Looking to get started with Generative AI?
Learn how to work with LLMs in Python right in your browser

Run and edit the code from this tutorial online
Run codeSetting Up
Install SHAP either using PyPI or conda-forge:
pip install shapor
conda install -c conda-forge shapLoad the Telecom Customer Churn. The dataset looks clean, and the target column is “Churn.”
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()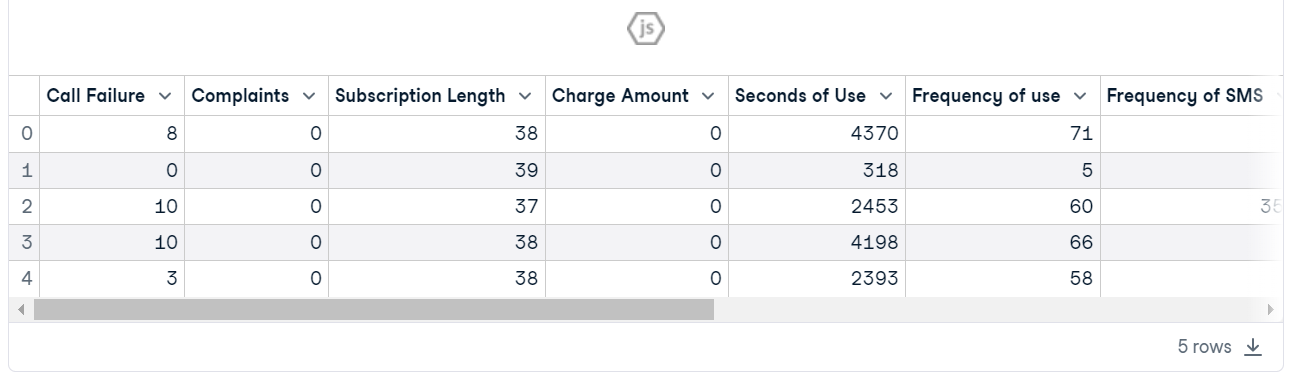
Model Training and Evaluation
- Create X and y using a target column and split the dataset into train and test.
- Train Random Forest Classifier on the training set.
- Make predictions using a testing set.
- Display classification report.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))The model has shown better performance for “0” label than “1” due to an unbalanced dataset. Overall, it is an acceptable result with 94% accuracy.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Check out our Classification in Machine Learning guide to learn about classification in machine learning with Python examples.
Setting up SHAP Explainer
Now comes the model explainer part.
We will first create an explainer object by providing a random forest classification model, then calculate SHAP value using a testing set.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Summary Plot
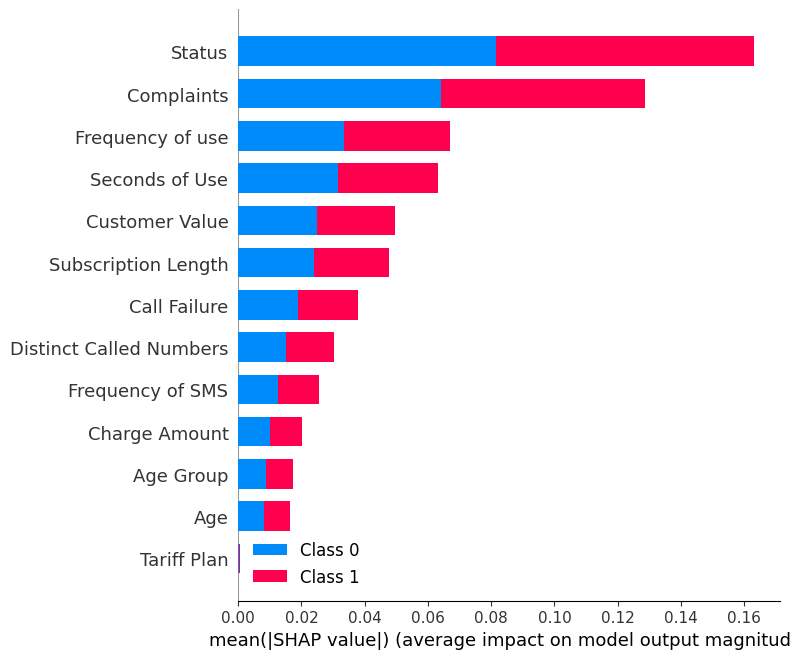
Display the summary_plot using SHAP values and testing set.
shap.summary_plot(shap_values, X_test)The summary plot shows the feature importance of each feature in the model. The results show that “Status,” “Complaints,” and “Frequency of use” play major roles in determining the results.
