
Pur potendo essere usato per classificazione e regressione, in questo articolo ci concentreremo sulla costruzione di un modello di classificazione. La classificazione nel machine learning è un compito supervisionato che prevede di prevedere un'etichetta categoriale per un dato punto dati in input. L'algoritmo viene addestrato su un dataset etichettato e usa le feature in input per imparare la mappatura tra input ed etichette di classe corrispondenti. Possiamo usare il modello addestrato per prevedere nuovi dati mai visti. Puoi anche eseguire il codice di questo tutorial aprendo questo workbook DataLab.
Panoramica di K-Nearest Neighbors
L'algoritmo kNN può essere visto come un sistema di voto, in cui l'etichetta di classe di maggioranza determina l'etichetta di un nuovo punto dati tra i suoi ‘k’ (dove k è un intero) vicini più prossimi nello spazio delle feature. Immagina un piccolo villaggio con qualche centinaio di abitanti e di dover decidere per quale partito politico votare. Per farlo, potresti chiedere ai vicini più prossimi quale partito sostengono. Se la maggioranza dei tuoi ‘k’ vicini più prossimi sostiene il partito A, con ogni probabilità voteresti anche tu per il partito A. È lo stesso principio del kNN: la classe di maggioranza tra i k vicini più prossimi determina la classe del nuovo punto.
Vediamo un altro esempio per approfondire. Immagina di avere dati sulla frutta, in particolare uva e pere. Hai un punteggio su quanto è rotondo il frutto e il diametro. Decidi di tracciarli su un grafico. Se qualcuno ti porta un nuovo frutto, potresti tracciarlo a tua volta e poi misurare la distanza dai k (un numero) punti più vicini per decidere che frutto sia. Nell'esempio sotto, se scegliamo di considerare tre punti, i tre più vicini sono pere, quindi sono sicuro al 100% che sia una pera. Se scegliamo di considerare i quattro punti più vicini, tre sono pere e uno è uva, quindi diremmo di essere sicuri al 75% che sia una pera. Più avanti nell'articolo vedremo come trovare il valore migliore di k e i diversi modi di misurare la distanza.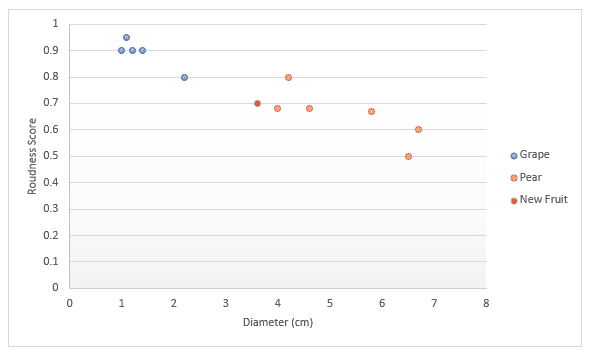
Il dataset
Per illustrare meglio l'algoritmo kNN, lavoriamo su un caso d'uso tipico per un data scientist. Supponiamo che tu sia un data scientist in un negozio online e ti sia stato chiesto di individuare transazioni fraudolente. Le uniche feature a disposizione per ora sono:
dist_from_home: la distanza tra l'abitazione dell'utente e il luogo in cui è stata effettuata la transazione.purchase_price_ratio: il rapporto tra il prezzo dell'articolo acquistato in questa transazione e il prezzo mediano degli acquisti di quell'utente.
I dati contano 39 osservazioni, ciascuna una transazione. In questo tutorial, il dataset ci viene fornito nella variabile df, e appare così:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
Workflow di k-Nearest Neighbors
Per adattare e addestrare questo modello, seguiremo l'infografica The Machine Learning Workflow.
