
kNN hem sınıflandırma hem de regresyon için kullanılabilse de, bu makale bir sınıflandırma modeli kurmaya odaklanacaktır. Makine öğreniminde sınıflandırma, verilen bir girdi veri noktası için kategorik bir etiketin tahmin edilmesini içeren bir denetimli öğrenme görevidir. Algoritma, etiketli bir veri kümesi üzerinde eğitilir ve girdiler ile karşılık gelen sınıf etiketleri arasındaki eşlemeyi öğrenmek için girdi özelliklerini kullanır. Eğitilmiş modeli, yeni ve görülmemiş verileri tahmin etmek için kullanabiliriz. Ayrıca bu öğretideki kodu, şu DataLab çalışma defterini açarak çalıştırabilirsiniz.
K-En Yakın Komşuya Genel Bakış
kNN algoritması bir oylama sistemi olarak düşünülebilir; özellik uzayında en yakın ‘k’ (k bir tam sayıdır) komşu arasında çoğunlukta olan sınıf etiketi, yeni bir veri noktasının sınıf etiketini belirler. Birkaç yüz sakini olan küçük bir köyü hayal edin ve kime oy vermeniz gerektiğine karar vermek zorundasınız. Bunu yapmak için en yakın komşularınıza gidip hangi siyasi partiyi desteklediklerini sorabilirsiniz. Eğer ‘k’ en yakın komşunuzun çoğunluğu A partisini destekliyorsa, siz de büyük olasılıkla A partisine oy verirsiniz. kNN’in çalışma mantığı da buna benzer; çoğunlukta olan sınıf etiketi, yeni bir veri noktasının sınıf etiketini en yakın k komşusu arasında belirler.
Başka bir örnekle daha derine inelim. Meyvelerle ilgili verileriniz olduğunu düşünün; özellikle üzüm ve armut. Meyvenin ne kadar yuvarlak olduğuna dair bir puanınız ve bir de çap değeri var. Bunları bir grafikte göstermeye karar veriyorsunuz. Biri size yeni bir meyve verdiğinde, bunu da grafiğe yerleştirip k (bir sayı) en yakın noktaya olan mesafeyi ölçerek ne olduğunu belirleyebilirsiniz. Aşağıdaki örnekte üç noktayı ölçmeyi seçersek, en yakın üç nokta armut olduğundan bunun %100 armut olduğunu söyleyebiliriz. Dört en yakın noktayı ölçmeyi seçersek, üçünün armut biri üzüm olduğu durumda bunun %75 olasılıkla armut olduğunu söyleriz. Bu yazının ilerleyen kısımlarında k için en iyi değerin nasıl bulunacağını ve mesafeyi ölçmenin farklı yollarını ele alacağız.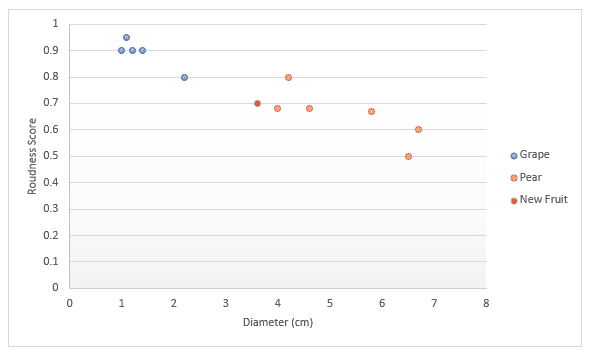
Veri Kümesi
kNN algoritmasını daha iyi göstermek için, bir veri bilimcisi olarak çalışırken karşılaşabileceğiniz bir vaka çalışması üzerinde çalışalım. Çevrimiçi bir perakendecide veri bilimcisi olduğunuzu ve sahtekâr işlemleri tespit etme görevi verildiğini varsayalım. Bu aşamada sahip olduğunuz tek özellikler şunlardır:
dist_from_home: Kullanıcının ev konumu ile işlemin yapıldığı yer arasındaki mesafe.purchase_price_ratio: Bu işlemin satın alma fiyatının, o kullanıcının medyan satın alma fiyatına oranı.
Veriler 39 gözlemden oluşuyor ve her biri bir işlemi temsil ediyor. Bu öğreticide bize df değişkeninde verilen veri kümesi şöyle görünüyor:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
k-En Yakın Komşu İş Akışı
Bu modeli kurup eğitmek için Makine Öğrenimi İş Akışı infografiğini takip edeceğiz.
