
Hoewel kNN kan worden gebruikt voor classificatie en regressie, richt dit artikel zich op het bouwen van een classificatiemodel. Classificatie in machine learning is een supervised learning-taak waarbij je een categorisch label voorspelt voor een gegeven datapunt. Het algoritme wordt getraind op een gelabelde dataset en gebruikt de inputfeatures om de mapping te leren tussen de inputs en de bijbehorende klasselabels. We kunnen het getrainde model gebruiken om nieuwe, ongeziene data te voorspellen. Je kunt de code voor deze tutorial ook uitvoeren door dit DataLab-werkboek te openen.
Een overzicht van k-nearest neighbors
Het kNN-algoritme kun je zien als een stemsysteem, waarbij het meerderheidsetiket de klasse van een nieuw datapunt bepaalt onder zijn dichtstbijzijnde ‘k’ (waarbij k een geheel getal is) buren in de feature-ruimte. Stel je een klein dorp voor met een paar honderd inwoners, en je moet beslissen op welke politieke partij je gaat stemmen. Je zou je dichtstbijzijnde buren kunnen vragen welke partij zij steunen. Als de meerderheid van je ‘k’ dichtstbijzijnde buren partij A steunt, dan stem je waarschijnlijk ook op partij A. Zo werkt kNN: het meerderheidsetiket bepaalt de klasse van een nieuw datapunt onder zijn k dichtstbijzijnde buren.
Laten we nog een voorbeeld bekijken. Stel dat je gegevens hebt over fruit, specifiek druiven en peren. Je hebt een score voor hoe rond het fruit is en de diameter. Je besluit deze op een grafiek te plotten. Als iemand je een nieuw stuk fruit geeft, kun je dit ook op de grafiek zetten en vervolgens de afstand meten tot de k (een getal) dichtstbijzijnde punten om te bepalen welk fruit het is. In het onderstaande voorbeeld, als we drie punten meten, zijn de drie dichtstbijzijnde punten peren, dus ik ben 100% zeker dat dit een peer is. Als we de vier dichtstbijzijnde punten nemen, zijn er drie peren en één druif, dus we zouden zeggen dat we 75% zeker zijn dat dit een peer is. We bespreken later in dit artikel hoe je de beste waarde voor k vindt en de verschillende manieren om afstand te meten.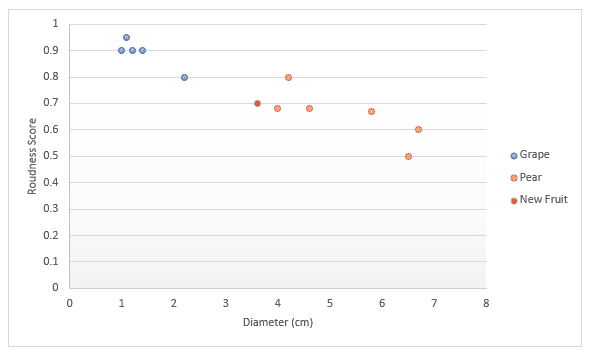
De dataset
Om het kNN-algoritme verder te illustreren, werken we aan een casus die je als data scientist kunt tegenkomen. Stel dat je data scientist bent bij een online retailer en de taak hebt gekregen om frauduleuze transacties te detecteren. De enige features die je op dit moment hebt, zijn:
dist_from_home: de afstand tussen de woonlocatie van de gebruiker en de plaats waar de transactie is gedaan.purchase_price_ratio: de verhouding tussen de prijs van het in deze transactie gekochte item en de mediane aankoopprijs van die gebruiker.
De data bevat 39 observaties, dit zijn afzonderlijke transacties. In deze tutorial hebben we de dataset gekregen in de variabele df; die ziet er zo uit:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
k-nearest neighbors-workflow
Om dit model te fitten en te trainen, volgen we de infographic The Machine Learning Workflow.
