
Mặc dù kNN có thể dùng cho cả phân loại và hồi quy, bài viết này sẽ tập trung vào xây dựng mô hình phân loại. Phân loại trong machine learning là một tác vụ học có giám sát liên quan đến việc dự đoán nhãn dạng phân loại cho một điểm dữ liệu đầu vào. Thuật toán được huấn luyện trên một bộ dữ liệu đã gán nhãn và sử dụng các đặc trưng đầu vào để học ánh xạ giữa đầu vào và nhãn lớp tương ứng. Chúng ta có thể dùng mô hình đã huấn luyện để dự đoán dữ liệu mới, chưa thấy. Bạn cũng có thể chạy mã cho hướng dẫn này bằng cách mở sổ tay DataLab này.
Tổng quan về K-Nearest Neighbors
Thuật toán kNN có thể được coi là một hệ thống bỏ phiếu, trong đó nhãn lớp chiếm đa số sẽ quyết định nhãn lớp của một điểm dữ liệu mới trong số ‘k’ (k là số nguyên) láng giềng gần nhất trong không gian đặc trưng. Hãy tưởng tượng một ngôi làng nhỏ với vài trăm cư dân, và bạn phải quyết định nên bỏ phiếu cho đảng chính trị nào. Để làm điều này, bạn có thể đến hỏi những hàng xóm gần nhất xem họ ủng hộ đảng nào. Nếu đa số ‘k’ hàng xóm gần nhất của bạn ủng hộ đảng A, thì rất có thể bạn cũng sẽ bỏ phiếu cho đảng A. Đây tương tự cách kNN hoạt động, trong đó nhãn lớp đa số quyết định nhãn lớp của một điểm dữ liệu mới trong số k láng giềng gần nhất.
Hãy xem sâu hơn với một ví dụ khác. Giả sử bạn có dữ liệu về trái cây, cụ thể là nho và lê. Bạn có điểm đánh giá độ tròn và đường kính. Bạn quyết định vẽ chúng lên đồ thị. Nếu ai đó đưa cho bạn một quả mới, bạn cũng có thể đặt điểm của nó lên đồ thị, rồi đo khoảng cách đến k (một con số) điểm gần nhất để quyết định đó là loại quả gì. Trong ví dụ dưới đây, nếu chúng ta chọn đo ba điểm, ta có thể nói ba điểm gần nhất là lê, nên tôi chắc chắn 100% đây là lê. Nếu chọn đo bốn điểm gần nhất, ba là lê và một là nho, vậy chúng ta sẽ nói chúng ta chắc 75% đây là lê. Chúng ta sẽ đề cập cách tìm giá trị k tối ưu và các cách đo khoảng cách khác nhau ở phần sau của bài viết này.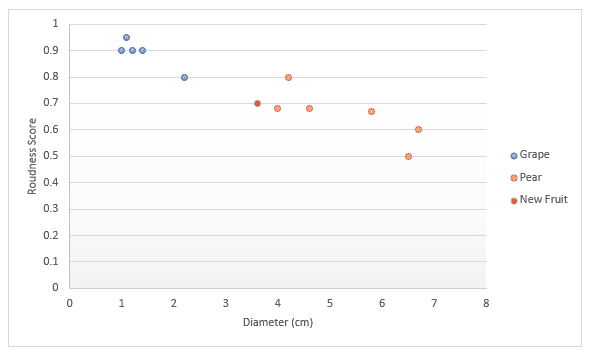
Tập dữ liệu
Để minh họa thêm thuật toán kNN, hãy làm một nghiên cứu tình huống mà bạn có thể gặp khi làm nhà khoa học dữ liệu. Giả sử bạn là nhà khoa học dữ liệu tại một nhà bán lẻ trực tuyến và bạn được giao nhiệm vụ phát hiện giao dịch gian lận. Những đặc trưng duy nhất bạn có ở giai đoạn này là:
dist_from_home: Khoảng cách giữa vị trí nhà của người dùng và nơi thực hiện giao dịch.purchase_price_ratio: tỷ lệ giữa giá mặt hàng được mua trong giao dịch này so với giá mua trung vị của người dùng đó.
