
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Model bahasa besar (LLM) merevolusi berbagai industri. Dari chatbot layanan pelanggan hingga alat analisis data yang canggih, kapabilitas teknologi kuat ini membentuk ulang lanskap interaksi digital dan automasi.
Namun, penerapan LLM secara praktis dapat dibatasi oleh kebutuhan komputasi berdaya tinggi atau keharusan waktu respons yang cepat. Model-model ini umumnya membutuhkan perangkat keras yang canggih dan banyak dependensi, yang dapat menyulitkan adopsi di lingkungan yang lebih terbatas.
Di sinilah LLaMa.cpp (atau LLaMa C++) hadir membantu, menyediakan alternatif yang lebih ringan dan portabel dibandingkan kerangka kerja yang berat.

Logo Llama.cpp (sumber)
Llama.cpp dikembangkan oleh Georgi Gerganov. Perangkat ini mengimplementasikan arsitektur LLaMa milik Meta dalam C/C++ yang efisien, dan merupakan salah satu komunitas open-source paling dinamis di sekitar inferensi LLM dengan lebih dari 900 kontributor, 69.000+ bintang di repositori GitHub resmi, dan 2.600+ rilis.
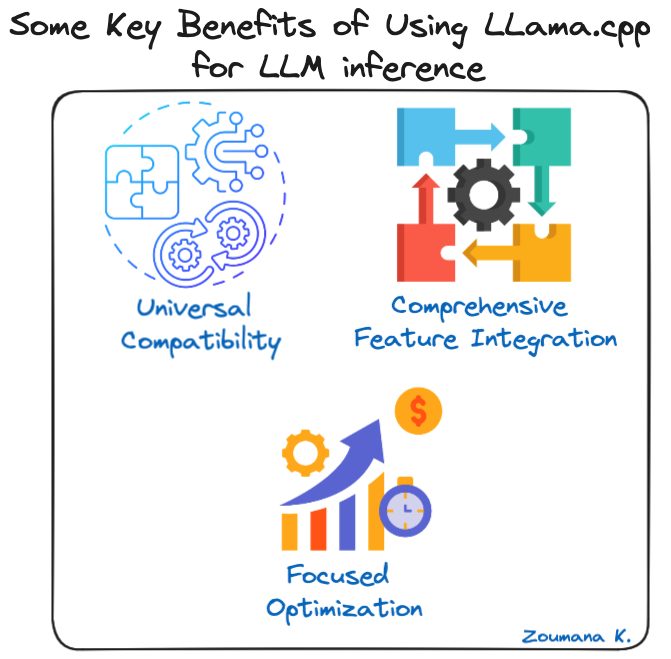
Beberapa manfaat kunci menggunakan LLama.cpp untuk inferensi LLM
Dengan pemahaman tentang Llama.cpp ini, bagian selanjutnya dari tutorial akan memandu proses mengimplementasikan use case pembuatan teks. Kita mulai dengan mengeksplorasi dasar-dasar LLama.cpp, memahami alur kerja ujung ke ujung proyek yang sedang dibahas, serta menganalisis beberapa penerapannya di berbagai industri.
Tulang punggung Llama.cpp adalah model Llama asli, yang juga berbasis arsitektur transformer. Para penulis Llama memanfaatkan berbagai peningkatan yang kemudian diusulkan dan digunakan pada model berbeda seperti PaLM.
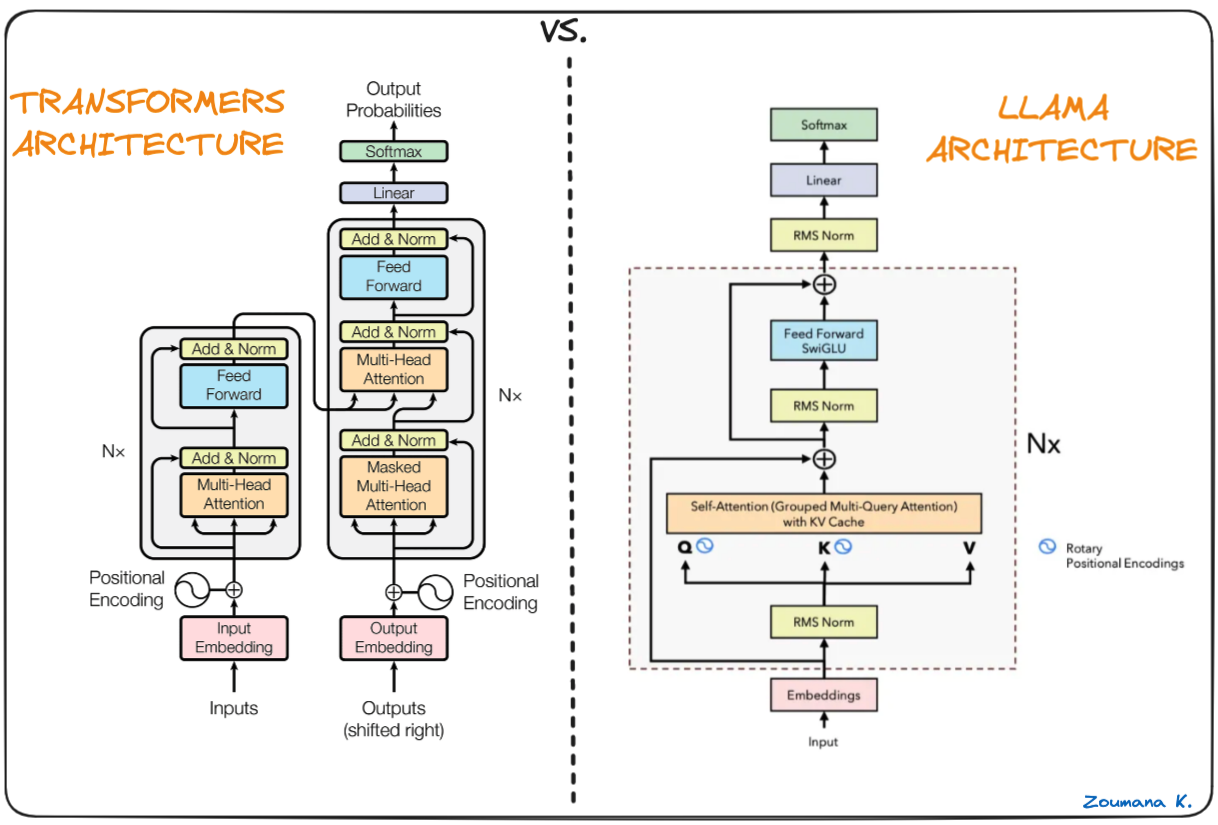
Perbedaan antara arsitektur Transformers dan Llama (Arsitektur Llama oleh Umar Jamil)
Perbedaan utama antara arsitektur LLaMa dan transformer:
Prasyarat untuk mulai bekerja dengan LLama.cpp mencakup:
Python: agar dapat menjalankan pip, yaitu pengelola paket PythonLlama-cpp-python: binding Python untuk llama.cppDisarankan membuat lingkungan virtual untuk menghindari masalah terkait proses instalasi, dan conda bisa menjadi kandidat yang baik untuk pembuatan lingkungan.
Semua perintah di bagian ini dijalankan dari terminal. Dengan pernyataan conda create, kita membuat lingkungan virtual bernama llama-cpp-env.
conda create --name llama-cpp-envSetelah lingkungan virtual berhasil dibuat, kita mengaktifkan lingkungan virtual di atas menggunakan pernyataan conda activate, sebagai berikut:
conda activate llama-cpp-envPernyataan di atas akan menampilkan nama variabel lingkungan di dalam tanda kurung pada awal terminal sebagai berikut:

Nama lingkungan virtual setelah aktivasi
Sekarang, kita dapat memasang paket llama-cpp-python sebagai berikut:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48Eksekusi llama_cpp_script.py yang berhasil berarti pustaka telah terpasang dengan benar.
Untuk memastikan pemasangan berhasil, mari buat dan tambahkan pernyataan import, lalu jalankan skripnya.
from llama_cpp import Llama ke berkas llama_cpp_script.py, lalullama_cpp_script.py untuk mengeksekusi berkas. Jika pustaka gagal diimpor, akan muncul error; karenanya, proses instalasi perlu didiagnosis lebih lanjut.Pada tahap ini, proses pemasangan seharusnya sudah berhasil. Mari dalami pemahaman dasar-dasar LLama.cpp.
Kelas Llama yang diimpor di atas adalah konstruktor utama yang dimanfaatkan saat menggunakan Llama.cpp, dan menerima beberapa parameter—tidak terbatas pada yang di bawah ini. Daftar lengkap parameter tersedia di dokumentasi resmi:
model_path: Path ke berkas model Llama yang digunakanprompt: Prompt input untuk model. Teks ini ditokenisasi dan diteruskan ke model.device: Perangkat yang digunakan untuk menjalankan model Llama; dapat berupa CPU atau GPU.max_tokens: Jumlah token maksimum yang akan dihasilkan dalam respons modelstop: Daftar string yang akan menghentikan proses generasi modeltemperature: Nilai berkisar antara 0 dan 1. Semakin rendah nilainya, semakin deterministik hasil akhirnya. Sebaliknya, nilai yang lebih tinggi menghasilkan lebih banyak keacakan, sehingga output lebih beragam dan kreatif.top_p: Digunakan untuk mengontrol keragaman prediksi, artinya memilih token paling mungkin yang probabilitas kumulatifnya melampaui ambang tertentu. Dimulai dari nol, nilai yang lebih tinggi meningkatkan peluang menemukan output yang lebih baik namun memerlukan komputasi tambahan.echo: Boolean untuk menentukan apakah model menyertakan prompt asli di awal (True) atau tidak menyertakannya (False)Misalnya, anggap kita ingin menggunakan model bahasa besar bernama <MY_AWESOME_MODEL> yang disimpan di direktori kerja saat ini. Proses instansiasi akan terlihat seperti ini:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Kodenya cukup jelas dan mudah dipahami dari poin-poin awal yang menjelaskan arti setiap parameter.