Makine öğrenimi iş akışı infografiğini indirin
Bununla birlikte verilerimiz oldukça temiz olduğundan her adımı uygulamayacağız. Şunları yapacağız:
- Özellik mühendisliği
- Veriyi bölme
- Modeli eğitme
- Hiperparametre ayarlama
- Model performansını değerlendirme
Veriyi Görselleştirme
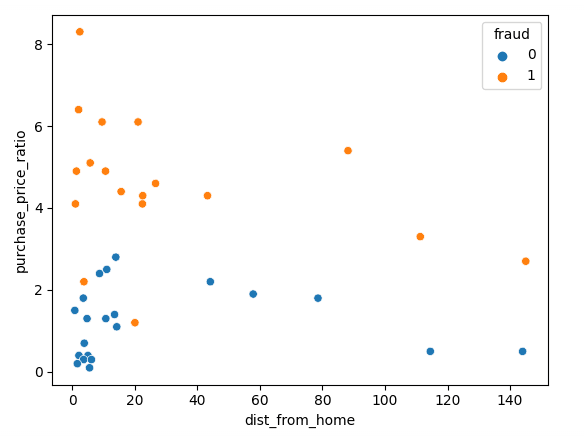
Verimizi Matplotlib kullanarak görselleştirerek başlayalım; iki özelliğimizi bir saçılım grafiğinde gösterebiliriz.
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Gördüğünüz gibi, işlemler arasında belirgin bir fark var; sahtekâr işlemler, müşterilerin medyan siparişine kıyasla çok daha yüksek değerde. Evden uzaklık etrafındaki eğilimleri yorumlamak biraz zor; sahtekâr olmayan işlemler genellikle eve daha yakın olsa da birkaç aykırı değer mevcut.
Veriyi Normalize Etme ve Bölme
Herhangi bir makine öğrenimi modelini eğitirken, veriyi eğitim ve test olarak bölmek önemlidir. Eğitim verisi modeli uyarlamak için kullanılır. Algoritma, özellikler ile hedef değişken arasındaki ilişkiyi öğrenmek için eğitim verisini kullanır. Eğitim verisinde, yeni ve görülmemiş veriler üzerinde tahmin yapmak için kullanılabilecek bir desen bulmaya çalışır. Test verisi ise modelin performansını değerlendirmek için kullanılır. Model, test verisi üzerinde tahminler yaparak bunları gerçek hedef değerleriyle karşılaştırır.
Bir kNN sınıflandırıcısını eğitirken özellikleri normalize etmek kritik önemdedir. Bunun nedeni kNN’in noktalar arasındaki mesafeyi ölçmesidir. Varsayılan olarak Öklid Uzaklığı kullanılır; bu, iki nokta arasındaki kare farkların toplamının kareköküdür. Bizim durumumuzda purchase_price_ratio 0 ile 8 arasındayken dist_from_home çok daha büyüktür. Normalize etmezsek, sayılar daha büyük olduğu için hesabımız dist_from_home tarafından aşırı ağırlıklandırılır.
Veriyi eğitim ve test kümelerine böldükten sonra normalize etmeliyiz. Bunun nedeni “veri sızıntısını” önlemektir; tüm veriyi bir kerede normalize etmek, modelin test kümesi hakkında fazladan bilgi edinmesine yol açar.
Aşağıdaki kod veri kümesini eğitim/test olarak böler, ardından scikit-learn’ün standart ölçekleyicisi ile normalleştirir. Önce eğitim verisi üzerinde .fit_transform() çağırarak ölçekleyicimizi eğitim verisinin ortalamasına ve standart sapmasına uydururuz. Ardından .transform() çağırarak öğrenilen bu değerleri test verisine uygularız.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Modeli Uydurma ve Değerlendirme
Artık modeli eğitmeye hazırız. Bunun için k değerini şimdilik 3 olarak sabitleyeceğiz; ancak bunu daha sonra optimize etmemiz gerekecek. Önce bir kNN model örneği oluşturuyor, ardından bunu eğitim verimize uyduruyoruz. Modelin öğrenebilmesi için hem özellikleri hem de hedef değişkeni geçiriyoruz.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)Model artık eğitildi! Test veri kümesi üzerinde tahminler yapabiliriz; bunları daha sonra modeli puanlamak için kullanacağız.