Dữ liệu có 39 quan sát, mỗi quan sát là một giao dịch riêng lẻ. Trong hướng dẫn này, chúng ta được cung cấp tập dữ liệu dưới biến df, trông như sau:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
Quy trình k-Nearest Neighbors
Để fit và huấn luyện mô hình này, chúng ta sẽ làm theo infographic Quy trình làm việc Machine Learning.
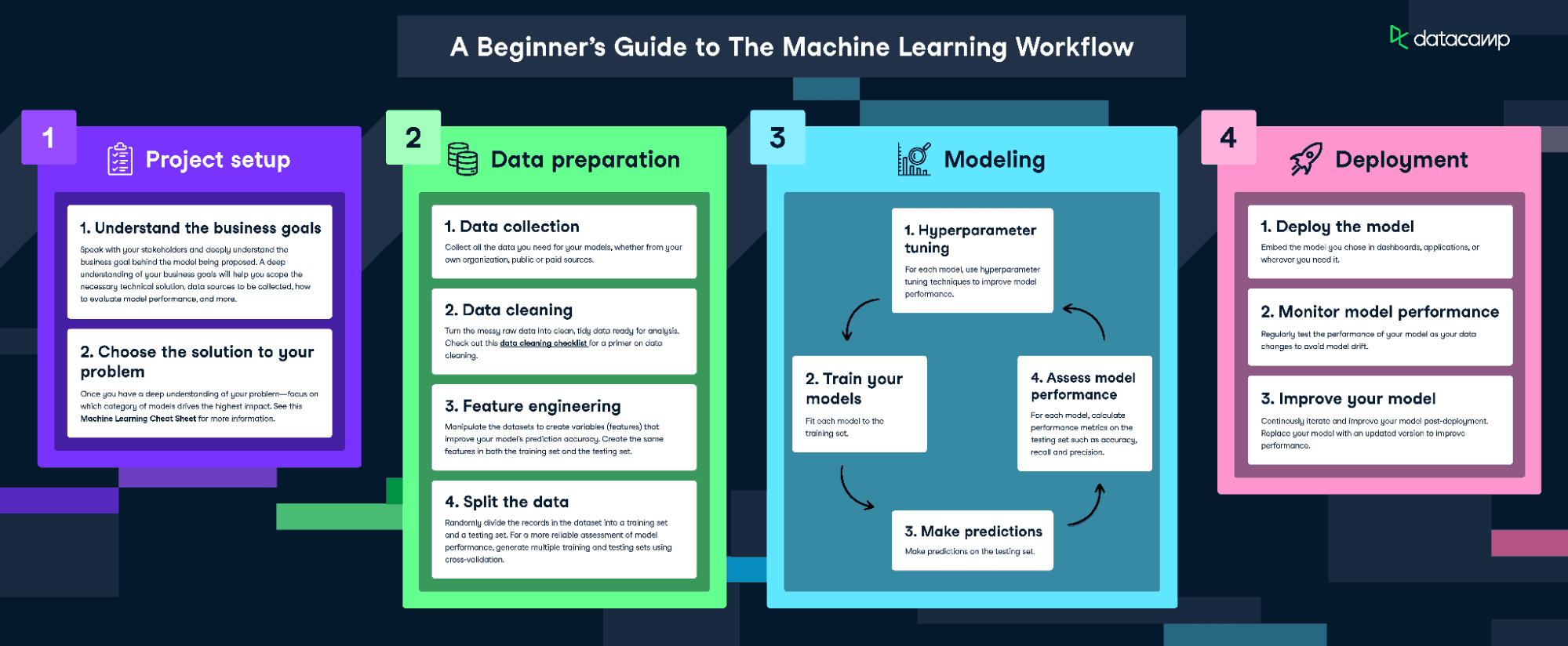
Tải infographic quy trình làm việc machine learning
Tuy nhiên, vì dữ liệu của chúng ta khá sạch, chúng ta sẽ không thực hiện mọi bước. Chúng ta sẽ làm những việc sau:
- Kỹ thuật đặc trưng
- Chia dữ liệu
- Huấn luyện mô hình
- Tối ưu siêu tham số
- Đánh giá hiệu năng mô hình
Trực quan hóa dữ liệu
Hãy bắt đầu bằng cách trực quan hóa dữ liệu bằng Matplotlib; chúng ta có thể vẽ hai đặc trưng của mình trên biểu đồ scatter.