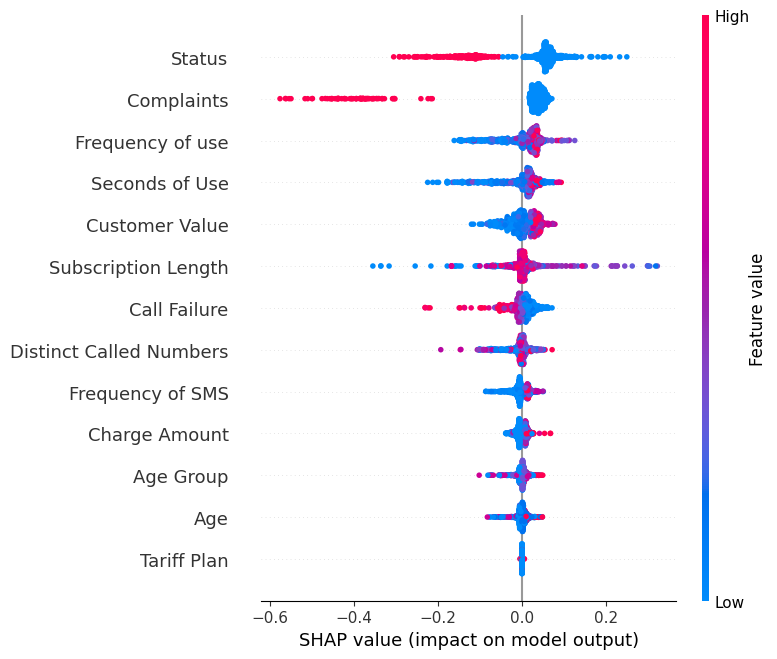
Display the summary_plot of the label “0”.
shap.summary_plot(shap_values[0], X_test)- Y-axis indicates the feature names in order of importance from top to bottom.
- X-axis represents the SHAP value, which indicates the degree of change in log odds.
- The color of each point on the graph represents the value of the corresponding feature, with red indicating high values and blue indicating low values.
- Each point represents a row of data from the original dataset.
If you look at the feature “Complaints ', you will see that it is mostly high with a negative SHAP value. It means higher complaint counts tend to negatively affect the output.
Note: for label “1” the visualization will be flipped.
Dependence Plot
Visualize the dependence_plot between the feature “Subscription Length” and “Age.”
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")A dependence plot is a type of scatter plot that displays how a model's predictions are affected by a specific feature (Subscription Length). On average, subscription lengths have a mostly positive effect on the model.
Force Plot
We will examine the first sample in the testing set to determine which features contributed to the "0" result. To do this, we will utilize a force plot and provide the expected value, SHAP value, and testing sample.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)We can clearly see that zero complaints and zero call failures have contributed to negative to loss of customers.
Let’s look at customer churn samples with label “1”.
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)You can see all of the features with the value and magnitude that have contributed to a loss of customers. It seems that even one unresolved complaint can cost a telecommunications company.