y_pred = knn.predict(X_test)Bu modeli değerlendirmenin en basit yolu doğruluğu (accuracy) kullanmaktır. Tahminleri test kümesindeki gerçek değerlerle karşılaştırır ve modelin kaçını doğru bulduğunu sayarız.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875Oldukça iyi bir skor! Ancak k değerimizi optimize ederek daha da iyisini yapabiliriz.
k için En İyi Değeri Bulmak Üzere Çapraz Doğrulama Kullanma
Ne yazık ki k için en iyi değeri bulmanın sihirli bir yolu yok. Birçok farklı değeri döngüyle denemeli ve ardından en iyi kanaatimizi kullanmalıyız.
Aşağıdaki kodda k için bir değer aralığı seçiyor ve sonuçları saklamak için boş bir liste oluşturuyoruz. Doğruluk skorlarını bulmak için çapraz doğrulama kullanıyoruz; bu, eğitim ve test bölmesi oluşturmamız gerekmediği anlamına gelir, ancak veriyi ölçeklememiz gerekir. Ardından değerler üzerinde döngü kurup skorları listemize ekliyoruz.
Çapraz doğrulamayı uygulamak için scikit-learn’ün cross_val_score fonksiyonunu kullanıyoruz. Bir kNN model örneğini, verilerimizi ve yapılacak bölme sayısını geçiriyoruz. Aşağıdaki kodda beş bölme kullanıyoruz; bu, modelin veriyi eşit büyüklükte beş gruba ayıracağı ve 4’ünü eğitim, 1’ini test için kullanacağı anlamına gelir. Her grup için döngü kurup bir doğruluk skoru verir; bunların ortalamasını alarak en iyi modeli buluruz.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
scores.append(np.mean(score))Sonuçları aşağıdaki kodla görselleştirebiliriz
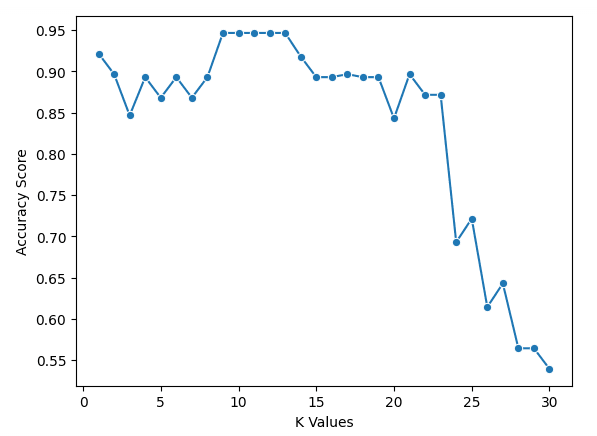
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
plt.ylabel("Accuracy Score")Grafikten k = 9, 10, 11, 12 ve 13 değerlerinin tamamının %95’in biraz altında doğruluk skoruna sahip olduğunu görebiliriz. En iyi skor için berabere kaldıkları durumda, daha küçük bir k değeri kullanmak tavsiye edilir. Çünkü k değeri arttıkça model, asıl noktadan daha uzaktaki daha fazla veri noktasını kullanır. Bir diğer seçenek de farklı değerlendirme metriklerini incelemektir.
Daha Fazla Değerlendirme Metrikleri
Artık aşağıdaki kodla en iyi k değerini kullanarak modelimizi eğitebiliriz.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)ardından doğruluk, kesinlik (precision) ve duyarlılık (recall) ile değerlendirebiliriz (rastgelelik nedeniyle sonuçlarınız farklı olabilir)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Bir Sonraki Seviyeye Taşıyın
- scikit-learn ile Denetimli Öğrenme kursu, DataCamp’in Python ile makine öğrenimi müfredatına giriş niteliğindedir ve k-en yakın komşuları kapsar.
- Python’da Anomali Tespiti, Python’da Eksik Verilerle Başa Çıkma ve Finans için Python ile Makine Öğrenimi kurslarının tümü k-en yakın komşu kullanımına örnekler içerir.
- Python’da Karar Ağacı Sınıflandırması Öğreticisi, verileri sınıflandırmak için başka bir makine öğrenimi modelini ele alır.
- scikit-learn cheat sheet, popüler makine öğrenimi işlevleri için kullanışlı bir başvuru sunar.