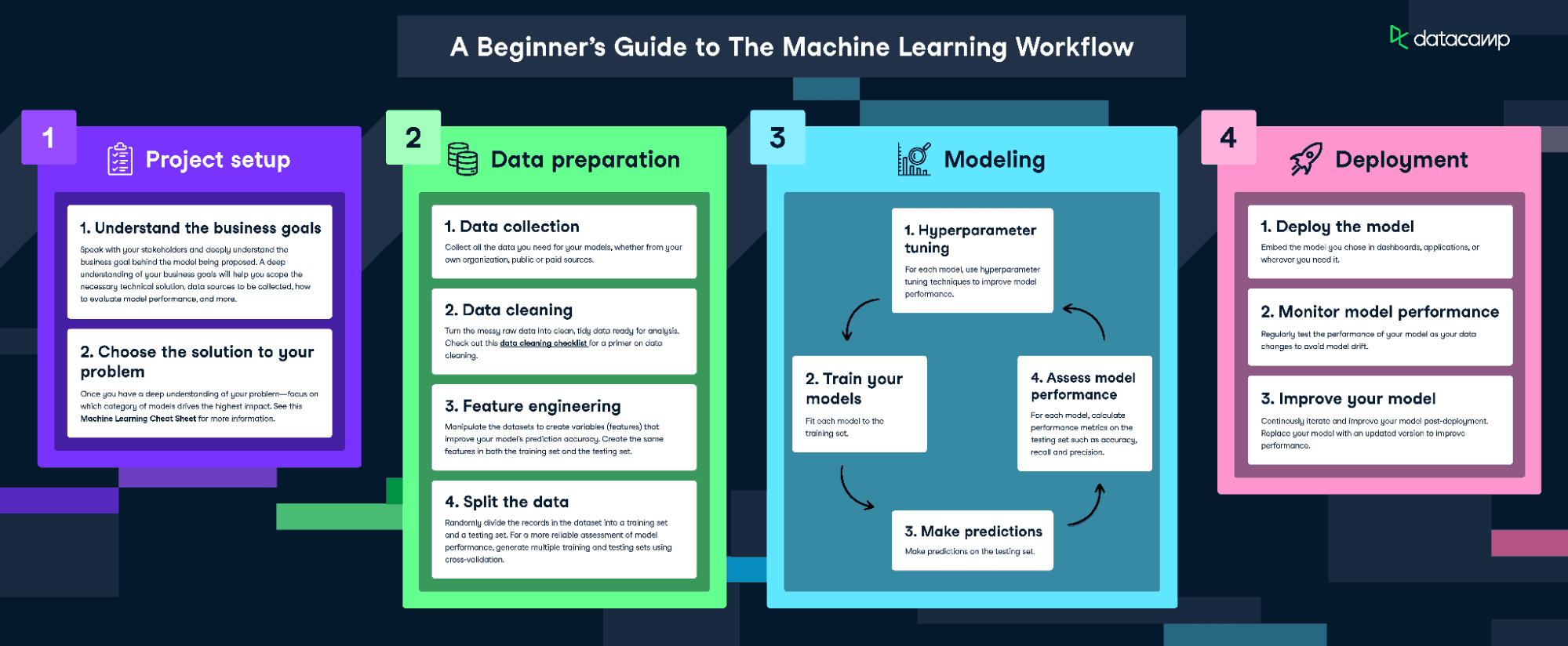
Download de machine learning workflow-infographic
Omdat onze data vrij schoon is, doorlopen we niet elke stap. We doen het volgende:
- Feature engineering
- De data splitsen
- Het model trainen
- Hyperparameters afstemmen
- Modelprestaties beoordelen
Visualiseer de data
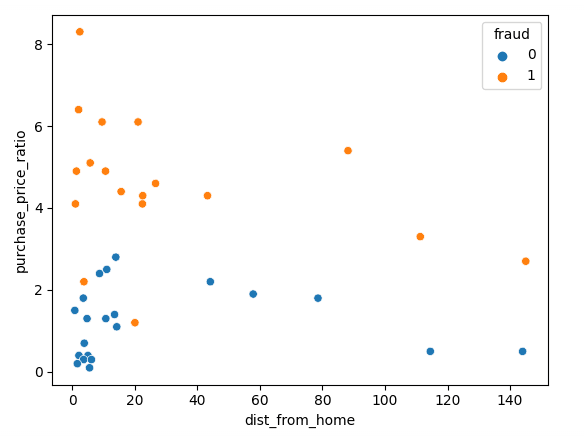
Laten we beginnen met het visualiseren van onze data met Matplotlib; we kunnen onze twee features in een scatterplot plotten.
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Zoals je ziet, is er een duidelijk verschil tussen deze transacties: frauduleuze transacties hebben een veel hogere waarde vergeleken met de mediane bestelling van de klant. De trends rondom afstand tot huis zijn wat lastiger te duiden: niet-frauduleuze transacties zijn doorgaans dichter bij huis, maar er zijn verschillende uitschieters.
Normaliseren & de data splitsen
Bij het trainen van een machine learning-model is het belangrijk om de data te splitsen in trainings- en testdata. De trainingsdata wordt gebruikt om het model te fitten. Het algoritme gebruikt de trainingsdata om de relatie tussen de features en het target te leren. Het probeert een patroon te vinden in de trainingsdata dat kan worden gebruikt om voorspellingen te doen op nieuwe, ongeziene data. De testdata wordt gebruikt om de prestaties van het model te evalueren. Het model wordt op de testdata getest door voorspellingen te doen en deze te vergelijken met de werkelijke targetwaarden.
Bij het trainen van een kNN-classifier is het cruciaal om de features te normaliseren. Dit komt omdat kNN de afstand tussen punten meet. Standaard wordt de Euclidische afstand gebruikt, de wortel uit de som van de gekwadrateerde verschillen tussen twee punten. In ons geval ligt purchase_price_ratio tussen 0 en 8, terwijl dist_from_home veel groter is. Als we dit niet normaliseren, zal onze berekening zwaar worden beïnvloed door dist_from_home, omdat die waarden groter zijn.