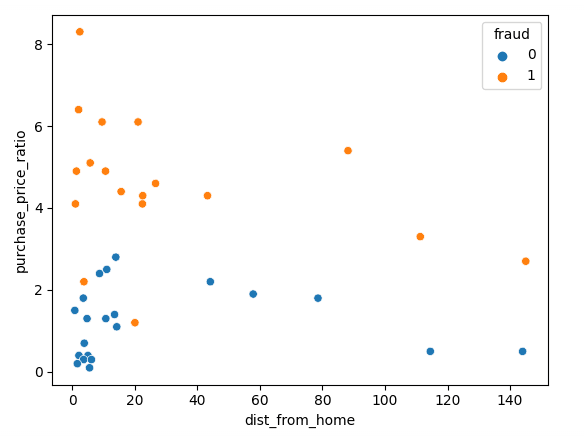
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Như bạn thấy, có sự khác biệt rõ rệt giữa các giao dịch này, với các giao dịch gian lận có giá trị cao hơn nhiều so với đơn hàng trung vị của khách hàng. Xu hướng liên quan đến khoảng cách từ nhà hơi khó diễn giải, với các giao dịch không gian lận thường gần nhà hơn nhưng có một số ngoại lệ.
Chuẩn hóa & chia dữ liệu
Khi huấn luyện bất kỳ mô hình machine learning nào, việc chia dữ liệu thành tập huấn luyện và tập kiểm tra là quan trọng. Tập huấn luyện được dùng để fit mô hình. Thuật toán sử dụng dữ liệu huấn luyện để học mối quan hệ giữa các đặc trưng và mục tiêu. Nó cố gắng tìm ra mẫu trong dữ liệu huấn luyện có thể dùng để dự đoán dữ liệu mới, chưa thấy. Tập kiểm tra được dùng để đánh giá hiệu năng của mô hình. Mô hình được kiểm tra trên tập kiểm tra bằng cách dùng nó để tạo dự đoán và so sánh các dự đoán này với giá trị mục tiêu thực tế.
Khi huấn luyện bộ phân loại kNN, việc chuẩn hóa các đặc trưng là điều cốt yếu. Lý do là kNN đo khoảng cách giữa các điểm. Mặc định là dùng khoảng cách Euclid, tức căn bậc hai của tổng bình phương chênh lệch giữa hai điểm. Trong trường hợp của chúng ta, purchase_price_ratio nằm trong khoảng 0 đến 8 trong khi dist_from_home lớn hơn nhiều. Nếu không chuẩn hóa, phép tính của chúng ta sẽ bị chi phối mạnh bởi dist_from_home vì các con số lớn hơn.
Chúng ta nên chuẩn hóa dữ liệu sau khi chia thành tập huấn luyện và kiểm tra. Điều này nhằm tránh ‘rò rỉ dữ liệu’ vì việc chuẩn hóa toàn bộ dữ liệu cùng lúc sẽ cung cấp cho mô hình thêm thông tin về tập kiểm tra.
Đoạn mã sau chia dữ liệu thành tập train/test, sau đó chuẩn hóa bằng bộ chuẩn hóa chuẩn của scikit-learn. Trước tiên, chúng ta gọi .fit_transform() trên dữ liệu huấn luyện, thao tác này fit bộ chuẩn hóa với giá trị trung bình và độ lệch chuẩn của dữ liệu huấn luyện. Sau đó, chúng ta áp dụng cho dữ liệu kiểm tra bằng cách gọi .transform(), sử dụng các giá trị đã học trước đó.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Fit và đánh giá mô hình
Bây giờ chúng ta sẵn sàng huấn luyện mô hình. Với việc này, chúng ta sẽ dùng giá trị cố định 3 cho k, nhưng sau đó sẽ cần tối ưu. Trước tiên, chúng ta tạo một thực thể mô hình kNN, rồi fit nó với dữ liệu huấn luyện. Chúng ta truyền cả đặc trưng và biến mục tiêu để mô hình có thể học.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)Mô hình đã được huấn luyện! Chúng ta có thể tạo dự đoán trên tập kiểm tra, và sau đó dùng để chấm điểm mô hình.
y_pred = knn.predict(X_test)Cách đơn giản nhất để đánh giá mô hình này là dùng độ chính xác (accuracy). Chúng ta kiểm tra các dự đoán so với giá trị thực trong tập kiểm tra và đếm xem mô hình dự đoán đúng bao nhiêu.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875Đây là một điểm số khá tốt! Tuy nhiên, chúng ta có thể làm tốt hơn bằng cách tối ưu giá trị k.