Hasil model berupa dictionary yang berisi respons yang dihasilkan beserta beberapa metadata tambahan. Format output akan dibahas di bagian berikutnya dari artikel ini.
Sekarang waktunya memulai implementasi proyek pembuatan teks. Memulai proyek Llama.cpp baru tidak lebih dari mengikuti templat kode Python di atas, yang menjelaskan semua langkah dari memuat model bahasa besar yang diinginkan hingga menghasilkan respons akhir.
Proyek ini memanfaatkan versi GGUF dari Zephyr-7B-Beta dari Hugging Face. Ini adalah versi fine-tuned dari mistralai/Mistral-7B-v0.1 yang dilatih pada campuran dataset publik dan sintetis menggunakan Direct Preference Optimization (DPO).
Pengantar Menggunakan Transformers dan Hugging Face kami memberikan pemahaman lebih baik tentang Transformers dan cara memanfaatkan kekuatannya untuk menyelesaikan masalah nyata. Kami juga memiliki tutorial Mistral 7B.
Model Zephyr dari Hugging Face (sumber)
Setelah model diunduh secara lokal, kita dapat memindahkannya ke lokasi proyek dalam folder model. Sebelum masuk ke implementasi, mari pahami struktur proyeknya:

Struktur proyek
Langkah pertama adalah memuat model menggunakan konstruktor Llama. Karena ini model besar, penting untuk menentukan ukuran konteks maksimum model yang akan dimuat. Pada proyek ini, kita menggunakan 512 token.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Setelah model dimuat, langkah berikutnya adalah tahap pembuatan teks, dengan menggunakan templat kode asli, tetapi kita menggunakan fungsi pembantu bernama generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputDi dalam klausa __main__, fungsi tersebut dapat dijalankan menggunakan sebuah prompt.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)Respons model disajikan di bawah ini:

Respons model
Respons yang dihasilkan model adalah <What do you think about the inclusion policies in Tech companies?> dan respons persis dari model disorot dalam kotak oranye.
Walaupun output lengkap ini dapat berguna untuk penggunaan lebih lanjut, kita mungkin hanya tertarik pada respons tekstual dari model. Kita dapat memformat respons untuk mendapatkan hasil tersebut dengan memilih kolom “text” dari elemen “choices” sebagai berikut:
final_result = model_output["choices"][0]["text"].strip()
Fungsi strip() digunakan untuk menghapus spasi kosong di awal dan akhir string dan hasilnya adalah:
Tech companies want diverse workforces to build better products.Bagian ini membahas aplikasi nyata LLama.cpp dan menyajikan masalah yang mendasari, solusi yang memungkinkan, serta manfaat menggunakan Llama.cpp.
Bayangkan ETP4Africa, sebuah startup teknologi yang membutuhkan model bahasa yang dapat beroperasi secara efisien di berbagai perangkat untuk aplikasi pendidikan mereka tanpa menimbulkan keterlambatan.
Mereka mengimplementasikan Llama.cpp, memanfaatkan kinerja yang dioptimalkan untuk CPU dan kemampuan untuk berinteraksi dengan backend berbasis Go mereka.
Integrasi Llama.cpp memungkinkan aplikasi ETP4Africa menawarkan panduan pemrograman yang langsung dan interaktif, sehingga meningkatkan pengalaman dan keterlibatan pengguna.
Data Engineering adalah komponen kunci dari setiap proyek Data Science dan AI, dan tutorial kami Pengantar LangChain untuk Data Engineering & Aplikasi Data menyediakan panduan lengkap untuk memasukkan AI dari model bahasa besar ke dalam pipeline data dan aplikasi.
Singkatnya, artikel ini telah memberikan gambaran menyeluruh mengenai penyiapan dan pemanfaatan model bahasa besar dengan LLama.cpp.
Instruksi terperinci diberikan untuk membantu Anda memahami dasar-dasar Llama.cpp, menyiapkan lingkungan kerja, memasang pustaka yang diperlukan, dan mengimplementasikan use case pembuatan teks (tanya jawab).
Terakhir, wawasan praktis disajikan untuk aplikasi dunia nyata dan bagaimana Llama.cpp dapat digunakan secara efisien untuk mengatasi masalah yang mendasarinya.
Siap menyelami lebih dalam dunia model bahasa besar? Tingkatkan keterampilan Anda dengan kerangka kerja deep learning andal LangChain dan Pytorch yang digunakan para profesional AI melalui tutorial kami How to Build LLM Applications with LangChain dan How to Train a LLM with PyTorch.
Mulai Perjalanan AI Anda Hari Ini!
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