We moeten de data normaliseren nadat we deze hebben gesplitst in train- en testsets. Dit voorkomt ‘data leakage’, omdat normaliseren in één keer het model extra informatie over de testset zou geven.
De volgende code splitst de data in train/test-splits en normaliseert vervolgens met scikit-learn’s StandardScaler. We roepen eerst .fit_transform() aan op de trainingsdata, waarmee onze scaler wordt gefit op het gemiddelde en de standaarddeviatie van de trainingsdata. Vervolgens passen we dit toe op de testdata met .transform(), die de eerder geleerde waarden gebruikt.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Het model fitten en evalueren
We zijn nu klaar om het model te trainen. Hiervoor gebruiken we een vaste waarde van 3 voor k, maar die optimaliseren we later. We maken eerst een instantie van het kNN-model en fitten dit vervolgens op onze trainingsdata. We geven zowel de features als de targetvariabele door, zodat het model kan leren.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)Het model is nu getraind! We kunnen voorspellingen doen op de testset, die we later kunnen gebruiken om het model te scoren.
y_pred = knn.predict(X_test)De eenvoudigste manier om dit model te evalueren is met accuracy. We vergelijken de voorspellingen met de werkelijke waarden in de testset en tellen hoe vaak het model het goed had.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875Dit is een prima score! Mogelijk kunnen we nog beter scoren door de waarde van k te optimaliseren.
Met cross-validatie de beste waarde voor k vinden
Er is helaas geen magische manier om de beste waarde voor k te vinden. We moeten door veel verschillende waarden itereren en dan ons oordeel vellen.
In de onderstaande code selecteren we een reeks waarden voor k en maken we een lege lijst om onze resultaten op te slaan. We gebruiken cross-validatie om de accuracy-scores te vinden. Dit betekent dat we geen train-test-split hoeven te maken, maar we moeten de data wel schalen. We loopen vervolgens over de waarden en voegen de scores toe aan onze lijst.
Om cross-validatie te implementeren, gebruiken we scikit-learn’s cross_val_score. We geven een instantie van het kNN-model door, samen met onze data en het aantal splits. In de code hieronder gebruiken we vijf splits, wat betekent dat het model de data opsplitst in vijf even grote groepen en er 4 gebruikt om te trainen en 1 om het resultaat te testen. Het doorloopt elke groep en geeft een accuracy-score, die we middelen om het beste model te vinden.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
scores.append(np.mean(score))We kunnen de resultaten plotten met de volgende code
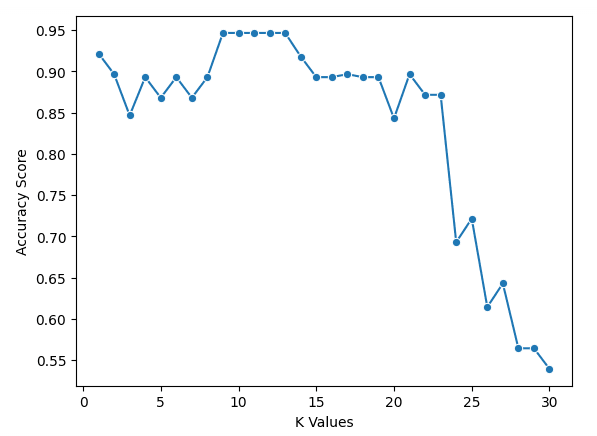
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
plt.ylabel("Accuracy Score")We zien in onze grafiek dat k = 9, 10, 11, 12 en 13 allemaal een accuracy-score hebben van net onder de 95%. Omdat deze gelijkstaan voor de beste score, is het aan te raden een kleinere waarde voor k te gebruiken. Bij hogere k-waarden gebruikt het model namelijk meer datapunten die verder van het origineel afliggen. Een andere optie is om andere evaluatiemetrics te verkennen.
Meer evaluatiemetrics
We kunnen nu ons model trainen met de beste k-waarde met de onderstaande code.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)en vervolgens evalueren met accuracy, precision en recall (let op: jouw resultaten kunnen verschillen door randomisatie)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Til het naar een hoger niveau
- De cursus Supervised Learning with scikit-learn is het startpunt van DataCamp’s curriculum voor machine learning in Python en behandelt k-nearest neighbors.
- De cursussen Anomaly Detection in Python, Dealing with Missing Data in Python en Machine Learning for Finance in Python laten ook voorbeelden zien van het gebruik van k-nearest neighbors.
- De Decision Tree Classification in Python Tutorial behandelt een ander machine learning-model voor classificatie.
- De scikit-learn cheat sheet biedt een handige referentie voor populaire machine learning-functionaliteit.