Sử dụng xác thực chéo để tìm giá trị k tốt nhất
Đáng tiếc là không có cách thần kỳ nào để tìm giá trị k tốt nhất. Chúng ta phải lặp qua nhiều giá trị khác nhau rồi dùng phán đoán tốt nhất.
Trong đoạn mã dưới đây, chúng ta chọn một khoảng giá trị cho k và tạo một danh sách rỗng để lưu kết quả. Chúng ta dùng xác thực chéo để tìm điểm chính xác, đồng nghĩa chúng ta không cần tạo tập train/test, nhưng vẫn cần scale dữ liệu. Sau đó, chúng ta lặp qua các giá trị và thêm điểm số vào danh sách.
Để triển khai xác thực chéo, chúng ta dùng cross_val_score của scikit-learn. Chúng ta truyền một thực thể mô hình kNN, cùng với dữ liệu và số lần chia. Trong mã dưới đây, chúng ta dùng năm lần chia, nghĩa là mô hình sẽ chia dữ liệu thành năm nhóm có kích thước bằng nhau và dùng 4 nhóm để huấn luyện, 1 nhóm để kiểm tra. Nó sẽ lặp qua từng nhóm và cho điểm accuracy, rồi chúng ta lấy trung bình để tìm mô hình tốt nhất.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
scores.append(np.mean(score))Chúng ta có thể vẽ kết quả bằng đoạn mã sau
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
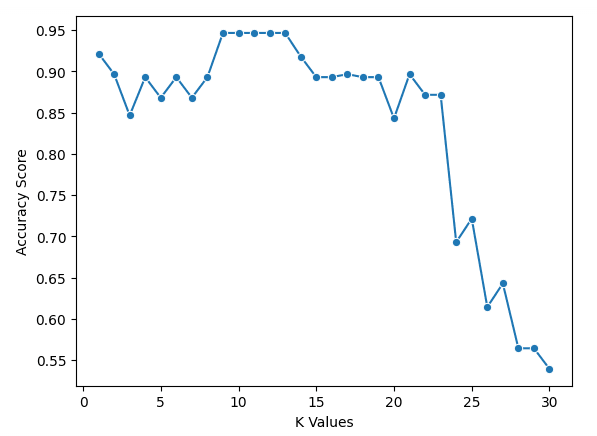
plt.ylabel("Accuracy Score")Từ biểu đồ, ta thấy k = 9, 10, 11, 12 và 13 đều có điểm accuracy gần 95%. Vì các giá trị này đồng hạng cao nhất, nên khuyến nghị dùng giá trị k nhỏ hơn. Lý do là khi dùng k lớn, mô hình sẽ sử dụng nhiều điểm dữ liệu ở xa điểm gốc hơn. Một lựa chọn khác là khám phá thêm các thước đo đánh giá khác.
Nhiều thước đo đánh giá hơn
Giờ chúng ta có thể huấn luyện mô hình với giá trị k tốt nhất bằng đoạn mã dưới đây.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)sau đó đánh giá bằng accuracy, precision và recall (lưu ý kết quả của bạn có thể khác do ngẫu nhiên)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Nâng cấp lên mức tiếp theo
- Khóa học Supervised Learning with scikit-learn là điểm khởi đầu cho lộ trình machine learning bằng Python của DataCamp và có nội dung về k-nearest neighbors.
- Các khóa học Anomaly Detection in Python, Dealing with Missing Data in Python và Machine Learning for Finance in Python đều có ví dụ sử dụng k-nearest neighbors.
- Hướng dẫn Phân loại Cây quyết định trong Python trình bày một mô hình machine learning khác để phân loại dữ liệu.
- Tờ phao scikit-learn cung cấp tham chiếu tiện lợi cho các chức năng machine learning phổ biến.