deze beeldt de modelbeslissingen visueel af door de cumulatieve SHAP-waarden voor elke voorspelling te plotten.shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Elke getekende lijn in de decision-plot laat zien hoe sterk de individuele features hebben bijgedragen aan een enkele modelvoorspelling, en verklaart zo welke featurewaarden de voorspelling hebben gestuurd.
Let op: de decision-plot voor doellabel “1” helt richting “1”.
Toon de decision-plot voor doellabel “0”
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Hier helt de decision-plot richting “0”.
Toepassingen van SHAP-waarden
Naast verklaarbaarheid en uitlegbaarheid in machine learning kun je SHAP-waarden gebruiken voor:
- Modeldebugging. Door de SHAP-waarden te onderzoeken, kunnen we vooroordelen of uitschieters in de data identificeren die het model fouten laten maken.
- Feature-importance. Het identificeren en verwijderen van kenmerken met geringe impact kan een meer geoptimaliseerd model opleveren.
- Uitleg verankeren. We kunnen SHAP-waarden gebruiken om individuele voorspellingen uit te leggen door de essentiële kenmerken te benadrukken die tot die voorspelling hebben geleid. Dat helpt gebruikers de beslissingen van een model te begrijpen en te vertrouwen.
- Modelsamenvattingen. Ze kunnen een globale samenvatting van een model geven in de vorm van een SHAP summary-plot. Dat biedt een overzicht van de belangrijkste kenmerken over de hele dataset.
- Bias detecteren. Analyse van SHAP-waarden helpt te identificeren of bepaalde kenmerken bepaalde groepen onevenredig beïnvloeden. Het maakt het mogelijk om discriminatie in het model op te sporen en te verkleinen.
- Fairness-audits. Ze kunnen worden gebruikt om de eerlijkheid en ethische implicaties van een model te beoordelen.
- Regelgevende goedkeuring. SHAP-waarden kunnen helpen om goedkeuring van toezichthouders te krijgen door de beslissingen van het model uit te leggen.
Conclusie
We hebben SHAP-waarden verkend en gezien hoe we ze kunnen gebruiken om machinelearningmodellen interpreteerbaar te maken. Hoewel een accuraat model essentieel is, moeten bedrijven verder kijken dan alleen nauwkeurigheid en focussen op uitlegbaarheid en transparantie om het vertrouwen van gebruikers en toezichthouders te winnen.
Kunnen uitleggen waarom een model een bepaalde voorspelling heeft gedaan, helpt mogelijke biases te debuggen, dataproblemen te identificeren en de beslissingen van het model te onderbouwen.
Ben je nieuw in machine learning en wil je job-ready worden? Overweeg dan de carrièreroute Machine Learning Scientist with Python. Dit programma helpt je de benodigde Python-vaardigheden te beheersen om machine learning scientist te worden en een baan te vinden.