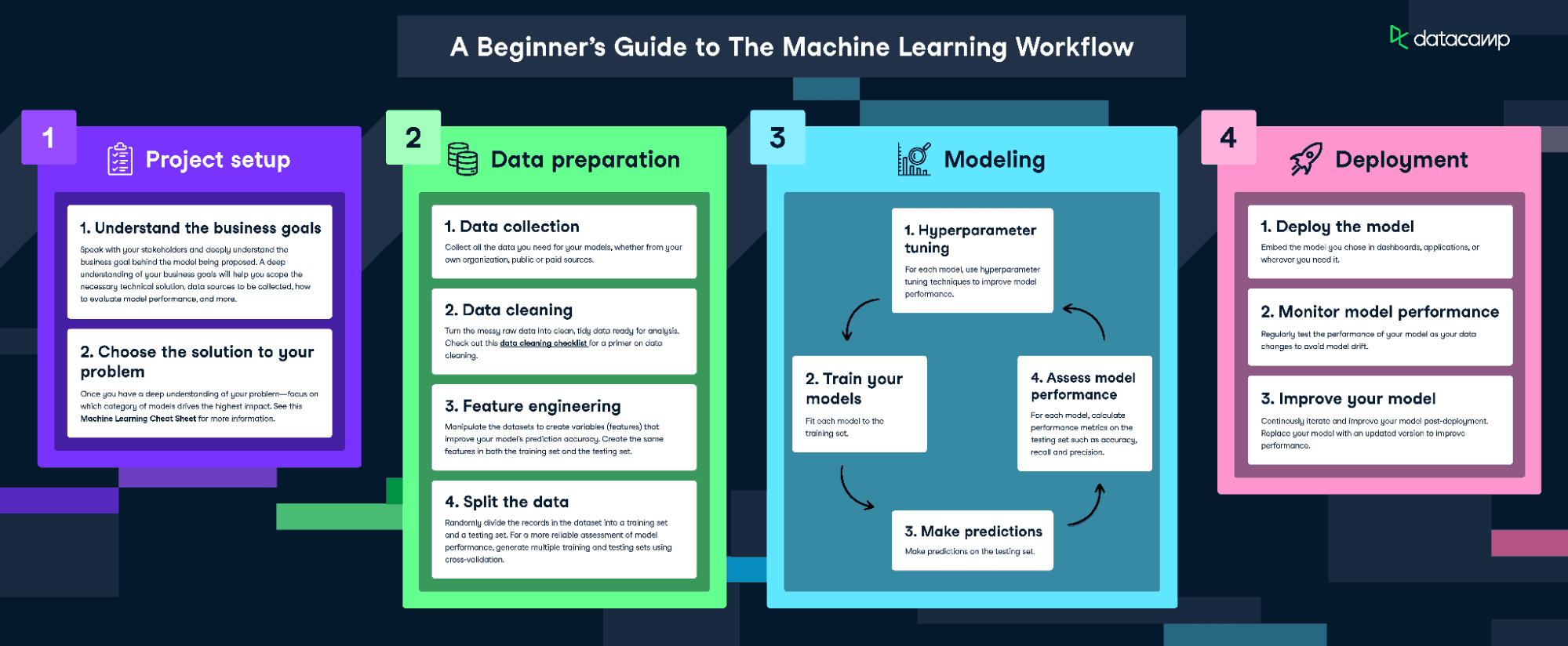
Scarica l'infografica sul workflow del machine learning
Tuttavia, dato che i nostri dati sono piuttosto puliti, non svolgeremo ogni passaggio. Faremo quanto segue:
- Feature engineering
- Suddivisione dei dati
- Addestramento del modello
- Tuning degli iperparametri
- Valutazione delle prestazioni del modello
Visualizzare i dati
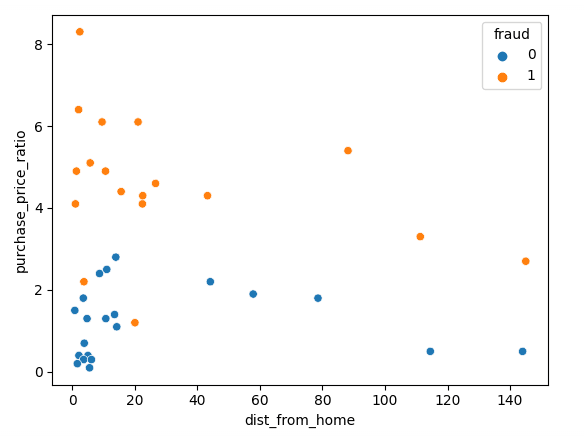
Iniziamo visualizzando i dati con Matplotlib; possiamo tracciare le due feature in uno scatter plot.
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Come puoi vedere, c'è una chiara differenza tra queste transazioni: quelle fraudolente hanno un valore molto più alto rispetto all'ordine mediano dei clienti. Le tendenze rispetto alla distanza da casa sono un po' difficili da interpretare: le transazioni non fraudolente in genere sono più vicine a casa, ma con diversi outlier.
Normalizzazione e suddivisione dei dati
Quando si addestra un qualsiasi modello di machine learning, è importante suddividere i dati in training e test. I dati di training servono ad adattare il modello. L'algoritmo usa i dati di training per apprendere la relazione tra le feature e il target, cercando uno schema che consenta di fare previsioni su nuovi dati mai visti. I dati di test servono a valutare le prestazioni del modello: si eseguono previsioni e si confrontano con i valori reali del target.
Quando si addestra un classificatore kNN, è fondamentale normalizzare le feature. Questo perché kNN misura la distanza tra i punti. Il default è la distanza euclidea, cioè la radice quadrata della somma delle differenze al quadrato tra due punti. Nel nostro caso, purchase_price_ratio va da 0 a 8, mentre dist_from_home è molto più grande. Se non normalizzassimo, il calcolo sarebbe fortemente influenzato da dist_from_home perché i numeri sono più grandi.
