
Meskipun kNN dapat digunakan untuk klasifikasi dan regresi, artikel ini akan berfokus pada membangun model klasifikasi. Klasifikasi dalam machine learning adalah tugas supervised learning yang melibatkan prediksi label kategorikal untuk suatu titik data masukan. Algoritma dilatih pada dataset berlabel dan menggunakan fitur masukan untuk mempelajari pemetaan antara input dan label kelas yang sesuai. Kita dapat menggunakan model terlatih untuk memprediksi data baru yang belum pernah dilihat. Anda juga dapat menjalankan kode untuk tutorial ini dengan membuka buku kerja DataLab ini.
Gambaran Umum K-Nearest Neighbors
Algoritma kNN dapat dianggap sebagai sistem voting, di mana label kelas mayoritas menentukan label kelas dari titik data baru di antara ‘k’ tetangga terdekatnya (k adalah bilangan bulat) di ruang fitur. Bayangkan sebuah desa kecil dengan beberapa ratus penduduk, dan Anda harus memutuskan partai politik mana yang akan Anda pilih. Untuk itu, Anda mungkin mendatangi tetangga terdekat dan menanyakan partai politik yang mereka dukung. Jika mayoritas dari ‘k’ tetangga terdekat Anda mendukung partai A, maka kemungkinan besar Anda juga akan memilih partai A. Ini mirip dengan cara kerja kNN, di mana label kelas mayoritas menentukan label kelas titik data baru di antara k tetangga terdekatnya.
Mari kita dalami dengan contoh lain. Bayangkan Anda memiliki data tentang buah, khususnya anggur dan pir. Anda memiliki skor seberapa bulat buah tersebut dan diameternya. Anda memutuskan untuk memplot ini pada sebuah grafik. Jika seseorang memberikan buah baru, Anda bisa memplotnya juga, lalu mengukur jarak ke k (sebuah angka) titik terdekat untuk menentukan itu buah apa. Pada contoh di bawah, jika kita memilih mengukur tiga titik, kita dapat mengatakan tiga titik terdekat adalah pir, jadi saya 100% yakin ini adalah pir. Jika kita memilih mengukur empat titik terdekat, tiga adalah pir sementara satu anggur, sehingga kita akan mengatakan kita 75% yakin ini adalah pir. Kita akan membahas cara menemukan nilai k terbaik dan berbagai cara mengukur jarak nanti di artikel ini.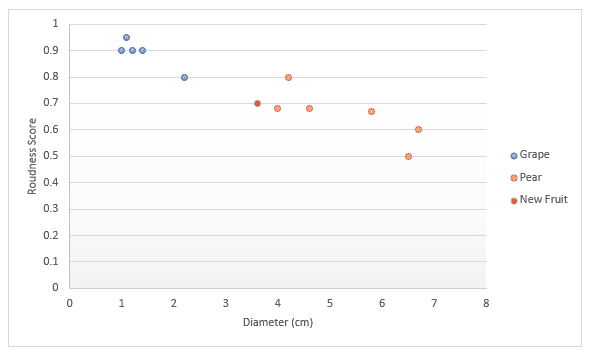
Dataset
Untuk mengilustrasikan algoritma kNN lebih lanjut, mari kita kerjakan studi kasus yang mungkin Anda temui saat bekerja sebagai data scientist. Misalkan Anda adalah data scientist di sebuah peritel online, dan Anda ditugaskan mendeteksi transaksi penipuan. Satu-satunya fitur yang Anda miliki saat ini adalah:
dist_from_home: Jarak antara lokasi rumah pengguna dan tempat transaksi dilakukan.purchase_price_ratio: rasio antara harga barang yang dibeli pada transaksi ini terhadap median harga pembelian pengguna tersebut.
Data memiliki 39 observasi yang merupakan transaksi individual. Dalam tutorial ini, kita diberikan dataset pada variabel df, tampilannya seperti ini:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
Alur Kerja k-Nearest Neighbors
Untuk menyesuaikan dan melatih model ini, kita akan mengikuti infografik The Machine Learning Workflow.