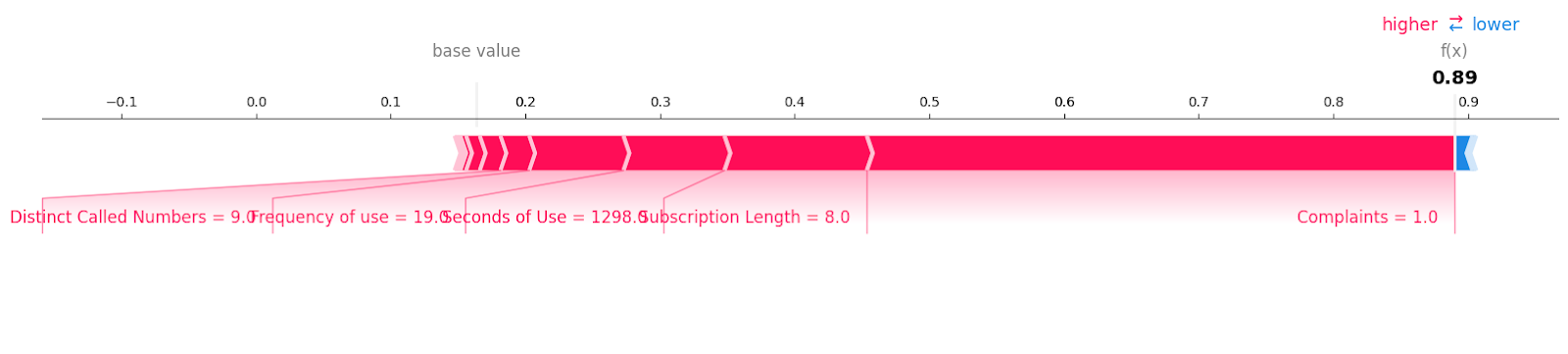
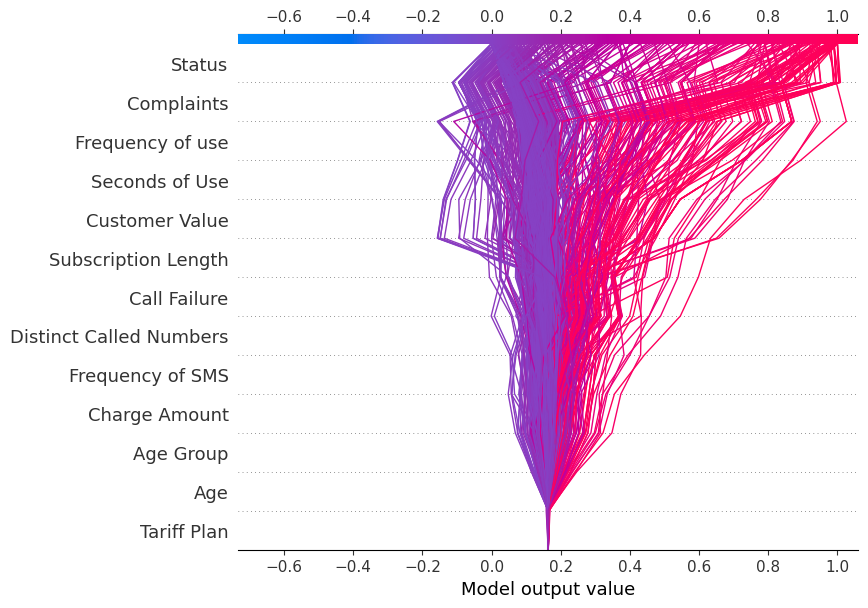
Decision Plot
We will now display the decision_plot. It visually depicts the model decisions by mapping the cumulative SHAP values for each prediction.
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Each plotted line on the decision plot shows how strongly the individual features contributed to a single model prediction, thus explaining what feature values pushed the prediction.
Note: The target label “1” decision plot is tilted towards “1”.
Display the decision plot for the target label “0”
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)For the decision plot is tilted towards “0”.

Application of SHAP Values
Apart from machine learning interpretability and explainability, SHAP value can be used for:
- Model debugging. By examining the SHAP values, we can identify any biases or outliers in the data that may be causing the model to make mistakes.
- Feature importance. Identifying and removing low-impact features can create a more optimized model.
- Anchoring explanations. We can use SHAP values to explain individual predictions by highlighting the essential features that caused that prediction. It can help users understand and trust a model's decisions.
- Model summaries. It can provide a global summary of a model in the form of a SHAP value summary plot. It gives an overview of the most important features across the entire dataset.
- Detecting biases. The SHAP value analysis helps identify if certain features disproportionately affect particular groups. It enables the detection and reduction of discrimination in the model.
- Fairness auditing. It can be used to assess a model's fairness and ethical implications.
- Regulatory approval. SHAP values can help gain regulatory approval by explaining the model's decisions.
Conclusion
We have explored SHAP values and how we can use them to provide interpretability for machine learning models. While having an accurate model is essential, companies need to go beyond accuracy and focus on interpretability and transparency to gain the trust of users and regulators.
Being able to explain why a model made a particular prediction helps debug potential biases, identify data issues, and justify the model's decisions.
If you're new to machine learning and looking to become job-ready, consider taking the Machine Learning Scientist with Python career track. This program will help you master the necessary Python skills to become a machine learning scientist and land a job.