Dovremmo normalizzare i dati dopo averli suddivisi in training e test. Questo per evitare la ‘fuga di informazioni’: normalizzare tutto in una volta darebbe al modello informazioni aggiuntive sul test set.
Il codice seguente suddivide i dati in train/test, poi normalizza usando lo standard scaler di scikit-learn. Per prima cosa chiamiamo .fit_transform() sui dati di training, che adatta lo scaler alla media e alla deviazione standard del training. Possiamo poi applicarlo ai dati di test chiamando .transform(), che usa i valori appresi in precedenza.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Adattare e valutare il modello
Ora siamo pronti per addestrare il modello. Useremo un valore fisso di 3 per k, ma lo ottimizzeremo più avanti. Creiamo prima un'istanza del modello kNN e poi lo adattiamo ai dati di training. Passiamo sia le feature sia la variabile target, così il modello può apprendere.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)Il modello è stato addestrato! Possiamo fare previsioni sul dataset di test, che useremo poi per valutare il modello.
y_pred = knn.predict(X_test)Il modo più semplice per valutare questo modello è l'accuracy. Confrontiamo le previsioni con i valori reali nel test set e contiamo quante volte il modello ha indovinato.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875È un buon punteggio! Tuttavia, possiamo forse migliorare ottimizzando il valore di k.
Usare la cross-validation per trovare il valore migliore di k
Purtroppo non esiste un metodo magico per trovare il miglior k. Dobbiamo provare molti valori diversi e poi usare il nostro giudizio.
Nel codice qui sotto, selezioniamo un intervallo di valori per k e creiamo una lista vuota per salvare i risultati. Usiamo la cross-validation per ottenere gli score di accuracy, il che significa che non dobbiamo creare uno split train/test, ma dobbiamo comunque scalare i dati. Iteriamo quindi sui valori e aggiungiamo gli score alla lista.
Per implementare la cross-validation, usiamo cross_val_score di scikit-learn. Passiamo un'istanza del modello kNN, insieme ai nostri dati e al numero di split. Nel codice sotto usiamo cinque split, il che significa che il modello dividerà i dati in cinque gruppi di uguale dimensione e userà 4 per l'addestramento e 1 per il test. Scorrerà ciascun gruppo fornendo un punteggio di accuracy, che poi mediamos per trovare il modello migliore.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
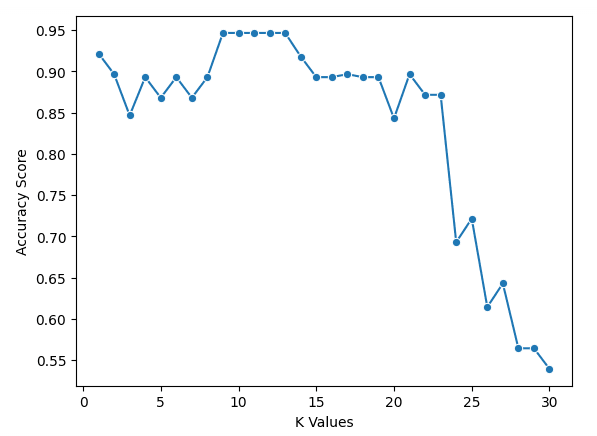
scores.append(np.mean(score))Possiamo tracciare i risultati con il seguente codice
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
plt.ylabel("Accuracy Score")Dal grafico si vede che k = 9, 10, 11, 12 e 13 hanno tutti un'accuracy appena sotto il 95%. Dato che sono a pari merito, è consigliabile usare un valore di k più piccolo. Questo perché con valori di k più grandi il modello utilizza più punti dati lontani dall'osservazione originale. Un'altra opzione è esplorare altre metriche di valutazione.
Altre metriche di valutazione
Ora possiamo addestrare il modello usando il valore di k migliore con il codice seguente.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)poi valutarlo con accuracy, precision e recall (nota che i risultati possono differire a causa della randomizzazione)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Fai un passo in più
- Il corso Supervised Learning with scikit-learn è il punto di ingresso al curriculum di machine learning in Python di DataCamp e copre i k-nearest neighbors.
- I corsi Anomaly Detection in Python, Dealing with Missing Data in Python e Machine Learning for Finance in Python mostrano esempi d'uso dei k-nearest neighbors.
- Il tutorial Decision Tree Classification in Python tratta un altro modello di machine learning per la classificazione dei dati.
- La cheat sheet di scikit-learn fornisce un comodo riferimento alle funzionalità più usate nel machine learning.