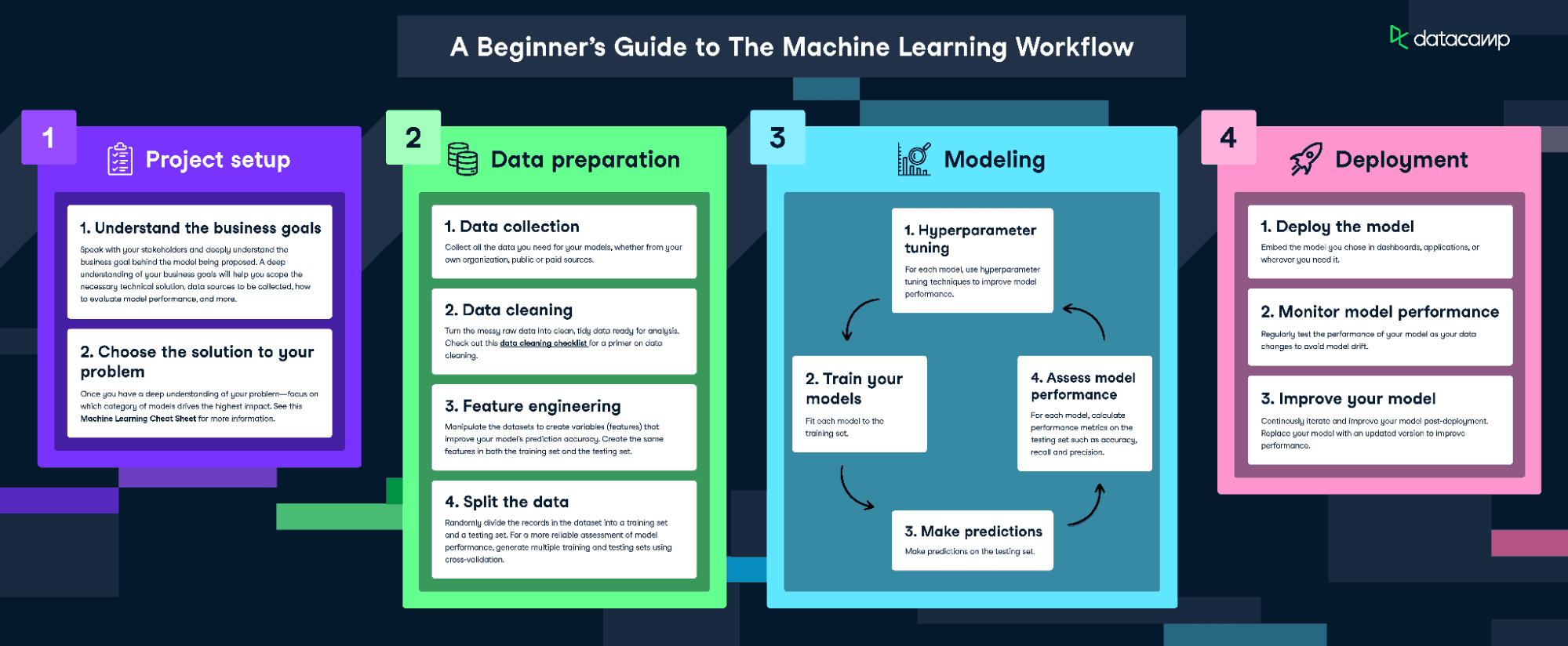
Unduh infografik alur kerja machine learning
Namun, karena data kita cukup bersih, kita tidak akan menjalankan setiap langkah. Kita akan melakukan hal-hal berikut:
- Rekayasa fitur
- Membagi data
- Melatih model
- Tuning hiperparameter
- Menilai kinerja model
Memvisualisasikan Data
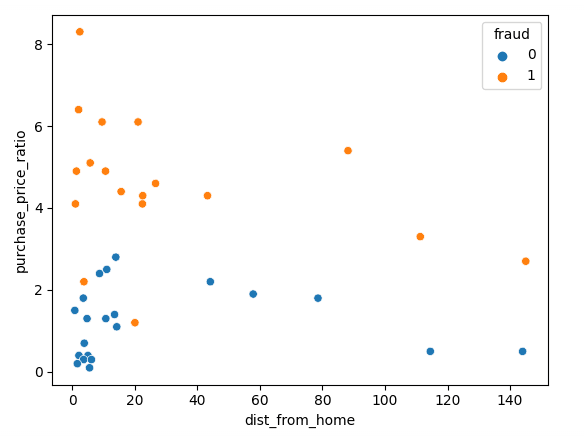
Mari mulai dengan memvisualisasikan data menggunakan Matplotlib; kita dapat memplot dua fitur kita dalam scatterplot.
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Seperti yang terlihat, ada perbedaan yang jelas di antara transaksi ini, dengan transaksi penipuan bernilai jauh lebih tinggi dibandingkan median pesanan pelanggan. Pola terkait jarak dari rumah agak sulit ditafsirkan, dengan transaksi non-penipuan umumnya lebih dekat ke rumah namun memiliki beberapa outlier.
Menormalisasi & Membagi Data
Saat melatih model machine learning apa pun, penting untuk membagi data menjadi data latih dan data uji. Data latih digunakan untuk menyesuaikan model. Algoritma menggunakan data latih untuk mempelajari hubungan antara fitur dan target. Ia mencoba menemukan pola dalam data latih yang dapat digunakan untuk membuat prediksi pada data baru yang belum pernah dilihat. Data uji digunakan untuk mengevaluasi kinerja model. Model diuji pada data uji dengan menggunakannya untuk membuat prediksi dan membandingkan prediksi ini dengan nilai target aktual.
Saat melatih classifier kNN, sangat penting untuk menormalisasi fitur. Ini karena kNN mengukur jarak antar titik. Default-nya adalah menggunakan Jarak Euclidean, yaitu akar kuadrat dari jumlah selisih kuadrat antara dua titik. Dalam kasus kita, purchase_price_ratio berada antara 0 dan 8 sementara dist_from_home jauh lebih besar. Jika kita tidak menormalisasi ini, perhitungan kita akan sangat dipengaruhi oleh dist_from_home karena angkanya lebih besar.
Kita sebaiknya menormalisasi data setelah membaginya menjadi set latih dan uji. Ini untuk mencegah ‘data leakage’ karena normalisasi akan memberikan informasi tambahan tentang set uji jika kita menormalisasi semua data sekaligus.
Kode berikut membagi data menjadi train/test split, lalu menormalisasi menggunakan standard scaler dari scikit-learn. Kita terlebih dahulu memanggil .fit_transform() pada data latih, yang menyesuaikan scaler kita ke mean dan standar deviasi data latih. Kita kemudian menerapkannya ke data uji dengan memanggil .transform(), yang menggunakan nilai yang telah dipelajari sebelumnya.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Menyesuaikan dan Mengevaluasi Model
Sekarang kita siap melatih model. Untuk ini, kita akan menggunakan nilai tetap 3 untuk k, tetapi kita perlu mengoptimalkannya nanti. Pertama, kita membuat instance model kNN, lalu menyesuaikannya dengan data latih. Kita meneruskan baik fitur maupun variabel target agar model dapat belajar.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)Model sekarang telah dilatih! Kita dapat membuat prediksi pada dataset uji, yang nantinya dapat kita gunakan untuk memberi skor pada model.
y_pred = knn.predict(X_test)Cara paling sederhana untuk mengevaluasi model ini adalah menggunakan akurasi. Kita memeriksa prediksi terhadap nilai aktual di set uji dan menghitung berapa banyak yang benar diprediksi model.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875Ini skor yang cukup baik! Namun, kita mungkin bisa lebih baik dengan mengoptimalkan nilai k.
Menggunakan Cross Validation untuk Mendapatkan Nilai k Terbaik
Sayangnya, tidak ada cara ajaib untuk menemukan nilai k terbaik. Kita harus melakukan loop melalui banyak nilai yang berbeda, lalu menggunakan penilaian terbaik kita.
Pada kode di bawah, kita memilih rentang nilai untuk k dan membuat daftar kosong untuk menyimpan hasil. Kita menggunakan cross-validation untuk menemukan skor akurasi, yang berarti kita tidak perlu membuat train/test split, tetapi kita tetap perlu melakukan skala pada data kita. Lalu kita melakukan loop atas nilai-nilai tersebut dan menambahkan skor ke daftar.
Untuk menerapkan cross-validation, kita menggunakan cross_val_score dari scikit-learn. Kita meneruskan instance model kNN, bersama data dan jumlah split yang akan dibuat. Pada kode di bawah, kita menggunakan lima split yang berarti model akan membagi data menjadi lima kelompok berukuran sama dan menggunakan 4 untuk melatih serta 1 untuk menguji hasilnya. Ia akan melakukan loop melalui setiap kelompok dan memberikan skor akurasi, yang kita rata-rata untuk menemukan model terbaik.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
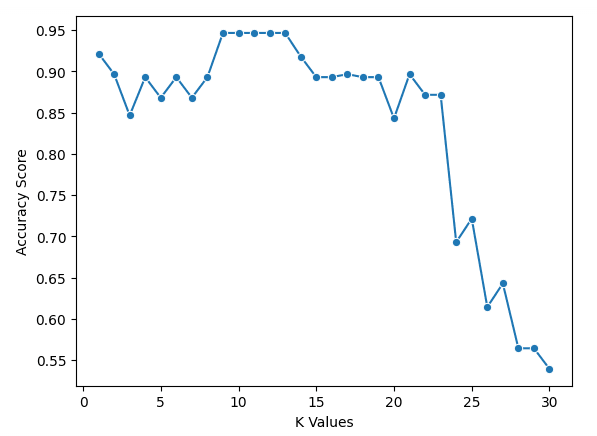
scores.append(np.mean(score))Kita dapat memplot hasilnya dengan kode berikut
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
plt.ylabel("Accuracy Score")Dari grafik, terlihat bahwa k = 9, 10, 11, 12, dan 13 semuanya memiliki skor akurasi tepat di bawah 95%. Karena ini seri untuk skor terbaik, disarankan menggunakan nilai k yang lebih kecil. Alasannya, saat menggunakan nilai k yang lebih tinggi, model akan menggunakan lebih banyak titik data yang lebih jauh dari yang asli. Opsi lain adalah mengeksplorasi metrik evaluasi lainnya.
Metrik Evaluasi Lainnya
Sekarang kita dapat melatih model menggunakan nilai k terbaik dengan kode di bawah.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)kemudian evaluasi dengan akurasi, presisi, dan recall (perhatikan hasil Anda dapat berbeda karena pengacakan)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Tingkatkan ke Level Berikutnya
- Kursus Supervised Learning with scikit-learn adalah titik awal kurikulum machine learning in Python DataCamp dan membahas k-nearest neighbors.
- Kursus Anomaly Detection in Python, Dealing with Missing Data in Python, dan Machine Learning for Finance in Python semuanya menampilkan contoh penggunaan k-nearest neighbors.
- Tutorial Decision Tree Classification in Python membahas model machine learning lain untuk mengklasifikasikan data.
- scikit-learn cheat sheet menyediakan referensi praktis untuk fungsionalitas machine learning populer.
